GIL
全局解释器锁,这个锁是个粗粒度的锁,解释器层面上的锁,为了保证线程安全,同一时刻只允许一个线程执行,但这个锁并不能保存线程安全,因为GIL会释放掉的并且切换到另外一个线程上,不会完全占用,依据分配策略(时间片、执行字节码行数、IO操作)。GIL只能保证同一时刻同一CPU上只有一个线程执行,但不能保证线程切换的时候能把一行代码翻译成的bytecode执行完,这就会出现问题,所以说只是一定程度上的保证线程安全。GIL 使得同一个时刻只有一个线程在一个CPU上执行字节码,无法将多个线程映射到多个CPU上,这也是为什么这么说Python多线程鸡肋,也就是说根本意义上来说Python是个单线程的,这个GIL只在CPython中才有,其他版本中没有。
但单线程有个非常大的优势就是在处理IO密集型的任务时候显得与众不同,Python中分线程和协程两种方式,线程是由系统控制调用,协程是由程序员控制,也就是说在把控度角度上来看协程比线程更加具有优势。其一协程比线程更加轻量,其二协程切换完全由程序员控制而不是操作系统控制,其三协程切换消耗远比线程小。
北门吹雪:http://www.cnblogs.com/2bjiujiu/
Python 代码执行原理
# Python代码 --> 解释器 --> bytecode --> 一行一行执行 bytecode
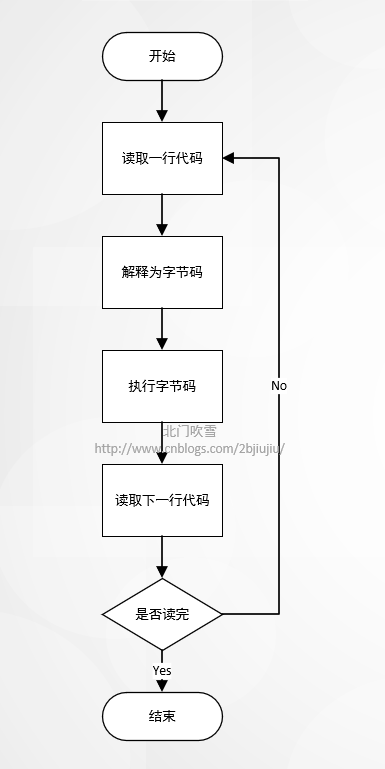
函数执行过程原理:
import dis
def add(a):
a += 1
def subtract(a):
a -= 1
if __name__ == '__main__':
# add 函数执行过程
dis.dis(add)
print()
# subtract 函数执行过程
dis.dis(subtract)
结果:
5 0 LOAD_FAST 0 (a)
2 LOAD_CONST 1 (1)
4 INPLACE_ADD
6 STORE_FAST 0 (a)
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
9 0 LOAD_FAST 0 (a)
2 LOAD_CONST 1 (1)
4 INPLACE_SUBTRACT
6 STORE_FAST 0 (a)
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
简化一下执行结果过程:
def add(a):
a += 1
add
1. load a
2. load 1
3. +
4. 赋值给a a = a +1
def desc(a):
a -= 1
desc
1. load a
2. load 1
3. -
4. 赋值给a a = a - 1
以上过程 GIL会在其中某个过程释放掉给其他线程,问题出现在4赋值阶段,多个线程切换,最终a的值处于各自线程最终结果,假如a=1,则add线程赋值 a = 2 然而 desc线程赋值 a = 0,那么问题出现了,为了解决这个问题,引入锁的概念,线程同步机制,锁住出现问题的代码段,锁住代码块之间串行。获得锁和释放锁带来性能问题,并且带来死锁问题。
beimenchuixue:http://www.cnblogs.com/2bjiujiu/
锁
1. 普通锁 threading.Lock
2. 重入锁(递归锁) threading.Rlodk
# 重入锁使用条件,必须在同一线程内,连续调用多次acquire,一定要注意acquire和 release的次数相等
# 重入锁一般用于一个线程中嵌套一层逻辑,里层逻辑使用了锁机制
如何产生死锁:
1. 获取锁并没有释放锁同时又获取锁
2. 线程A锁住线程B希望获得锁的资源没有释放,线程B锁住线程A的希望获取的资源并没有是否掉,也就是说两个线程各自锁住对方想要获取锁的资源没有释放掉。
3. 一个线程函数中,获得锁之后,再次调用另外一个函数,另外一个函数也获得锁, 通过 Rlodk锁解决这个问题
# 死锁本质原因用土话说:吃着碗里的看着锅里的或互相锁住对象想要的
线程:
1. 操作系统调度单的最小单位,对于IO操作多进程和多线程差别不大
2. 线程出现的原因是进程粒度太大,希望更小的单元使用CPU资源,CPU上执行的是线程,CPU执行线程代码或指令集
3. 线程是进程的一部分,进程至少有一个主线程
4. 线程本身不能分配和拥有资源,只能访问和使用进程资源,因此切换线程比进程切换更加快
5. 多线程可以利用多核和多个CPU性能资源优势,但在Python中不行,由于GIL锁的存在
6. 多线程也是异步编程方式,大多数情况下主线程不知道子线程是否执行往,主线程也不依赖子线程的执行结果
北门吹雪:http://www.cnblogs.com/2bjiujiu/
CPU密集型
1. 处理数据(计算)
IO密集型
# 等待数据
1. 查询数据库
2. 请求网络资源
3. 读写文件
# 依据程序花费的时间是在CPU上还是在等待数据上判断这个程序是CPU密集型还是IO密集型
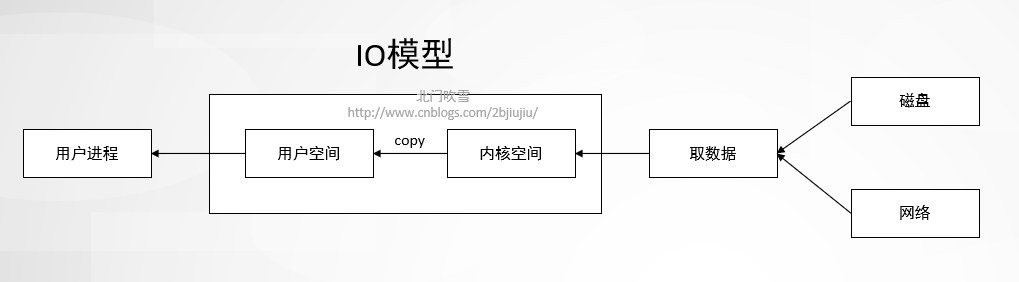
IO操作主要分两类: 网络IO 和 磁盘IO
多线程模块 threading
threading使用过程
1. 实例线程
2. 启动线程
3. 等待或者不等待子线程执行
这里使用socket server线程实现方式实例:
import socket
