目录:导读
前言
在性能测试工作中,业务模型、流量模型和数据模型是至关重要且必须在项目中构建的,否则很可能导致测试的场景和实际差距很大,测试结果也无法为性能分析和优化提供足够有说服力的支撑。
三大模型,以电商业务下单的场景举例说明,如下图:
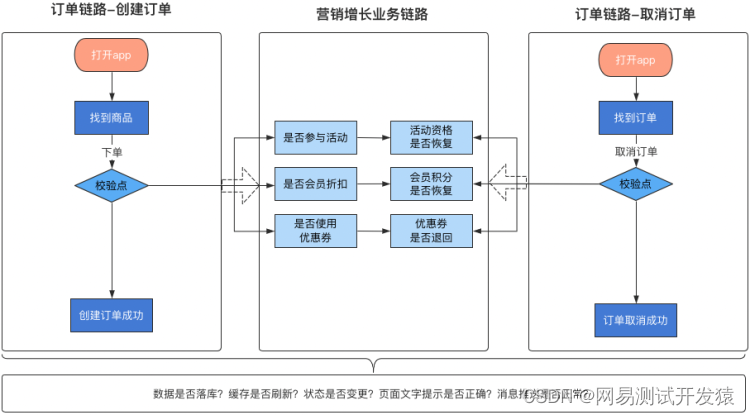
业务模型
大家可以将业务模型看作功能测试中的业务场景。在性能测试中要构建业务模型,我们要考虑如下几个因素:
商品库存是否足够;
下单的商品是否可参与营销活动;
下单的用户是否是vip会员,有会员折扣;
下单的用户是否有优惠券,该优惠券是否满足本订单的优惠条件;
…
其实业务模型和功能测试时候的业务场景分析没什么区别,都是为了针对被测业务和服务进行分析,确保测试的场景和需求是一致的。
如果是更复杂的业务和更大范围的测试需求,可能还要考虑线上业务的流量入口、风控等因素。
当然在实际的工作或项目中,建议通过分析需求,梳理出压测涉及到的业务和场景,绘制成一个业务模型思维导图,这样便于后续的工作开展。
业务模型思维导图可以用树状图也可以用类似上图的样子,便于理解即可。
流量模型
我们都知道,性能测试执行压测时,都是基于接口或某个URL来进行的。本质是模拟生产环境的用户,构造请求对被测系统施加压力,验证系统性能是否满足业务需要,是否存在性能瓶颈。
生产环境的用户操作场景是很复杂的,所以请求的大小和请求路径也各不一样。
以上图为例,下单时候有些用户使用了优惠券,有些用户不是vip会员无法享受折扣,有些商品没有营销活动。这些因素要求我们在构造请求时,需要按照不同的业务场景构造不同的请求。
所谓的流量模型,其本质是按照业务场景的不同将请求按照真实的比例进行配置,也称之为业务配比。
