最近在使用pyspark处理数据,需要连接各种各样的表和字段,因此记录相关函数的使用情况。今天介绍explode().
1. explode()函数简介
explode 函数是 pandas.DataFrame 类的一个方法,能够通过pyspark间接调用。
它可以将一个包含list或者其它可迭代对象的列拆分成多行,然后在所有其它列上进行复制。
函数原型:参数 column 表示 指定要拆分的列。
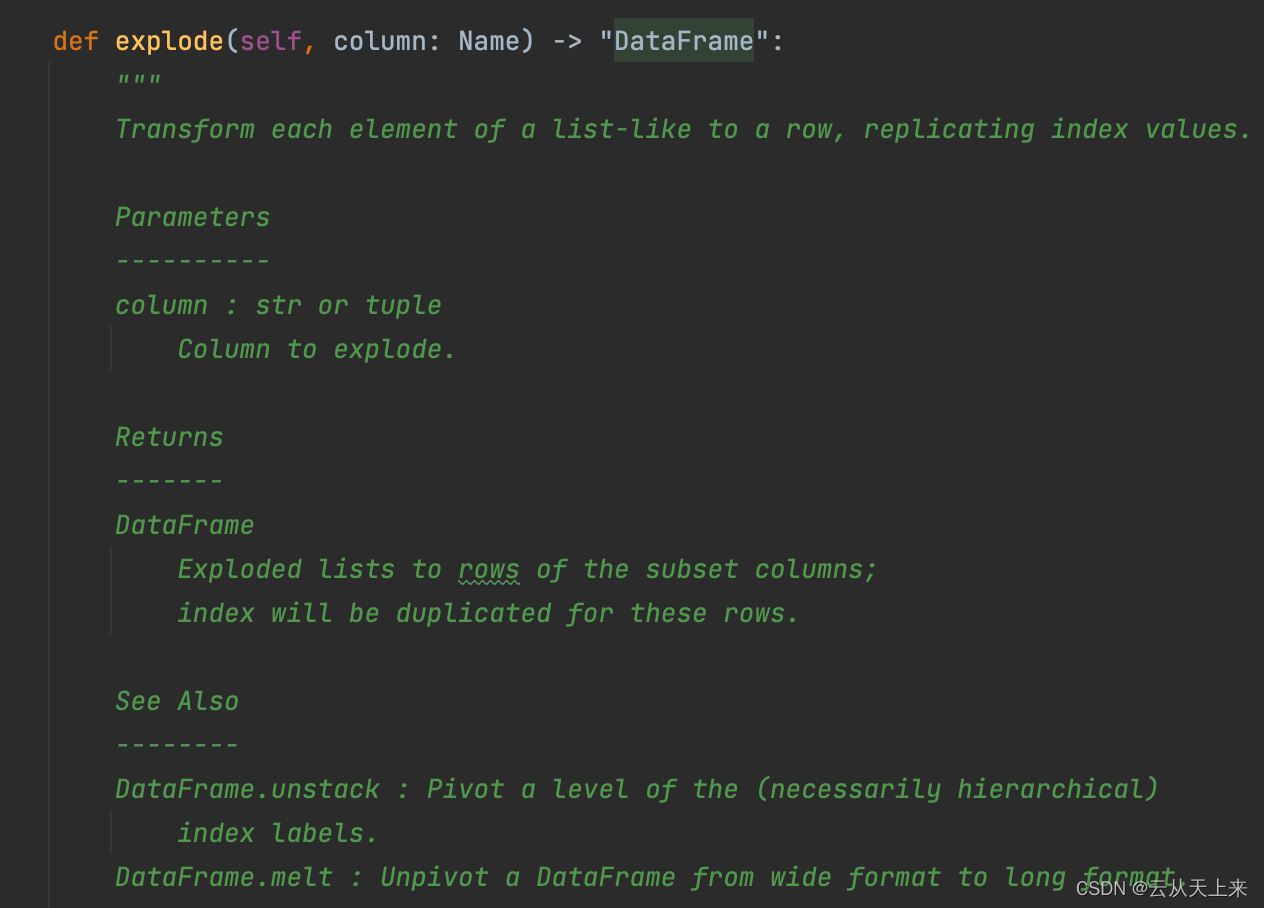
通过 pyspark调用:
from pyspark.sql import functions as F
F.explode(column)2. 实验效果
第一步:创建一个包含两列(A,B)的dataframe数据,且B包含了不同长度的数组。
import pandas as pd
df = pd.DataFrame({
'A': ['a', 'b', 'c', 'd', 'e'],
'B': [[1], [2, 4], [4, 5, 6], [], [7]]
})
print(df)
第二步:将B列展开
import pandas as pd
df = pd.DataFrame({
'A': ['a', 'b', 'c', 'd', 'e'],
'B': [[1], [2, 4], [4, 5, 6], [], [7]]
})
df = df.explode('B')
print(df)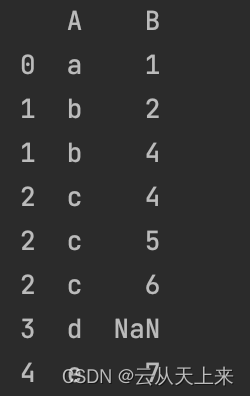
由结果可知,‘a’对应list[1],list[1]展开不变,和‘a',一对一;元素’b‘对应list[2, 4],展开list数组,元素‘b'复制,分别对应元素 2 和 4;以此类推。
注意到,A列元素伴随着B列中对应元素的展开,而复制;元素’d‘对应的空list,因此展开/拆解后A列对应的B列元素同样为空。
更加复杂的情况,A、B、C三列,df = df.explode('B').explode('C'),则考虑了所有组合情况。详情请见博客链接:pandas dataframe 中的explode函数用法详解 - Python技术站