一,基础环境
os:linux,python:3.7+,torch:1.8+
GitHub地址:https://github.com/open-mmlab/mmsegmentation
二,安装依赖
2.1 安装MMCV
pip install -U openmim
mim install mmcv-full
2.2 安装MMsegmentation
方式一:git安装
git clone https://github.com/open-mmlab/mmsegmentation.git
方式二:下载压缩包本地解压安装
download mmsegmentation-master.zip
2.3 pip install -v -e .
cd到mmsegmentation目录下执行:pip install -v -e .
(注:不要忽略了最后的点)
2.4 安装其他依赖
pip install -r requirements.txt
pip install labelme(用于后续转换标注数据)
三,自定义数据集(VOC格式)
3.1 VOC目录结构:
mmsegmentation-master
│ │── data
│ │ ├── VOCdevkit
│ │ │ ├── VOC2012
│ │ │ │ ├── JPEGImages
│ │ │ │ │ ├── image1.jpg
│ │ │ │ │ ├── image2.jpg
│ │ │ │ │ ├── image3.jpg
│ │ │ │ ├── SegmentationClass
│ │ │ │ │ ├── mask1.png
│ │ │ │ │ ├── mask2.png
│ │ │ │ │ ├── mask3.png
│ │ │ │ ├── ImageSets
│ │ │ │ │ ├── Segmentation
│ │ │ │ │ │ │ ├── train.txt
│ │ │ │ │ │ │ ├── val.txt
JPEGImage:原始图像
SegmentationClass:标注图像
ImageSets/Segmentation:训练验证txt文件,存储图片的文件名
其它数据集格式目录结构:
https://github.com/open-mmlab/mmsegmentation/blob/master/docs/en/dataset_prepare.md#prepare-datasets
3.2 数据集处理
labelme标注文件为json格式,需要将json格式转换为png格式的mask图片
3.2.1 数据准备
创建如下结构的文件夹存放原始图片和json格式的标注文件:
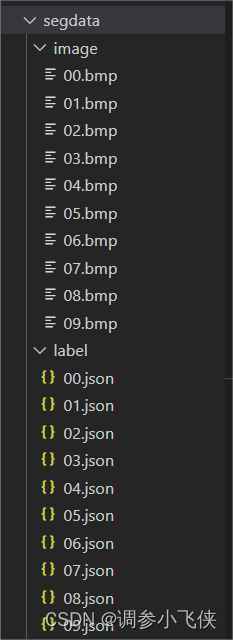
3.2.2 标注文件格式转换(json-png)
为了后续训练,需要将labelme标注的json格式文件转换为png格式文件
转换代码如下(需要labelme中的一些依赖,所以前面安装了labelme)
import argparse
import base64
import json
import os
import shutil
import os.path as osp
import imgviz
import PIL.Image
from labelme.logger import logger
from labelme import utils
def main(in_file, out_dir):
logger.warning(
"This script is aimed to demonstrate how to convert the "
"JSON file to a single image dataset."
)
logger.warning(
"It won't handle multiple JSON files to generate a "
"real-use dataset."