大家也可以将流量模型理解为压测模型,工作中常见的压测模型有如下几种:
单机单接口基准测试
基准测试最常见的就是对登录场景进行压测。
单机单接口的压测,可以通过梯度递增的方式,观察随着请求的增加,其性能表现&资源损耗的变化。
单机混合链路容量测试
以上图为例,订单服务包含创建订单、取消订单、订单列表、订单详情等接口。
每个接口的请求量大小、请求内容各不相同。单机混合场景,大多通过梯度增加请求的方式,观察服务级别的性能表现,目的是排查上下游调用依赖的瓶颈。
生产环境全链路压测场景
针对生产集群的全链路压测,常见的案例就是双11电商大促。生产全链路压测模型较多,一般有如下几种:
梯度加压:为了探测集群模式下系统的最大吞吐量(避免压垮服务,造成事故);
固定并发:验证系统长期处于负载下的稳定性;
脉冲并发:探测系统的健壮性、验证限流熔断等服务保护措施的正确性&可用性;
超卖验证:对电商业务来说,主要针对一些限时抢购&秒杀的场景(一般这种场景,会涉及到分布式锁、缓存、数据一致性等技术点;玩不好的话,容易造成客诉、资损、甚至服务异常宕机!);
构建流量模型
这是之前实际工作中一次双11大促时的流量模型构建案例,仅供参考。
业务目标:双11当天,预估平均客单价为500,单日GMV为10亿,那么支付订单量为10亿/500=200W;
技术指标:
假设日常支付订单量为50W,支付转化率为40%,订单支付QPS峰值为200。预估大促时的支付转化率为60%,则可得:大促峰值订单支付QPS为(200/40%)60%(200W/50W)=1200QPS。为了留有一定冗余空间,上浮30%,即订单支付的QPS预估为1500;
