文章目录
应用程序可能从 stdin 接收数据,也可能从 socket 接收数据。即可能有多个 IO 来源
- 可用 fgets() 等待 stdin ,但这样就无法在套接字有数据时读入数据
- 也可用 read() 等待套接字有数据返回,但这样也无法在 stdin 有数据时读入数据
「I/O 多路复用」把 stdin、套接字等都看做 I/O 的一路,当任何一路 I/O 有“事件”时通知应用程序去处理相应的 I/O 事件,此程序就变成了“多面手”,仿佛可同时处理多个 I/O 事件。(如上例使用 I/O 复用后,若 stdin 有数据,立即从 stdin 读入数据,通过套接字发送出去;若套接字有数据可读,立即可读出数据。)select()、poll()、epoll() 都是 I/O 多路复用技术。
一、select()
select() 会通知内核挂起进程,当一或多个 I/O 事件发生后,控制权返还给应用程序由应用程序处理 I/O 事件。这些 I/O 事件的类型非常多,比如:
- stdin 文件描述符,准备好可读。
- 监听套接字,准备好,新的连接已建立成功。
- 已连接套接字,准备好可写。
- 若一个 I/O 事件,等待超过了 10 秒发生了超时事件。
内核用 select() 标识套接字有数据可读时,用 read() 肯定不会阻塞。具体有如下几种情况:
- 情况一:套接字接收缓冲区有数据可读,则此时执行 read() 不阻塞,而是会直接读到这部分数据。
- 情况二:若对方发送了 FIN,则此时执行 read() 不阻塞,直接返回 0。
- 情况三:针若一个监听套接字有已建立完的连接,则此时执行 accept() 不阻塞,直接返回已完成的连接。
- 情况四:套接字有错误待处理,则此时执行 read() 不阻塞,且返回 -1。
内核用 select() 标识套接字有数据可写时,用 write() 肯定不会阻塞。具体有如下几种情况:
- 第一种是套接字发送缓冲区足够大,若用非阻塞套接字 write() 将不会被阻塞而直接返回。
- 第二种是连接的写半边已关闭,若继续写则将产生 SIGPIPE 信号。
- 第三种是套接字上有错误待处理,用 write() 去执行写,不阻塞且返回 -1。
select() 是多个 UNIX 平台支持的非常常见的 I/O 多路复用技术,它通过描述符集合来表示检测的 I/O 对象,通过三个不同的描述符集合来描述 I/O 事件 :可读、可写和异常。
但 select() 的缺点是所支持的文件描述符的个数有限。Linux 中 select() 的默认最大值为 1024。
1.1 用法
select() 声明如下:
- 返回:若有就绪描述符则为其数目,若超时则为 0,若出错则为 -1
- maxfd 表示待测试的描述符基数,其值是待测试的最大描述符加 1。如 select() 待测试的描述符集合是 {0,1,4},则向量对应的是
a[4],a[3],a[2],a[1],a[0],故 maxfd 为 5。 - 读描述符集合 readset、写描述符集合 writeset 和异常描述符集合 exceptset,分别通知内核在哪些描述符上,检测数据可读,可写和有异常发生。
int select(int maxfd, fd_set *readset, fd_set *writeset, fd_set *exceptset, const struct timeval *timeout);
- 通过如下宏可设置 fdset(描述符集合):
- 其实很多系统用一个整型数组表示一个描述字集合,一个 32 位的整型数可表示 32 个描述字。(如第一个整型数表示 0-31 描述字,第二个整型数表示 32-63 描述字,以此类推。)
- 若某描述符集合设置为空,即表示不需内核做相关的检测。
// fdset(描述符集合)可视为一个向量,向量的每个元素都是二进制数中的 0 或 1。 0 代表不需要处理,1 代表需要处理
// a[maxfd-1], ..., a[1], a[0]
void FD_ZERO (fd_set *fdset); // 此向量的所有元素都设置成 0
void FD_SET (int fd, fd_set *fdset); // 把对应套接字 fd 的元素,a[fd] 设置成 1
void FD_CLR (int fd, fd_set *fdset); // 把对应套接字 fd 的元素,a[fd] 设置成 0
int FD_ISSET(int fd, fd_set *fdset); // 对此向量进行检测,判断出对应套接字的元素 a[fd] 是 0 还是 1
- 最后一个参数是 timeval 结构体时间:
- 若设置成空 (NULL),表示若无 I/O 事件发生,则 select() 一直等待下去。
- 若设置一个非零的值,表示等待固定的一段时间后,从 select() 阻塞调用中返回。
- 若将 tv_sec 和 tv_usec 都设置成 0,表示根本不等待,检测完毕立即返回。(较少使用此方式)
struct timeval {
long tv_sec; // seconds
long tv_usec; // microseconds
};
1.1 实战
下文是基于 select() 的 server 示例:
- 第 12 行通过 FD_ZERO() 初始化了一个描述符集合,此描述符读集合是空的:
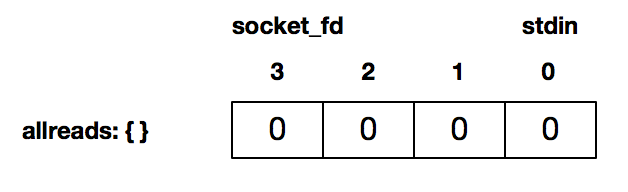
- 第 13、14 行,分别用 FD_SET() 将描述符 0(即 stdin),以及连接套接字描述符 3 设置为待检测:
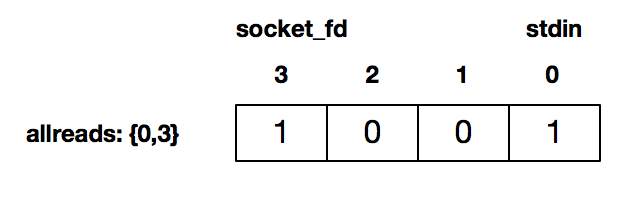
- 接下来的 16-51 行是循环检测,这里没有阻塞在 fgets() 或 read(),而是通过 select() 来检测套接字描述字有数据可读、或 stdin 有数据可读。如当用户在 stdin 输入使得 stdin 描述符可读时,返回的 readmask 的值为:
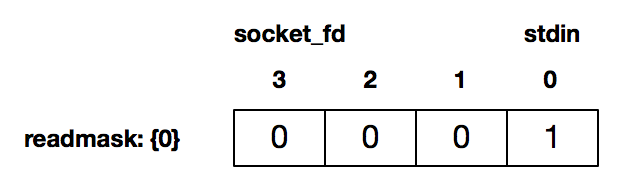
- 此时 select() 调用返回,可用 FD_ISSET() 判断哪个描述符准备好可读了。如上图此时是 stdin 可读,37-51 行读入后发送给对端。
- 若连接描述字准备好可读了,第 24 行判断为真,用 read() 将套接字数据读出。
- 第 17 行是每次测试完后,都会「重新设置」待测试的描述符集合。(如上例在 select() 测试之前的数据是{0,3},select() 测试之后就变成了{0}。)这是因为 select() 的每次完成测试之后,内核都会修改描述符集合,通过修改完的描述符集合来和应用程序交互,应用程序用 FD_ISSET() 对每个描述符进行判断从而知道发生了什么事件。
- 第 18 行用 socket_fd+1 来表示待测试的描述符基数。切记需要 +1。
// https://github.com/datager/yolanda/blob/master/chap-20/select01.c
int main(int argc, char **argv) {
if (argc != 2) {
error(1, 0, "usage: select01 <IPaddress>");
}
int socket_fd = tcp_client(argv[1], SERV_PORT);
char recv_line[MAXLINE], send_line[MAXLINE];
int n;
fd_set readmask;
fd_set allreads;
FD_ZERO(&allreads); // 第12行:用 FD_ZERO() 初始化了一个描述符集合,此描述符读集合是空的
FD_SET(0, &allreads); // 第13行:用 FD_SET() 将 stdin (即描述符0) 设置为待检测
FD_SET(socket_fd, &allreads); // 第14行:用 FD_SET() 将连接套接字(描述符3) 设置为待检测
for (;;) {
// 16-51行: 循环检测
readmask = allreads; // 第17行: 每次测试完之后,重新设置待测试的描述符集合。如在 select() 测试之前的数据是{0,3},select() 测试之后就变成了{0}。然后这里再重置为{0,3}。这是因为 select() 调用每次完成测试之后 内核都会修改描述符集合,通过修改完的描述符集合来和应用程序交互,应用程序用 FD_ISSET() 对每个描述符进行判断从而知道发生了什么事件。
int rc = select(socket_fd + 1, &readmask, NULL, NULL, NULL); // 第18行: 用socket_fd+1 表示待测试的描述符基数(切记需要 +1)。本行没有阻塞在 fgets() 或 read() 调用,而是通过 select() 来检测套接字描述字有数据可读、或 stdin 有数据可读。比如当用户在 stdin 输入使得 stdin 描述符可读时,返回的 readmask 的值为:0001; select() 调用返回后即可用 FD_ISSET() 来判断哪个描述符准备好可读了
if (rc <= 0) {
error(1, errno, "select() failed");
}
if (FD_ISSET(socket_fd, &readmask)) {
// 第24行: 连接描述字准备好可读了, 判断为真, 用 read() 将套接字数据读出
n = read(socket_fd, recv_line, MAXLINE);
if (n < 0) {
error(1, errno, "read error");
} else if (n == 0) {
error(1, 0, "server terminated \n");
}
recv_line[n] = 0;
fputs(recv_line, stdout);
fputs("\n", stdout);
}
if (FD_ISSET(STDIN_FILENO, &readmask)) {
// stdin 可读,37-51 行程序读入后发送给对端
if (fgets(send_line, MAXLINE, stdin) != NULL) {
int i = strlen(send_line);
if (send_line[i - 1] == '\n') {
send_line[i - 1] = 0;
}
printf("now sending %s\n", send_line);
size_t rt = write(socket_fd, send_line, strlen(send_line));
if (rt < 0) {
error(1, errno, "write failed ");
}
printf("send bytes: %zu \n", rt);
}
}
}
}
二、poll()
poll() 是除了 select() 之外,另一种普遍用的 I/O 多路复用技术,和 select() 相比:
- 它突破了文件描述符的个数限制
- 和内核交互的数据结构也有变化
2.1 用法
声明如下:
int poll(struct pollfd *fds, unsigned long nfds, int timeout);
// 返回值:若有就绪描述符则为其数目,若超时则为 0,若出错则为 -1
// 参数 nfds: 描述的是数组 fds 的大小,即向 poll() 申请的事件检测的个数。
- 第一个参数是一个 pollfd 的数组。其中 pollfd 的结构如下:
struct pollfd {
int fd; // file descriptor: 描述符 fd
short events; // events to look for: 描述符上待检测的事件类型 events, 注意这里的 events 可表示多个不同的事件,具体的实现可通过用二进制掩码位操作来完成,
short revents; // returned events: 和 select() 非常不同的地方在于,poll 每次检测之后的结果不会修改原来的传入值,而是将结果保留在 revents 字段中,这样就不需要每次检测完都得重置待检测的描述字和感兴趣的事件。
};
events 类型的事件可分为两大类:
- 第一类是可读事件,有以下几种:
// 一般程序用 POLLIN 即可。套接字可读事件和 select() 的 readset 基本一致,即若系统内核通知应用程序有数据可读则 read() 不会被阻塞。
#define POLLIN 0x0001 /* any readable data available */
#define POLLPRI 0x0002 /* OOB/Urgent readable data */
#define POLLRDNORM 0x0040 /* non-OOB/URG data available */
#define POLLRDBAND 0x0080 /* OOB/Urgent readable data */
- 第二类是可写事件,有以下几种:
// 一般程序用 POLLOUT。套接字可写事件和 select() 的 writeset 基本一致,即若系统内核通知套接字缓冲区已准备好则 write() 不会被阻塞。
#define POLLOUT 0x0004 /* file descriptor is writeable */
#define POLLWRNORM POLLOUT /* no write type differentiation */
#define POLLWRBAND 0x0100 /* OOB/Urgent data can be written */
- 前两类事件都可在 “returned events” 复用。第三类是错误事件,其无法通过 poll() 向系统内核递交检测请求,只能通过“returned events”来加以检测。
#define POLLERR 0x0008 /* 一些错误发送 */
#define POLLHUP 0x0010 /* 描述符挂起 */
#define POLLNVAL 0x0020 /* 请求的事件无效 */
参数 nfds 描述的是数组 fds 的大小,即向 poll() 申请的事件检测的个数。
最后一个参数 timeout,描述了 poll() 的行为。
- 若是一个 <0 的数,表示在有事件发生之前永远等待;
- 若是 0,表示不阻塞进程立即返回;
- 若是一个 >0 的数,表示 poll() 调用方等待指定的毫秒数后返回。
关于返回值:
- 当有错误发生时,返回 -1;
- 若在指定的时间到达之前未发生任何事件,则返回 0;
- 否则就返回检测到的事件个数,即 “returned events” 中非 0 的描述符个数。
poll() 有一点非常好,若不想对某个 pollfd 结构进行事件检测,可把它对应的 pollfd 结构的 fd 成员设置成一个负值。这样 poll() 将忽略此 events 事件,检测完成后所对应的 “returned events” 成员值也将被置为 0。
和 select() 对比一下,发现 poll() 和 select() 不一样的地方就是:
- 在 select() 里,文件描述符的个数已随着 fd_set 的实现而固定,无法对此进行配置
- 而在 poll() 里,可控制 pollfd 结构的数组大小,这意味着可突破原来 select() 最大描述符的限制,此情况下应用程序调用者需分配 pollfd 数组并通知 poll() 该数组的大小。
2.2 实战
下面将开发一个基于 poll() 的 server,其可同时处理多个 client 连接,且一旦有 client 数据接收则同步回显回去。这已是一个颇具高并发处理的 server 原型了,再加上后面讲到的非阻塞 I/O 和多线程等技术,基本上就是可用的准生产级别了。
// https://github.com/datager/yolanda/blob/master/chap-21/pollserver.c
#define INIT_SIZE 128
int main(int argc, char **argv) {
int listen_fd, connected_fd;
int ready_number;
ssize_t n;
char buf[MAXLINE];
struct sockaddr_in client_addr;
listen_fd = tcp_server_listen(SERV_PORT); // 创建一个监听套接字,并绑定在本地的地址和端口上
// 初始化 pollfd 数组,此数组的第一个元素是 listen_fd,其余的用来记录将要连接的 connect_fd
struct pollfd event_set[INIT_SIZE]; // 初始化event_set变量,其为pollfd数组, 代表了检测的事件集合。这里数组的大小固定为 INIT_SIZE,而这在实际的生产环境肯定是需要改进的。
event_set[0].fd = listen_fd; // 14-15行: 表示期望系统内核检测监听套接字上的, 连接建立完成事件。
event_set[0].events = POLLRDNORM;
// 前文介绍 poll() 时,说过若对应 pollfd 里的文件描述字 fd 为负数,poll() 将会忽略此 pollfd。 故此处均设置为-1
int i;
for (i = 1; i < INIT_SIZE; i++) {
event_set[i].fd = -1;
}
for (;;) {
if ((ready_number = poll(event_set, INIT_SIZE, -1)) < 0) {
// timeout 设置为 -1,表示在 I/O 事件发生之前 poll() 一直阻塞。
error(1, errno, "poll failed ");
}
if (event_set[0].revents & POLLRDNORM) {
// 内核检测到 监听套接字上的 连接建立事件 (通过event_set[0].revent 和 对应的事件类型,按位与是因为 event 都是通过二进制位来进行记录的,位与操作是和对应的二进制位进行操作,一个文件描述字是可对应到多个事件类型的。)
socklen_t client_len = sizeof(client_addr);
connected_fd = accept(listen_fd, (struct sockaddr *) &client_addr, &client_len);
// 找到一个可记录该连接套接字的位置
for (i = 1; i < INIT_SIZE; i++) {
// 33-38 行做了一件事: 就是把连接描述字 connect_fd 也加入到 event_set 里,且说明了感兴趣的事件类型为 POLLRDNORM,即套集字上有数据可读。
if (event_set[i].fd < 0) {
// 从数组里查找一个没有没占用的位置,即 fd 为 -1 的位置,然后把 fd 设置为新的连接套接字 connect_fd
event_set[i].fd = connected_fd;
event_set[i].events = POLLRDNORM;
break;
}
}
if (i == INIT_SIZE) {
// 41-42 行: 若在数组里找不到这样一个位置,说明 event_set 已被很多连接充满了,无法接收更多连接了。
error(1, errno, "can not hold so many clients");
}
if (--ready_number <= 0) // 45-46 行是一个加速优化能力: 因 poll() 返回的整数说明了这次 I/O 事件描述符的个数。若处理完监听套接字之后,就已完成了这次 I/O 复用所要处理的事情,即可跳过后面的处理再次进入 poll() 调用。
continue;
}
for (i = 1; i < INIT_SIZE; i++) {
// 循环处理: 查看 event_set 里面其他的事件,即已连接套接字的 可读事件
int socket_fd;
if ((socket_fd = event_set[i].fd) < 0) // 若数组里的 pollfd 的 fd 为 -1,说明此 pollfd 没有递交有效的检测,直接跳过
continue;
if (event_set[i].revents & (POLLRDNORM | POLLERR)) {
// 通过检测 revents 的事件类型是 POLLRDNORM 或 POLLERR,可进行读操作
if ((n = read(socket_fd, buf, MAXLINE)) > 0) {
// 读取数据正常之后,再通过 write() 回显给客户端
if (write(socket_fd, buf, n) < 0) {
error(1, errno, "write error");
}
} else if (n == 0 || errno == ECONNRESET) {
// 若读到 EOF 或是连接重置,则关闭此连接,并把 event_set 对应的 pollfd 重置为 -1
close(socket_fd);
event_set[i].fd = -1;
} else {
// 读取数据失败
error(1, errno, "read error");
}
if (--ready_number <= 0)
break;
}
}
}
}
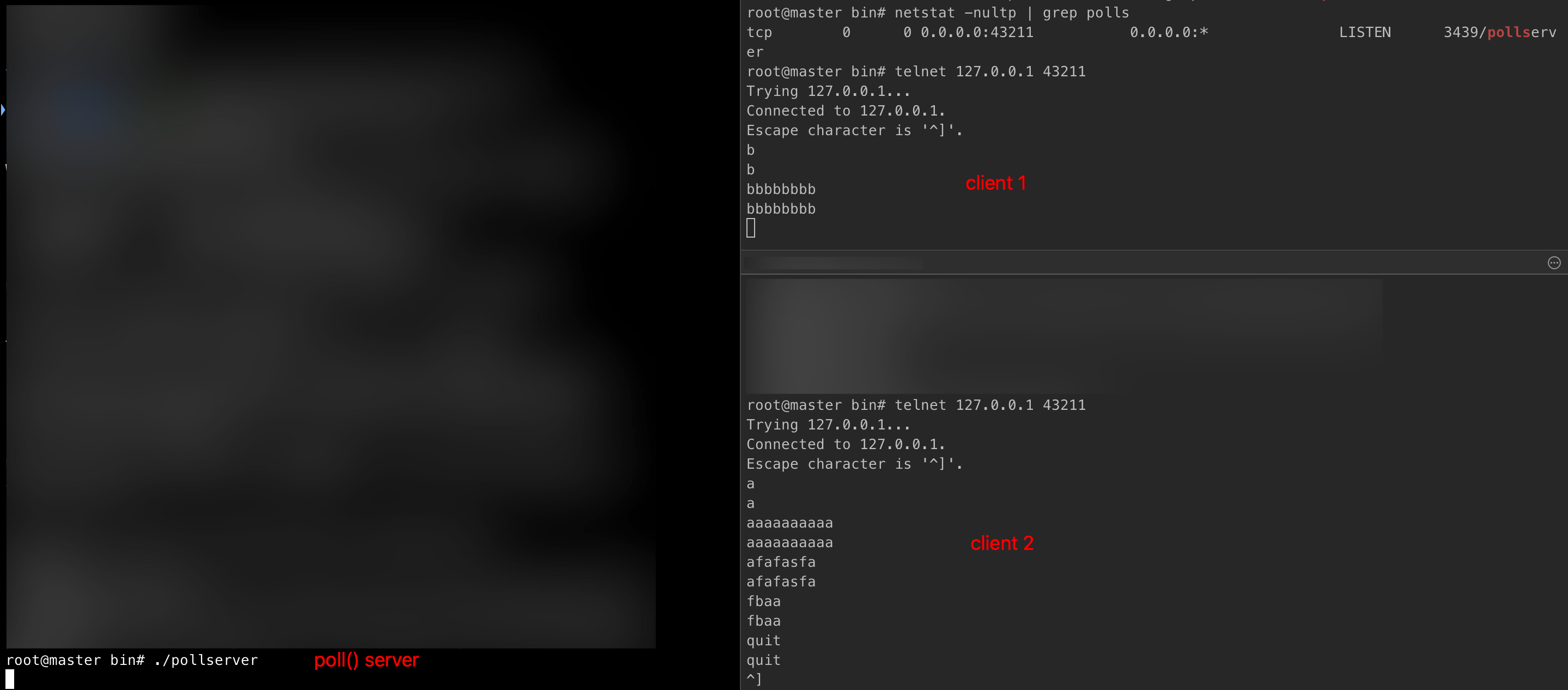
启动此 server,然后通过 telnet 连接到此 server。为了检验此 server 的 I/O 复用能力,可多开几个 telnet client,并在屏幕上输入各种字符串。可看到这两 client 互不影响,每个 client 输入的字符很快会被回显到 client 屏幕上。一个 client 断开连接,也不会影响到其他 client 。
三、阻塞、非阻塞
- 阻塞:当应用程序调用阻塞 I/O 完成某个操作时,应用程序会被挂起等待内核完成操作,感觉应用程序像是被“阻塞”了一样。其实内核是将 CPU 时间切换给其他有需要的进程,网络应用程序在这种情况下就会得不到 CPU 时间来做该做的事。
- 非阻塞:当应用程序调非阻塞 I/O 完成某个操作时,内核立即返回,而不会把 CPU 时间切换给其他进程,应用程序在返回后可得到足够的 CPU 时间来继续完成其他事。
若拿去书店买书举例子
- 阻塞 I/O 对应什么场景呢? 你去了书店,告诉老板(内核)你想要某本书,然后你就一直在那里等着,直到书店老板翻箱倒柜找到你想要的书,有可能还要帮你联系全城其它分店。注意,此过程中你一直滞留在书店等待老板的回复,好像在书店老板这里"阻塞"住了。
- 非阻塞 I/O 呢?你去了书店,问老板有没你心仪的那本书,老板查了下电脑,告诉你没有,你就悻悻离开了。一周后你又来此书店,再问此老板,老板一查,有了,于是你买了这本书。注意此过程中,你没有被阻塞,而是在不断轮询。
- 但轮询的效率太低了,于是你向老板提议:“老板,到货给我打电话吧,我再来付钱取书。”这就是前面讲到的 I/O 多路复用。
- 再进一步,你连去书店取书也想省了,得了,让老板代劳吧,你留下地址,付了书费,让老板到货时寄给你,你直接在家里拿到就可看了。这就是异步 I/O。
这几个 I/O 模型,再加上进程、线程模型,构成了整个网络编程的知识核心。
3.1 非阻塞 IO
非阻塞 IO 和 前文介绍的 IO 多路复用,都是高性能网络编程的常见技术。非阻塞 I/O 可用在 read、write、accept、connect 等多种不同的场景,在非阻塞 I/O 下,用轮询的方式引起 CPU 占用率高,所以一般将非阻塞 I/O 和 I/O 多路复用技术 select、poll 等搭配用,在非阻塞 I/O 事件发生时,再调用对应事件的处理函数。这种方式极大地提高了程序的健壮性和稳定性,是 Linux 高性能网络编程首选。
按场景,非阻塞 I/O 可被用到读操作、写操作、接收连接操作和发起连接操作上。接下来对它们一一解读。
3.1.1 read()
若套接字对应的接收缓冲区没有数据可读,在非阻塞情况下 read() 会立即返回,一般返回 EWOULDBLOCK 或 EAGAIN 出错信息。在这种情况下,出错信息需小心处理,比如后面再次调用 read(),而不是直接作为错误直接返回。这就好像去书店买书没买到离开一样,需要不断轮询。
3.1.2 write()
不知道你有没有注意到,在阻塞 I/O 情况下,write() 返回的字节数,和输入的参数总是一样的。若返回值总是和输入的数据大小一样,write() 等写入函数还需要定义返回值吗?我不知道你是不是和我一样,刚接触到这一部分知识时有这种困惑。
这里就要引出所说的非阻塞 I/O。在非阻塞 I/O 的情况下,若套接字的发送缓冲区已达到了极限,不能容纳更多的字节,那么操作系统内核会尽最大可能从应用程序拷贝数据到发送缓冲区中,并立即从 write() 等函数调用中返回。可想而知,在拷贝动作发生的瞬间,有可能一个字符也没拷贝,有可能所有请求字符都被拷贝完成,那么此时候就需要返回一个数值,告诉应用程序到底有多少数据被成功拷贝到了发送缓冲区中,应用程序需要再次调用 write() ,以输出未完成拷贝的字节。
即 阻塞 I/O 和 非阻塞 I/O 处理方式不一样。
- 阻塞 I/O:拷贝→直到所有数据拷贝至发送缓冲区完成→返回。
- 非阻塞 I/O:拷贝→返回→再拷贝→再返回。
- 不过在实战中可不用区别阻塞和非阻塞 I/O,用循环的方式来写入数据就好了。只不过在阻塞 I/O 的情况下,循环只执行一次就结束了。代码如下:
/* 向文件描述符 fd 写入 n 字节数 */
ssize_t writen(int fd, const void * data, size_t n)
{
size_t nleft;
ssize_t nwritten;
const char *ptr;
ptr = data;
nleft = n;
// 若还有数据没被拷贝完成,就一直循环
while (nleft > 0) {
if ( (nwritten = write(fd, ptr, nleft)) <= 0) {
// 这里 EINTR 是非阻塞 non-blocking 情况下,通知再次调用 write()
if (nwritten < 0 && errno == EINTR)
nwritten = 0;
else
return -1; // 出错退出
}
// 指针增大,剩下字节数变小
nleft -= nwritten;
ptr += nwritten;
}
return n;
}
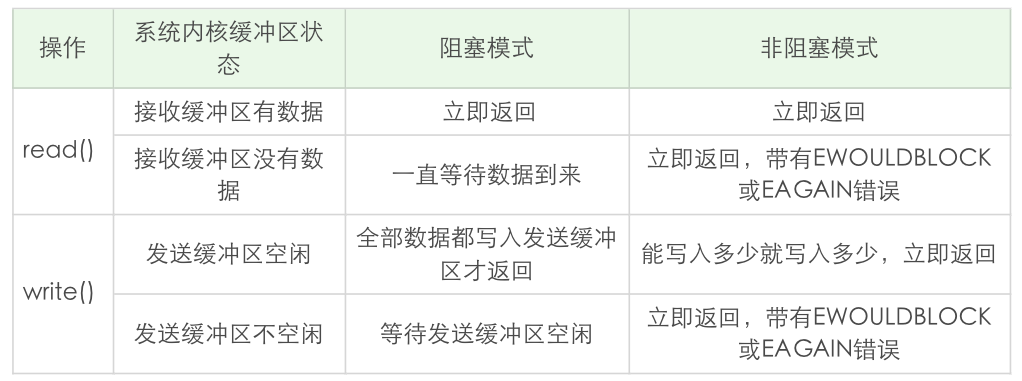
关于 read() 和 write() 的区别:
- read()
- 当接收区有数据时:就立即返回,而不是等到应用程序给定的数据充满才返回。
- 当接收缓冲区为空时:
- 阻塞模式会等待
- 非阻塞模式立即返回 -1,并有 EWOULDBLOCK 或 EAGAIN 错误。
- write()
- 阻塞模式下,只有在发送缓冲区足以容纳应用程序的输出字节时才返回。(特例是对方主动关闭了套接字时 write() 会立即返回,并通过返回值告诉应用程序实际写入的字节数,若再次对此套接字 write() 就会返回失败。失败是通过返回值 -1 来通知到应用程序的。)
- 非阻塞模式下,则是能写入多少就写入多少,并返回实际写入的字节数。
3.1.3 accept()
当 accept() 和 I/O 多路复用 select()、poll() 等一起配合用时,若在监听套接字上触发事件,则说明有连接建立完成,此时调用 accept() 肯定可返回已连接的套接字。
这样看来似乎把监听套接字设置为非阻塞没有任何好处。为说明此问题,构建一个 client 程序,其中最关键的是,一旦连接建立,设置 SO_LINGER 套接字选项,把 l_onoff 标志设置为 1,把 l_linger 时间设置为 0。这样连接被关闭时,TCP 套接字上将会发送一个 RST。
struct linger ling;
ling.l_onoff = 1;
ling.l_linger = 0;
setsockopt(socket_fd, SOL_SOCKET, SO_LINGER, &ling, sizeof(ling));
close(socket_fd);
server 用 select() 做 I/O 多路复用,不过监听套接字仍然是 blocking 的。若监听套接字上有事件发生,休眠 5 秒,以便模拟高并发场景下的情形:
- 这里的休眠时间非常关键,这样在监听套接字上有可读事件发生时,并没有马上调用 accept()。由于 client 发生了 RST 分节,该连接被接收端内核从自己的已完成队列中删除了,此时再调用 accept(),由于没有已完成连接(假设没有其他已完成连接),accept() 一直阻塞,更为严重的是,该线程再也没有机会对其他 I/O 事件进行分发,相当于该 server 无法对新连接和其他 I/O 进行服务。
if (FD_ISSET(listen_fd, &readset)) {
printf("listening socket readable\n");
sleep(5);
struct sockaddr_storage ss;
socklen_t slen = sizeof(ss);
int fd = accept(listen_fd, (struct sockaddr *) &ss, &slen);
若将监听套接字设为非阻塞,上述的情形就不会再发生。只不过对于 accept 的返回值,需要正确地处理各种看似异常的错误,如忽略 EWOULDBLOCK、EAGAIN 等。
此例子给的启发是,一定要将监听套接字设置为非阻塞的,尽管这里休眠时间 5 秒有点夸张,但是在极端情况下处理不当的server 程序是有可能碰到文稿中例子所阐述的情况,为了让server 程序在极端情况下工作正常,这点工作还是非常值得的。
3.1.4 connect()
在非阻塞 TCP 套接字上调用 connect(),会立即返回一个 EINPROGRESS 错误。TCP 三次握手会正常进行,应用程序可继续做其他初始化的事情。当该连接建立成功或失败时,通过 I/O 多路复用 select、poll 等可进行连接的状态检测。
3.1.5 非阻塞IO + select() 多路复用实战
#include "lib/common.h"
#define MAX_LINE 1024
#define FD_INIT_SIZE 128
char rot13_char(char c) {
if ((c >= 'a' && c <= 'm') || (c >= 'A' && c <= 'M'))
return c + 13;
else if ((c >= 'n' && c <= 'z') || (c >= 'N' && c <= 'Z'))
return c - 13;
else
return c;
}
//数据缓冲区
struct Buffer {
int connect_fd; //连接字
char buffer[MAX_LINE]; //实际缓冲
size_t writeIndex; //缓冲写入位置
size_t readIndex; //缓冲读取位置
int readable; //是否可读
};
//分配一个Buffer对象,初始化writeIdnex和readIndex等
struct Buffer *alloc_Buffer() {
struct Buffer *buffer = malloc(sizeof(struct Buffer));
if (!buffer)
return NULL;
buffer->connect_fd = 0;
buffer->writeIndex = buffer->readIndex = buffer->readable = 0;
return buffer;
}
//释放Buffer对象
void free_Buffer(struct Buffer *buffer) {
free(buffer);
}
//这里从fd套接字读取数据,数据先读取到本地buf数组中,再逐个拷贝到buffer对象缓冲中
int onSocketRead(int fd, struct Buffer *buffer) {
char buf[1024];
int i;
ssize_t result;
while (1) {
result = recv(fd, buf, sizeof(buf), 0);
if (result <= 0)
break;
//按char对每个字节进行拷贝,每个字节都会先调用rot13_char来完成编码,之后拷贝到buffer对象的缓冲中,
//其中writeIndex标志了缓冲中写的位置
for (i = 0; i < result; ++i) {
if (buffer->writeIndex < sizeof(buffer->buffer))
buffer->buffer[buffer->writeIndex++] = rot13_char(buf[i]);
//若读取了回车符,则认为client端发送结束,此时可把编码后的数据回送给客户端
if (buf[i] == '\n') {
buffer->readable = 1; //缓冲区可读
}
}
}
if (result == 0) {
return 1;
} else if (result < 0) {
if (errno == EAGAIN)
return 0;
return -1;
}
return 0;
}
//从buffer对象的readIndex开始读,一直读到writeIndex的位置,这段区间是有效数据
int onSocketWrite(int fd, struct Buffer *buffer) {
while (buffer->readIndex < buffer->writeIndex) {
ssize_t result = send(fd, buffer->buffer + buffer->readIndex, buffer->writeIndex - buffer->readIndex, 0);
if (result < 0) {
if (errno == EAGAIN)
return 0;
return -1;
}
buffer->readIndex += result;
}
//readindex已追上writeIndex,说明有效发送区间已全部读完,将readIndex和writeIndex设置为0,复用这段缓冲
if (buffer->readIndex == buffer->writeIndex)
buffer->readIndex = buffer->writeIndex = 0;
//缓冲数据已全部读完,不需要再读
buffer->readable = 0;
return 0;
}
int main(int argc, char **argv) {
int listen_fd;
int i, maxfd;
struct Buffer *buffer[FD_INIT_SIZE];
for (i = 0; i < FD_INIT_SIZE; ++i) {
buffer[i] = alloc_Buffer();
}
listen_fd = tcp_nonblocking_server_listen(SERV_PORT); // 用 fcntl 将监听套接字设置为非阻塞
fd_set readset, writeset, exset;
FD_ZERO(&readset);
FD_ZERO(&writeset);
FD_ZERO(&exset);
while (1) {
maxfd = listen_fd;
