大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用17-pytorch框架下模型int8,fp32量化技巧,Int8和fp32量化都是一种模型优化方法,Int8和fp32量化的主要目的是减少神经网络模型的计算量和内存占用,从而提高模型的推断速度和效率,尤其是在移动设备等资源有限的环境下。Int8量化可以将神经网络中所有的权重和激活值转换成8位整数进行表示,从而实现内存占用的大幅减少;fp32量化可以将权重和激活值转换成32位浮点数的固定点表示,也能减少内存占用和计算量,同时更加精确地表示数值。通过对神经网络模型进行量化优化,可以提高模型在实际使用中的响应速度和效率,并且能够在一定程度上避免过度拟合的问题。
一、Int8量化和fp32量化
Int8量化(8位整数量化)是指将网络中的所有权重和激活值转换成8位整数表示,从而减少模型的计算量和内存占用。这样可以提高模型在移动设备上的执行速度和效率,同时减少内存占用。
fp32量化(32位浮点数量化)是指将权重和激活值转换为32位浮点数的固定点表示,从而减少内存占用和计算量。这种量化不同于Int8量化,因为它使用浮点数,所以可以更加精确地表示数值,但同时也需要更多的内存。
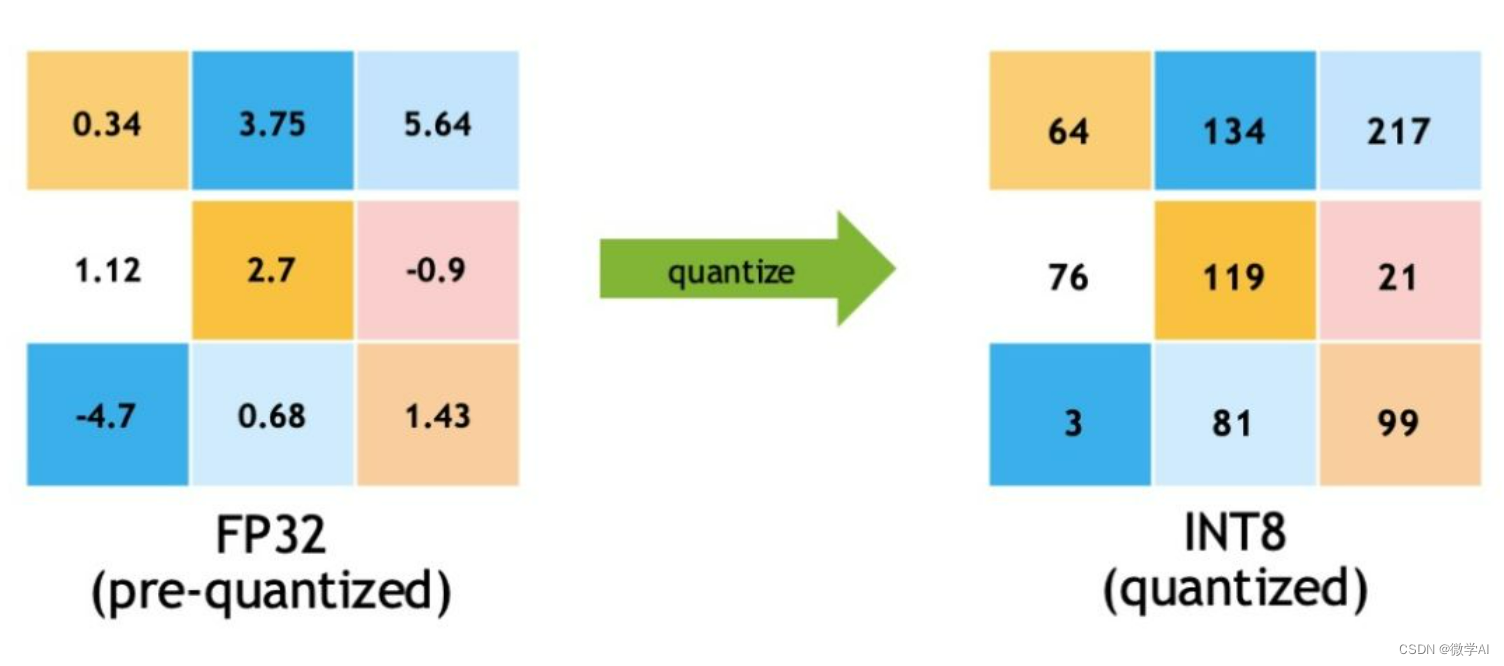
二、Int8量化和fp32量化代码样例
我们用PyTorch框架的示例代码,展示了如何对预训练的ResNet152模型进行int8、fp16和fp32量化,并使用量化后的模型进行图像分类预测。首先,确保已经安装了PyTorch和torchvision库。代码中使用time_it装