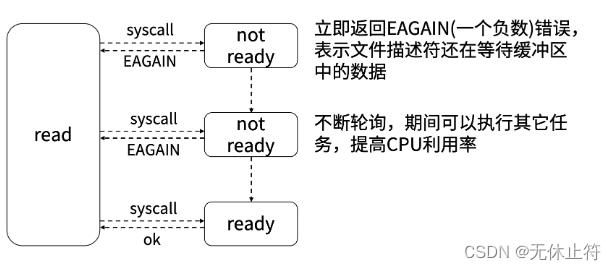
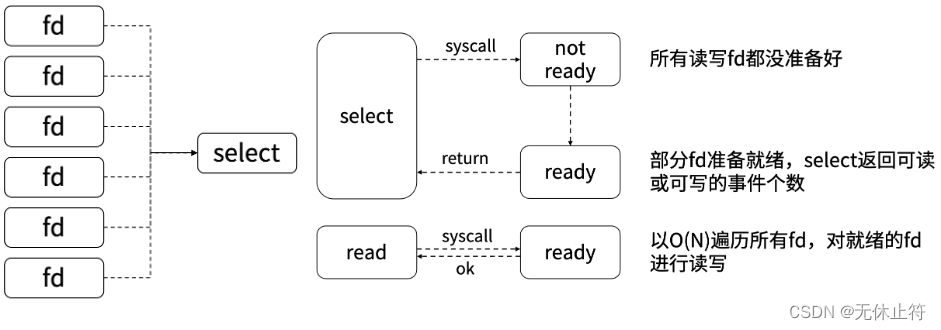
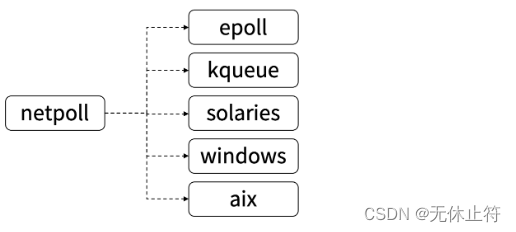
var wg = sync.WaitGroup{
}funcAdd(){
defer wg.Done()//减1
time.Sleep(100* time.Millisecond)
fmt.Println("Add")}funcmain(){
wg.Add(2)//加2goAdd()goAdd()
wg.Wait()//等待为0}
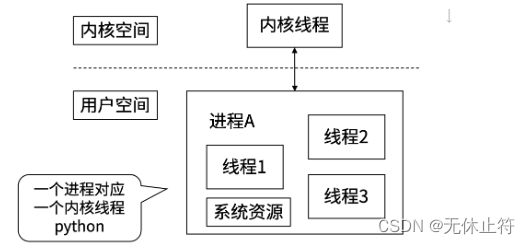
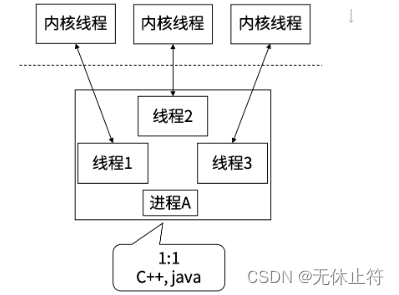
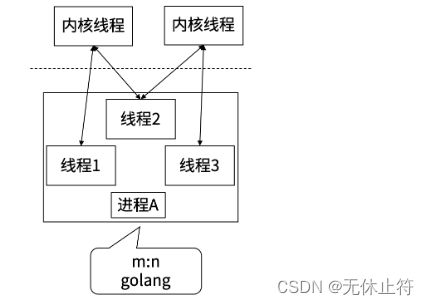
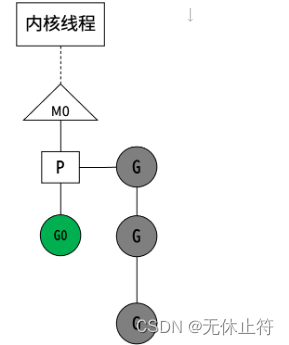
协程之间互不影响:除了main协程退出后,所有协程都会退出;其他的协程之间互不影响
var wg = sync.WaitGroup{
}funcAdd(){
defer wg.Done()//减1goSub()
fmt.Println("over Add")}funcSub(){
time.Sleep(2000* time.Millisecond)
fmt.Println("over Sub")}funcmain(){
wg.Add(2)//加2goAdd()goAdd()
wg.Wait()//等待为0
time.Sleep(5000* time.Millisecond)//等待Sub协程// over Add// over Add// over Sub// over Sub}
funcmain(){
//channel仅作为协程间同步的工具,不需要传递具体的数据,管道类型可以用struct{}//空结构体变量的内存占用为0,因此struct{}类型的管道比bool类型的管道还要省内存
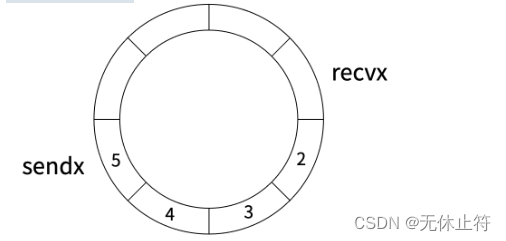
ch :=make(chanstruct{
},1)
ch <-struct{
}{
}//有1个缓冲可以用,无需阻塞,可以立即执行gofunc(){
//子协程1
time.Sleep(5* time.Second)//sleep一个很长的时间<-ch //如果把本行代码注释掉,main协程5秒钟后会报fatal error
fmt.Println("sub routine 1 over")}()//由于子协程1已经启动,寄希望于子协程1帮自己解除阻塞,所以会一直等子协程1执行结束//如果子协程1执行结束后没帮自己解除阻塞,则希望完全破灭,报出deadlock
ch <-struct{
}{
}
fmt.Println("send to channel in main routine")gofunc(){
//子协程2
time.Sleep(2* time.Second)
ch <-struct{
}{
}//channel已满,子协程2会一直阻塞在这一行