FD_ZERO(&readset);
FD_ZERO(&writeset);
FD_ZERO(&exset);
// listener加入readset
FD_SET(listen_fd, &readset);
for (i = 0; i < FD_INIT_SIZE; ++i) {
if (buffer[i]->connect_fd > 0) {
if (buffer[i]->connect_fd > maxfd)
maxfd = buffer[i]->connect_fd;
FD_SET(buffer[i]->connect_fd, &readset);
if (buffer[i]->readable) {
FD_SET(buffer[i]->connect_fd, &writeset);
}
}
}
if (select(maxfd + 1, &readset, &writeset, &exset, NULL) < 0) {
// 用 select() 进行 I/O 事件分发处理
error(1, errno, "select() error");
}
if (FD_ISSET(listen_fd, &readset)) {
printf("listening socket readable\n");
sleep(5);
struct sockaddr_storage ss;
socklen_t slen = sizeof(ss);
int fd = accept(listen_fd, (struct sockaddr *) &ss, &slen); // 处理新的连接套接字,注意这里也把连接套接字设置为非阻塞的
if (fd < 0) {
error(1, errno, "accept failed");
} else if (fd > FD_INIT_SIZE) {
error(1, 0, "too many connections");
close(fd);
} else {
make_nonblocking(fd);
if (buffer[fd]->connect_fd == 0) {
buffer[fd]->connect_fd = fd;
} else {
error(1, 0, "too many connections");
}
}
}
for (i = 0; i < maxfd + 1; ++i) {
int r = 0;
if (i == listen_fd)
continue;
if (FD_ISSET(i, &readset)) {
// 在处理连接套接字上的 I/O 读写事件,这里抽象了一个 Buffer 对象,Buffer 对象用了 readIndex 和 writeIndex 分别表示当前缓冲的读写位置
r = onSocketRead(i, buffer[i]);
}
if (r == 0 && FD_ISSET(i, &writeset)) {
r = onSocketWrite(i, buffer[i]);
}
if (r) {
buffer[i]->connect_fd = 0;
close(i);
}
}
}
}
实验如下:
启动该server :
$./nonblockingserver
用多个 telnet client 连接该 server,可验证交互正常:
$telnet 127.0.0.1 43211
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
fasfasfasf
snfsnfsnfs
四、epoll()
非阻塞 I/O 加上 I/O 多路复用,已渐渐帮助在高性能网络编程此领域搭建了初步的基石。但是,离最终的目标还差那么一点,若说 I/O 多路复用帮打开了高性能网络编程的窗口,那么今天的主题——epoll,将为增添足够的动力。
select、poll、epoll 几种不同的 I/O 复用技术在面对不同文件描述符大小时的表现差异如下图:
- 明显看到,epoll 的性能是最好的,即使在多达 10000 个文件描述的情况下,其性能的下降和有 10 个文件描述符的情况相比,差别也不是很大。而随着文件描述符的增大,常规的 select() 和 poll() 性能逐渐变得很差。

epoll 可说是和 poll 非常相似的一种 I/O 多路复用技术,有些朋友将 epoll 归为异步 I/O,我觉得这是不正确的。
本质上 epoll 还是一种 I/O 多路复用技术, epoll 通过监控注册的多个描述字,来进行 I/O 事件的分发处理。不同于 poll 的是,epoll 不仅提供了默认的 level-triggered(条件触发)机制,还提供了性能更为强劲的 edge-triggered(边缘触发)机制。
用 epoll 进行网络程序的编写,需要三个步骤,分别是 epoll_create,epoll_ctl 和 epoll_wait。
4.1 epoll_create()
epoll_create()() 创建了一个 epoll 实例,从 Linux 2.6.8 开始,参数 size 被自动忽略,但是该值仍需要一个大于 0 的整数。
- 关于此参数 size,在一开始的 epoll_create 实现中,是用来告知内核期望监控的文件描述字大小,然后内核用这部分的信息来初始化内核数据结构,在新的实现中,此参数不再被需要,因为内核可动态分配需要的内核数据结构。只需要注意,每次将 size 设置成一个大于 0 的整数就可了。
此 epoll 实例被用来调用 epoll_ctl 和 epoll_wait,若此 epoll 实例不再需要,比如server 正常关机,需要调用 close()() 释放 epoll 实例,这样系统内核可回收 epoll 实例所分配用的内核资源。
int epoll_create(int size);
int epoll_create1(int flags); // epoll_create1() 的用法和 epoll_create() 基本一致
// 返回值: 若成功返回一个大于 0 的值,表示 epoll 实例;若返回 -1 表示出错
4.2 epoll_ctl()
创建完 epoll 实例之后,可通过调用 epoll_ctl 往此 epoll 实例增加或删除监控的事件。函数 epll_ctl 有 4 个入口参数。
- 第一个参数 epfd 是刚刚调用 epoll_create 创建的 epoll 实例描述字,可简单理解成是 epoll 句柄。
- 第二个参数表示增加还是删除一个监控事件,它有三个选项可供选择:
- EPOLL_CTL_ADD: 向 epoll 实例注册文件描述符对应的事件;
- EPOLL_CTL_DEL:向 epoll 实例删除文件描述符对应的事件;
- EPOLL_CTL_MOD: 修改文件描述符对应的事件。
- 第三个参数是注册的事件的文件描述符,比如一个监听套接字。
- 第四个参数表示的是注册的事件类型,并可在此结构体里设置用户需要的数据,其中最为常见的是用联合结构里的 fd 字段,表示事件所对应的文件描述符。
- 在前面介绍 poll 时已接触过基于 mask 的事件类型了,这里 epoll 仍旧用了同样的机制,重点看一下这几种事件类型:
- EPOLLIN:表示对应的文件描述字可读;
- EPOLLOUT:表示对应的文件描述字可写;
- EPOLLRDHUP:表示套接字的一端已关闭,或半关闭;
- EPOLLHUP:表示对应的文件描述字被挂起;
- EPOLLET:设置为 edge-triggered,默认为 level-triggered。
- 在前面介绍 poll 时已接触过基于 mask 的事件类型了,这里 epoll 仍旧用了同样的机制,重点看一下这几种事件类型:
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// 返回值: 若成功返回 0;若返回 -1 表示出错
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
4.3 epoll_wait()
epoll_wait() 类似之前的 poll() 和 select() ,调用者进程被挂起,在等待内核 I/O 事件的分发。
- 第一个参数是 epoll 实例描述字,即 epoll 句柄。
- 第二个参数返回给用户空间需要处理的 I/O 事件,这是一个数组,数组的大小由 epoll_wait 的返回值决定,此数组的每个元素都是一个需要待处理的 I/O 事件,其中 events 表示具体的事件类型,事件类型取值和 epoll_ctl 可设置的值一样,此 epoll_event 结构体里的 data 值就是在 epoll_ctl 那里设置的 data,即用户空间和内核空间调用时需要的数据。
- 第三个参数是一个大于 0 的整数,表示 epoll_wait 可返回的最大事件值。
- 第四个参数是 epoll_wait 阻塞调用的超时值,若此值设置为 -1,表示不超时;若设置为 0 则立即返回,即使没有任何 I/O 事件发生。
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
// 返回值: 成功返回的是一个大于 0 的数,表示事件的个数;返回 0 表示的是超时时间到;若出错返回 -1.
4.4 实战
下面把原先基于 poll 的 server 改造成基于 epoll 的:
#include "lib/common.h"
#define MAXEVENTS 128
char rot13_char(char c) {
if ((c >= 'a' && c <= 'm') || (c >= 'A' && c <= 'M'))
return c + 13;
else if ((c >= 'n' && c <= 'z') || (c >= 'N' && c <= 'Z'))
return c - 13;
else
return c;
}
int main(int argc, char **argv) {
int listen_fd, socket_fd;
int n, i;
int efd;
struct epoll_event event;
struct epoll_event *events;
listen_fd = tcp_nonblocking_server_listen(SERV_PORT);
efd = epoll_create1(0); // 创建一个 epoll 实例
if (efd == -1) {
error(1, errno, "epoll create failed");
}
event.data.fd = listen_fd; // 将监听套接字对应的 I/O 事件进行了注册,这样在有新的连接建立之后,就可感知到。注意这里用的是 edge-triggered(边缘触发)。
event.events = EPOLLIN | EPOLLET;
if (epoll_ctl(efd, EPOLL_CTL_ADD, listen_fd, &event) == -1) {
error(1, errno, "epoll_ctl add listen fd failed");
}
/* Buffer where events are returned */
events = calloc(MAXEVENTS, sizeof(event)); // 为返回的 event 数组分配了内存
while (1) {
// 主循环调用 epoll_wait 函数分发 I/O 事件
n = epoll_wait(efd, events, MAXEVENTS, -1); // 当 epoll_wait 成功返回时,通过遍历返回的 event 数组,就直接可知道发生的 I/O 事件
printf("epoll_wait wakeup\n");
for (i = 0; i < n; i++) {
if ((events[i].events & EPOLLERR) ||
(events[i].events & EPOLLHUP) ||
(!(events[i].events & EPOLLIN))) {
// 判断了各种错误情况
fprintf(stderr, "epoll error\n");
close(events[i].data.fd);
continue;
} else if (listen_fd == events[i].data.fd) {
// 监听套接字上有事件发生的情况下,调用 accept 获取已建立连接,并将该连接设置为非阻塞,再调用 epoll_ctl 把已连接套接字对应的可读事件注册到 epoll 实例中。这里用了 event_data 里面的 fd 字段,将连接套接字存储其中。
struct sockaddr_storage ss;
socklen_t slen = sizeof(ss);
int fd = accept(listen_fd, (struct sockaddr *) &ss, &slen);
if (fd < 0) {
error(1, errno, "accept failed");
} else {
make_nonblocking(fd);
event.data.fd = fd;
event.events = EPOLLIN | EPOLLET; //edge-triggered
if (epoll_ctl(efd, EPOLL_CTL_ADD, fd, &event) == -1) {
error(1, errno, "epoll_ctl add connection fd failed");
}
}
continue;
} else {
// 处理已连接套接字上的可读事件,读取字节流,编码后再回应给 client
socket_fd = events[i].data.fd;
printf("get event on socket fd == %d \n", socket_fd);
while (1) {
char buf[512];
if ((n = read(socket_fd, buf, sizeof(buf))) < 0) {
if (errno != EAGAIN) {
error(1, errno, "read error");
close(socket_fd);
}
break;
} else if (n == 0) {
close(socket_fd);
break;
} else {
for (i = 0; i < n; ++i) {
buf[i] = rot13_char(buf[i]);
}
if (write(socket_fd, buf, n) < 0) {
error(1, errno, "write error");
}
}
}
}
}
}
free(events);
close(listen_fd);
}
实验如下:
启动该server :
$./epoll01
epoll_wait wakeup
epoll_wait wakeup
epoll_wait wakeup
get event on socket fd == 6
epoll_wait wakeup
get event on socket fd == 5
epoll_wait wakeup
get event on socket fd == 5
epoll_wait wakeup
get event on socket fd == 6
epoll_wait wakeup
get event on socket fd == 6
epoll_wait wakeup
get event on socket fd == 6
epoll_wait wakeup
get event on socket fd == 5
再启动几个 telnet client,可看到有连接建立情况下,epoll_wait 迅速从挂起状态结束;并套接字上有数据可读时,epoll_wait 也迅速结束挂起状态,这时候通过 read 可读取套接字接收缓冲区上的数据。
$telnet 127.0.0.1 43211
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
fasfsafas
snfsfnsnf
^]
telnet> quit
Connection closed.
4.5 edge-triggered VS level-triggered
edge-triggered 是边缘触发,level-triggered 是条件触发。用如下程序来说明一下这两者之间的不同。
在这两个程序里,即使已连接套接字上有数据可读,也不调用 read() 去读,只是简单地打印出一句话。
第一个程序设置为 edge-triggered,即边缘触发。开启此server 程序,用 telnet 连接上,输入一些字符,看到,server 只从 epoll_wait 中苏醒过一次,就是第一次有数据可读时。
$./epoll02
epoll_wait wakeup
epoll_wait wakeup
get event on socket fd == 5
$telnet 127.0.0.1 43211
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
asfafas
第二个程序设置为 level-triggered,即条件触发。然后按照同样的步骤来一次,观察 server,这一次可看到,server 不断地从 epoll_wait 中苏醒,告诉有数据需要读取。
$./epoll03
epoll_wait wakeup
epoll_wait wakeup
get event on socket fd == 5
epoll_wait wakeup
get event on socket fd == 5
epoll_wait wakeup
get event on socket fd == 5
epoll_wait wakeup
get event on socket fd == 5
...
这就是两者的区别,条件触发的意思是只要满足事件的条件,比如有数据需要读,就一直不断地把此事件传递给用户;而边缘触发的意思是只有第一次满足条件时才触发,之后就不会再传递同样的事件了。
一般认为,边缘触发的效率比条件触发的效率要高,这一点也是 epoll 的杀手锏之一。
早在 Linux 实现 epoll 之前,Windows 系统就已在 1994 年引入了 IOCP,这是一个异步 I/O 模型,用来支持高并发的网络 I/O,而著名的 FreeBSD 在 2000 年引入了 Kqueue——一个 I/O 事件分发框架。2002 年,epoll 最终在 Linux 2.5.44 中首次出现,在 2.6 中趋于稳定,为 Linux 的高性能网络 I/O 画上了一段句号。epoll 通过改进的接口设计,避免了用户态 - 内核态频繁的数据拷贝,大大提高了系统性能。
五、阻塞IO+进程模型
pid_t fork(void)
// 返回:在子进程中为 0,在父进程中为子进程 ID,若出错则为 -1
if(fork() == 0){
do_child_process(); // 子进程执行代码
}else{
do_parent_process(); // 父进程执行代码
}
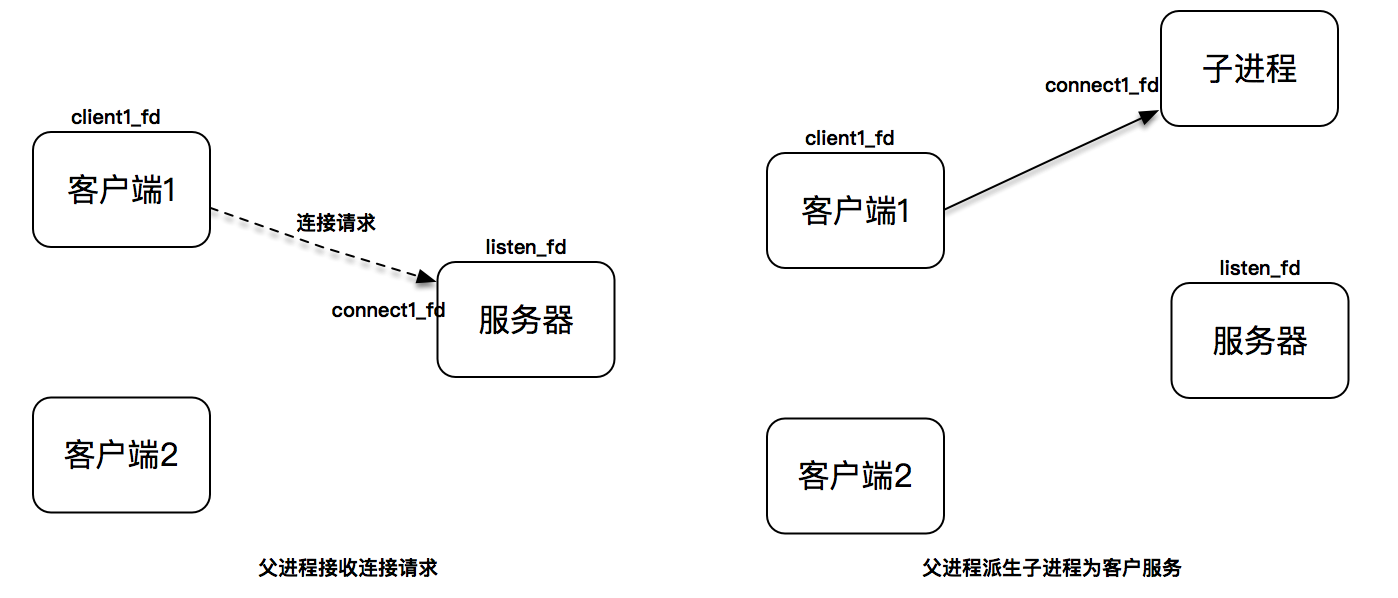
假设有两个客户端,server 初始监听在套接字 lisnted_fd 上。当第一个客户端发起连接请求,连接建立后产生出连接套接字,此时,父进程派生出一个子进程,在子进程中,用连接套接字和客户端通信,因此子进程不需要关心监听套接字,只需要关心连接套接字;父进程则相反,将客户服务交给子进程来处理,因此父进程不需要关心连接套接字,只需要关心监听套接字。
下图描述了从连接请求到连接建立,父进程派生子进程为客户服务:
假设父进程之后又接收了新的连接请求,从 accept 调用返回新的已连接套接字,父进程又派生出另一个子进程,此子进程用第二个已连接套接字为客户端服务。这张图同样描述了此过程:
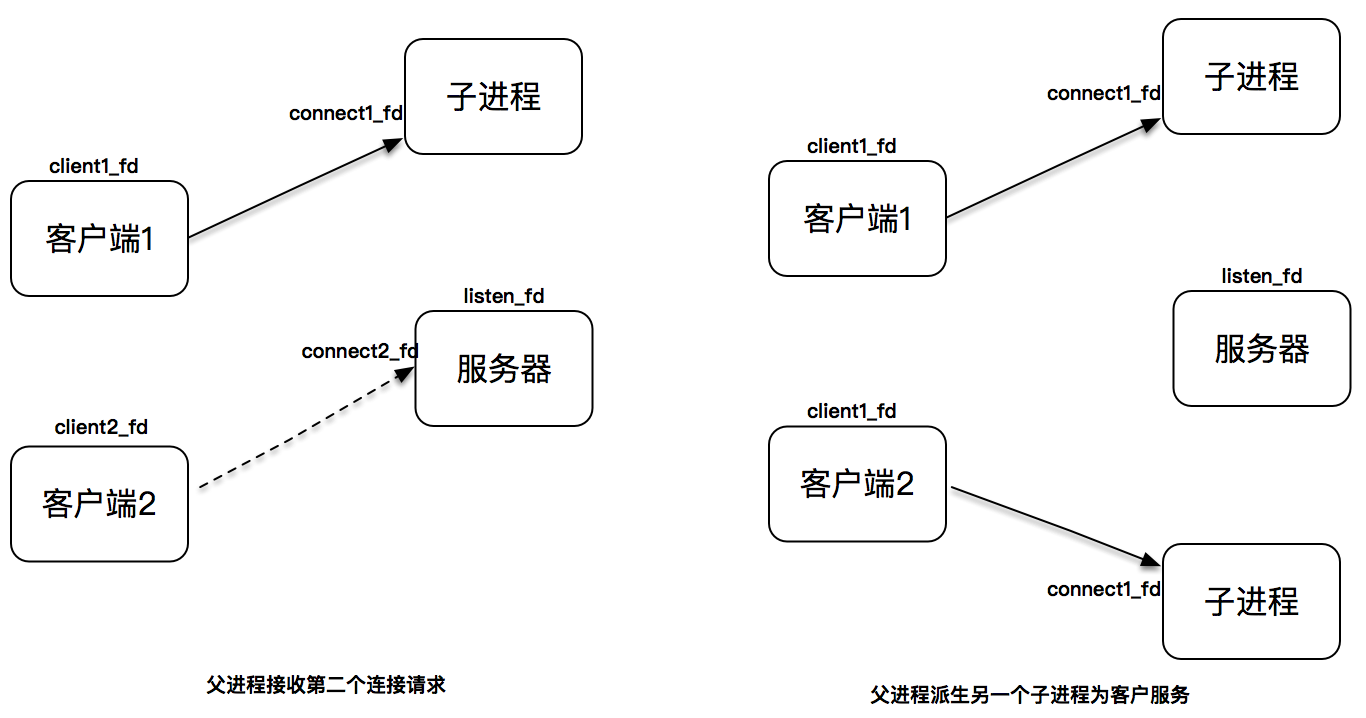
现在,server 的父进程继续监听在套接字上,等待新的客户连接到来;两个子进程分别用两个不同的连接套接字为两个客户服务。
server 端程序如下:
#include "lib/common.h"
#define MAX_LINE 4096
char rot13_char(char c) {
if ((c >= 'a' && c <= 'm') || (c >= 'A' && c <= 'M'))
return c + 13;
else if ((c >= 'n' && c <= 'z') || (c >= 'N' && c <= 'Z'))
return c - 13;
else
return c;
}
void child_run(int fd) {
char outbuf[MAX_LINE + 1];
size_t outbuf_used = 0;
ssize_t result;
while (1) {
char ch; // 每次读一个字符
result = recv(fd, &ch, 1, 0);
if (result == 0) {
break;
} else if (result == -1) {
perror("read");
break;
}
if (outbuf_used < sizeof(outbuf)) {
outbuf[outbuf_used++] = rot13_char(ch);
}
if (ch == '\n') {
// 若是回车就发送。此回显方式比较有“交互感”
send(fd, outbuf, outbuf_used, 0); // send(int sockfd, const void *buf, size_t len, int flags); 即向fd,发outbuf指针处,长度是outbuf_used,的内容
outbuf_used = 0; // 发完,则下标复位到0,继续\n后字符的监听
continue;
}
}
}
void sigchld_handler(int sig) {
while (waitpid(-1, 0, WNOHANG) > 0); // 在一个循环体内调用了 waitpid 函数,以便回收所有已终止的子进程。这里选项 WNOHANG 用来告诉内核,即使还有未终止的子进程也不要阻塞在 waitpid 上。注意这里不可用 wait,因为 wait 函数在有未终止子进程的情况下,无法不阻塞。
return;
}
int main(int c, char **v) {
int listener_fd = tcp_server_listen(SERV_PORT);
signal(SIGCHLD, sigchld_handler); // 注册了一个信号处理函数,用来回收子进程资源
while (1) {
struct sockaddr_storage ss;
socklen_t slen = sizeof(ss);
int fd = accept(listener_fd, (struct sockaddr *) &ss, &slen);
if (fd < 0) {
error(1, errno, "accept failed");
exit(1);
}
if (fork() == 0) {
// 子进程
close(listener_fd); // 从父进程派生出的子进程,同时也会复制一份描述字,即,连接套接字和监听套接字的引用计数都会被加 1,而调用 close 函数则会对引用计数进行减 1 操作,这样在套接字引用计数到 0 时,才可将套接字资源回收。所以,这里的 close 函数非常重要,缺少了它们,就会引起server 资源的泄露。
child_run(fd);
exit(0);
} else {
// 父进程
close(fd);
}
}
return 0;
}
运行效果如下:
# server
./fork01
# telnet client1
$telnet 127.0.0.1 43211
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
afasfa
nsnfsn
]
telnet> quit
Connection closed.
# telnet client2
$telnet 127.0.0.1 43211
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
agasgasg
ntnftnft
]
telnet> quit
Connection closed.
# client 退出,server 也在正常工作,此时若再通过 telnet 建立新的连接,client 和 server 的数据传输也会正常进行。至此,构建了一个完整的 server ,可并发处理多个不同的 client 连接,互不干扰。
六、阻塞IO+线程模型
线程(thread)是运行在进程中的一个“逻辑流”,现代操作系统都允许在单进程中运行多个线程。线程由操作系统内核管理。每个线程都有自己的上下文(context),包括一个可唯一标识线程的 ID(thread ID,或叫 tid)、栈、程序计数器、寄存器等。在同一个进程中,所有的线程共享该进程的整个虚拟地址空间,包括代码、数据、堆、共享库等。
在同一个进程下,线程上下文切换的开销要比进程小得多。怎么理解线程上下文呢?的代码被 CPU 执行时,是需要一些数据支撑的,比如程序计数器告诉 CPU 代码执行到哪里了,寄存器里存了当前计算的一些中间值,内存里放置了一些当前用到的变量等,从一个计算场景,切换到另外一个计算场景,程序计数器、寄存器等这些值重新载入新场景的值,就是线程的上下文切换。
5.1 POSIX 线程模型
POSIX 线程是现代 UNIX 系统提供的处理线程的标准接口。POSIX 定义的线程函数大约有 60 多个,这些函数可帮助创建线程、回收线程。接下来先看一个简单的例子程序。
int another_shared = 0;
void thread_run(void *arg) {
int *calculator = (int *) arg;
printf("hello, world, tid == %d \n", pthread_self());
for (int i = 0; i < 1000; i++) {
*calculator += 1;
another_shared += 1;
}
}
int main(int c, char **v) {
int calculator;
pthread_t tid1;
pthread_t tid2;
pthread_create(&tid1, NULL, thread_run, &calculator); // 创建了两个子线程: 每个子线程都在对calculator 和 another_shared 这两个共享变量做计算
pthread_create(&tid2, NULL, thread_run, &calculator);
pthread_join(tid1, NULL); // 等待这两个子线程处理完毕之后终止
pthread_join(tid2, NULL);
printf("calculator is %d \n", calculator);
printf("another_shared is %d \n", another_shared);
}
// 运行此程序,很幸运,计算的结果是正确的:
$./thread-helloworld
hello, world, tid == 125607936
hello, world, tid == 126144512
calculator is 2000
another_shared is 2000
5.1.1 pthread_create()
每个线程都有一个线程 ID(tid)唯一来标识,其数据类型为 pthread_t,一般是 unsigned int。若创建线程成功,tid 就返回正确的线程 ID。
每个线程都会有很多属性,比如优先级、是否应该成为一个守护进程等,这些值可通过 pthread_attr_t 来描述,一般不会特殊设置,可直接指定此参数为 NULL。
第三个参数为新线程的入口函数,该函数可接收一个参数 arg,类型为指针,若想给线程入口函数传多个值,那么需要把这些值包装成一个结构体,再把此结构体的地址作为 pthread_create 的第四个参数,在线程入口函数内,再将该地址转为该结构体的指针对象。
int pthread_create(pthread_t *tid, const pthread_attr_t *attr,
void *(*func)(void *), void *arg);
// 返回:若成功则为 0,若出错则为正的 Exxx 值
// 新线程的入口函数内,可执行 pthread_self 函数返回线程 tid
pthread_t pthread_self(void)
5.1.2 终止线程
终止一个线程最直接的方法是在父线程内调用以下函数:
- 当调用此函数之后,父线程会等待其他
所有的子线程终止,之后父线程自己终止。 - 当然,若一个子线程入口函数直接退出了,那么子线程也就自然终止了。所以,绝大多数的子线程执行体都是一个无限循环。
void pthread_exit(void *status)
也可通过调用 pthread_cancel 来主动终止一个子线程,和 pthread_exit 不同的是,它可指定某个子线程终止:
int pthread_cancel(pthread_t tid)
5.1.3 回收已终止线程的资源
当调用 pthread_join 时,主线程会阻塞,直到对应 tid 的子线程自然终止。和 pthread_cancel 不同的是,它不会强迫子线程终止。
int pthread_join(pthread_t tid, void ** thread_return)
5.1.4 分离线程
一个线程的重要属性是可结合的,或是分离的。
- 一个可结合的线程是能够被其他线程杀死和回收资源的;默认的属性就是可结合的。
- 而一个分离的线程不能被其他线程杀死或回收资源。
可通过调用 pthread_detach 函数分离一个线程:
int pthread_detach(pthread_t tid)
在高并发的例子里,每个连接都由一个线程单独处理,在这种情况下,server 程序并不需要对每个子线程进行终止,此话,每个子线程可在入口函数开始的地方,把自己设置为分离的,这样就能在它终止后自动回收相关的线程资源了,就不需要调用 pthread_join 函数了。
5.2 示例
接下来,改造一下 server。的目标是这样:每次有新的连接到达后,创建一个新线程,而不是用进程来处理它。
#include "lib/common.h"
extern void loop_echo(int);
void thread_run(void *arg) {
pthread_detach(pthread_self()); // 将子线程转变为分离的,也就意味着子线程独自负责线程资源回收
int fd = (int) arg; // 强制将指针转变为描述符数据,和前面将描述字转换为 void * 指针对应
loop_echo(fd);
}
int main(int c, char **v) {
int listener_fd = tcp_server_listen(SERV_PORT);
pthread_t tid;
while (1) {
struct sockaddr_storage ss;
socklen_t slen = sizeof(ss);
int fd = accept(listener_fd, (struct sockaddr *) &ss, &slen); // 阻塞调用在 accept 上,一旦有新连接建立,阻塞调用返回,调用 pthread_create 创建一个子线程来处理此连接。
if (fd < 0) {
error(1, errno, "accept failed");
} else {
pthread_create(&tid, NULL, &thread_run, (void *) fd); // 传的是一个指针,但是此指针里存放的并不是一个地址,而是连接描述符的数值
}
}
return 0;
}
char rot13_char(char c) {
if ((c >= 'a' && c <= 'm') || (c >= 'A' && c <= 'M'))
return c + 13;
else if ((c >= 'n' && c <= 'z') || (c >= 'N' && c <= 'Z'))
return c - 13;
else
return c;
}
void loop_echo(int fd) {
// 接收客户端的数据之后,再编码回送出去
char outbuf[MAX_LINE + 1];
size_t outbuf_used = 0;
ssize_t result;
while (1) {
char ch;
result = recv(fd, &ch, 1, 0);
// 断开连接或出错
if (result == 0) {
break;
} else if (result == -1) {
error(1, errno, "read error");
break;
}
if (outbuf_used < sizeof(outbuf)) {
outbuf[outbuf_used++] = rot13_char(ch);
}
if (ch == '\n') {
send(fd, outbuf, outbuf_used, 0);
outbuf_used = 0;
continue;
}
}
}
运行此程序之后,开启多个 telnet client,可看到此 server 可处理多个并发连接并回送数据。单独一个连接退出也不会影响其他连接的数据收发。
$telnet 127.0.0.1 43211
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
aaa
nnn
^]
telnet> quit
Connection closed.
5.3 线程池
上面的server 虽然可正常工作,不过它有一个缺点,那就是若并发连接过多,就会引起线程的频繁创建和销毁。虽然线程切换的上下文开销不大,但是线程创建和销毁的开销却是不小的。
可用预创建线程池的方式来进行优化:在server 启动时,可先按照固定大小预创建出多个线程,当有新连接建立时,往连接字队列里放置此新连接描述字,线程池里的线程负责从连接字队列里取出连接描述字进行处理。
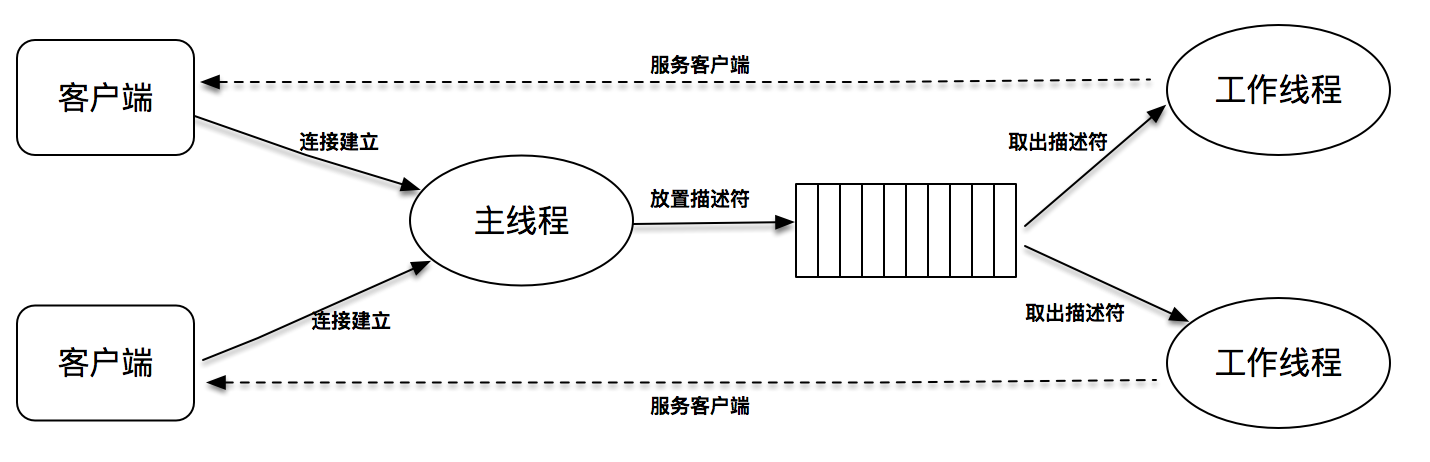
此程序的关键是连接字队列的设计,因为这里既有往此队列里放置描述符的操作,也有从此队列里取出描述符的操作。
对此,需要引入两个重要的概念,一个是锁 mutex,一个是条件变量 condition。锁很好理解,加锁的意思就是其他线程不能进入;条件变量则是在多个线程需要交互的情况下,用来线程间同步的原语。
// 定义一个队列
typedef struct {
int number; // 队列里的描述字最大个数
int *fd; // 这是一个数组指针
int front; // 当前队列的头位置
int rear; // 当前队列的尾位置
pthread_mutex_t mutex; // 锁
pthread_cond_t cond; // 条件变量
} block_queue;
// 初始化队列
void block_queue_init(block_queue *blockQueue, int number) {
blockQueue->number = number;
blockQueue->fd = calloc(number, sizeof(int));
blockQueue->front = blockQueue->rear = 0;
pthread_mutex_init(&blockQueue->mutex, NULL);
pthread_cond_init(&blockQueue->cond, NULL);
}
// 往队列里放置一个描述字 fd
void block_queue_push(block_queue *blockQueue, int fd) {
// 一定要先加锁,因为有多个线程需要读写队列
pthread_mutex_lock(&blockQueue->mutex);
// 将描述字放到队列尾的位置
blockQueue->fd[blockQueue->rear] = fd;
// 若已到最后,重置尾的位置
if (++blockQueue->rear == blockQueue->number) {
blockQueue->rear = 0;
}
printf("push fd %d", fd);
// 主线程通知其他等待读的工作线程,有新的连接字等待处理
pthread_cond_signal(&blockQueue->cond);
// 解锁
pthread_mutex_unlock(&blockQueue->mutex);
}
// 从队列里读出描述字进行处理
int block_queue_pop(block_queue *blockQueue) {
// 加锁
pthread_mutex_lock(&blockQueue->mutex);
// 判断队列里没有新的连接字可处理,就一直条件等待,直到有新的连接字入队列
while (blockQueue->front == blockQueue->rear)
pthread_cond_wait(&blockQueue->cond, &blockQueue->mutex); // 调用 pthread_cond_wait,所有的工作线程等待有新的描述字可达
// 取出队列头的连接字
int fd = blockQueue->fd[blockQueue->front];
// 若已到最后,重置头的位置
if (++blockQueue->front == blockQueue->number) {
blockQueue->front = 0;
}
printf("pop fd %d", fd);
// 解锁
pthread_mutex_unlock(&blockQueue->mutex);
// 返回连接字
return fd;
}
server 端如下:
void thread_run(void *arg) {
pthread_t tid = pthread_self();
pthread_detach(tid);
block_queue *blockQueue = (block_queue *) arg;
while (1) {
// 工作线程的主循环: 从描述字队列中取出描述字,对此连接进行服务处理
int fd = block_queue_pop(blockQueue);
printf("get fd in thread, fd==%d, tid == %d", fd, tid);
loop_echo(fd);
}
}
int main(int c, char **v) {
int listener_fd = tcp_server_listen(SERV_PORT);
block_queue blockQueue;
block_queue_init(&blockQueue, BLOCK_QUEUE_SIZE);
thread_array = calloc(THREAD_NUMBER, sizeof(Thread));
int i;
for (i = 0; i < THREAD_NUMBER; i++) {
pthread_create(&(thread_array[i].thread_tid), NULL, &thread_run, (void *) &blockQueue);
}
while (1) {
struct sockaddr_storage ss;
socklen_t slen = sizeof(ss);
int fd = accept(listener_fd, (struct sockaddr *) &ss, &slen);
if (fd < 0) {
error(1, errno, "accept failed");
} else {
// 在新连接建立后,将连接描述字加入到队列中
block_queue_push(&blockQueue, fd);
}
}
return 0;
}
运行此程序之后,开启多个 telnet client ,可看到此server 程序可正常处理多个并发连接并回显:
$telnet 127.0.0.1 43211
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
aaa
nnn
^]
telnet> quit
Connection closed.
和前面的程序相比,线程创建和销毁的开销大大降低,但因为线程池大小固定,又因为用了阻塞套接字,肯定会出现有连接得不到及时服务的场景。此问题的解决还是要回到我在开篇词里提到的方案上来,多路 I/O 复用加上线程来处理,仅仅用阻塞 I/O 模型和线程是无法达到极致的高并发处理能力。
六、IO多路复用+线程:用 poll 单线程处理所有 IO 事件
6.1 事件驱动
事件驱动的好处是占用资源少,效率高,可扩展性强,是支持高性能高并发的不二之选。
若你熟悉 GUI 编程的话,你就会知道,GUI 设定了一系列的控件,如 Button、Label、文本框等,当设计基于控件的程序时,一般都会给 Button 的点击安排一个函数,类似这样:
// 按钮点击的事件处理
void onButtonClick(){
}
此设计的思想是,一个无限循环的事件分发线程在后台运行,一旦用户在界面上产生了某种操作,如点击了某个 Button,或点击了某个文本框,一个事件会被产生并放置到事件队列中,此事件会有一个类似前面的 onButtonClick 回调函数。事件分发线程的任务,就是为每个发生的事件找到对应的事件回调函数并执行它。这样,一个基于事件驱动的 GUI 程序就可完美地工作了。
通过用 poll、epoll 等 I/O 分发技术,可设计出基于套接字的事件驱动程序,从而满足高性能、高并发的需求。事件驱动模型,也被叫做反应堆模型(reactor),或是 Event loop 模型。此模型的核心有两点。
- 第一,它存在一个无限循环的事件分发线程,或叫做 reactor 线程、Event loop 线程。此事件分发线程的背后,就是 poll、epoll 等 I/O 分发技术的用。
- 第二,所有的 I/O 操作都可抽象成事件,每个事件必须有回调函数来处理。acceptor 上有连接建立成功、已连接套接字上发送缓冲区空出可写、通信管道 pipe 上有数据可读,这些都是一个个事件,通过事件分发,这些事件都可一一被检测,并调用对应的回调函数加以处理。
6.2 几种 I/O 模型和线程模型设计
任何一个网络程序,所做的事情可总结成下面几种:
- read:从套接字收取数据;
- decode:对收到的数据进行解析;
- compute:根据解析之后的内容,进行计算和处理;
- encode:将处理之后的结果,按照约定的格式进行编码;
- send:最后,通过套接字把结果发送出去。
6.2.1 fork
用 fork 来创建子进程,为每个到达的客户连接服务。文稿中的这张图很好地解释了此设计模式,可想而知的是,随着客户数的变多,fork 的子进程也越来越多,即使客户和server 之间的交互比较少,此子进程也不能被销毁,一直需要存在。用 fork 的方式处理非常简单,它的缺点是处理效率不高,fork 子进程的开销太大。
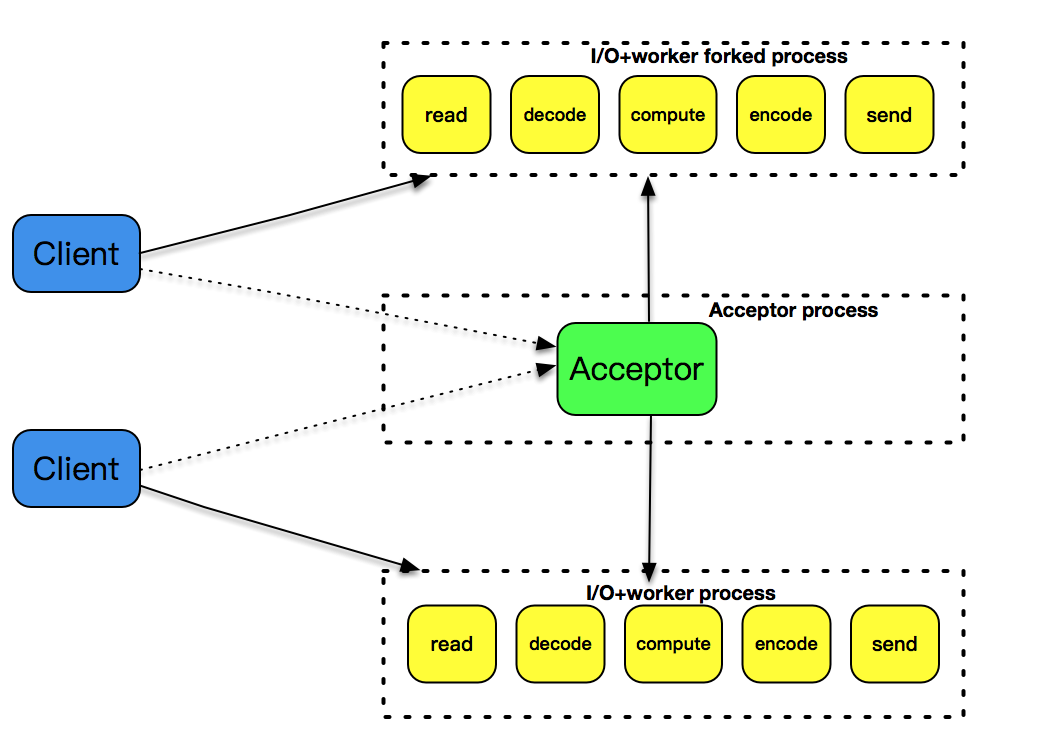
6.2.2 pthread
用 pthread_create 创建子线程,因为线程是比进程更轻量级的执行单位,所以它的效率相比 fork 的方式,有一定的提高。但是,每次创建一个线程的开销仍然是不小的,因此,引入了线程池的概念,预先创建出一个线程池,在每次新连接达到时,从线程池挑选出一个线程为之服务,很好地解决了线程创建的开销。但是,此模式还是没有解决空闲连接占用资源的问题,若一个连接在一定时间内没有数据交互,此连接还是要占用一定的线程资源,直到此连接消亡为止。
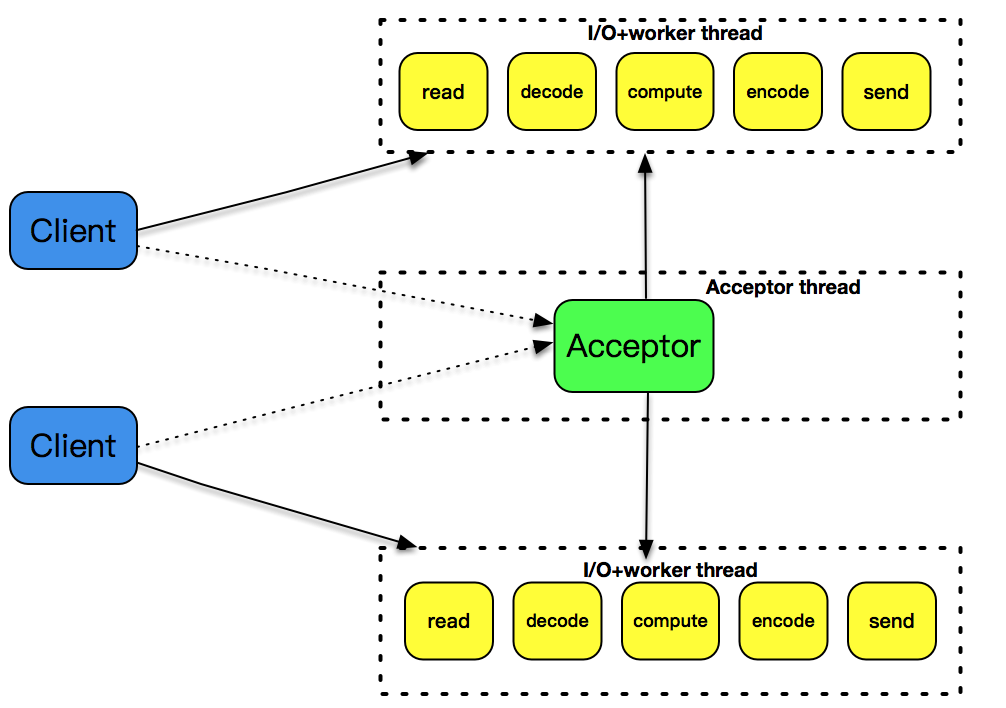
6.2.3 single reactor thread
事件驱动模式是解决高性能、高并发比较好的一种模式。为什么呢?
因为这种模式是符合大规模生产的需求的。的生活中遍地都是类似的模式。比如你去咖啡店喝咖啡,你点了一杯咖啡在一旁喝着,服务员也不会管你,等你有续杯需求时,再去和服务员提(触发事件), 服务员满足了你的需求,你就继续可喝着咖啡玩手机。整个柜台的服务方式就是一个事件驱动的方式。
我在文稿中放了一张图解释了这一讲的设计模式。一个 reactor 线程上同时负责分发 acceptor 的事件、已连接套接字的 I/O 事件。
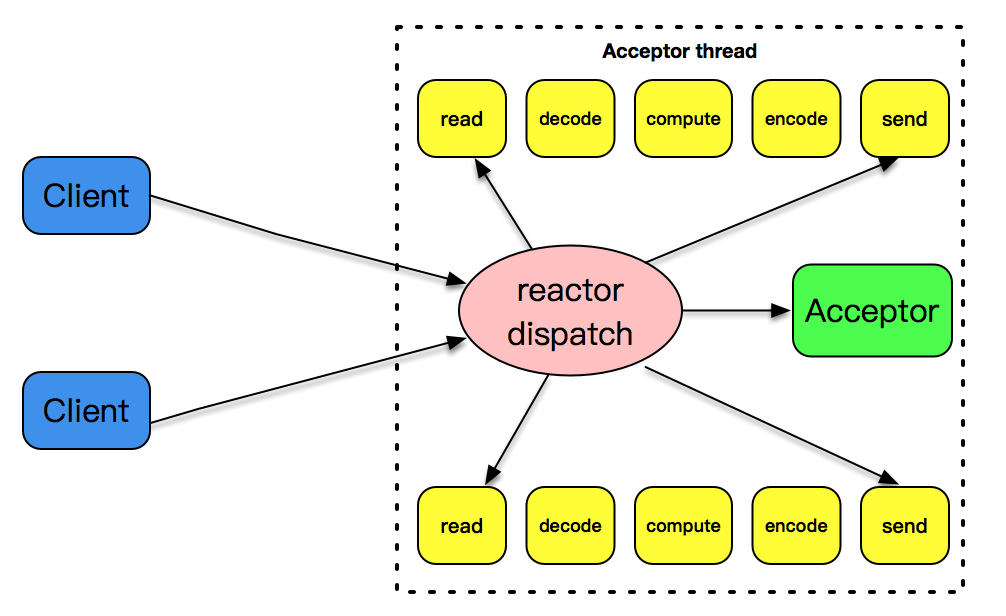
6.2.4 single reactor thread + worker threads
但是上述的设计模式有一个问题,和 I/O 事件处理相比,应用程序的业务逻辑处理是比较耗时的,比如 XML 文件的解析、数据库记录的查找、文件资料的读取和传输、计算型工作的处理等,这些工作相对而言比较独立,它们会拖慢整个反应堆模式的执行效率。
所以,将这些 decode、compute、enode 型工作放置到另外的线程池中,和反应堆线程解耦,是一个比较明智的选择。我在文稿中放置了此一张图。反应堆线程只负责处理 I/O 相关的工作,业务逻辑相关的工作都被裁剪成一个一个的小任务,放到线程池里由空闲的线程来执行。当结果完成后,再交给反应堆线程,由反应堆线程通过套接字将结果发送出去。
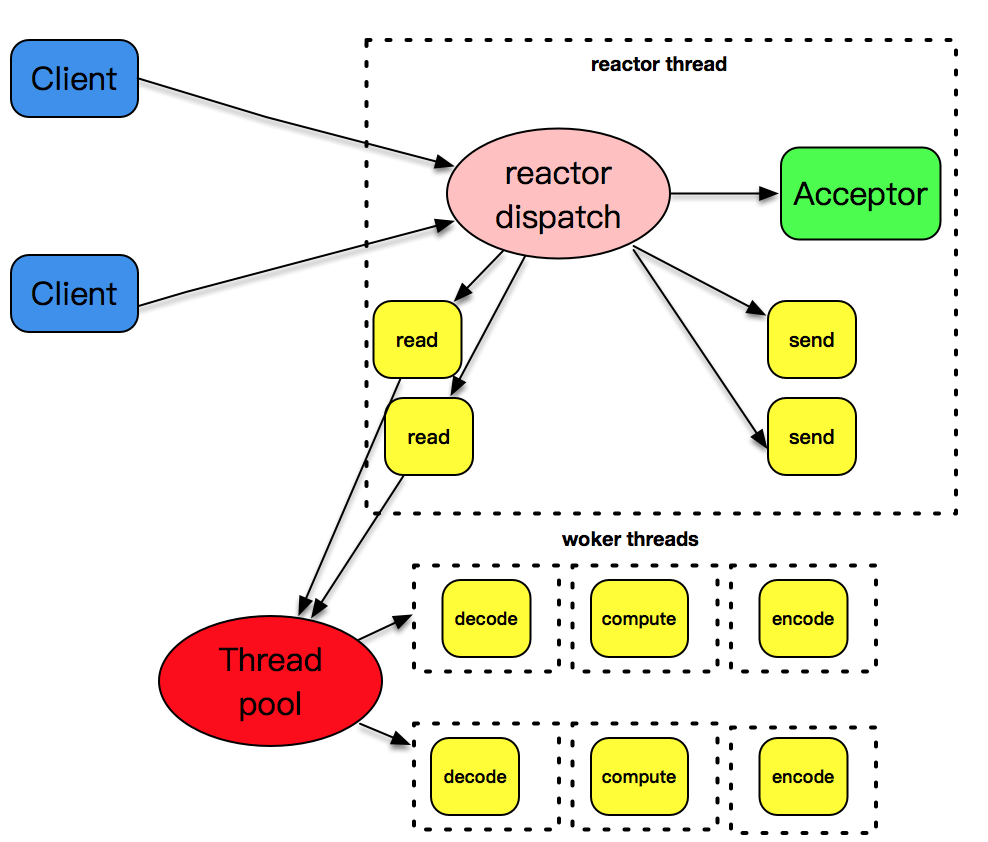
server 示例:
#include <lib/acceptor.h>
#include "lib/common.h"
#include "lib/event_loop.h"
#include "lib/tcp_server.h"
char rot13_char(char c) {
if ((c >= 'a' && c <= 'm') || (c >= 'A' && c <= 'M'))
return c + 13;
else if ((c >= 'n' && c <= 'z') || (c >= 'N' && c <= 'Z'))
return c - 13;
else
return c;
}
// 连接建立之后的 callback
int onConnectionCompleted(struct tcp_connection *tcpConnection) {
printf("connection completed\n");
return 0;
}
// 数据读到 buffer 之后的 callback
int onMessage(struct buffer *input, struct tcp_connection *tcpConnection) {
printf("get message from tcp connection %s\n", tcpConnection->name);
printf("%s", input->data);
struct buffer *output = buffer_new();
int size = buffer_readable_size(input);
for (int i = 0; i < size; i++) {
buffer_append_char(output, rot13_char(buffer_read_char(input)));
}
tcp_connection_send_buffer(tcpConnection, output);
return 0;
}
// 数据通过 buffer 写完之后的 callback
int onWriteCompleted(struct tcp_connection *tcpConnection) {
printf("write completed\n");
return 0;
}
// 连接关闭之后的 callback
int onConnectionClosed(struct tcp_connection *tcpConnection) {
printf("connection closed\n");
return 0;
}
int main(int c, char **v) {
// 主线程 event_loop
struct event_loop *eventLoop = event_loop_init(); // 创建了一个 event_loop,即 reactor 对象,此 event_loop 和线程相关联,每个 event_loop 在线程里执行的是一个无限循环,以便完成事件的分发
// 初始化 acceptor, 用来监听在某个端口上
struct acceptor *acceptor = acceptor_init(SERV_PORT);
// 初始 tcp_server,可指定线程数目,若线程是 0,就只有一个线程,既负责 acceptor,也负责 I/O
// 这里比较重要的是传入了几个回调函数,分别对应了连接建立完成、数据读取完成、数据发送完成、连接关闭完成几种操作,通过回调函数,让业务程序可聚焦在业务层开发。
struct TCPserver *tcpServer = tcp_server_init(eventLoop, acceptor, onConnectionCompleted, onMessage,
onWriteCompleted, onConnectionClosed, 0);
tcp_server_start(tcpServer); // 开启监听
// main thread for acceptor
event_loop_run(eventLoop); // 运行 event_loop 无限循环,等待 acceptor 上有连接建立、新连接上有数据可读
}
运行此server 程序,开启两个 telnet client,看到 server 的输出如下:这里自始至终都只有一个 main thread 在工作,可见,单线程的 reactor 处理多个连接时也可表现良好。
$./poll-server-onethread
[msg] set poll as dispatcher
[msg] add channel fd == 4, main thread
[msg] poll added channel fd==4
[msg] add channel fd == 5, main thread
[msg] poll added channel fd==5
[msg] event loop run, main thread
[msg] get message channel i==1, fd==5
[msg] activate channel fd == 5, revents=2, main thread
[msg] new connection established, socket == 6
connection completed
[msg] add channel fd == 6, main thread
[msg] poll added channel fd==6
[msg] get message channel i==2, fd==6
[msg] activate channel fd == 6, revents=2, main thread
get message from tcp connection connection-6
afadsfaf
[msg] get message channel i==2, fd==6
[msg] activate channel fd == 6, revents=2, main thread
get message from tcp connection connection-6
afadsfaf
fdafasf
[msg] get message channel i==1, fd==5
[msg] activate channel fd == 5, revents=2, main thread
[msg] new connection established, socket == 7
connection completed
[msg] add channel fd == 7, main thread
[msg] poll added channel fd==7
[msg] get message channel i==3, fd==7
[msg] activate channel fd == 7, revents=2, main thread
get message from tcp connection connection-7
sfasggwqe
[msg] get message channel i==3, fd==7
[msg] activate channel fd == 7, revents=2, main thread
[msg] poll delete channel fd==7
connection closed
[msg] get message channel i==2, fd==6
[msg] activate channel fd == 6, revents=2, main thread
[msg] poll delete channel fd==6
connection closed
6.2.5 主从 reactor 模式
前文引入了 reactor 反应堆模式,并让 reactor 反应堆同时分发 Acceptor 上的连接建立事件和已建立连接的 I/O 事件。
这种模式,在发起连接请求的客户端非常多的情况下,有一个地方是有问题的,那就是单 reactor 线程既分发连接建立,又分发已建立连接的 I/O,有点忙不过来,在实战中的表现可能就是客户端连接成功率偏低。
再者,新的硬件技术不断发展,多核多路 CPU 已得到极大的应用,单 reactor 反应堆模式看着大把的 CPU 资源却不用,有点可惜。
这一讲就将 acceptor 上的连接建立事件和已建立连接的 I/O 事件分离,形成所谓的主 - 从 reactor 模式。
主 - 从此模式的核心思想是,主反应堆线程只负责分发 Acceptor 连接建立,已连接套接字上的 I/O 事件交给 sub-reactor 负责分发。其中 sub-reactor 的数量,可根据 CPU 的核数来灵活设置。
比如一个四核 CPU,可设置 sub-reactor 为 4。相当于有 4 个身手不凡的反应堆线程同时在工作,这大大增强了 I/O 分发处理的效率。而且,同一个套接字事件分发只会出现在一个反应堆线程中,这会大大减少并发处理的锁开销。
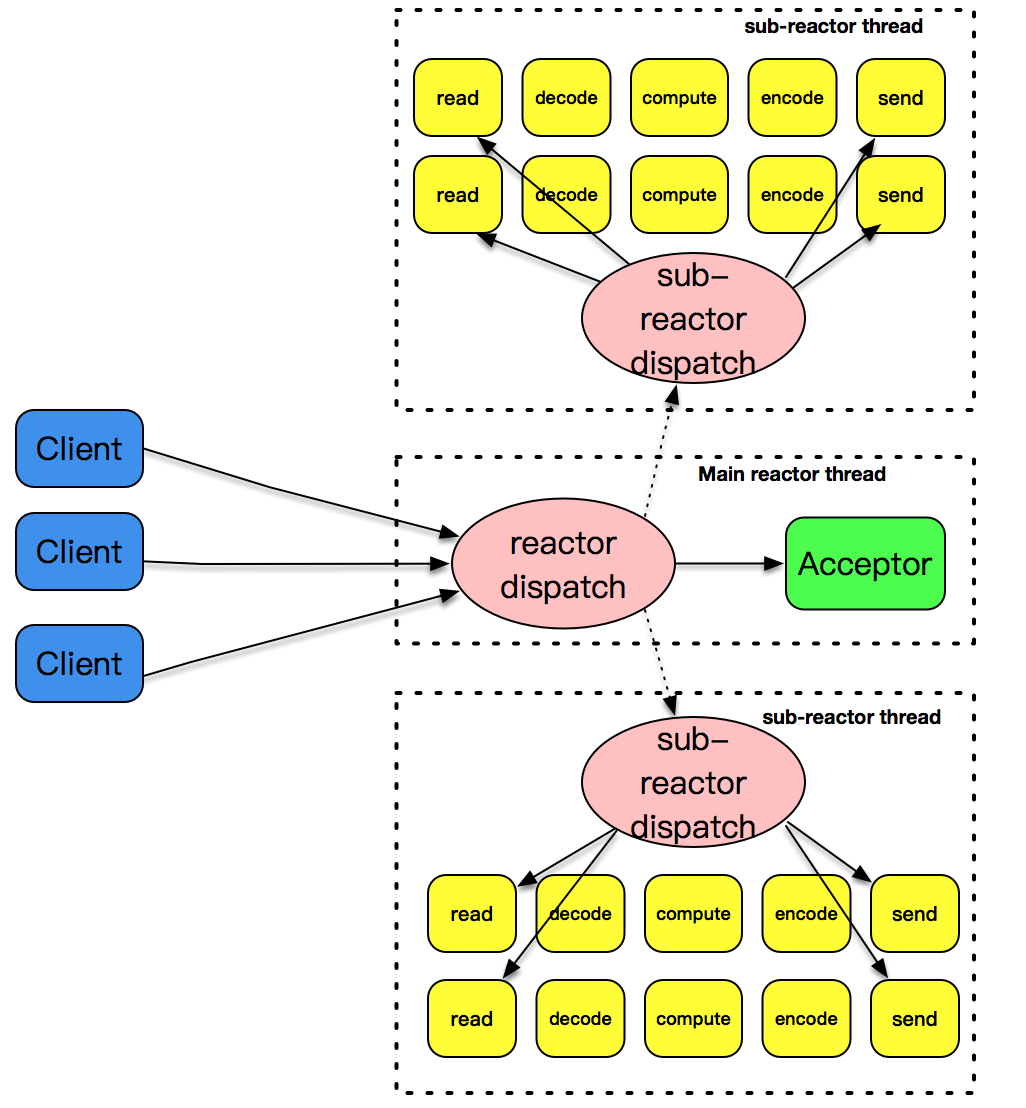
上图中,的主反应堆线程一直在感知连接建立的事件,若有连接成功建立,主反应堆线程通过 accept() 获取已连接套接字,接下来会按照一定的算法选取一个从反应堆线程,并把已连接套接字加入到选择好的从反应堆线程中。
主反应堆线程唯一的工作,就是调用 accept 获取已连接套接字,以及将已连接套接字加入到从反应堆线程中。不过,这里还有一个小问题,主反应堆线程和从反应堆线程,是两个不同的线程,如何把已连接套接字加入到另外一个线程中呢?更令人沮丧的是,此时从反应堆线程或许处于事件分发的无限循环之中,在这种情况下应该怎么办呢?
6.2.6 主从 reactor + worker threads 模式
若说主 - 从 reactor 模式解决了 I/O 分发的高效率问题,那么 work threads 就解决了业务逻辑和 I/O 分发之间的耦合问题。把这两个策略组装在一起,就是实战中普遍采用的模式。大名鼎鼎的 Netty,就是把这种模式发挥到极致的一种实现。不过要注意 Netty 里面提到的 worker 线程,其实就是这里说的从 reactor 线程,并不是处理具体业务逻辑的 worker 线程。
下面贴的一段代码就是常见的 Netty 初始化代码,这里 Boss Group 就是 acceptor 主反应堆,workerGroup 就是从反应堆。而处理业务逻辑的线程,通常都是通过用 Netty 的程序开发者进行设计和定制,一般来说,业务逻辑线程需要从 workerGroup 线程中分离,以便支持更高的并发度。
public final class TelnetServer {
static final int PORT = Integer.parseInt(System.getProperty("port", SSL ? "8992" : "8023"));
public static void main(String[] args) throws Exception {
// 产生一个 reactor 线程,只负责 accetpor 的对应处理
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
// 产生一个 reactor 线程,负责处理已连接套接字的 I/O 事件分发
EventLoopGroup workerGroup = new NioEventLoopGroup(1);
try {
// 标准的 Netty 初始,通过 serverbootstrap 完成线程池、channel 以及对应的 handler 设置,注意这里讲 bossGroup 和 workerGroup 作为参数设置
