作者 | 小戏、Python
凡是与这些林林总总的大模型有过深度亲密交流的,估计都领略过大模型极强的胡编乱造的能力。很多大模型的用户抱着想一探这些目前世界上最接近人工智能的东西真面貌、切身感受它的神乎其技时,却往往被它在很多问题上一本正经的胡说八道给打败。不夸张的说,目前大模型发展真正的限制,有可能并不在于上下文长度、成本、应用等等方面,而是在于这些大模型根深蒂固的机器幻觉。
一个非常有意思的问题可能在于:大模型究竟是否知道自己“不知道一些东西”呢?即大模型是否了解自己在一些未知领域的局限性,而当触碰到自己的知识边界时,可以不采用胡言乱语的说法而是大方承认自己不知道呢?
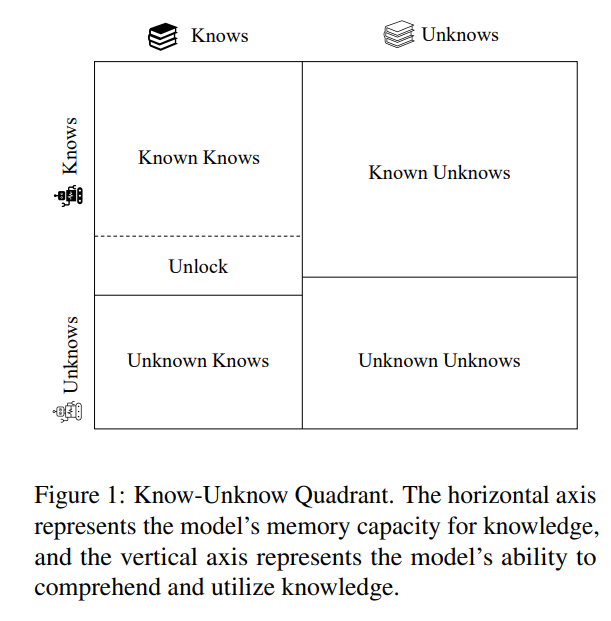
上图构造了一个“Know-Unknow”矩阵,可以帮助我们区分模型对知识的理解与掌握能力,可以看到“Know-Unknow”矩阵分为了四个模块,分别是“知道自己知道”,“不知道自己知道”,“知道自己不知道”以及“不知道自己不知道”,“知道自己知道”与“不知道自己知道”的比值可以用来衡量模型对现有知识的利用能力与熟悉程度,而“知道自己不知道”与“不知道自己不知道”的比值则反应了大模型的“自我认知水平”。
显然,当大模型自我认知能力较差时,它们就会胡言乱语胡说八道,而当大模型自我认知能力较强时,它们才会冷静的判断这个问题是否超出自己的知识边界,给出审慎的回答。那么,问题来了,现有的大模型在“自我认知”这个方面表现如何呢?来自复旦与新国立的学者们为大模型的自我认知能力进行了一次测评,结果却发现,从自我认知水平角度衡量,一般人类的自我认知水平为 84.93%,但是目前最“清醒”的模型 GPT-4 的自我认知水平才仅有 75.47%,与人类的自我认知水平相比存在明显差距,换言之,相比于人类,GPT-4 与其他所有参与测评的 20 余种大模型都存在盲目高估自己认知水平的问题。
大模型研究测试传送门
GPT-4能力研究传送门(遇浏览器警告点高级/继续访问即可):
https://gpt4test.com

具体而言,作者团队首先针对这样一个新颖的“自我认知”问题,构建了一个新的数据集 SelfAware,这个数据集首先选择了 2858 个无法被回答的问题,问题主要来源于 Quora 和 HowStuffWorks,每个问题都经过三个分析员人工评估,确保满足“无法回答”的要求,只有被三个分析人员同时认为无法回答的问题才被归入 SelfAware,共计 1032 个问题。如下图所示,这些问题包含各种类别,比如没有科学依据的问题、纯粹想象的问题、完全主观的问题等等,一般我们认为,大模型在面对这些问题时,应当表达出不确定性,而非给出一个结论性的答案。