)
parser = argparse.ArgumentParser()
parser.add_argument("--json_file", default=in_file)
parser.add_argument("-o", "--out", default=out_dir)
args = parser.parse_args()
json_file = args.json_file
if args.out is None:
out_dir = osp.basename(json_file).replace(".", "_")
out_dir = osp.join(osp.dirname(json_file), out_dir)
else:
img_name = json_file.split(os.sep)[-1].split('.')[0]
out_dir = os.path.join(args.out, img_name)
print('out_dir:: ', out_dir)
if not osp.exists(out_dir):
os.mkdir(out_dir)
data = json.load(open(json_file))
imageData = data.get("imageData")
if not imageData:
imagePath = os.path.join(os.path.dirname(json_file), data["imagePath"])
with open(imagePath, "rb") as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode("utf-8")
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {
"_background_": 0}
for shape in sorted(data["shapes"], key=lambda x: x["label"]):
label_name = shape["label"]
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
lbl, _ = utils.shapes_to_label(
img.shape, data["shapes"], label_name_to_value
)
label_names = [None] * (max(label_name_to_value.values()) + 1)
for name, value in label_name_to_value.items():
label_names[value] = name
lbl_viz = imgviz.label2rgb(
lbl, imgviz.asgray(img), label_names=label_names, loc="rb"
)
PIL.Image.fromarray(img).save(osp.join(out_dir, "img.png"))
utils.lblsave(osp.join(out_dir, "{}.png".format(img_name)), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, "label_viz.png"))
with open(osp.join(out_dir, "label_names.txt"), "w") as f:
for lbl_name in label_names:
f.write(lbl_name + "\n")
logger.info("Saved to: {}".format(out_dir))
def cp_file(src_im, src_ms, dst_im, dst_ms):
for im in os.listdir(src_im):
impath = os.path.join(src_im, im)
shutil.copy(impath, dst_im)
for ms_dir in os.listdir(src_ms):
mspath = os.path.join(src_ms, ms_dir, '{}.png'.format(ms_dir))
shutil.copy(mspath, dst_ms)