from threading import Thread
class BeiMenChuiXueHandle(Thread):
def __init__(self, conn, remote_address):
super().__init__()
self.conn = conn
self.remote_address = remote_address
def run(self):
while True:
try:
data = self.conn.recv(1024).decode("utf-8")
except ConnectionResetError as e:
print("北门吹雪")
print("%s:%s 断开连接" % self.remote_address)
break
self.conn.send(bytes(data.upper(), encoding='utf-8'))
self.conn.close()
class BeiMenChuiXueHandleSocket:
def __init__(self):
self.listener = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
def _handle(self, conn, remote_address):
# 1实例线程
handler = BeiMenChuiXueHandle(conn, remote_address)
# 启动线程
handler.start()
def socket_run(self, ip, port):
self.listener.bind((ip, port))
self.listener.listen()
while True:
conn, remote_address = self.listener.accept()
print("北门吹雪")
print("%s:%s 建立连接" % remote_address)
# 3. 线程去处理连接,因为服务端是一直运行,也就是说是否等待进程完成已经不需要
self._handle(conn, remote_address)
if __name__ == '__main__':
listener = BeiMenChuiXueHandleSocket()
listener.socket_run(ip='0.0.0.0', port=8000)
对线程相关操作,这些操作都是在线程实例上的方法
1. 设置为守护线程 .setDaemon(True)
# 主线程不等待子线程完成,其实不加上jion都是守护线程,加上语义更加明显而已
2. 堵塞等待线程完成 .join
# 这个是写在主线程中,在这一行如果线程没有执行完则产生堵塞等待线程执行完,线程执行完则不堵塞执行后面的代码
3. 设置线程名字 .setname
# 其实在实例化的时候可以设置线程名字,有一个name参数
4. 获取线程名字 .getname
import socket
from threading import Thread
def beimenchuixue_handler(conn, remote_address):
"""线程处理处理每个连接"""
# 处理客户端端口异常
while True:
try:
data = conn.recv(1024).decode("utf-8")
except ConnectionResetError as e:
print("%s:%s 断开连接" % remote_address)
break
conn.send(bytes(data.upper(), encoding='utf-8'))
conn.close()
def beimenchuixue_socket():
listener = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listener.bind(('0.0.0.0', 8000))
listener.listen()
while True:
conn, remote_address = listener.accept()
print("%s:%s 建立连接" % remote_address)
# 通过name设置线程名
handler = Thread(target=beimenchuixue_handler, args=(conn, remote_address), name="北门吹雪")
# 设置为守护线程,必须在启动前设置
handler.setDaemon(True)
handler.start()
# 获得线程名
print(handler.getName())
# 线程是否激活
print(handler.is_alive())
# 判断是否守护线程
print(handler.isDaemon())
# 和 is_active()一样
print(handler.isAlive())
if __name__ == '__main__':
beimenchuixue_socket()
5. 获得进程中主线程编号 threading.currennt_thread()
# 这个可以放到任何地方,结果是一样的
北_门_吹_雪:http://www.cnblogs.com/2bjiujiu/
线程通信
1. 共享变量