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.handler(new LoggingHandler(LogLevel.INFO))
.childHandler(new TelnetServerInitializer(sslCtx));
// 开启两个 reactor 线程无限循环处理
b.bind(PORT).sync().channel().closeFuture().sync();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
}
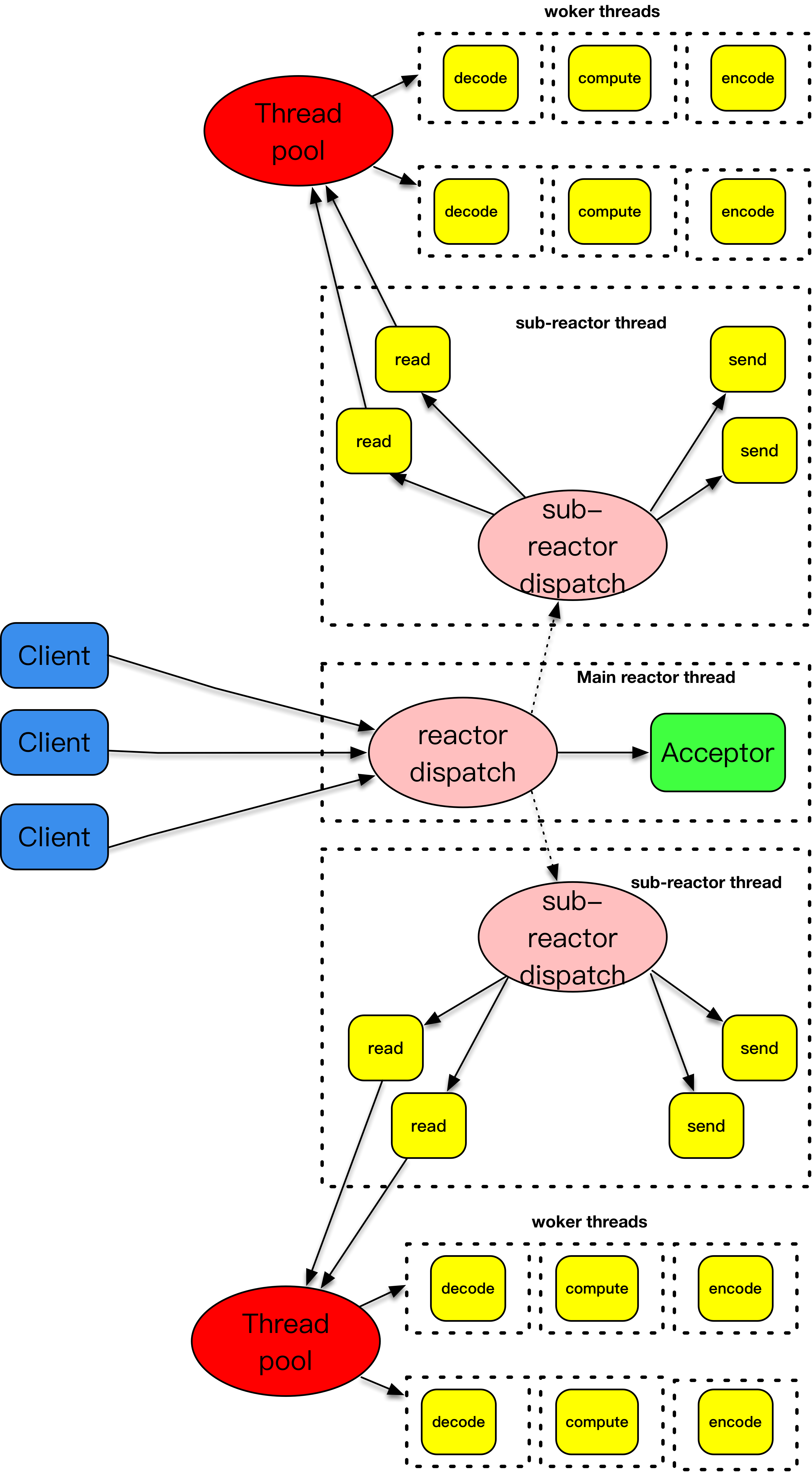
此模式将 decode、compute、encode 等 CPU 密集型的工作从 I/O 线程中拿走,这些工作交给 worker 线程池来处理,而且这些工作拆分成了一个个子任务进行。encode 之后完成的结果再由 sub-reactor 的 I/O 线程发送出去。
样例 server 如下:
#include <lib/acceptor.h>
#include "lib/common.h"
#include "lib/event_loop.h"
#include "lib/tcp_server.h"
char rot13_char(char c) {
if ((c >= 'a' && c <= 'm') || (c >= 'A' && c <= 'M'))
return c + 13;
else if ((c >= 'n' && c <= 'z') || (c >= 'N' && c <= 'Z'))
return c - 13;
else
return c;
}
// 连接建立之后的 callback
int onConnectionCompleted(struct tcp_connection *tcpConnection) {
printf("connection completed\n");
return 0;
}
// 数据读到 buffer 之后的 callback
int onMessage(struct buffer *input, struct tcp_connection *tcpConnection) {
printf("get message from tcp connection %s\n", tcpConnection->name);
printf("%s", input->data);
struct buffer *output = buffer_new();
int size = buffer_readable_size(input);
for (int i = 0; i < size; i++) {
buffer_append_char(output, rot13_char(buffer_read_char(input)));
}
tcp_connection_send_buffer(tcpConnection, output);
return 0;
}
// 数据通过 buffer 写完之后的 callback
int onWriteCompleted(struct tcp_connection *tcpConnection) {
printf("write completed\n");
return 0;
}
// 连接关闭之后的 callback
int onConnectionClosed(struct tcp_connection *tcpConnection) {
printf("connection closed\n");
return 0;
}
int main(int c, char **v) {
// 主线程 event_loop
struct event_loop *eventLoop = event_loop_init();
// 初始化 acceptor
struct acceptor *acceptor = acceptor_init(SERV_PORT);
// 初始 tcp_server,可指定线程数目,这里线程是 4,说明是一个 acceptor 线程,4 个 I/O 线程,没一个 I/O 线程
//tcp_server 自己带一个 event_loop
struct TCPserver *tcpServer = tcp_server_init(eventLoop, acceptor, onConnectionCompleted, onMessage,
onWriteCompleted, onConnectionClosed, 4);
tcp_server_start(tcpServer);
// main thread for acceptor
event_loop_run(eventLoop);
}
创建 TCPServer 时,线程的数量设置不再是 0,而是 4。这里线程是 4,说明是一个主 acceptor 线程,4 个从 reactor 线程,每一个线程都跟一个 event_loop 一一绑定。
通过回调函数暴露了交互的接口,这里应用程序开发者完全可在 onMessage() 里面获取一个子线程来处理 encode、compute 和 decode 的工作,像下面的示范代码一样:
// 数据读到 buffer 之后的 callback
int onMessage(struct buffer *input, struct tcp_connection *tcpConnection) {
printf("get message from tcp connection %s\n", tcpConnection->name);
printf("%s", input->data);
// 取出一个线程来负责 decode、compute 和 encode
struct buffer *output = thread_handle(input);
// 处理完之后再通过 reactor I/O 线程发送数据
tcp_connection_send_buffer(tcpConnection, output);
return
}
运行效果如下:
- 启动此server ,你可从server 的输出上看到用了 poll 作为事件分发方式。
- 多打开几个 telnet client 交互,main-thread 只负责新的连接建立,每个客户端数据的收发由不同的子线程 Thread-1、Thread-2、Thread-3 和 Thread-4 来提供服务。
- 这里由于用了子线程进行 I/O 处理,主线程可专注于新连接处理,从而大大提高了客户端连接成功率。
$./poll-server-multithreads
[msg] set poll as dispatcher
[msg] add channel fd == 4, main thread
[msg] poll added channel fd==4
[msg] set poll as dispatcher
[msg] add channel fd == 7, main thread
[msg] poll added channel fd==7
[msg] event loop thread init and signal, Thread-1
[msg] event loop run, Thread-1
[msg] event loop thread started, Thread-1
[msg] set poll as dispatcher
[msg] add channel fd == 9, main thread
[msg] poll added channel fd==9
[msg] event loop thread init and signal, Thread-2
[msg] event loop run, Thread-2
[msg] event loop thread started, Thread-2
[msg] set poll as dispatcher
[msg] add channel fd == 11, main thread
[msg] poll added channel fd==11
[msg] event loop thread init and signal, Thread-3
[msg] event loop thread started, Thread-3
[msg] set poll as dispatcher
[msg] event loop run, Thread-3
[msg] add channel fd == 13, main thread
[msg] poll added channel fd==13
[msg] event loop thread init and signal, Thread-4
[msg] event loop run, Thread-4
[msg] event loop thread started, Thread-4
[msg] add channel fd == 5, main thread
[msg] poll added channel fd==5
[msg] event loop run, main thread
[msg] get message channel i==1, fd==5
[msg] activate channel fd == 5, revents=2, main thread
[msg] new connection established, socket == 14
connection completed
[msg] get message channel i==0, fd==7
[msg] activate channel fd == 7, revents=2, Thread-1
[msg] wakeup, Thread-1
[msg] add channel fd == 14, Thread-1
[msg] poll added channel fd==14
[msg] get message channel i==1, fd==14
[msg] activate channel fd == 14, revents=2, Thread-1
get message from tcp connection connection-14
fasfas
[msg] get message channel i==1, fd==14
[msg] activate channel fd == 14, revents=2, Thread-1
get message from tcp connection connection-14
fasfas
asfa
[msg] get message channel i==1, fd==5
[msg] activate channel fd == 5, revents=2, main thread
[msg] new connection established, socket == 15
connection completed
[msg] get message channel i==0, fd==9
[msg] activate channel fd == 9, revents=2, Thread-2
[msg] wakeup, Thread-2
[msg] add channel fd == 15, Thread-2
[msg] poll added channel fd==15
[msg] get message channel i==1, fd==15
[msg] activate channel fd == 15, revents=2, Thread-2
get message from tcp connection connection-15
afasdfasf
[msg] get message channel i==1, fd==15
[msg] activate channel fd == 15, revents=2, Thread-2
get message from tcp connection connection-15
afasdfasf
safsafa
[msg] get message channel i==1, fd==15
[msg] activate channel fd == 15, revents=2, Thread-2
[msg] poll delete channel fd==15
connection closed
[msg] get message channel i==1, fd==5
[msg] activate channel fd == 5, revents=2, main thread
[msg] new connection established, socket == 16
connection completed
[msg] get message channel i==0, fd==11
[msg] activate channel fd == 11, revents=2, Thread-3
[msg] wakeup, Thread-3
[msg] add channel fd == 16, Thread-3
[msg] poll added channel fd==16
[msg] get message channel i==1, fd==16
[msg] activate channel fd == 16, revents=2, Thread-3
get message from tcp connection connection-16
fdasfasdf
[msg] get message channel i==1, fd==14
[msg] activate channel fd == 14, revents=2, Thread-1
[msg] poll delete channel fd==14
connection closed
[msg] get message channel i==1, fd==5
[msg] activate channel fd == 5, revents=2, main thread
[msg] new connection established, socket == 17
connection completed
[msg] get message channel i==0, fd==13
[msg] activate channel fd == 13, revents=2, Thread-4
[msg] wakeup, Thread-4
[msg] add channel fd == 17, Thread-4
[msg] poll added channel fd==17
[msg] get message channel i==1, fd==17
[msg] activate channel fd == 17, revents=2, Thread-4
get message from tcp connection connection-17
qreqwrq
[msg] get message channel i==1, fd==16
[msg] activate channel fd == 16, revents=2, Thread-3
[msg] poll delete channel fd==16
connection closed
[msg] get message channel i==1, fd==5
[msg] activate channel fd == 5, revents=2, main thread
[msg] new connection established, socket == 18
connection completed
[msg] get message channel i==0, fd==7
[msg] activate channel fd == 7, revents=2, Thread-1
[msg] wakeup, Thread-1
[msg] add channel fd == 18, Thread-1
[msg] poll added channel fd==18
[msg] get message channel i==1, fd==18
[msg] activate channel fd == 18, revents=2, Thread-1
get message from tcp connection connection-18
fasgasdg
^C
七、epoll + 多线程 的 「主从 reactor 模式」
的网络框架的 lib/event_loop.c 文件的 event_loop_init_with_name(),通过宏 EPOLL_ENABLE 来决定是用 epoll 还是 poll 的:
struct event_loop *event_loop_init_with_name(char *thread_name) {
...
