作者 | 智商掉了一地、ZenMoore
关于 P 图,本懒人想说的简直太多了,之前想换个背景总会把主体抠成毛边,随着最近越来越多的强大图像或多模态工具的诞生,人们在图像创作方面的技术实力越来越强大。比如,现在有许多智能 P 图工具,可以自动识别图像中的人物和背景,并将其快速地抠出。
越来越多的基于深度学习的图像生成模型也得到了发展,包括利用 GAN 进行图像生成、将文本转化为图像的模型等等。这些技术的发展,为普通人的图像创作带来了更多的可能性和创造力。而 BLIP-2 在多模态文本生成上的表现已经广为人知,当它与 Diffusion 技术结合使用时,或许会进一步提升“指哪儿改哪儿”的效果。
如图1所示,最近有一篇文章利用预训练的主题表示,在有效的微调或零样本学习的情况下进行主题驱动的生成。此外,该模型还可以作为一种基础的主题驱动的文本到图像生成模型,通过与 ControlNet 和 prompt-to-prompt 等技术相结合,支持控制生成和图像编辑等应用。
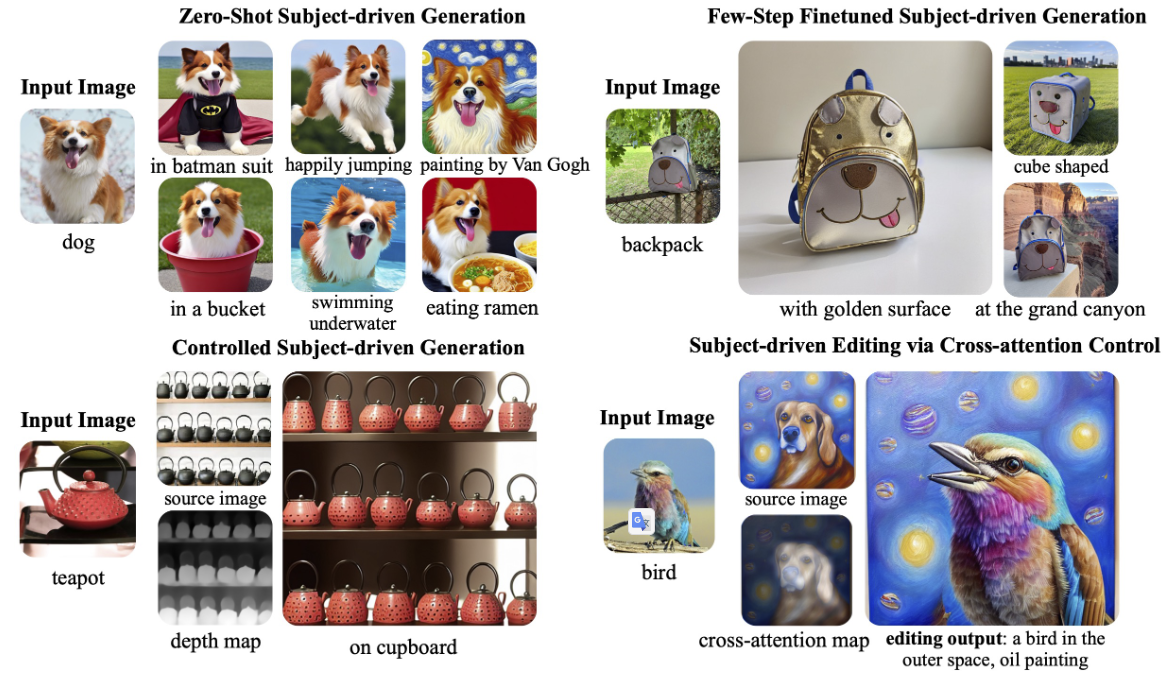
话不多说,咱们先来看看它的 demo 展示~
论文题目:
BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing
论文链接:
https://arxiv.org/abs/2305.14720
Demo 地址:
https://dxli94.github.io/BLIP-Diffusion-website/
代码地址:
https://github.com/salesforce/LAVIS/tree/main/projects/blip-diffusion
大模型研究测试传送门
ChatGPT传送门(免墙,可直接测试):
https://yeschat.cn
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
https://gpt4test.com
Demo 体验
1.主题驱动的文本-图像生成
这里有一项挑战,你能猜出哪个是真正的主题图片吗?
