go语言原生就支持协程,底层就实现了协程调度,高并发是go语言的特性之一。
goroutine原理
线程是操作系统的调度,协程是用户态、用户调度,一个线程之上是可以运行很多协程的。
协程与线程之间的关系
协程:线程=1:1
一个协程绑定一个线程,协程的调度都由CPU完成,等同于线程切换,上下文切换很慢
协程:线程=N:1
N个协程绑定1个线程,协程可以在用户态完成切换,不会陷入到内核态,但是无法利用多核资源
协程:线程=N:M
多个线程同时执行多个协程,可以利用上多核资源,克服了以上两种模型的缺点
协程goroutine是建立在操作系统线程基础之上的,它与操作系统线程之间实现了一个多对多(N:M)的两级线程模型。
G-M模型
go1.0版本之前的协程调度是G-M模型。线程想要执行或放回协程都必须访问全局的G队列,并且线程有多个,因为多线程访问同一资源需要加锁保证互斥和同步,所以全局队列是有互斥锁进行保护的,这会产生锁争抢的问题,并且每个协程的缓存都会保存在内存缓存中,会占用很多的内存空间。因此,在1.12版本之后,采用了G-P-M模型。
G-P-M模型
G表示goroutine协程;P表示processer逻辑处理器;M表示machine线程。
相比G-M模型引入了P逻辑处理器,完善了协程调度模型。
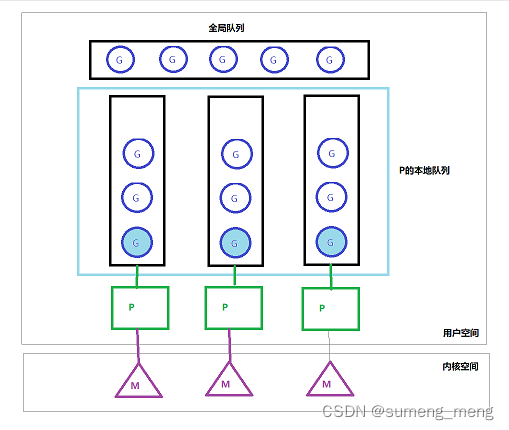
通常情况下每一个运行的处理任务的M,都必须对应着一个P。
这种模型有两种存储G的队列:全局G队列,P对应的本地队列。本地队列满了(上限是256个),自动会往全局队列中放,并且G的缓存保存在P中,即P中保存着本地队列中所有G的缓存,减少了内存的消耗。
1.如何在多核心的系统上尽量合理的分配G,提高并发能力?
go运行时系统会始终保证至少有一个活跃的M和P去绑定各种G队列去处理相应的任务,一般这个活跃的M就称为自旋线程--处于运行状态但是没有可执行的G。
M会先在自己的P队列中查找G任务,如果自己队列里没有,就去全局队列中找G任务处理,如果全局队列没有G任务就去偷其他P队列的任务(偷一半任务)--这种机制称为work stealing机制。
注意:本线程无G执行时,会去偷窃G,而不是直接销毁线程。
2.如果某个M在执行G的过程中被系统调用阻塞了,怎么办?
当M被内核调度器调度出CPU并处于阻塞状态,那么M关联的G就没有办法运行了。go在运行的时候有一个系统监控进程--sysmon线程,能够监控到这种情况,如果遇到阻塞的情况,会让P与M剥离,寻找其他空闲的M或者新建M来接管P,然后继续运行原来队列中的G。
原来的M从阻塞状态恢复之后,会有两种情况:
①、如果有空闲的P则获取一个P,继续执行原本阻塞的G
②、如果没有空闲的P,就将原来阻塞的G加入全局队列,等待被其他的P调度,M就进入缓存池睡眠
这种机制称为hand off机制。
3.如果一个G在M上运行时间过长怎么办?
sysmon进程会监控,如果G运行时间过长,为了防止其他G被饿死的情况,会设置一个超时时间:一个goroutine最多占用CPU 10ms,超过时间就会让运行的G自己主动让出M的执行权。
协程编写
协程底层核心包:runtime包,goroutine就是runtime.g结构体。
runtime.GOMAXPROCS()函数可以设置P的数量,默认情况下P的数量等于CPU核数,当函数传入的参数为0表示当前默认的P数量,传入参数大于0时,表示设置P数量。
go在运行main函数时,就创建了一个协程--主协程,默认情况下主协程结束,子协程也会退出。
例:创建5个协程去请求百度页面,每个请求都睡1s
package main
func mian(){
fmt.Println(time.Now().Unix()) //显示当前时间戳
//请求5次百度页面
for i := 0; i < 5; i++{
go request("https://baidu.com") //开启协程同步执行
}
//睡5s 保证子协程全部执行完,再退出
time.Sleep(5 * time.Second)
}
func request(url string){
client := http.Client{}
r, _ := http.NewRequest("GET", url, nil)
response , e := client.Do(r)
if e != nil{
fmt.Println("发送请求失败!")
return
}
fmt.Println("请求状态码:", response.StatusCode)
defer response.Body.Close() //释放资源
time.Sleep(1 * time.Second)
fmt.Println(time.Now().Unix())
}运行结果:
还可以使用匿名函数的方式创建子协程:
package main
func main() {
//匿名函数的方式创建子协程
go func(){
i := 0
for{
i++
fmt.Println("子协程i =", i)
time.Sleep(1 * time.Second) //睡1s
}
}()
//主协程退出 子协程也退出
for i := 0; i < 3; i++{
fmt.Println("主协程i =", i)
time.Sleep(1 * time.Second)
}
}channel
CSP模型是一种并发编程模型,它不通过共享内存来通信,通过通信来共享内存,channel就是CSP的第一类对象。
channel的特点:channel通道本身就是一个队列,先进先出。channel是引用类型,可以用make初始化,每个channel中只能存放同一种类型的数据。使用channel进行收发操作是在不同的goroutine之间进行的。channel写满的时候不能写,取空的时候不能取,很容易产生死锁,很容易发生阻塞。
1.无缓冲通道--通常用于阻塞
package main
func main(){
fmt.Println("start main......")
//生成一个无缓冲通道 里面只能存放1个int类型的数据
ch1 := make(chan int)
go child(ch1)
fmt.Println("start child")
//从ch1通道里取数据
//要等子协程发送数据后主协程才能获取数据
//主协程会等子协程 起到阻塞当前主协程环境上下文的作用
<- ch1
fmt.Println("get data finish!")
}
func child(ch chan int){
fmt.Println("this is child")
time.Sleep(5 * time.Second)
//存入数据
ch <- -1
}运行结果:
2.有缓冲通道
package main
func main(){
//设置通道容量为6
ch1 := make(chan int, 6)
go senddata(ch1)
//睡5s保证通道里存满数据
time.Sleep(5 * time.Second)
//循环取出数据
for data := range ch1 {
fmt.Println("读取数据", data)
}
}
func senddata(ch chan int){
for i := 0; i < 10; i++{
ch <- i
fmt.Println("往通道里面放数据:", i)
}
defer close(ch)
}3.判断通道关闭的几种方式
以下三种方式的说明均使用相同的senddata()函数:
func senddata(ch chan string){
for i := 0; i < 3; i++{
//格式化存入字符串
ch <- fmt.Sprintf("send data %d", i)
}
//defer 是go中的一种延迟调用机制
defer fmt.Println("数据发送完毕!")
//数据发送完毕主动关闭通道 防止产生死锁 引起程序退出
defer close(ch)
}方式一:
func main(){
ch1 := make(chan string)
go senddata(ch1)
for{
data := <- ch1
//如果通道关闭,读取到的是数据类型的默认值 string类型的默认值是空字符串
if data == ""{
break
}
fmt.Println("从通道里读取到的数据:", data)
}
}方式二:
func main(){
ch1 := make(chan string)
go senddata(ch1)
for{
data, ok := <- ch1
//ok为false表示通道关闭
if !ok{
break
}
fmt.Println("获取到的数据:", data)
}
}方式三:
func main(){
ch1 := make(chan string)
go senddata(ch1)
//range会自动判断通道是否关闭,关闭了就会break
for value := range ch1{
fmt.Println("获取到的数据:", value)
}
}select语句
select语句会监听通道的数据,挑选可通信的channel执行代码,如果同时有多个可通信的channel,就随机挑一个;没有可通信的channel就执行default后面的代码。类似于switch case语句。
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go senddata1(ch1)
go senddata1(ch2)
//睡一秒让数据存入ch1 ch2中
time.Sleep(1 * time.Second)
flag := 0
for {
select {
case data1, ok1 := <-ch1:
if !ok1 {
fmt.Println("数据读取完毕!")
flag++
break //跳出select语句
}
fmt.Println("获取ch1的数据为:", data1)
case data2, ok2 := <-ch2:
if !ok2 {
fmt.Println("数据读取完毕!")
flag++
break
}
fmt.Println("获取ch2的数据为:", data2)
}
if flag == 2 {
return //两个通道都消费完了退出for循环
}
}
}
func senddata1(ch chan int) {
for i:=0; i<10; i++ {
ch <- i
}
defer close(ch)
}sync包
sync提供了一系列的同步互斥锁,如:
sync.Mutex 互斥锁
sync.RWMutex 读写锁
sync.WaitGroup 一个goroutine等待一组goroutine执行完成
sync.Map 并发版本的map
sync.Pool 并发池 负责安全的保存一组对象
示范互斥锁与等待组的应用:
//声明全局变量
var num = 20
var wg sync.WaitGroup //等待组对象
var mutex sync.Mutex //互斥锁对象
func main(){
for i := 0; i < 10; i++{
//设置wg内部的计数器 表示等待的子协程数量 可以累加
wg.Add(1)
name := fmt.Sprintf("协程%d",i)
go modifynum(name, &wg) //创建3个子协程
}
wg.Wait() //阻塞 等待wg内部计数器为0,才会继续进行后续的操作
fmt.Println("执行结束!")
}
//wg为引用类型 执行同一个对象
func modifynum(name string, wg *sync.WaitGroup){
defer wg.Done() //使用wg.Done 减少wg内部的计数器
mutex.Lock() //加互斥锁
fmt.Println(name, "running...")
num ++
fmt.Println("num is", num)
mutex.Unlock() //释放锁
}