#ifdef EPOLL_ENABLE
yolanda_msgx("set epoll as dispatcher, %s", eventLoop->thread_name);
eventLoop->eventDispatcher = &epoll_dispatcher;
#else
yolanda_msgx("set poll as dispatcher, %s", eventLoop->thread_name);
eventLoop->eventDispatcher = &poll_dispatcher;
#endif
eventLoop->event_dispatcher_data = eventLoop->eventDispatcher->init(eventLoop);
...
}
在根目录下的 CMakeLists.txt 文件里,引入 CheckSymbolExists
- 若系统里有 epoll_create() 和 sys/epoll.h,就自动开启 EPOLL_ENABLE。
- 若没有,EPOLL_ENABLE 就不会开启,即自动用 poll 作为默认的事件分发机制。
# check epoll and add config.h for the macro compilation
include(CheckSymbolExists)
check_symbol_exists(epoll_create "sys/epoll.h" EPOLL_EXISTS)
if (EPOLL_EXISTS)
# Linux 下设置为 epoll
set(EPOLL_ENABLE 1 CACHE INTERNAL "enable epoll")
# Linux 下也设置为 poll
# set(EPOLL_ENABLE "" CACHE INTERNAL "not enable epoll")
else ()
set(EPOLL_ENABLE "" CACHE INTERNAL "not enable epoll")
endif ()
但是,为了能让编译器用到此宏,需要让 CMake 往 config.h 文件里写入此宏的最终值,configure_file 命令就是起此作用的。其中 config.h.cmake 是一个模板文件,已预先创建在根目录下。同时还需要让编译器 include 此 config.h 文件。include_directories 可帮达成此目标。
configure_file(${
CMAKE_CURRENT_SOURCE_DIR}/config.h.cmake
${
CMAKE_CURRENT_BINARY_DIR}/include/config.h)
include_directories(${
CMAKE_CURRENT_BINARY_DIR}/include)
这样,在 Linux 下,就会默认用 epoll 作为事件分发。
server 如下:
#include <lib/acceptor.h>
#include "lib/common.h"
#include "lib/event_loop.h"
#include "lib/tcp_server.h"
char rot13_char(char c) {
if ((c >= 'a' && c <= 'm') || (c >= 'A' && c <= 'M'))
return c + 13;
else if ((c >= 'n' && c <= 'z') || (c >= 'N' && c <= 'Z'))
return c - 13;
else
return c;
}
// 连接建立之后的 callback
int onConnectionCompleted(struct tcp_connection *tcpConnection) {
printf("connection completed\n");
return 0;
}
// 数据读到 buffer 之后的 callback
int onMessage(struct buffer *input, struct tcp_connection *tcpConnection) {
printf("get message from tcp connection %s\n", tcpConnection->name);
printf("%s", input->data);
struct buffer *output = buffer_new();
int size = buffer_readable_size(input);
for (int i = 0; i < size; i++) {
buffer_append_char(output, rot13_char(buffer_read_char(input)));
}
tcp_connection_send_buffer(tcpConnection, output);
return 0;
}
// 数据通过 buffer 写完之后的 callback
int onWriteCompleted(struct tcp_connection *tcpConnection) {
printf("write completed\n");
return 0;
}
// 连接关闭之后的 callback
int onConnectionClosed(struct tcp_connection *tcpConnection) {
printf("connection closed\n");
return 0;
}
int main(int c, char **v) {
// 主线程 event_loop
struct event_loop *eventLoop = event_loop_init();
// 初始化 acceptor
struct acceptor *acceptor = acceptor_init(SERV_PORT);
// 初始 tcp_server,可指定线程数目,这里线程是 4,说明是一个 acceptor 线程,4 个 I/O 线程,没一个 I/O 线程
//tcp_server 自己带一个 event_loop
struct TCPserver *tcpServer = tcp_server_init(eventLoop, acceptor, onConnectionCompleted, onMessage,
onWriteCompleted, onConnectionClosed, 4);
tcp_server_start(tcpServer);
// main thread for acceptor
event_loop_run(eventLoop);
}
关于此程序,之前一直没有讲到的部分是缓冲区对象 buffer。这其实也是网络编程框架应该考虑的部分。
希望框架可对应用程序封装掉套接字读和写的部分,转而提供的是针对缓冲区对象的读和写操作。这样一来,从套接字收取数据、处理异常、发送数据等操作都被类似 buffer 此对象所封装和屏蔽,应用程序所要做的事情就会变得更加简单,从 buffer 对象中可获取已接收到的字节流再进行应用层处理,比如这里通过调用 buffer_read_char 函数从 buffer 中读取一个字节。
另外一方面,框架也必须对应用程序提供套接字发送的接口,接口的数据类型类似这里的 buffer 对象,可看到,这里先生成了一个 buffer 对象,之后将编码后的结果填充到 buffer 对象里,最后调用 tcp_connection_send_buffer 将 buffer 对象里的数据通过套接字发送出去。
这里像 onMessage、onConnectionClosed 几个回调函数都是运行在子反应堆线程中的,即,刚刚提到的生成 buffer 对象,encode 部分的代码,是在子反应堆线程中执行的。这其实也是回调函数的内涵,回调函数本身只是提供了类似 Handlder 的处理逻辑,具体执行是由事件分发线程,或说是 event loop 线程发起的。
框架通过一层抽象,让应用程序的开发者只需要看到回调函数,回调函数中的对象,也都是如 buffer 和 tcp_connection 这样封装过的对象,这样像套接字、字节流等底层实现的细节就完全由框架来完成了。
运行结果如下:
- 启动server ,可从屏幕输出上看到,用的是 epoll 作为事件分发器。
$./epoll-server-multithreads
[msg] set epoll as dispatcher, main thread
[msg] add channel fd == 5, main thread
[msg] set epoll as dispatcher, Thread-1
[msg] add channel fd == 9, Thread-1
[msg] event loop thread init and signal, Thread-1
[msg] event loop run, Thread-1
[msg] event loop thread started, Thread-1
[msg] set epoll as dispatcher, Thread-2
[msg] add channel fd == 12, Thread-2
[msg] event loop thread init and signal, Thread-2
[msg] event loop run, Thread-2
[msg] event loop thread started, Thread-2
[msg] set epoll as dispatcher, Thread-3
[msg] add channel fd == 15, Thread-3
[msg] event loop thread init and signal, Thread-3
[msg] event loop run, Thread-3
[msg] event loop thread started, Thread-3
[msg] set epoll as dispatcher, Thread-4
[msg] add channel fd == 18, Thread-4
[msg] event loop thread init and signal, Thread-4
[msg] event loop run, Thread-4
[msg] event loop thread started, Thread-4
[msg] add channel fd == 6, main thread
[msg] event loop run, main thread
开启多个 telnet client ,连接上该server , 通过屏幕输入和server 交互:
$telnet 127.0.0.1 43211
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
fafaf
snsns
^]
telnet> quit
Connection closed.
server 显示不断地从 epoll_wait 中返回处理 I/O 事件:
[msg] epoll_wait wakeup, main thread
[msg] get message channel fd==6 for read, main thread
[msg] activate channel fd == 6, revents=2, main thread
[msg] new connection established, socket == 19
connection completed
[msg] epoll_wait wakeup, Thread-1
[msg] get message channel fd==9 for read, Thread-1
[msg] activate channel fd == 9, revents=2, Thread-1
[msg] wakeup, Thread-1
[msg] add channel fd == 19, Thread-1
[msg] epoll_wait wakeup, Thread-1
[msg] get message channel fd==19 for read, Thread-1
[msg] activate channel fd == 19, revents=2, Thread-1
get message from tcp connection connection-19
afasf
[msg] epoll_wait wakeup, main thread
[msg] get message channel fd==6 for read, main thread
[msg] activate channel fd == 6, revents=2, main thread
[msg] new connection established, socket == 20
connection completed
[msg] epoll_wait wakeup, Thread-2
[msg] get message channel fd==12 for read, Thread-2
[msg] activate channel fd == 12, revents=2, Thread-2
[msg] wakeup, Thread-2
[msg] add channel fd == 20, Thread-2
[msg] epoll_wait wakeup, Thread-2
[msg] get message channel fd==20 for read, Thread-2
[msg] activate channel fd == 20, revents=2, Thread-2
get message from tcp connection connection-20
asfasfas
[msg] epoll_wait wakeup, Thread-2
[msg] get message channel fd==20 for read, Thread-2
[msg] activate channel fd == 20, revents=2, Thread-2
connection closed
[msg] epoll_wait wakeup, main thread
[msg] get message channel fd==6 for read, main thread
[msg] activate channel fd == 6, revents=2, main thread
[msg] new connection established, socket == 21
connection completed
[msg] epoll_wait wakeup, Thread-3
[msg] get message channel fd==15 for read, Thread-3
[msg] activate channel fd == 15, revents=2, Thread-3
[msg] wakeup, Thread-3
[msg] add channel fd == 21, Thread-3
[msg] epoll_wait wakeup, Thread-3
[msg] get message channel fd==21 for read, Thread-3
[msg] activate channel fd == 21, revents=2, Thread-3
get message from tcp connection connection-21
dfasfadsf
[msg] epoll_wait wakeup, Thread-1
[msg] get message channel fd==19 for read, Thread-1