if __name__ == "__main__":
im_path = './segdata/image'
js_path = './segdata/label'
ms_path = './segdata/mask'
if not os.path.exists(ms_path):
os.makedirs(ms_path)
for js in os.listdir(js_path):
js_file = os.path.join(js_path, js)
print('js_file: ', js_file)
main(js_file, ms_path)
voc_img = './data/VOCdevkit/VOC2012/JPEGImages'
vov_lab = './data/VOCdevkit/VOC2012/SegmentationClass'
cp_file(im_path, ms_path, voc_img, vov_lab)
需要修改的地方:
js_path:输入的json文件路径
ms_path:输出的mask文件路径
转换后会生成一个mask文件夹,其中每个子文件夹(对应每张图片)中的label.png就是我们需要的png格式的标注文件,
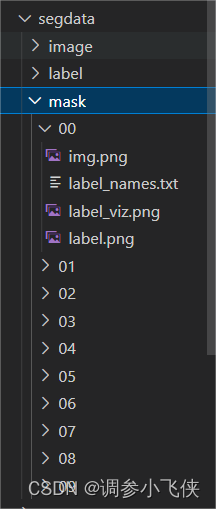
通过cp_file函数将转换后的mask标注文件和原始图像文件分别放在SegmentationClass和JPEGImages文件夹中,图像文件名和标注文件名要对应。
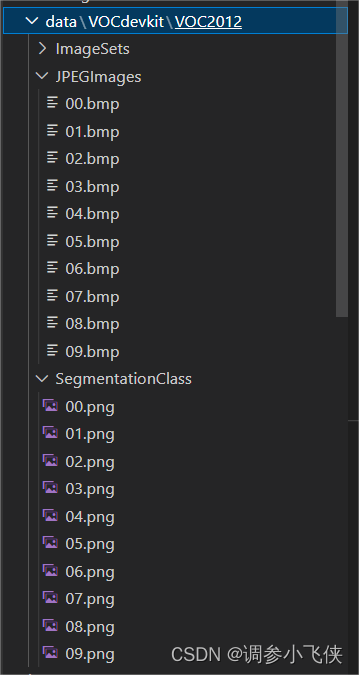
3.2.3 数据集划分(train/val)
数据集划分代码如下
import os
import random
import math
def main(imgdir, labdir, setdir, val_ratio, img_type):
datasets = []
for msk in os.listdir(labdir):
fname = msk.split('.')[0]
if '{}{}'.format(fname, img_type) in os.listdir(imgdir):
# print(msk)
datasets.append(fname)
# print(datasets)
random.seed(1)
total_nums = len(datasets)
val_num = math.ceil(val_ratio * total_nums)
val_indices = random.sample(range(total_nums), val_num)
print(val_indices)
f_train = open(os.path.join(setdir, 'train.txt'), 'w')
f_val = open(os.path.join(setdir, 'val.txt'), 'w')
for idx, names in enumerate(datasets):
if idx in val_indices:
f_val.write(names + '\n')
else:
f_train.write(names + '\n')
f_train.close()
f_val.close()
if __name__ == '__main__':
imgdir = './data/VOCdevkit/VOC2012/JPEGImages'
labdir = './data/VOCdevkit/VOC2012/SegmentationClass'
setdir = './data/VOCdevkit/VOC2012/ImageSets/Segmentation'
val_ratio = 0.2 # 验证集划分比例,训练集划分比例为1-val_ratio
img_type = '.bmp' # 原始图片的图片格式
main(imgdir, labdir, setdir, val_ratio, img_type)
数据集路径按VOC目录结构先定义好,将数据集划分为训练集和验证集
需要修改的地方:
val_ratio:验证集划分比例,训练集划分比例为1-val_ratio
img_type:原始图片的图片格式
注:以上代码记得将img_type换成你自己数据集原始图片的格式,后续在MMSegmentation配置文件中也需要修改图片格式,默认为’.jpg’格式。
最后会在路径data\VOCdevkit\VOC2012\ImageSets\Segmentation中生成train.txt和val.txt文件。
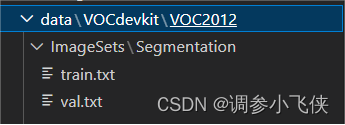
四,模型训练
4.1,修改configs/hrnet/fcn_hr18_512x512_20k_voc12aug.py(修改类别)
复制并重命名fcn_hr18_512x512_20k_voc12aug.py为fcn_hr18_512x512_20k_voc12aug_custom.py
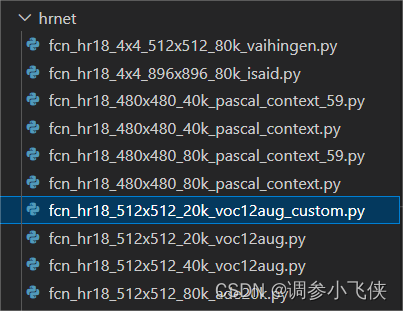
修改fcn_hr18_512x512_20k_voc12aug_custom.py:

将num_classes修改为自定义的类别数,背景类也算一类
4.2 修改configs/base/models/fcn_hr18.py(修改类别)

4.3 修改configs/base/datasets/pascal_voc12_aug.py和datasets/pascal_voc12.py
1,复制并重命名datasets/pascal_voc12_aug.py为
datasets/pascal_voc12_aug_custom.py
2,复制并重命名datasets/pascal_voc12.py为
datasets/pascal_voc12_custom.py
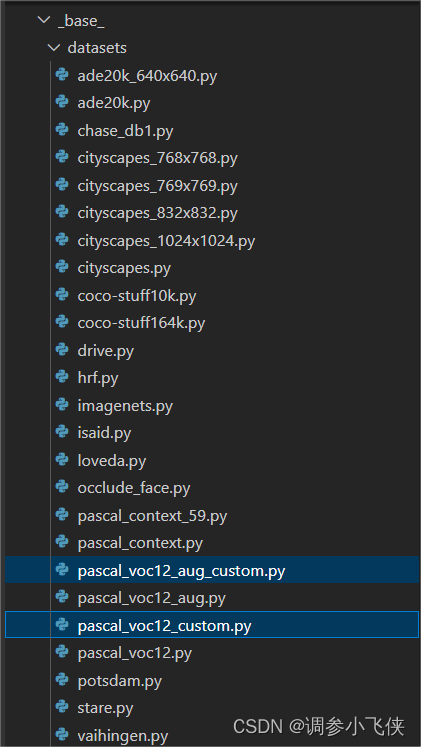
修改datasets/pascal_voc12_aug_custom.py
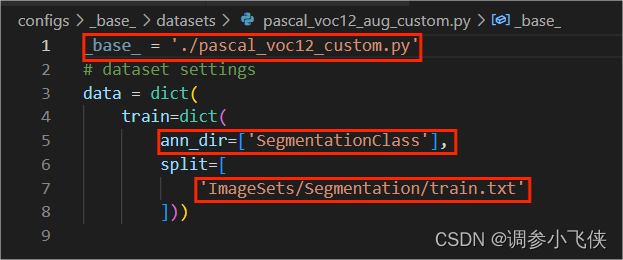
4.4 mmseg/datasets/voc.py(修改标签名称CLASSES, 修改标签颜色PALETTE,修改原始图片格式)
4.5 其他基础参数修改
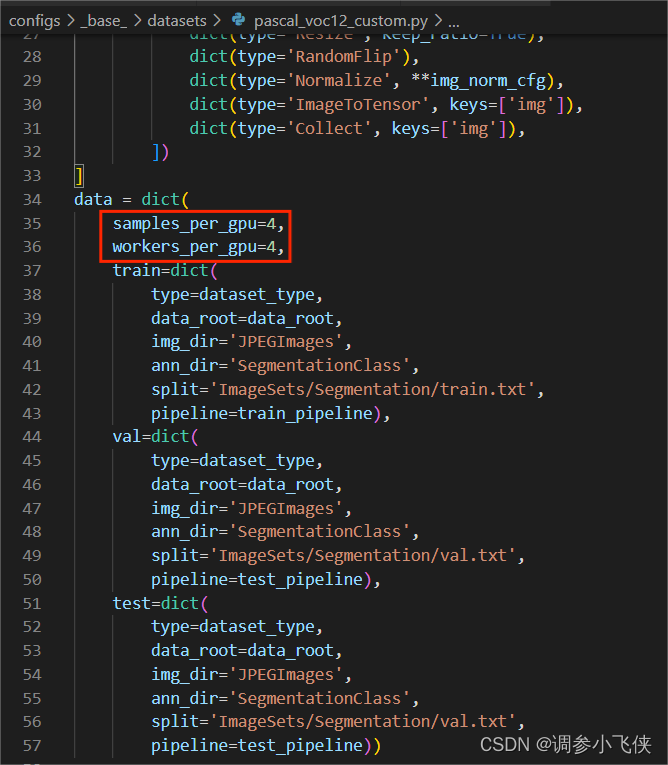
1,修改训练batchsize和numwork
修改configs/base/datasets/pascal_voc12_custom.py:samples_per_gpu=4, workers_per_gpu=4
2,修改训练策略参数
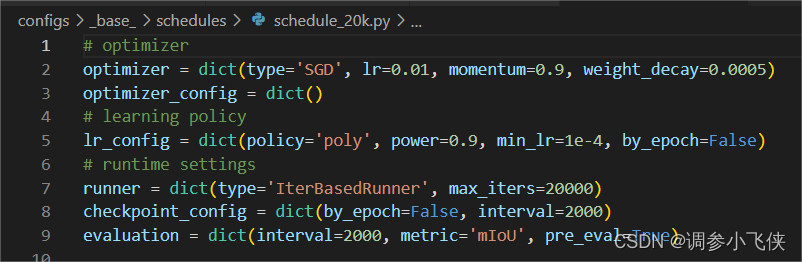
修改configs/base/schedules/schedule_20k.py中
模型优化器参数:optimizer
训练迭代次数:runner
保存权重的步长:checkpoint_config
模型验证参数:evaluation
4.6 开始训练
训练代码如下:
python tools/train.py configs/hrnet/fcn_hr18_512x512_20k_voc12aug_custom.py
四,模型推理
推理代码如下:
import os
from mmseg.apis import inference_segmentor, init_segmentor
# 配置文件路径
config_file = 'work_dirs/fcn_hr18_512x512_20k_voc12aug_custom/fcn_hr18_512x512_20k_voc12aug_custom.py'
# 权重文件路径
checkpoint_file = 'work_dirs/fcn_hr18_512x512_20k_voc12aug_custom/iter_2000.pth'
# 加载模型
model = init_segmentor(config_file, checkpoint_file, device='cuda:0')
img = './cat.bmp' # 推理图片的路径
# 开始推理
result = inference_segmentor(model, img)
# 显示推理结果
model.show_result(img, result, show=True)
# 保存推理结果
model.show_result(img, result, out_file='result_{}'.format(img.split('/')[-1]), opacity=0.5)