给定一个或几个主题的图像,该模型可以根据文本提示生成主题的新颖呈现。这个在 DreamBooth 数据集上的视觉效果,似乎已经到了能以假乱真的程度!


2.zero-shot 主题驱动的图像操作
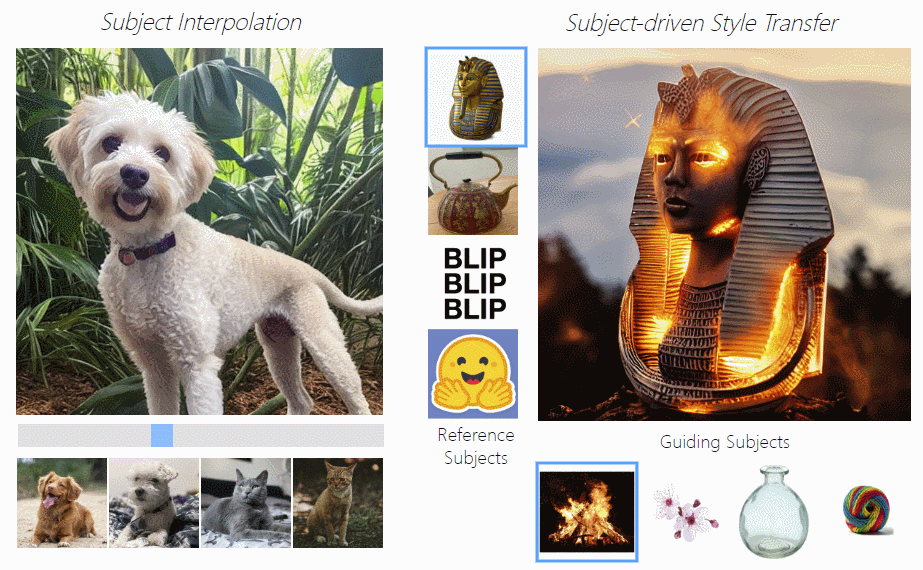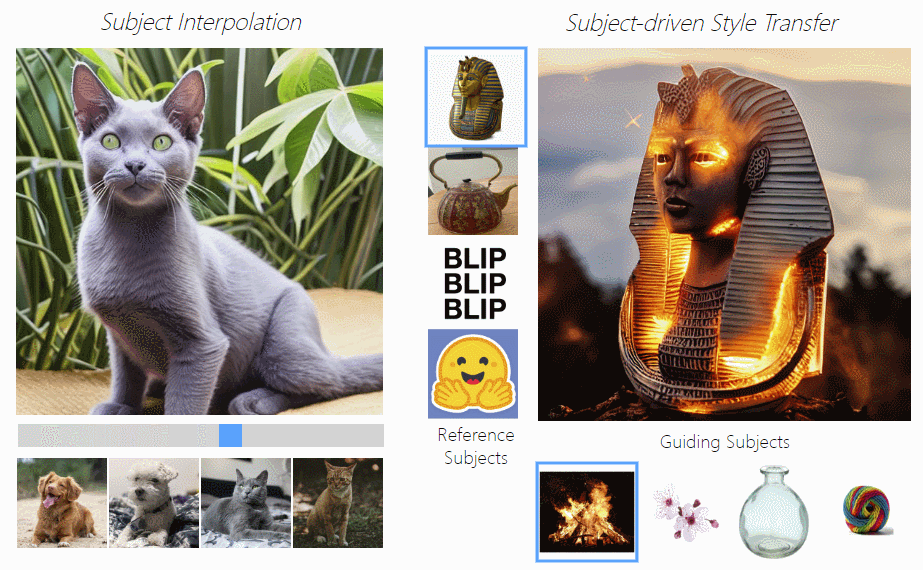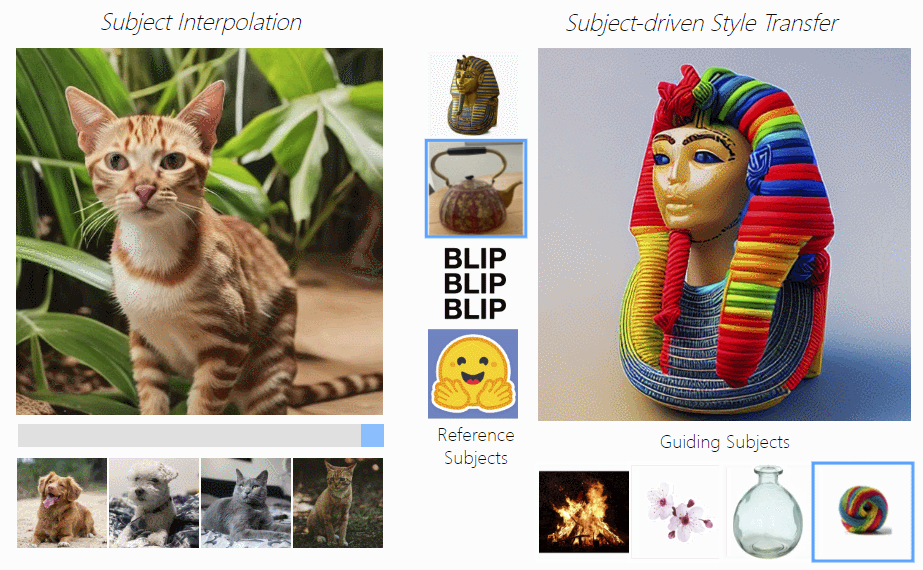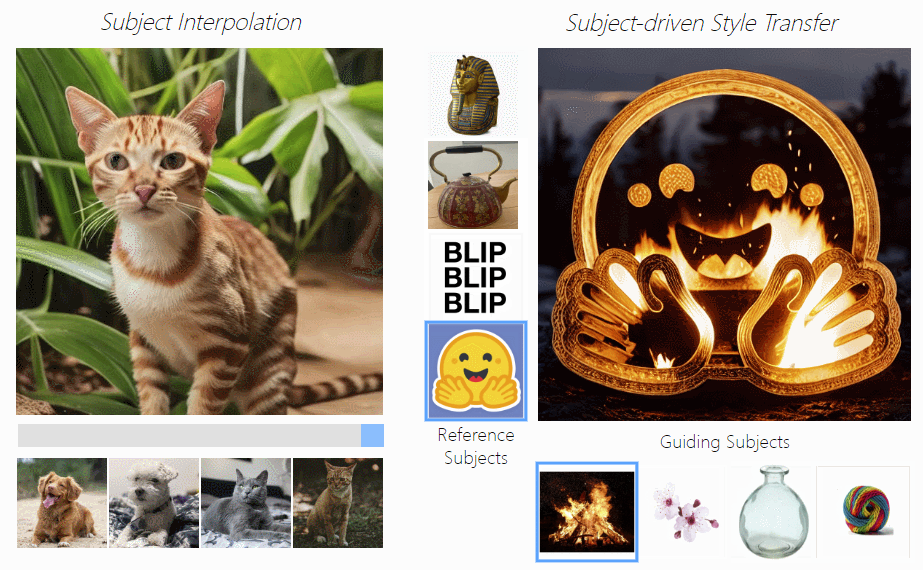
- 主题驱动的样式转移:通过主题嵌入插值实现新主题的创造,比如下图左边,拖动滑动条就能实现狗狗和猫咪之间的切换。
- 主题插值:主题驱动的风格迁移,下图右边可以实现用主题图像(如火焰、花朵、玻璃瓶等)控制图片为指定风格。
3.主题驱动的图像编辑
这是首个由主题驱动的图像编辑模型,通过用一个输入参考图像指定的主题替换文本中指定的另一个主题来编辑源图像。它可以根据用户提供的主题视觉效果进行编辑,无需手动 Mask。而且,编辑后的图有着较为自然的姿势、光线和风格,让图像更加逼真。这群小动物看起来真的是 Q 萌的,比起原图不止一点点可爱!!落日中的草莓蛋糕看起来似乎也没 P 图痕迹!