[msg] activate channel fd == 19, revents=2, Thread-1
connection closed
[msg] epoll_wait wakeup, main thread
[msg] get message channel fd==6 for read, main thread
[msg] activate channel fd == 6, revents=2, main thread
[msg] new connection established, socket == 22
connection completed
[msg] epoll_wait wakeup, Thread-4
[msg] get message channel fd==18 for read, Thread-4
[msg] activate channel fd == 18, revents=2, Thread-4
[msg] wakeup, Thread-4
[msg] add channel fd == 22, Thread-4
[msg] epoll_wait wakeup, Thread-4
[msg] get message channel fd==22 for read, Thread-4
[msg] activate channel fd == 22, revents=2, Thread-4
get message from tcp connection connection-22
fafaf
[msg] epoll_wait wakeup, Thread-4
[msg] get message channel fd==22 for read, Thread-4
[msg] activate channel fd == 22, revents=2, Thread-4
connection closed
[msg] epoll_wait wakeup, Thread-3
[msg] get message channel fd==21 for read, Thread-3
[msg] activate channel fd == 21, revents=2, Thread-3
connection closed
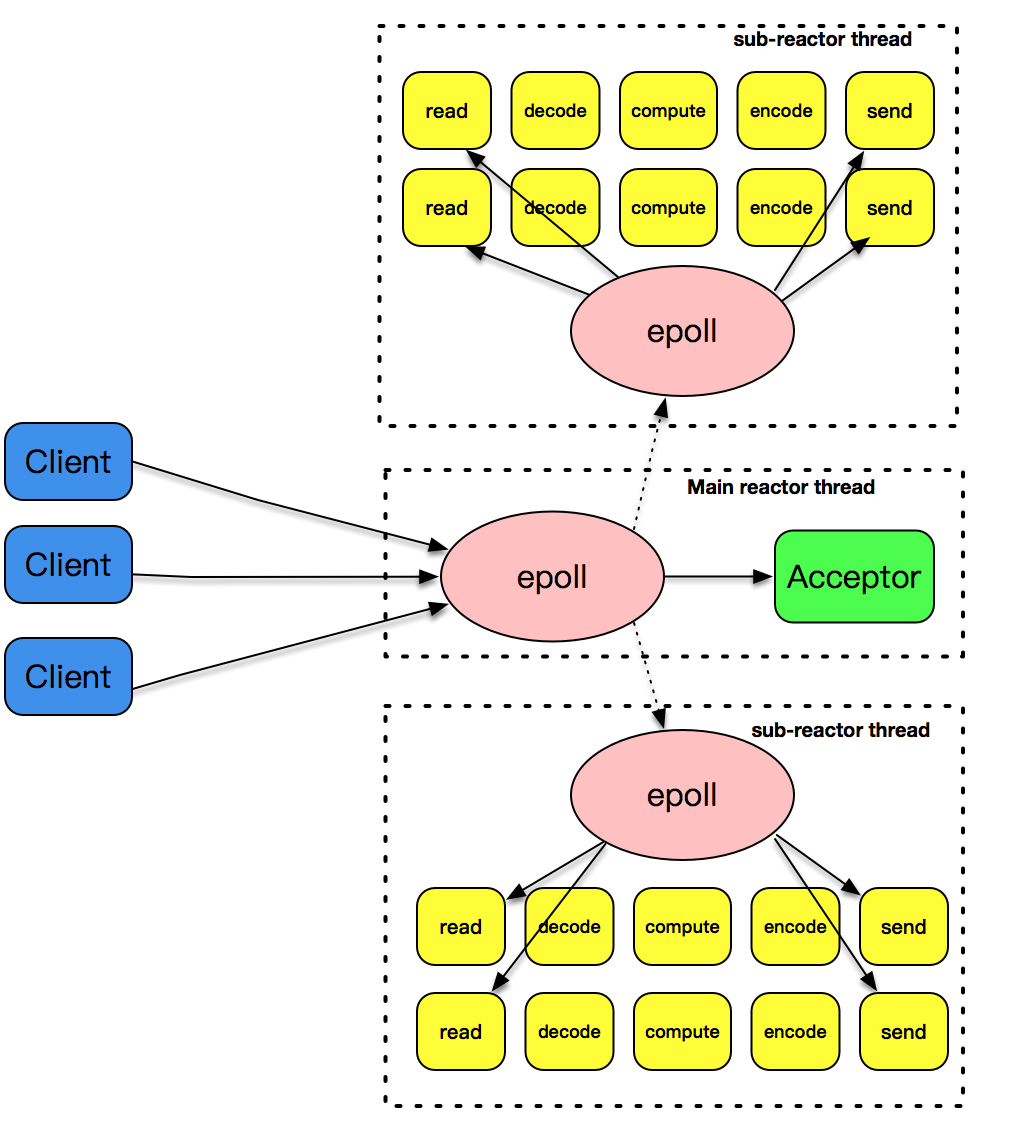
其中主线程的 epoll_wait 只处理 acceptor 套接字的事件,表示的是连接的建立;反应堆子线程的 epoll_wait 主要处理的是已连接套接字的读写事件。文稿中的这幅图详细解释了这部分逻辑。
八、Proactor 的网络事件驱动模式
8.1 阻塞 / 非阻塞 VS 同步 / 异步
老张爱喝茶,废话不说,煮开水。出场人物:老张,水壶两把(普通水壶,简称水壶;会响的水壶,简称响水壶)。
1 老张把水壶放到火上,立等水开。(同步阻塞)老张觉得自己有点傻
2 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞)老张还是觉得自己有点傻,于是变高端了,买了把会响笛的那种水壶。水开之后,能大声发出嘀~~~~的噪音。
3 老张把响水壶放到火上,立等水开。(异步阻塞)老张觉得这样傻等意义不大
4 老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞)老张觉得自己聪明了。
所谓同步异步,只是对于水开了此状态是老张主动去发现的还是水壶通知的。
- 老张主动去发现的,同步;
- 水壶通知的,异步。
- 虽然都能干活,但响水壶可在自己完工之后,提示老张水开了。这是普通水壶所不能及的。同步只能让调用者去轮询自己(情况2中),造成老张效率的低下。
所谓阻塞非阻塞,仅仅对于老张而言。
- 立等的老张,阻塞;
- 看电视的老张,非阻塞。
- 情况1和情况3中老张就是阻塞的,媳妇喊他都不知道。虽然3中响水壶是异步的,可对于立等的老张没有太大的意义。所以一般异步是配合非阻塞用的,这样才能发挥异步的效用。
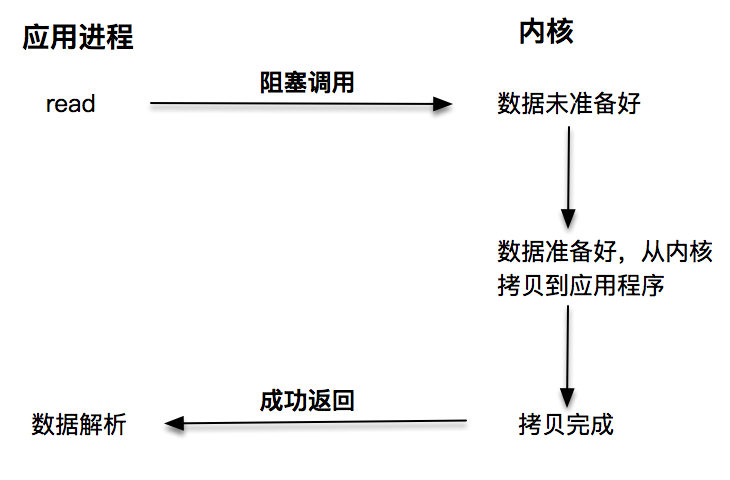
第一种是阻塞 I/O。阻塞 I/O 发起的 read 请求,线程会被挂起,一直等到内核数据准备好,并把数据从内核区域拷贝到应用程序的缓冲区中,当拷贝过程完成,read 请求调用才返回。接下来,应用程序就可对缓冲区的数据进行数据解析。
第二种是非阻塞 I/O。非阻塞的 read 请求在数据未准备好的情况下立即返回,应用程序可不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲,并完成这次 read() 。注意,这里最后一次 read() ,获取数据的过程,是一个同步的过程。这里的同步指的是内核区域的数据拷贝到缓存区此过程。
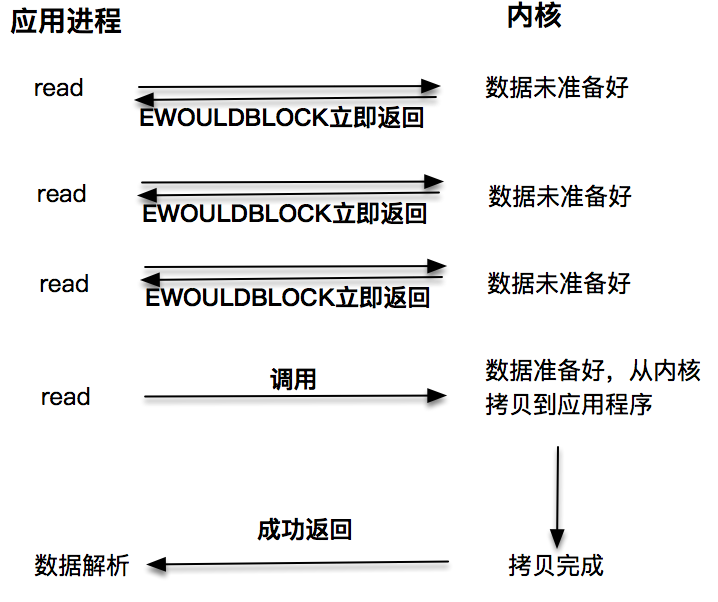
第三种:每次让应用程序去轮询内核的 I/O 是否准备好,是一个不经济的做法,因为在轮询的过程中应用进程啥也不能干。于是,像 select、poll 此 I/O 多路复用技术就隆重登场了。通过 I/O 事件分发,当内核数据准备好时,再通知应用程序进行操作。此做法大大改善了应用进程对 CPU 的利用率,在没有被通知的情况下,应用进程可用 CPU 做其他的事情。
注意,这里 read() ,获取数据的过程,也是一个同步的过程:
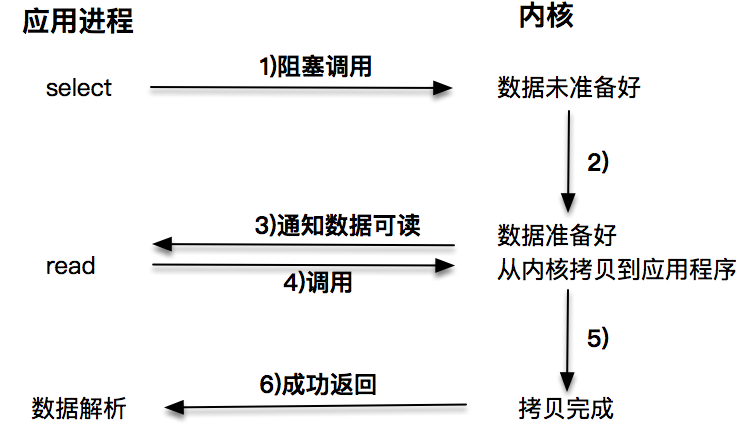
第一种阻塞 I/O 我想你已比较了解了,在阻塞 I/O 的情况下,应用程序会被挂起,直到获取数据。第二种非阻塞 I/O 和第三种基于非阻塞 I/O 的多路复用技术,获取数据的操作不会被阻塞。
无论是第一种阻塞 I/O,还是第二种非阻塞 I/O,第三种基于非阻塞 I/O 的多路复用都是同步调用技术。为什么这么说呢?因为同步调用、异步调用的说法,是对于获取数据的过程而言的,前面几种最后获取数据的 read 操作调用,都是同步的,在 read() 时,内核将数据从内核空间拷贝到应用程序空间,此过程是在 read 函数中同步进行的,若内核实现的拷贝效率很差,read() 就会在此同步过程中消耗比较长的时间。
而真正的异步调用则不用担心此问题,接下来就来介绍第四种 I/O 技术,当发起 aio_read 之后,就立即返回,内核自动将数据从内核空间拷贝到应用程序空间,此拷贝过程是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作:
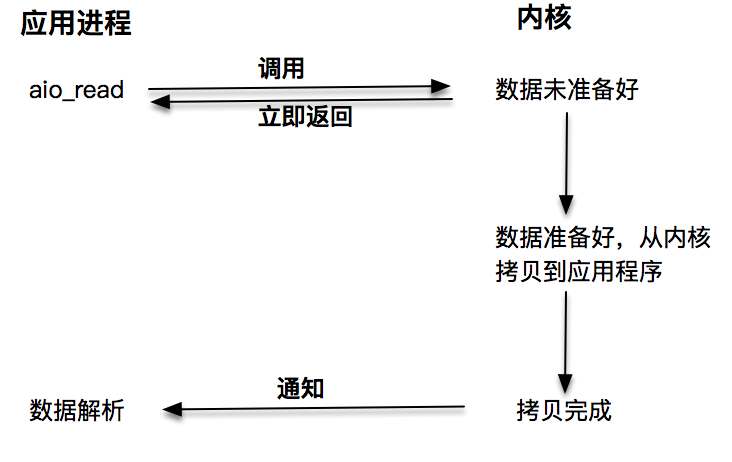
可这样对比:
- 第一种阻塞 I/O 就是你去了书店,告诉老板你想要某本书,然后你就一直在那里等着,直到书店老板翻箱倒柜找到你想要的书。
- 第二种非阻塞 I/O 类似于你去了书店,问老板有没有一本书,老板告诉你没有,你就离开了。一周以后,你又来此书店,再问此老板,老板一查,有了,于是你买了这本书。
- 第三种基于非阻塞的 I/O 多路复用,你来到书店告诉老板:“老板,到货给我打电话吧,我再来付钱取书。”
- 第四种异步 I/O 就是你连去书店取书的过程也想省了,你留下地址,付了书费,让老板到货时寄给你,你直接在家里拿到就可看了。
这里放置了一张表格,总结了以上几种 I/O 模型:

8.2 aio_read 和 aio_write
听起来,异步 I/O 有一种高大上的感觉。其实,异步 I/O 用起来倒是挺简单的。下面看一下一个具体的例子:
- aio_write:用来向内核提交异步写操作;
- aio_read:用来向内核提交异步读操作;
- aio_error:获取当前异步操作的状态;
- aio_return:获取异步操作读、写的字节数。
#include "lib/common.h"
#include <aio.h>
const int BUF_SIZE = 512;
int main() {
int err;
int result_size;
// 创建一个临时文件
char tmpname[256];
snprintf(tmpname, sizeof(tmpname), "/tmp/aio_test_%d", getpid());
unlink(tmpname);
int fd = open(tmpname, O_CREAT | O_RDWR | O_EXCL, S_IRUSR | S_IWUSR);
if (fd == -1) {
error(1, errno, "open file failed ");
}
char buf[BUF_SIZE];
struct aiocb aiocb;
// 初始化 buf 缓冲,写入的数据应该为 0xfafa 此,
memset(buf, 0xfa, BUF_SIZE);
memset(&aiocb, 0, sizeof(struct aiocb));
aiocb.aio_fildes = fd;
aiocb.aio_buf = buf;
aiocb.aio_nbytes = BUF_SIZE;
// 开始写
if (aio_write(&aiocb) == -1) {
printf(" Error at aio_write(): %s\n", strerror(errno));
close(fd);
exit(1);
}
// 因为是异步的,需要判断什么时候写完
while (aio_error(&aiocb) == EINPROGRESS) {
printf("writing... \n");
}
// 判断写入的是否正确
err = aio_error(&aiocb);
result_size = aio_return(&aiocb);
if (err != 0 || result_size != BUF_SIZE) {
printf(" aio_write failed() : %s\n", strerror(err));
close(fd);
exit(1);
}
// 下面准备开始读数据
char buffer[BUF_SIZE];
struct aiocb cb;
cb.aio_nbytes = BUF_SIZE;
cb.aio_fildes = fd;
cb.aio_offset = 0;
cb.aio_buf = buffer;
// 开始读数据
if (aio_read(&cb) == -1) {
printf(" air_read failed() : %s\n", strerror(err));
close(fd);
}
// 因为是异步的,需要判断什么时候读完
while (aio_error(&cb) == EINPROGRESS) {
printf("Reading... \n");
}
// 判断读是否成功
int numBytes = aio_return(&cb);
if (numBytes != -1) {
printf("Success.\n");
} else {
printf("Error.\n");
}
// 清理文件句柄
close(fd);
return 0;
}
// 其中用到内核的 aiocb 结构体
struct aiocb {
int aio_fildes; /* File descriptor */
off_t aio_offset; /* File offset */
volatile void *aio_buf; /* Location of buffer */
size_t aio_nbytes; /* Length of transfer */
int aio_reqprio; /* Request priority offset */
struct sigevent aio_sigevent; /* Signal number and value */
int aio_lio_opcode; /* Operation to be performed */
};
运行效果如下:
./aio01
writing...
writing...
writing...
writing...
writing...
writing...
writing...
writing...
writing...
writing...
writing...
writing...
writing...
writing...
Reading...
Reading...
Reading...
Reading...
Reading...
Reading...
Reading...
Reading...
Reading...
Success.
注意,以上的读写,都不需要在应用程序里再发起调用,系统内核直接帮做好了。
8.3 Linux 下 socket 套接字的异步支持
aio 系列函数是由 POSIX 定义的异步操作接口,可惜的是,Linux 下的 aio 操作,不是真正的操作系统级别支持的,它只是由 GNU libc 库函数在用户空间借由 pthread 方式实现的,而且仅仅针对磁盘类 I/O,套接字 I/O 不支持。
也有很多 Linux 的开发者尝试在操作系统内核中直接支持 aio,如一个叫做 Ben LaHaise 的人,就将 aio 实现成功 merge 到 2.5.32 中,这部分能力是作为 patch 存在的,但是,它依旧不支持套接字。
Solaris 倒是有真正的系统系别的 aio,不过还不是很确定它在套接字上的性能表现,特别是和磁盘 I/O 相比效果如何。
综合以上结论就是,Linux 下对异步操作的支持非常有限,这也是为什么用 epoll 等多路分发技术加上非阻塞 I/O 来解决 Linux 下高并发高性能网络 I/O 问题的根本原因。
Linux 的 AIO 机制可能后面逐渐不用了,可关注 5.1 的 io_uring 机制,大杀器
8.4 Windows 下的 IOCP 和 Proactor 模式
和 Linux 不同,Windows 下实现了一套完整的支持套接字的异步编程接口,这套接口一般被叫做 IOCompletetionPort(IOCP)。
这样,就产生了基于 IOCP 的所谓 Proactor 模式。
和 Reactor 模式一样,Proactor 模式也存在一个无限循环运行的 event loop 线程,但是不同于 Reactor 模式,此线程并不负责处理 I/O 调用,它只是负责在对应的 read、write() 完成的情况下,分发完成事件到不同的处理函数。
这里举一个 HTTP 服务请求的例子来说明:
- 客户端发起一个 GET 请求
- 此 GET 请求对应的字节流被内核读取完成,内核将此完成事件放置到一个队列中;
- event loop 线程,即 Poractor 从此队列里获取事件,根据事件类型,分发到不同的处理函数上,比如一个 http handle 的 onMessage 解析函数;
- HTTP request 解析函数完成报文解析;
- 业务逻辑处理,比如读取数据库的记录;
- 业务逻辑处理完成,开始 encode,完成之后,发起一个异步写操作;
- 此异步写操作被内核执行,完成之后此异步写操作被放置到内核的队列中;
- Proactor 线程获取此完成事件,分发到 HTTP handler 的 onWriteCompled() 执行。
从此例子可看出,由于系统内核提供了真正的“异步”操作,Proactor 不会再像 Reactor 一样,每次感知事件后再调用 read、write() 完成数据的读写,它只负责感知事件完成,并由对应的 handler 发起异步读写请求,I/O 读写操作本身是由系统内核完成的。和前面看到的 aio 的例子一样,这里需要传入数据缓冲区的地址等信息,这样,系统内核才可自动帮把数据的读写工作完成。
无论是 Reactor 模式,还是 Proactor 模式,都是一种基于事件分发的网络编程模式。Reactor 模式是基于待完成的 I/O 事件,而 Proactor 模式则是基于已完成的 I/O 事件,两者的本质,都是借由事件分发的思想,设计出可兼容、可扩展、接口友好的一套程序框架。