在线程函数上一层作用域定义一个变量,这线程函数都能方法到并能做修改,或者通过把公用变量传递到线程函数中)线程安全性(相对操作的变量来说,需要加锁让线程依次操作变量),虽然有时没有锁的情况下结果依然正确,因为GIL这把大锁的存在
from threading import Thread, Lock
from itertools import chain
# 共享变量,本质上是上一级变量,要修改则通过global和 nonlocal申明不是当前局变量
number = 1
lock = Lock()
def add():
global number
# 获取锁
lock.acquire()
number += 1
# 释放锁
lock.release()
def subtract():
global number
lock.acquire()
number -= 1
lock.release()
if __name__ == '__main__':
go_add_threads = {Thread(target=add, name='add_%s' % i) for i in range(100)}
go_subtract_threads = {Thread(target=subtract, name="add_thread_%s" % i) for i in range(100)}
# 启动并等待线程
for add_thread in chain(go_add_threads, go_subtract_threads):
add_thread.start()
for add_thread in chain(go_add_threads, go_subtract_threads):
add_thread.join()
# 获得共享变量值
print(number)
2. 通过Queue通信,Queue是线程安全,底层是使用deque数据结构实现,类似Go语言中CSP线程之间通信
# 下面这个实例模仿包子生产店子实现一个生产者与消费者模型实例,通过随机模块模拟等待顾客的过程,通过缓存队列模拟生产包子满了处于等待状态
from threading import Thread
import time
from queue import Queue
from random import randint
def producer(baozi_queue):
count = 1
while True:
print("-->包子出笼了,第%s包子" % count)
baozi_queue.put(count)
# 模拟做包子过程
time.sleep(1)
count += 1
def consumer(baozi_queue):
while True:
count = baozi_queue.get()
# 模拟吃包子过程,不是每时每刻都会有顾客,模拟等待顾客过程
time.sleep(randint(1, 10))
print("<--吃完第 %s 包子" % count)
if __name__ == '__main__':
# 缓存的队列, 做完10个包子就不再做了
baozi_queue = Queue(maxsize=10)
# 生产者
baozi_worker = Thread(target=producer, args=(baozi_queue, ), name="北门吹雪包子店,百年品牌老店")
# 消费者
baozi_consumer = Thread(target=consumer, args=(baozi_queue,), name="吃包子")
# 启动这两个线程
baozi_worker.start()
baozi_consumer.start()
baozi_worker.join()
baozi_consumer.join()
Queue队列其他相关方法和参数
get 有两个参数,block是否堵塞,timeout堵塞超时时间,其中一个条件触发则抛出异常
empty 判断队列是否为空
full 判断队列是否满
北_门_吹_雪:http://www.cnblogs.com/2bjiujiu/
经验:
1. Python多线程由于GIL存在本质上只是单线程,无法利用多核CPU性能优势,启动多进程某种意义上来说只是多启动了一个线程,启动新进程本身消耗远比线程资源消耗大多了,启动进程来折中解决Python线程问题不是好办法
2. 死锁本质原因是吃着碗里的看着锅里的或者互相锁住对方想要的资源
3. 采用Go语言中CSP线程通信模式解决线程安全问题,我觉得是当下最优的选择
4. 区分程序是CPU密集型还是IO密集型,主要看程序把时间花费在CPU上还是在等待数据上
5. 事件驱动,本质上是发送请求取数据,在等待取数据的时候去执行其他函数或过程,跳出时候注册一个事件,数据取回触发事件重新回到跳出的部分执行往下的代码,架构是:事件循环+回调函数
6. 事件驱动异步编程,虽然性能很优秀,但打破了传统上从下到下顺序执行的逻辑,把代码执行的逻辑彻底打乱,出错排错都是非常棘手问题,到底是选择异步编程还是同步编程,需要充分考虑技术人员技术能力和业务需求,如果不能满足则换成Go语言等本身支持异步编程的高性能语言进行处理业务需求,而不是死磕Python实现,这样死磕Python则会在维护与开发成本上花费更多也可能达不到预期效果
bei_men_chui_xxue:http://www.cnblogs.com/2bjiujiu/