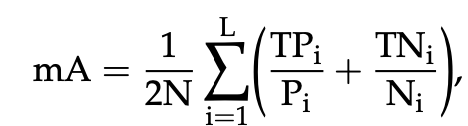本文是Pedestrian Attribute Recognition with Graph Convolutional Network in Surveillance Scenarios的译文。
摘要
监控场景下的行人属性识别是要预测一系列的属性标签,由于图像质量问题,外表的变化,以及不平衡的标签让他成为了一项很有挑战性的工作。在本文中,我们把它当成是多标签分类并且提出了一种新的基于图卷积神经的方法。模型由两部分组成,我们首先用CNN提取行人属性,这是图像处理中的通常做法。然后我们将属性通过词嵌入的方法构建相关矩阵。实验结果表明,结果领先于目前的最好方法。
方法
初步
多标签学习
如果用通常的二分类解决这个问题,那么20类就会有 2 20 2^{20} 220的可能。因此去找到标签之间的相关性很重要。以下三个学习策略很重要:
- 首先不考虑标签之间的相关性,把多标签分类转换为多个二分类问题
- 我们只考虑每个标签两两之间的关系,不考虑现实场景中更为复杂的多个标签的关系
- 考虑所有标签之间的关系,虽然可以获得更高的性能,但是计算量巨大
图卷积神经网络

模型结构

通过resnet101提取特征,与此同时两层的GCN来提取特征之间的关系。
特征抽取

随即裁剪并且把图片缩放到224224, 并且加入水平翻转做数据增强。最后从conv5_x得到204814*14的特征图
相关矩阵
- 首先我们考虑计算每个属性所出现的次数,用矩阵N表示:
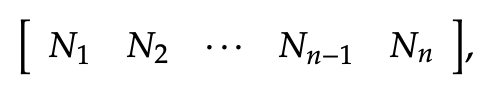
2.我们计算每两个标签共同出现的次数,用矩阵M表示:

那么可以得到条件概率: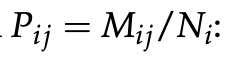
原因在于,如果一个人穿裙子,那么她是女性的概率很大,如果是一个女性,但是穿裙子的概率却没有那么大

实验
通过mA/Acc/Pre/Rec/F1这五种指标如下: