说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。


1.项目背景
蚁群优化算法(Ant Colony Optimization, ACO)是一种源于大自然生物世界的新的仿生进化算法,由意大利学者M. Dorigo, V. Maniezzo和A.Colorni等人于20世纪90年代初期通过模拟自然界中蚂蚁集体寻径行为而提出的一种基于种群的启发式随机搜索算法"。蚂蚁有能力在没有任何提示的情形下找到从巢穴到食物源的最短路径,并且能随环境的变化,适应性地搜索新的路径,产生新的选择。其根本原因是蚂蚁在寻找食物时,能在其走过的路径上释放一种特殊的分泌物——信息素(也称外激素),随着时间的推移该物质会逐渐挥发,后来的蚂蚁选择该路径的概率与当时这条路径上信息素的强度成正比。当一条路径上通过的蚂蚁越来越多时,其留下的信息素也越来越多,后来蚂蚁选择该路径的概率也就越高,从而更增加了该路径上的信息素强度。而强度大的信息素会吸引更多的蚂蚁,从而形成一种正反馈机制。通过这种正反馈机制,蚂蚁最终可以发现最短路径。
本项目通过ACO蚁群优化算法寻找最优的参数值来优化随机森林分类模型。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:

数据详情如下(部分展示):

3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:

3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:

从上图可以看到,总共有11个变量,数据中无缺失值,共1000条数据。
关键代码:

3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。

关键代码如下:

4.探索性数据分析
4.1 y变量柱状图
用Matplotlib工具的plot()方法绘制直方图:

4.2 y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:

4.3 相关性分析

从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:

6.构建ACO蚁群优化算法优化随机森林分类模型
主要使用ACO蚁群优化算法优化随机森林分类算法,用于目标分类。
6.1 ACO蚁群优化算法寻找的最优参数
关键代码:

最优参数:
 6.2 最优参数值构建模型
6.2 最优参数值构建模型

7.模型评估
7.1 评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
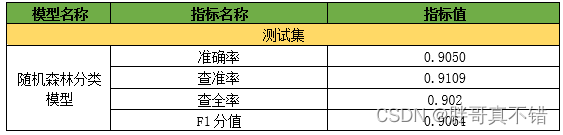
从上表可以看出,F1分值为0.9050,说明模型效果较好。
关键代码如下:

7.2 分类报告

从上图可以看出,分类为0的F1分值为0.90;分类为1的F1分值为0.91。
7.3 混淆矩阵
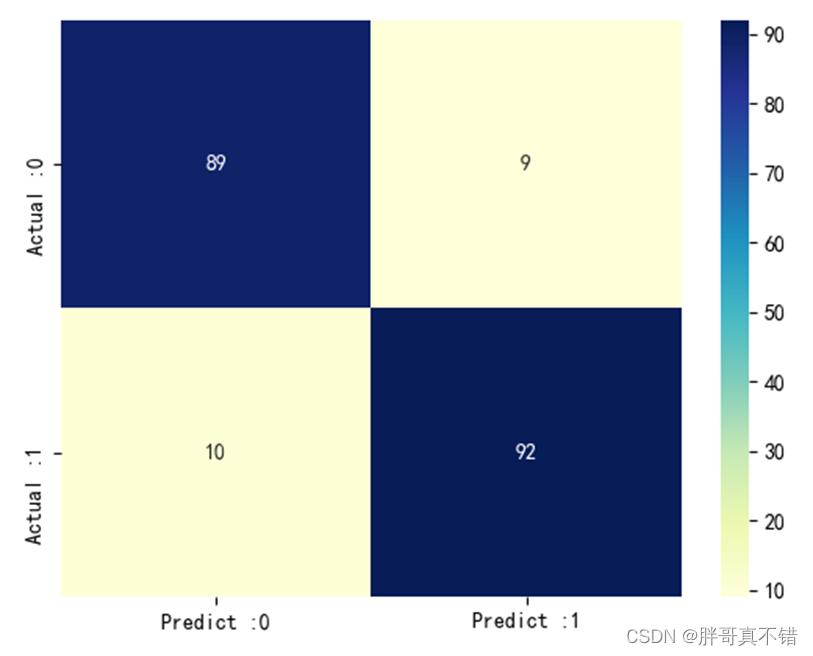
从上图可以看出,实际为0预测不为0的 有9个样本;实际为1预测不为1的 有10个样本,整体预测准确率良好。
8.结论与展望
综上所述,本文采用了ACO蚁群优化算法寻找随机森林分类算法的最优参数值来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。
# ====定义惩罚项函数======
def calc_e(X):
"""计算蚂蚁的惩罚项,X 的维度是 size * 2 """
ee = 0
"""计算第一个约束的惩罚项"""
e1 = X[0] + X[1] - 6
ee += max(0, e1)
"""计算第二个约束的惩罚项"""
e2 = 3 * X[0] - 2 * X[1] - 5
ee += max(0, e2)
return ee
# ******************************************************************************
# 本次机器学习项目实战所需的资料,项目资源如下:
# 项目说明:
# 链接:https://pan.baidu.com/s/1c6mQ_1YaDINFEttQymp2UQ
# 提取码:thgk
# ******************************************************************************
# ===定义子代和父辈之间的选择操作函数====
def update_best(parent, parent_fitness, parent_e, child, child_fitness, child_e, X_train, X_test, y_train, y_test):
"""
针对不同问题,合理选择惩罚项的阈值。本例中阈值为0.1
:param parent: 父辈个体
:param parent_fitness:父辈适应度值
:param parent_e :父辈惩罚项
:param child: 子代个体
:param child_fitness 子代适应度值
:param child_e :子代惩罚项
:return: 父辈 和子代中较优者、适应度、惩罚项
"""
if abs(parent[0]) > 0: # 判断取值
max_depth = int(abs(parent[0])) + 2 # 赋值
else:
max_depth = int(abs(parent[0])) + 5 # 赋值
if abs(parent[1]) > 0: # 判断取值
min_samples_leaf = int(abs(parent[1])) + 1 # 赋值
else:
min_samples_leaf = int(abs(parent[1])) + 5 # 赋值
更多项目实战,详见机器学习项目实战合集列表:
机器学习项目实战合集列表_机器学习实战项目_胖哥真不错的博客-CSDN博客