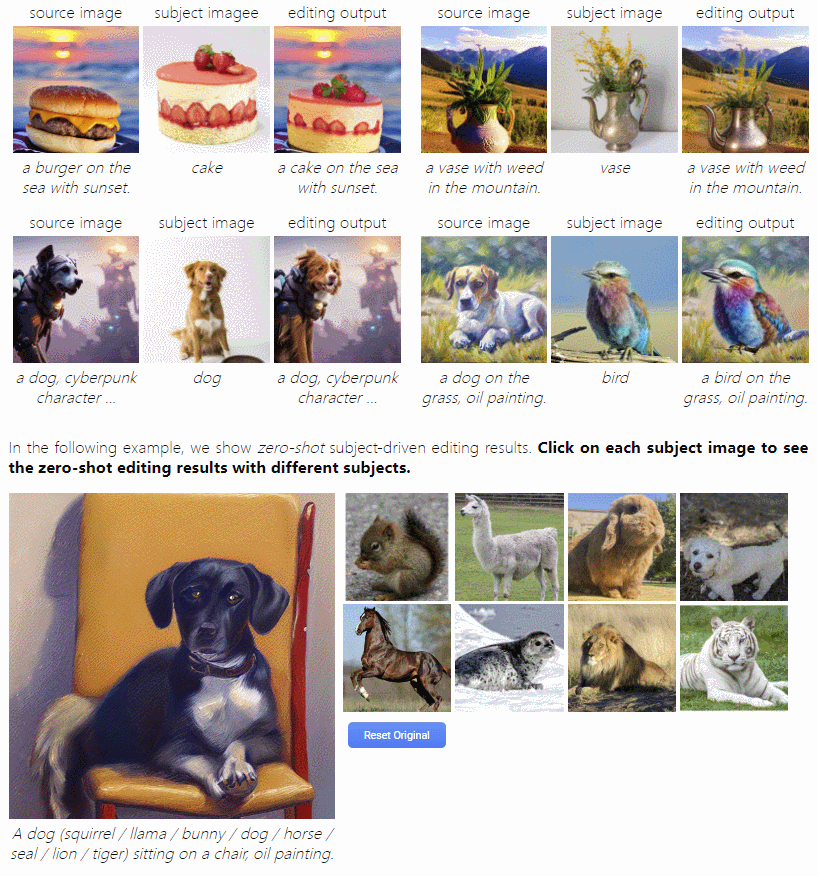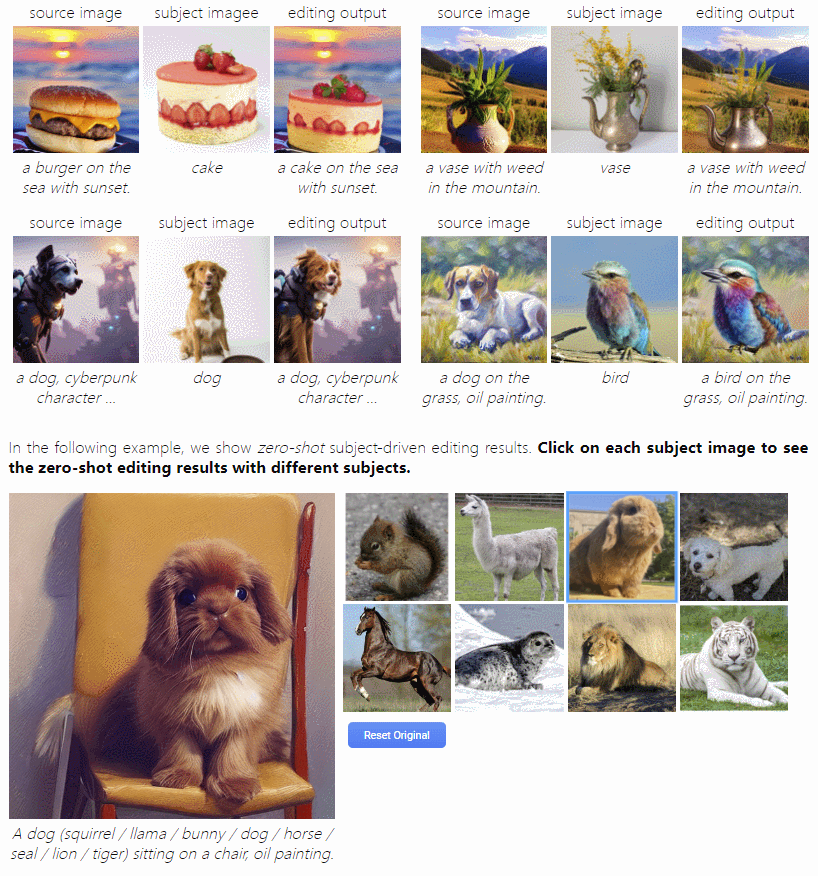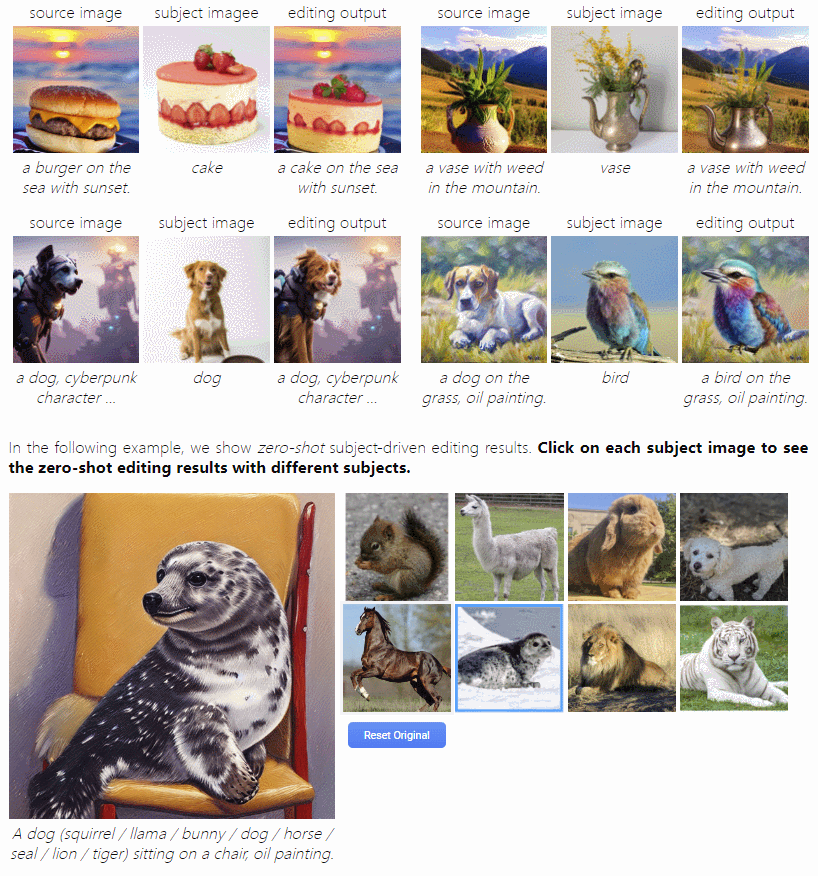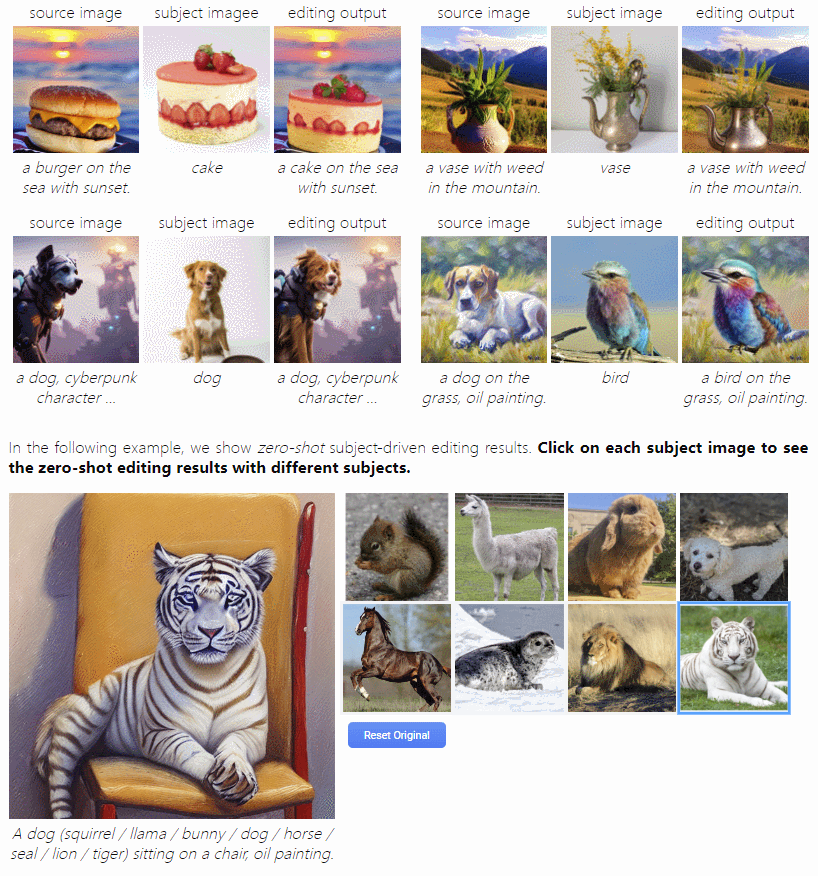
这也意味着用户不需要花费很多时间和精力来编辑图像,只需提供一个主题视觉效果,这个模型就能够自动地生成一个完美的、自然适合的图像,或许能为用户的图像编辑和设计需求带来很大的便利。
