目录
1. 介绍
本文使用resnet 34作为backbone代替传统unet的 vgg,实现对PASCAL VOC的分割
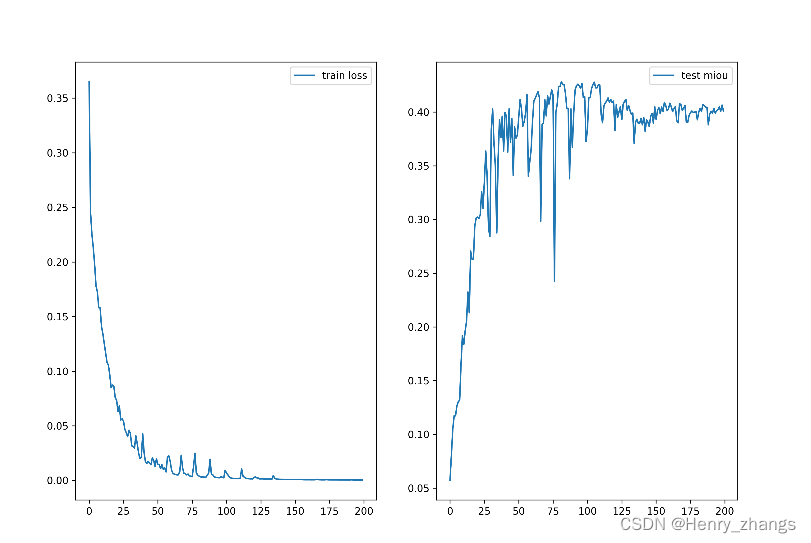
训练了两百个epoch后,mean iou到达了0.4左右,没有达到预期的效果
完整的下载地址:基于UNnet 对 PASCAL VOC 的分割
扫描二维码关注公众号,回复:
15166804 查看本文章

目录结构如下:
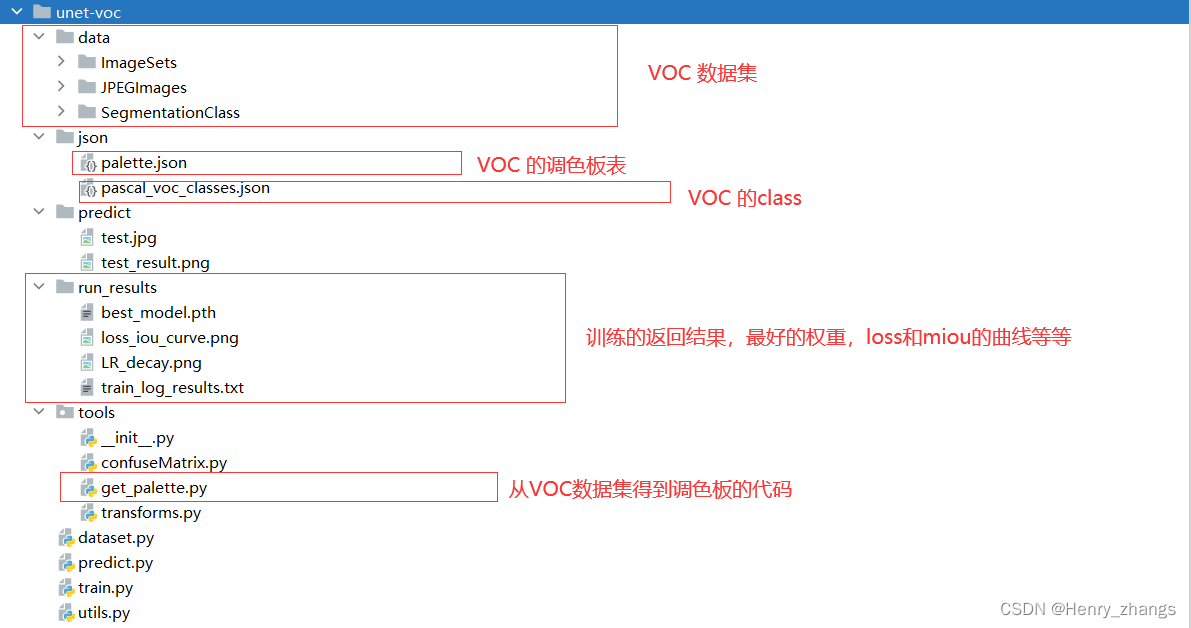
2. tools 代码文件夹
由于本人的习惯,这里放置项目需要的模块
本章,tools 文件夹主要有三个文件
- confuseMatrix 通过混淆矩阵去评估网络的性能
- get_palette 得到VOC数据集的调色板对照表
- transforms 自定义的语义分割的数据增广实现
2.1 get_palette
代码如下:
import json
import numpy as np
from PIL import Image
# 随机传入一张 label图片,读取mask标签,运行一次即可
target = Image.open('../data/SegmentationClass/2007_000032.png')
# 获取调色板
palette = target.getpalette()
print(palette)
palette = np.reshape(palette, (-1, 3)).tolist()
# 转换成字典子形式
pd = dict((i, color) for i, color in enumerate(palette))
json_str = json.dumps(pd)
with open("../json/palette.json", "w") as f:
f.write(json_str)
这里Image.open 只需要传入一张图片就行了,且整个项目只需要运行一次,生成的json文件如下:

2.2 transform
代码如下:
import numpy as np
import torch
from torchvision import transforms as T