fmt.Println("sub routine 2 over")}()
time.Sleep(3* time.Second)
fmt.Println("main routine exit")// sub routine 1 over// send to channel in main routine// main routine exit}
2 - 关闭channel
关闭channel的注意点
只有当管道关闭时,才能通过range遍历管道里的数据,否则会发生fatal error
管道关闭后读操作会立即返回,如果缓冲已空会返回“0值”
ele, ok := <-ch ok==true代表ele是管道里的真实数据
向已关闭的管道里send数据会发生panic
不能重复关闭管道,不能关闭值为nil的管道,否则都会panic
funcmain(){
c :=make(chanint,2)
c <-1
c <-2close(c)//如果不先close会报 -> fatal error: all goroutines are asleep - deadlock!// c <- 3 //关闭管道后继续向管道写入发生panic: send on closed channelfor ele :=range c {
fmt.Printf("%d ", ele)//1 2}//close channel之后,读操作总是立即返回//如果channel里没有元素,则返回对应类型的默认值
v :=<-c
fmt.Println(v)//0}
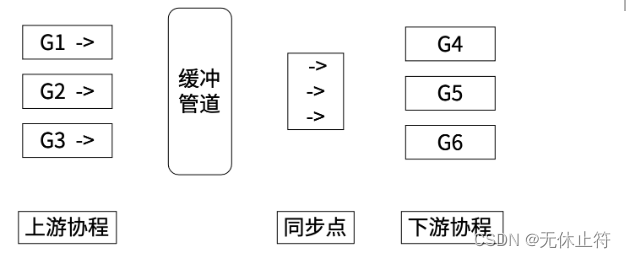
channel的应用
funcupstream(ch chanstruct{
}){
time.Sleep(15* time.Millisecond)
fmt.Println("一个上游协程执行结束")
ch <-struct{
}{
}//写}funcdownstream(ch chanstruct{
}){
<-ch //读
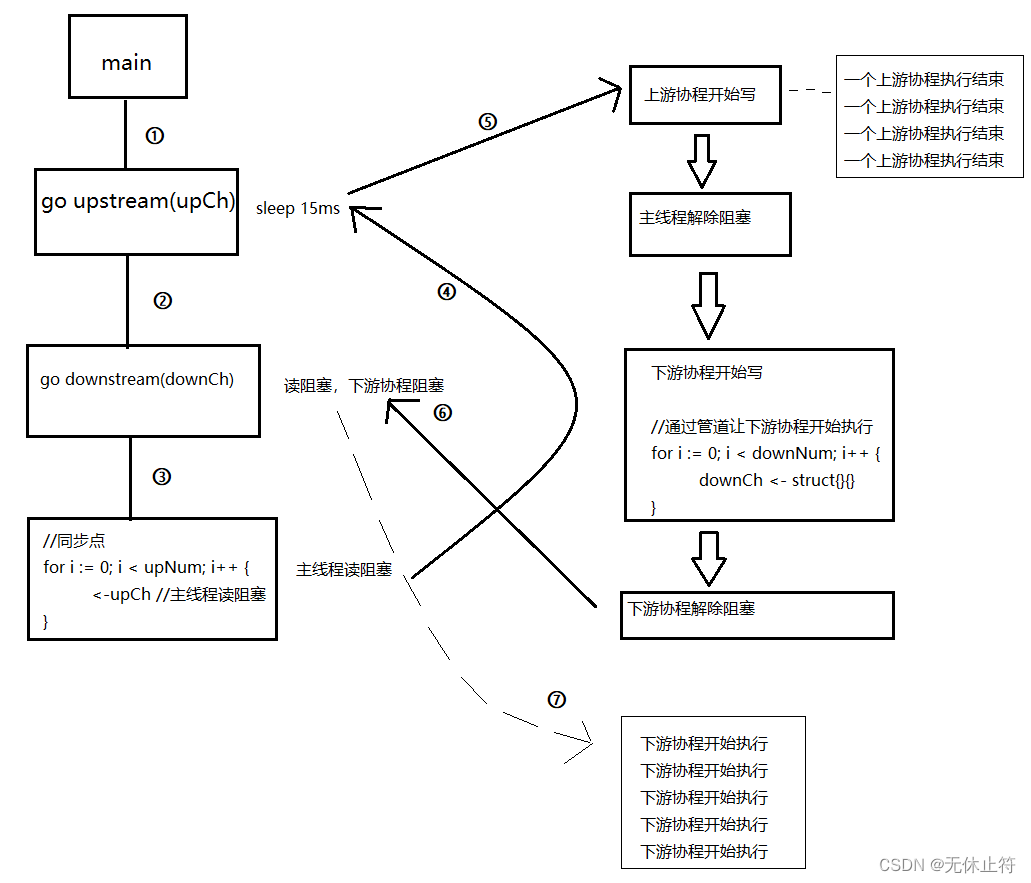
fmt.Println("下游协程开始执行")}funcmain(){
upNum :=4//上游协程的数量
downNum :=5//下游协程的数量
upCh :=make(chanstruct{
}, upNum)
downCh :=make(chanstruct{
}, downNum)//启动上游协程和下游协程,实际下游协程会先阻塞for i :=0; i < upNum; i++{
goupstream(upCh)//time.Sleep(15 * time.Millisecond) 延迟执行}for i :=0; i < downNum; i++{
godownstream(downCh)//读阻塞}//同步点for i :=0; i < upNum; i++{
<-upCh //主线程读阻塞}//通过管道让下游协程开始执行for i :=0; i < downNum; i++{
downCh <-struct{
}{
}}
time.Sleep(10* time.Millisecond)//等下游协程执行结束}
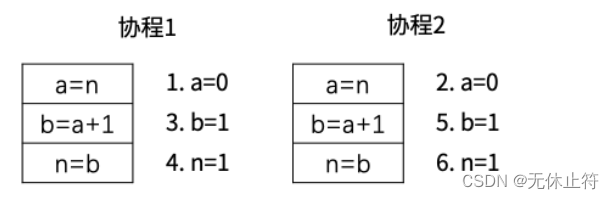
var n intfuncmain(){
wg := sync.WaitGroup{
}
wg.Add(1000)for i :=0; i <1000; i++{
gofunc(){
defer wg.Done()
n++}()}
wg.Wait()
fmt.Println(n)//无论运行多少次都不会到达1000}
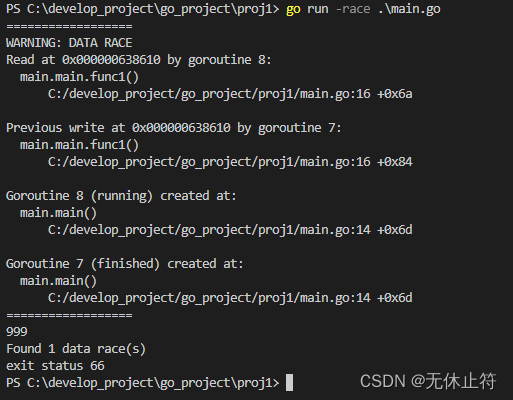
-rece:go run或go build时添加-race参数检查资源竞争情况go run -race .\main.go
2 - 原子操作
原子操作
func atomic.AddInt32(addr *int32, delta int32) (new int32)
func atomic.LoadInt32(addr *int32) (val int32)
var n int32funcmain(){
wg := sync.WaitGroup{
}
wg.Add(1000)for i :=0; i <1000; i++{
gofunc(){
defer wg.Done()
atomic.AddInt32(&n,1)}()}
wg.Wait()
fmt.Println(n)}
3 - 读写锁
读写锁:
var lock sync.RWMutex //声明读写锁,无需初始化
lock.Lock() lock.Unlock() //加写锁和释放写锁
lock.RLock() lock.RUnlock() //加读锁和释放读锁
var n int32var lock sync.RWMutex
funcmain(){
wg := sync.WaitGroup{
}
wg.Add(1000)for i :=0; i <1000; i++{
gofunc(){
defer wg.Done()
lock.Lock()
n++
lock.Unlock()}()}
wg.Wait()
fmt.Println(n)}
//切片和数组一样funcmain(){
lst :=make([]int,5)gofunc(){
for i :=0; i <len(lst); i +=1{
time.Sleep(10* time.Millisecond)
lst[i]=888}}()gofunc(){
for i :=0; i <len(lst); i +=1{
time.Sleep(10* time.Millisecond)
lst[i]=555}}()
time.Sleep(time.Second)
fmt.Println(lst)}// PS C:\develop_project\go_project\proj1> go run .\main.go// [888 888 888 888 888]// PS C:\develop_project\go_project\proj1> go run .\main.go// [888 555 555 555 555]// PS C:\develop_project\go_project\proj1> go run .\main.go// [555 555 555 555 555]// PS C:\develop_project\go_project\proj1> go run .\main.go// [555 555 555 555 555]// PS C:\develop_project\go_project\proj1> go run .\main.go// [888 555 555 555 555]// PS C:\develop_project\go_project\proj1> go run .\main.go// [555 888 888 888 888]//structfuncmain(){
type Student struct{
Age int
Name string}
stu :=new(Student)gofunc(){
for i :=0; i <10; i +=1{
time.Sleep(10* time.Millisecond)
stu.Age =18
time.Sleep(10* time.Millisecond)
stu.Name ="Jack"}}()gofunc(){
for i :=0; i <10; i +=1{
time.Sleep(10* time.Millisecond)
stu.Age =11
time.Sleep(10* time.Millisecond)
stu.Name ="Tom"}}()
time.Sleep(time.Second)
fmt.Println(stu)}// PS C:\develop_project\go_project\proj1> go run .\main.go// &{18 Jack}// PS C:\develop_project\go_project\proj1> go run .\main.go// &{11 Jack}// PS C:\develop_project\go_project\proj1> go run .\main.go// &{11 Tom}
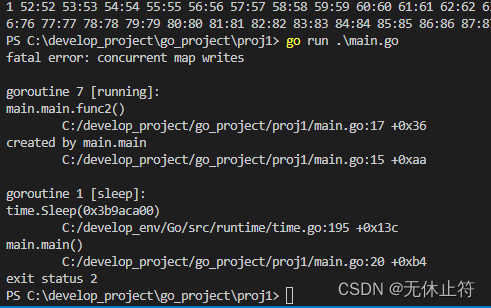
map:并发修改map有时会发生panic
fatal error: concurrent map writes
funcmain(){
mp :=make(map[int]int,10)gofunc(){
for i :=0; i <100; i +=1{
mp[i]= i
}}()gofunc(){
for i :=0; i <100; i +=1{
mp[i]= i
}}()
time.Sleep(time.Second)
fmt.Println(mp)}
sync.Map:如果需要并发修改map请使用sync.Map
funcmain(){
var mp sync.Map
gofunc(){
for i :=0; i <100; i +=1{
mp.Store(i, i)}}()gofunc(){
for i :=0; i <100; i +=1{
mp.Store(i, i)}}()
time.Sleep(time.Second)
fmt.Println(mp.Load(0))}