论文速览
如图 2 所示,BLIP-Diffusion 的预训练有两个阶段:
- 多模态表示学习阶段:使用 BLIP-2 进行多模态表示学习,为输入的图像产生文本对齐的视觉特征;
- 主题表示学习阶段:训练 Diffusion 模型,以使用 BLIP-2 的特征生成新的主题呈现,即通过组合具有随机背景的主题来合成输入图像。
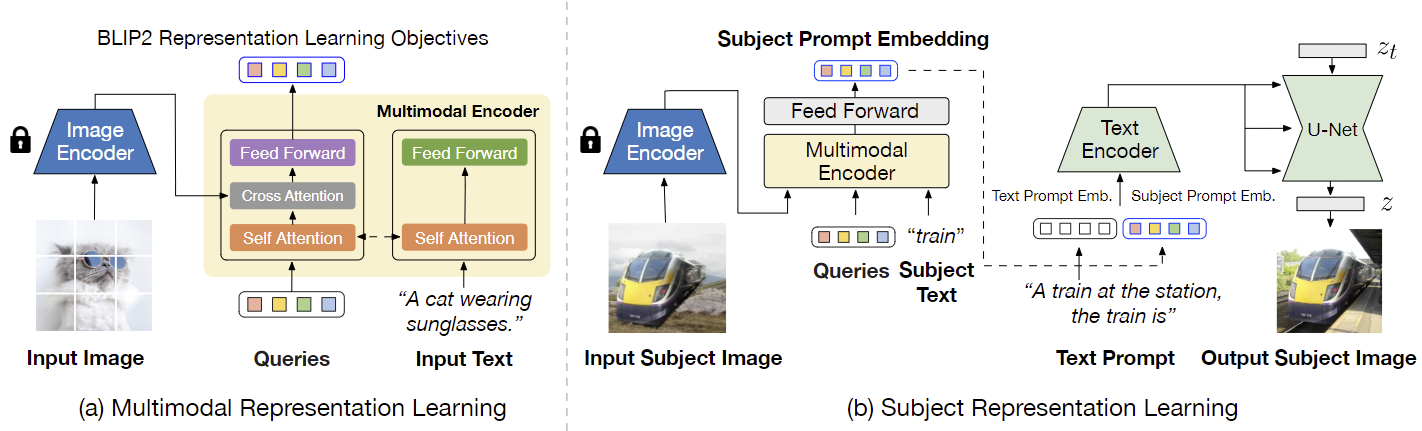
如图 3 所示,这样的合成对将前景主体和背景环境有效地分开,避免了主体不相关信息被编码到主题提示中。