同时,作为对照作者还收集了一部分有答案可回答的问题,分别从 SQuAD、HotpotQA、TriviaQA 数据集中选取,共 2337 个问题,这些问题都可以利用维基百科中的知识得到解答,由于维基百科是大模型训练的基础语料,因此可以默认大模型可以解答这类问题。
通过使用 SelfAware 数据集中的问题,作者团队以三种不同的输入模式,分别是直接输入,Prompt 输入与上下文学习输入的方法向大模型展开询问,得到大模型的答案。为了度量这些大模型的答案是否包含我们希望的不确定性,即清楚的表达自己不知道这块的知识,作者团队又构建了一个不确定度量方法,通过构建一个不确定语料库如下:

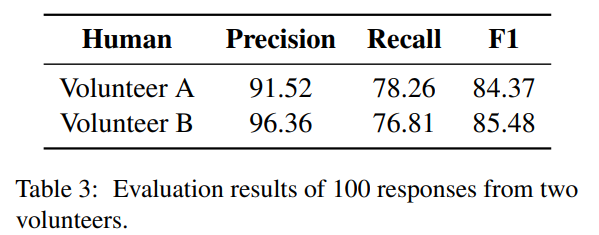
分别使用 SimCSE 计算大模型回答与这 16 种不确定语料的相似度,如果相似度超过某一阈值,则认为大模型表达了不确定性,承认了自己“无知”,最后使用 F1 分数作为综合打分,代表大模型的自知能力。同时,为了以人类作为一个对照,作者又邀请了两位志愿者使用 SelfAware 数据集对人类的自知能力进行了评估,得到了 84.93% 的结果:
而后,作者针对包含 GPT-4,GPT-3,GPT-3.5,LLaMA 系列,Alpaca 等的二十余种模型进行了测评,一个宏观的结果如下图所示:
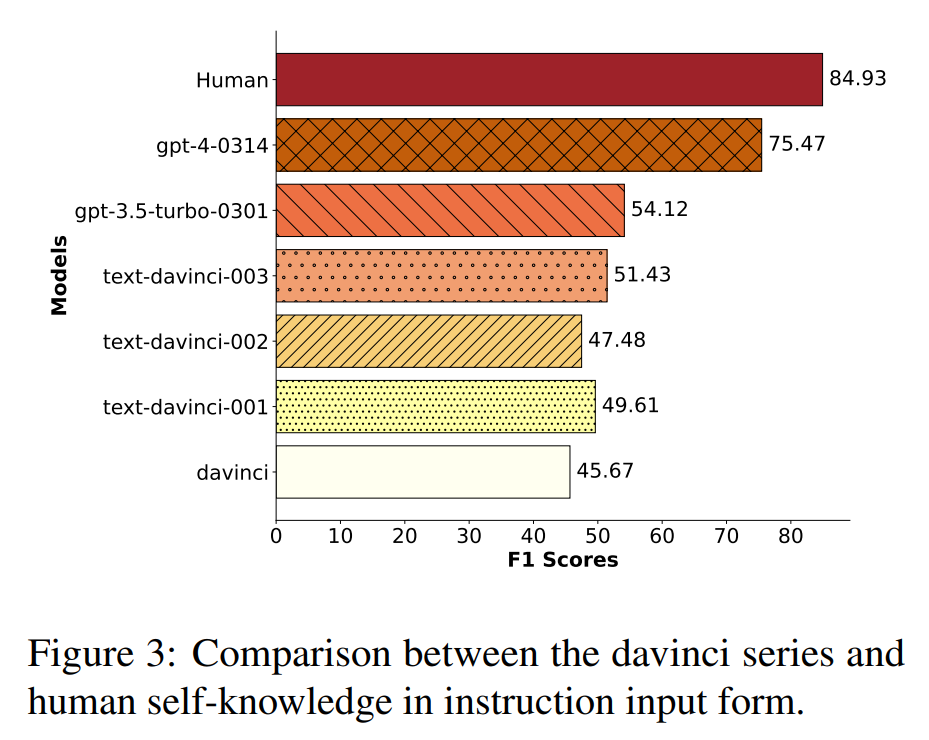
可以看到 GPT-4 依然高居榜首,但是距离人类尚有约 10% 的差距,即表明现在即使是 GPT-4 也仍然面临着自知能力不够强的大问题。而整个 LLaMA 系列的模型自知能力如下所示,距离 GPT 系列模型尚有差距:
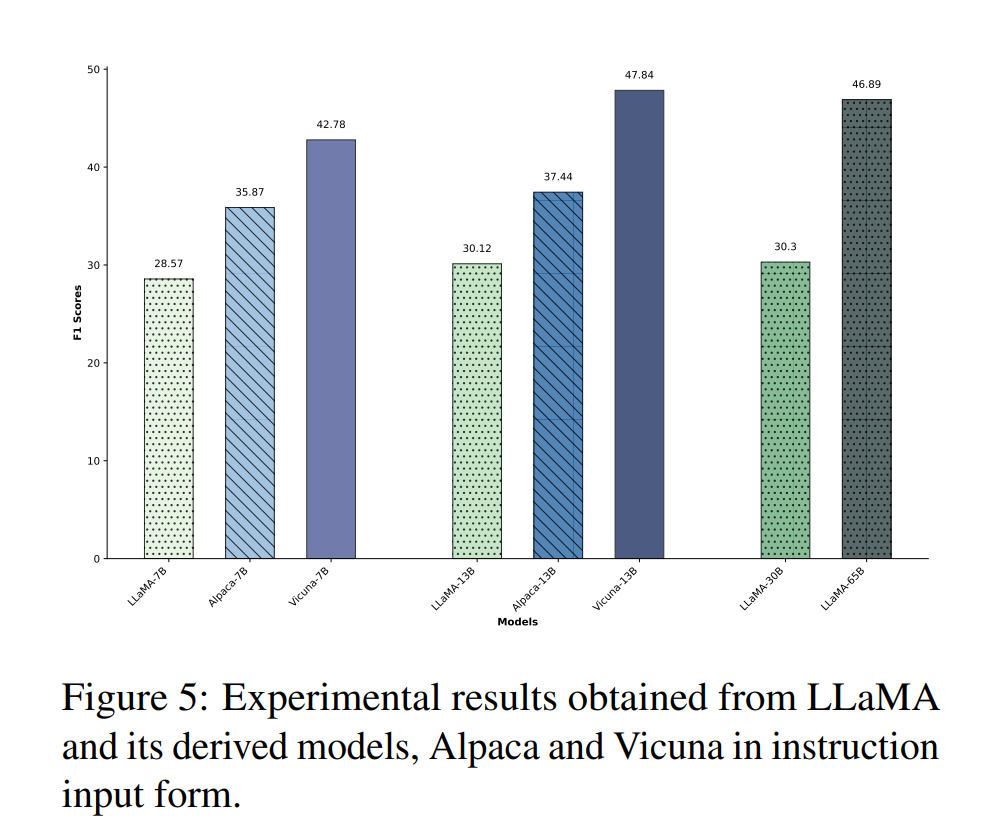
而可视化模型参数与自知能力的关系可以看到,无论采用哪种输入形式,模型参数大小的增加都会导致模型自知能力的提高:

同时,对比不同种的输入方式,也可以看到 Prompt 与上下文学习都可以显著提升大模型的自知能力,尤其是在 davinci 系列模型中,使用上下文学习的形式相比使用直接学习可以提升 27.96% 的性能。而在模型可回答的问题中,随着模型参数的增加,QA 任务的准确率得到飞速提升:

总结与讨论
从某种程度上来讲,这篇论文似乎完成了一个使用精致实验验证我们心中或许已经有答案的一个问题,其实哪怕是 GPT-4 也依然无法很好的解决机器幻觉的问题,也仍然会胡言乱语对下游许多任务造成不可信的危害。但是这篇论文仍然不确定含义的集合数量过少,也过于片面,无法真正度量模型是否有表达自己“不知道”,而对照组人类也仅仅选择了两个志愿者,偶然性仍然相当大。当然更重要的是,这篇论文给出了一个衡量模型能力边界的一个视角,去观察它是否“自知自己无知”,以描述它的自我认知水平,或许正如这篇论文开头引用的孔夫子的“知之为知之,不知为不知,是知也”一样,可能唯一真正的智慧,就是知道自己一无所知吧!
论文题目:
Do Large Language Models Know What They Don’t Know?
论文链接:
https://arxiv.org/pdf/2305.18153.pdf