电商的导购下单支付链路为:首页→商品详情→创建订单→订单支付→支付成功,这是类似漏斗的一个转化逻辑。假设首页→商品详情转化率为40%,商品详情→创建订单转化率为40%,创建订单→订单支付转化率为40%,那么可得:创建订单QPS为1500/40%=3750,商品详情QPS为3750/40%=9375,首页QPS为9375/40%=23437;
按照核心链路之间的依赖调用关系,借助trace追踪,可得到大促期间所有核心应用及核心链路的QPS数值。
建议评估后流量模型后,结合业务场景和服务间的调用关系,绘制成一个流量模型图,这样会更直观,便于工作开展。
数据模型
了解了业务模型和流量模型后,数据模型就很好理解了。
以上图为例,电商下单业务在构建数据模型时,要根据压测时常、压测次数和压测场景,准备不同类型的数据。
在准备数据时,还要考虑数据的有效性、数据量级、数据的组合逻辑关系以及数据是否符合生产环境的数据分布等情况。
如果测试过程中采用的数据不准确,那测试结果往往出现较大偏差。关于测试数据模型构建,可参考如下几点:
| 数据信息 | 说明 |
|---|---|
| 限制条件 | 用户操作权限、数据引用次数、数据过期设定(次数、绝对时间) |
| 数据量 | 实际生产环境的数据量为多少,在性能测试环境如何等量代换 |
| 数据类型 | 基础数据、热点数据、缓存数据、特殊数据 |
| 数据特点 | 是否可以复用、是否具有唯一性、自增、加密、拼接、转义等 |
| 准备方式 | copy真实环境数据、预埋铺底数据、脱敏生成数据 |
基础数据
也称为铺底数据,铺底数据目的是与线上保持一致(至少数量分布一致),再结合线上增长率,确认预埋数据量级及预埋方式。
涉及到压测时需要校验的数据,需要在铺底的时候就要精细化的设计,包括数据大小、数量、分布。
热点数据
需要了解被测接口的实现逻辑,确认以下信息:
是否有热点数据相关的操作:比如说所有用户秒杀同一件商品;
不同类型数据处理逻辑有差异时,需通过测试数据多样化提高性能测试代码覆盖率;
缓存数据
要确认是否有缓存,缓存大小。
秒杀抢购相关数据,一般来说都是进行队列处理,将该类型数据放入缓存中进行处理来应对高并发。
再比如用户登录所需的token等数据,在压测时,可以提前将构造好的数据预热到缓存,避免压测时用户服务成为瓶颈。
构建数据模型
构建数据模型的目的,最直观的就是压测时候的测试数据参数化。
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通
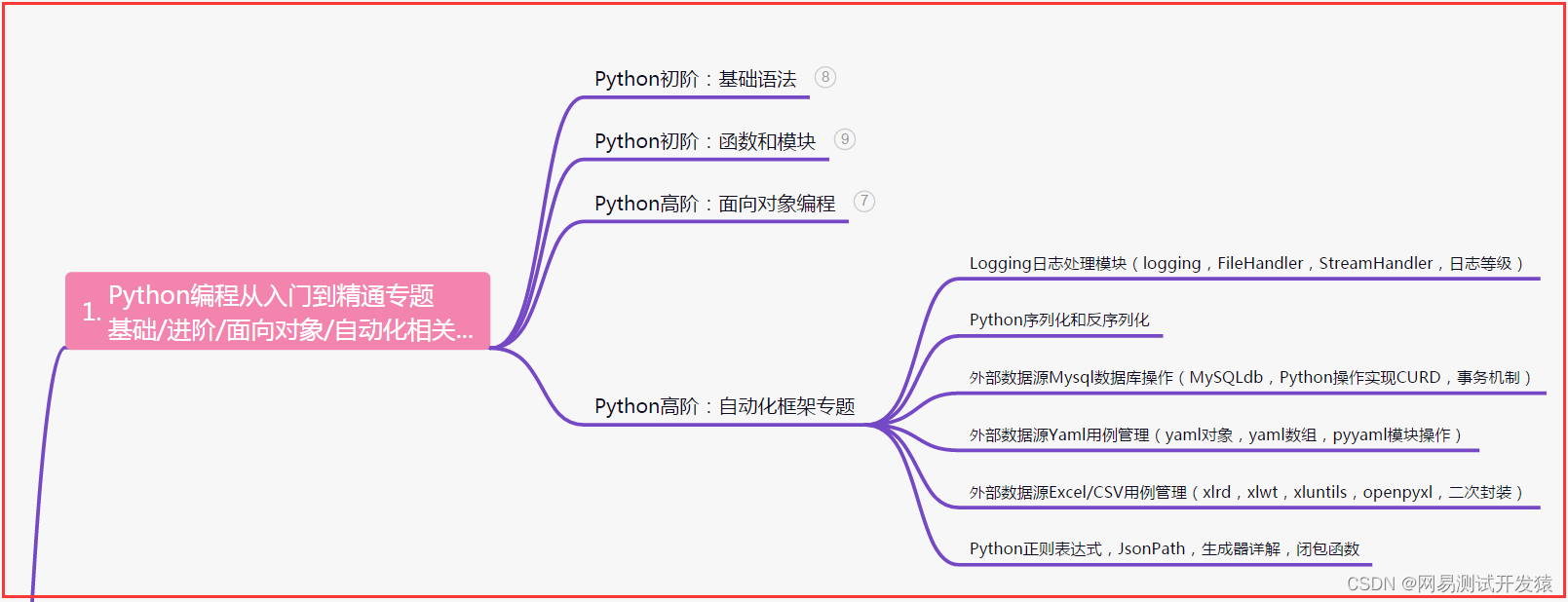
二、接口自动化项目实战
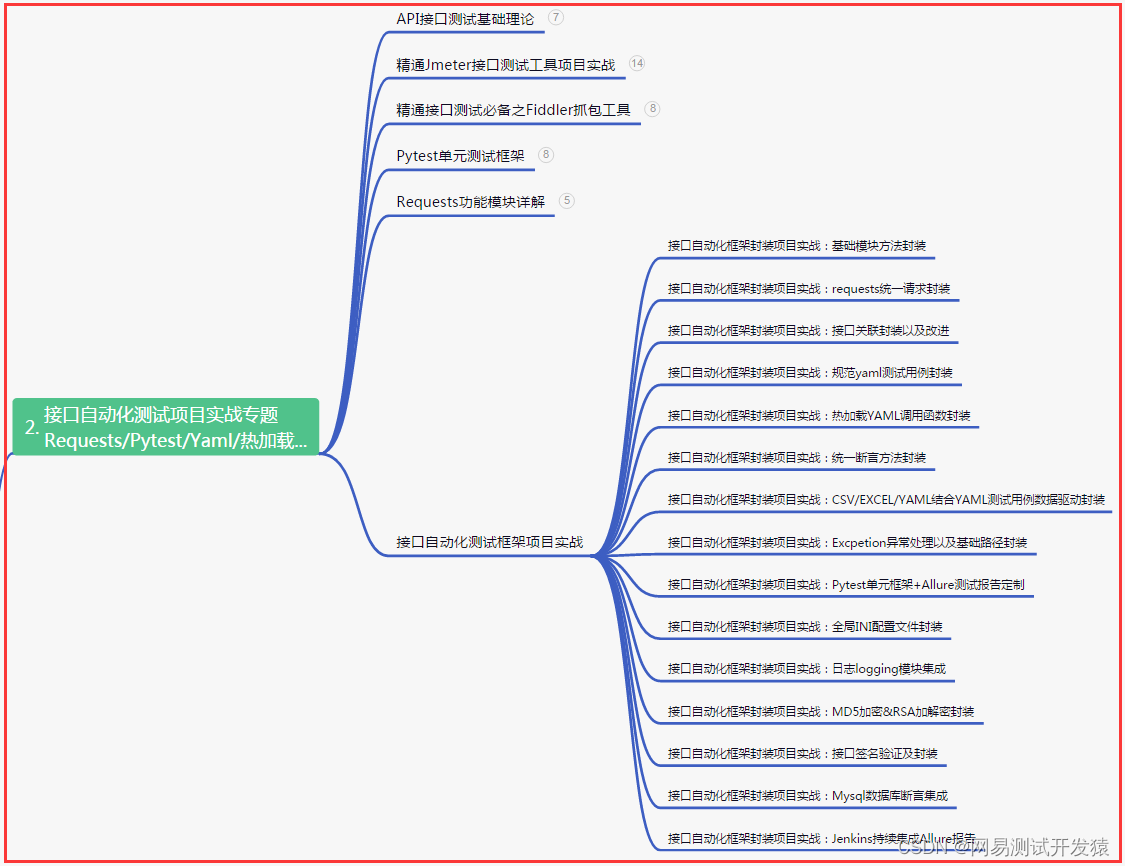
三、Web自动化项目实战
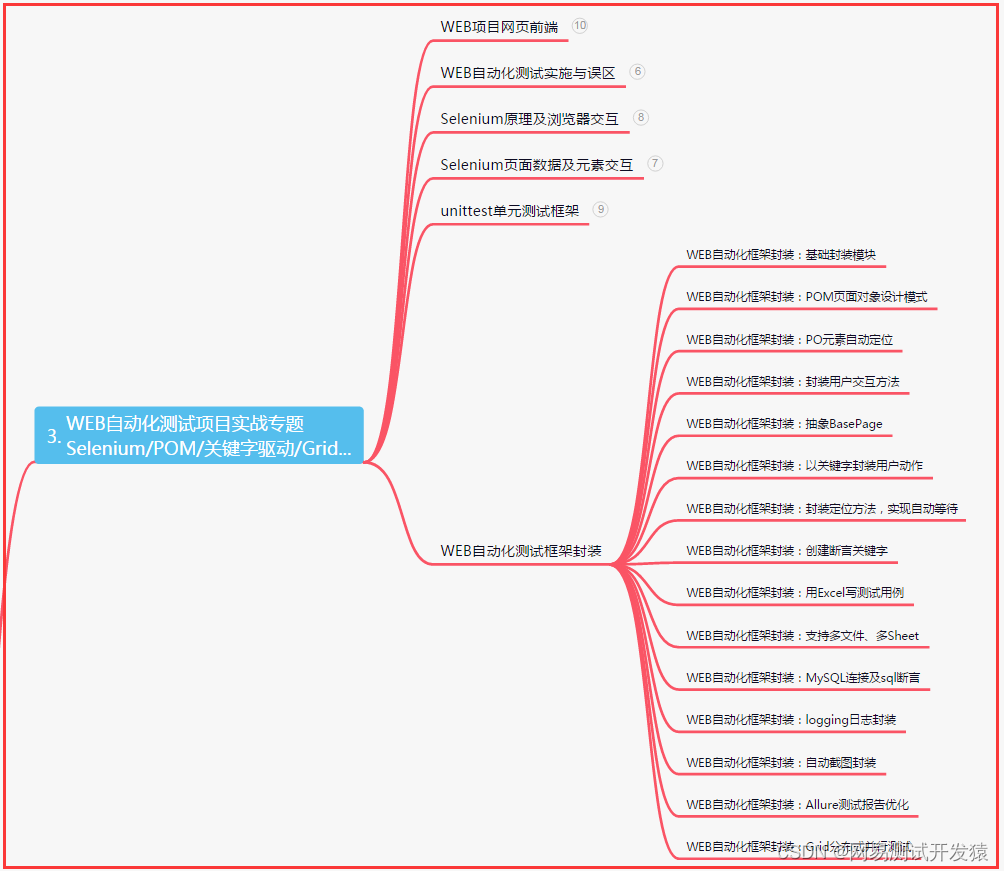
四、App自动化项目实战
五、一线大厂简历
六、测试开发DevOps体系
七、常用自动化测试工具

八、JMeter性能测试
九、总结(尾部小惊喜)
生活就像一场马拉松,要想走的更远,忍耐力和毅力不可或缺。在一路奋斗的过程中,我们会遇到挫折和失败,但只要坚持不懈地追寻理想,不断前行,就能收获美好与成功。怀着信心、热情和勇气,努力追求人生目标!
人生如一场修行,每天都在积累经验、学习成长。只有克服挑战和困难,才能超越自我,成就非凡。让我们勇敢面对挑战,持之以恒地努力,创造属于自己的辉煌人生!
成功不是结果,而是一个过程,是每天坚定信念和持续努力的体现。当困难与挫折来临时,我们需要有一颗沉稳勇敢的心,勇敢迎接人生挑战。让我们在奋发拼搏的路上,创造出不屈的品质和辉煌的人生!