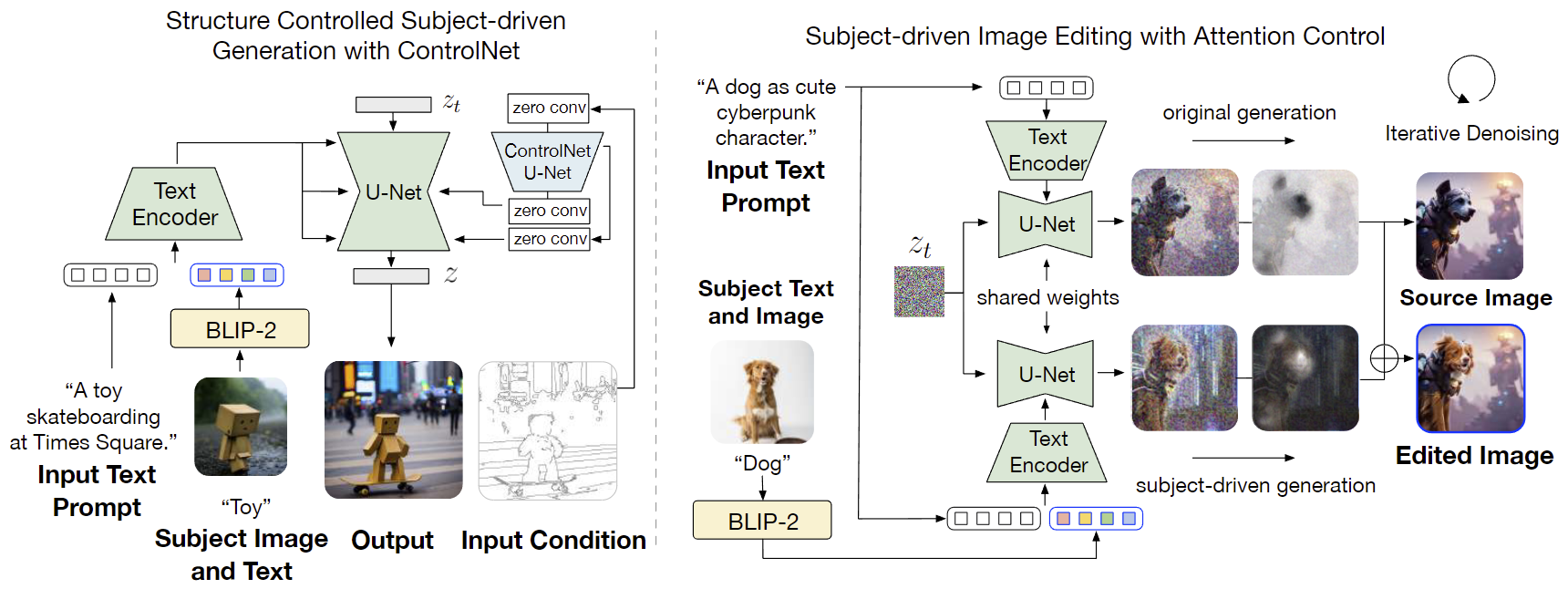
在图 4 中,BLIP-Diffusion 可以通过其他现有的可控生成技术进行即时扩展,以实现更先进的多模态可控图像生成/编辑功能。
- 左边:将 BLIP-Diffusion 和 ControlNet 相结合,实现了结构和主题的可控制生成,这个模型保留了基础扩散模型的建模能力,并且不需要重新调整 ControlNet 参数。
- 右边:则将协同注意力控制技术与 prompt-to-prompt 相结合,可以用于主题驱动的图像编辑,该模型在去噪步骤中演示了混合使用具有主题表示和没有主题表示的潜在映射。
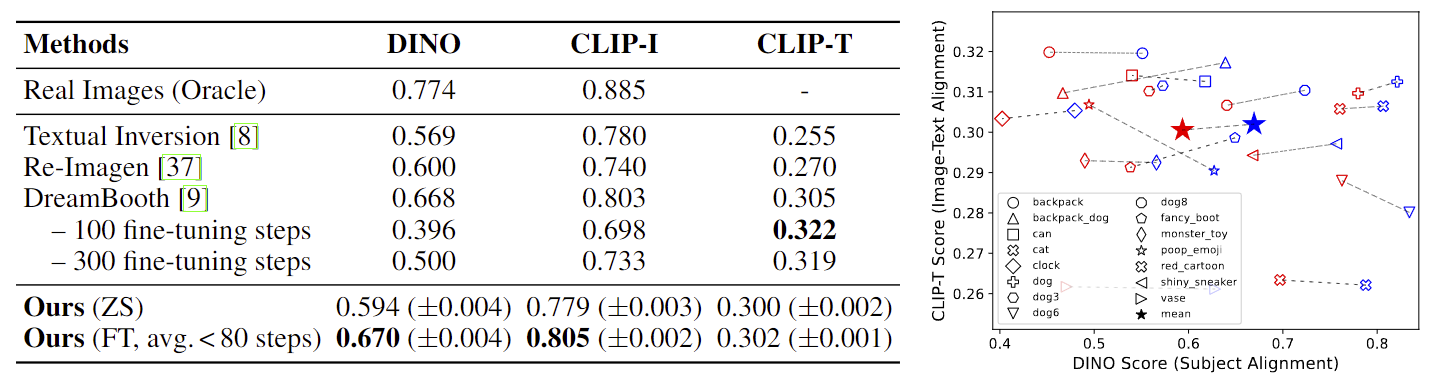
实验结果


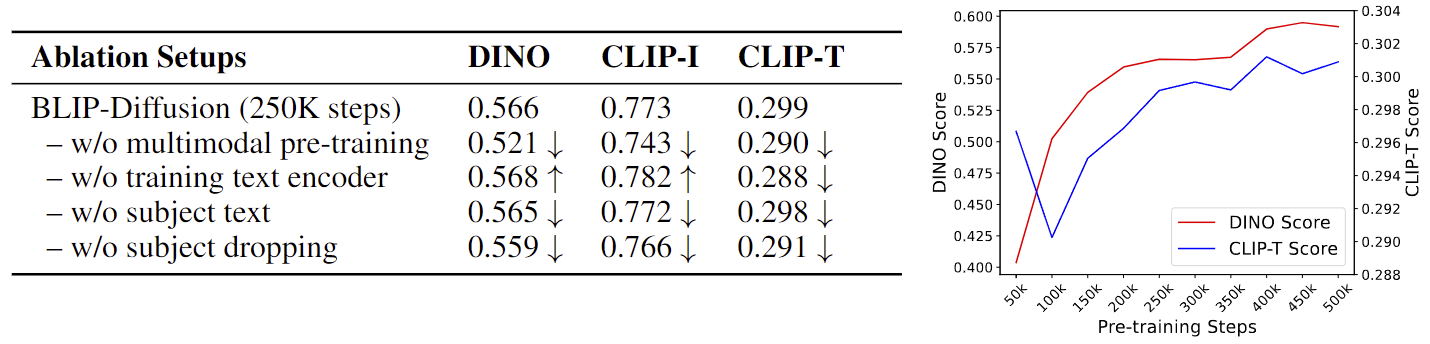
小结
诚如作者所言,BLIP-Diffusion 表明 BLIP-2 是一种相当通用的多模态表示学习框架,与其他主题驱动的生成模型不同,BLIP-Diffusion 引入了一个新的多模态编码器,它经过预训练提供主题表示。它不仅具有最先进的多模态到文本生成能力,而且灵活地与现有技术(如ControlNet 和 prompt-to-prompt)相结合,还可以解锁一系列令人印象深刻的多模态到图像生成能力。
回顾近期的诸多模型与工具,随着多模态技术的不断完善和发展,其在图像创作领域的应用潜力也随之呈现。通过将文本、图像、音频等多种信息进行融合和编码,多模态模型能够生成更加精准和丰富的图像内容。这种技术对与图像相关的行业,例如广告、设计和影视等领域,都是个好消息。也许随着时间的推移,我们可以看到更多多模态模型带来的创新和发展~