from torchvision.transforms import functional as F
class Compose(object):
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, image, target):
for t in self.transforms:
image, target = t(image, target)
return image, target
# 将图像和标签缩放
class Resize(object):
def __init__(self, size:list):
self.size = size
def __call__(self, image, target):
image = F.resize(image, self.size)
target = F.resize(target, self.size, interpolation=T.InterpolationMode.NEAREST)
return image, target
# 转为Tensor
class ToTensor(object):
def __call__(self, image, target):
image = F.to_tensor(image)
target = torch.as_tensor(np.array(target), dtype=torch.int64) # 不需要缩放,变成 tensor 就行
return image, target
class Normalize(object):
def __init__(self,mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)):
self.mean = mean
self.std = std
def __call__(self, image, target):
image = F.normalize(image, mean=self.mean, std=self.std)
return image, target
这里没有实现过多的预处理,只是实现了一个resize,原因如下
这里使用unet是官方实现的,导入的方式如下
import segmentation_models_pytorch as smp
model = smp.Unet(encoder_name='resnet34',in_channels=3,classes=21)这里需要保证输入的图像size是32的倍数,否则会报错:
![]()
3. train 部分
train 过程的实现较为简单,在可视化数据的时候,有几点需要注意
# 可视化数据
import numpy as np
dataloader = next(iter(train_loader))
img,label = dataloader
print(img.shape,img.dtype) # torch.Size([2, 3, 384, 512]) torch.float32
print(label.shape,label.dtype) # torch.Size([2, 384, 512]) torch.int64
print(np.unique(label)) # [ 0 4 6 7 9 12 15 20 255]
plot(data_loader=dataloader)因为使用的是交叉熵损失函数,所以label的维度需要比img的维度少1,且dtype是整型的,这里具体的可以参考:聊聊关于分类和分割的损失函数:nn.CrossEntropyLoss()
然后,label的灰度值只能是从0开始的自然数,如果是二分类就是0 1,这里pascal voc是20分类,所以最多是0-20之间的整数。至于255,是voc 自带的边界部分,忽略即可
展示的图像如下
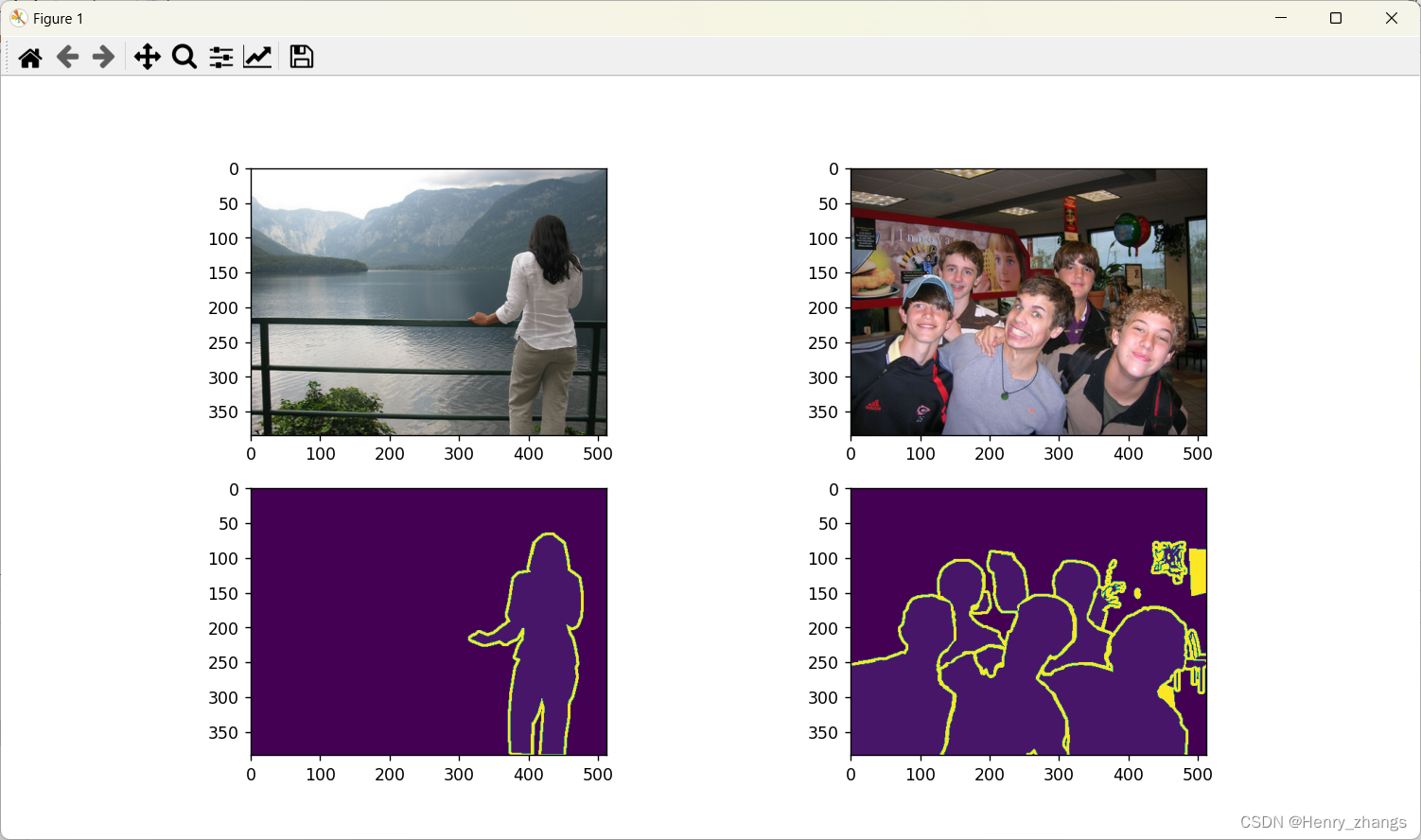
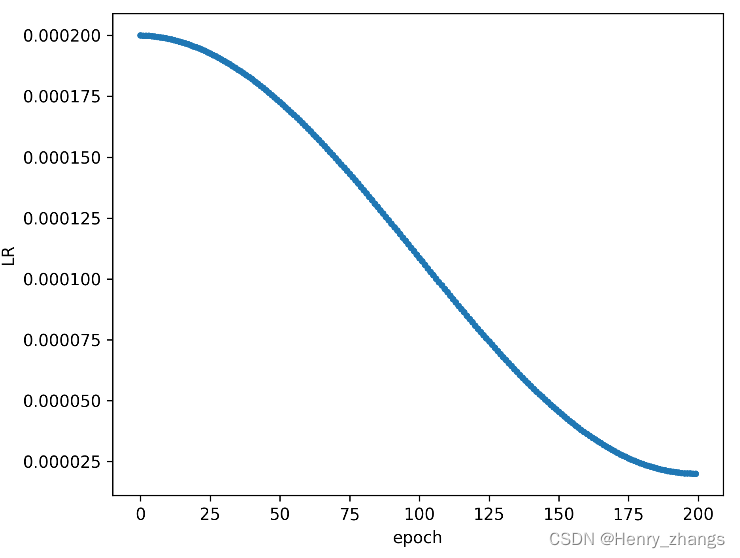
这里使用的学习率下降策略是cos,这里实现了两次,因为第一次需要绘制下降的曲线图,如果没有定义第二次的话,绘制曲线的时候,学习率已经被迭代完了

4. 结果展示
这里训练了 200个epoch,batch size = 4,初始学习率为0.0002,经过200个epoch,衰减为初始的0.1倍
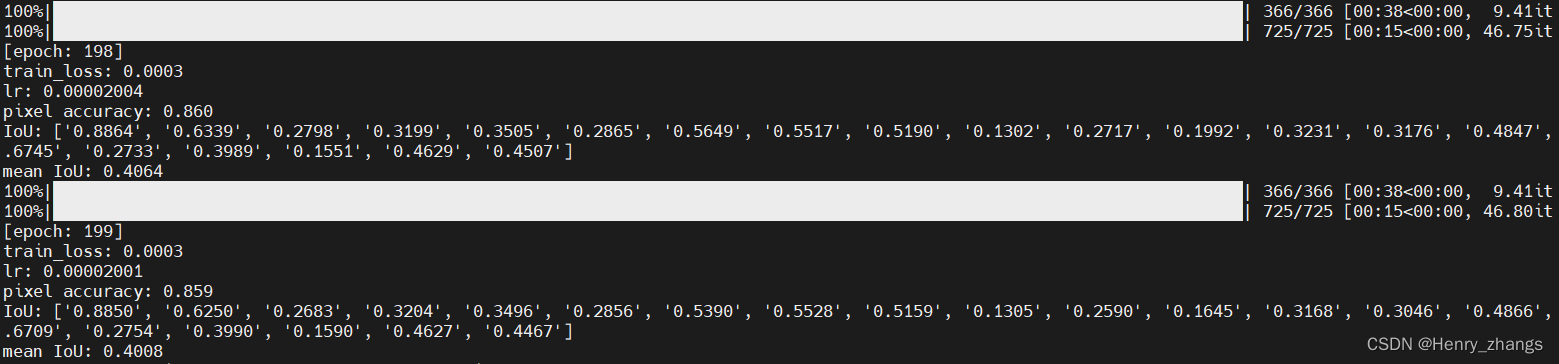
train 的loss曲线以及test 上的miou结果为:
预测单张图像:
