技术栈:
Flask框架、Selenium爬虫、机器学习、多元线性回归预测模型、LayUI框架、Echarts可视化大屏、淘宝数据采集
本课题的核心内容是对数据分析平台的基本需求为背景,根据预先设计的思路进行平台的搭建。运用Selenium爬虫技术将数据爬取并用Pandas进行清洗后,将数据导入到MySQL中,使用数据可视化技术对数据进行直观地展示,同时也通过机器学习中的多元线性回归算法对商品销量进行预测,并导入后台在后台管理中查看或使用。最后,本平台运用黑盒测试对数据管理和后台管理进行功能性测试,测试结果均符合预期且平台能够正常运行。
数据管理模块主要目的是对数据进行采集、清洗、分析、可视化、预测。并将得到的数据存入数据库中,在销量预测、数据可视化、后台管理的不同模块中需要不同数据时在数据库里进行调用,再渲染到相应界面。
(1)数据采集模块设计
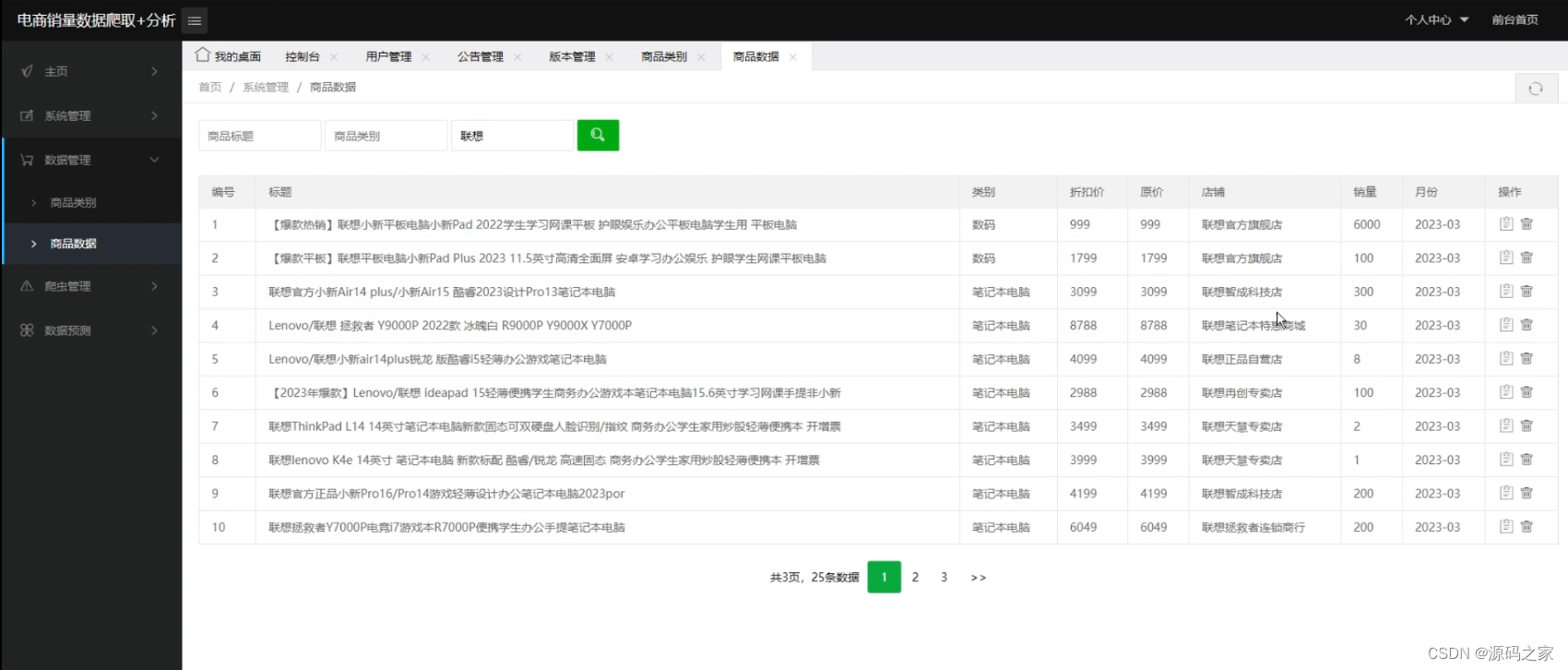
数据采集是数据分析的基础,数据采集以淘宝电商为爬取目标,运用selenium爬虫技术爬取产品相关数据,并分成不同的产品类别,对空值和异常值,利用Python的Numpy库和Pandas库,去除数据里的脏数据和空数据,使数据规范化,对不同指标进行分析,再将数据存储在数据库中。根据需求取出数据为后续数据可视化和机器学习提供数据。
常见的数据来源分为四类:开放数据源,爬虫抓取,日志采集和传感器。本文采用爬虫抓取的方式实现数据采集。selenium是一个自动化测试工具,它可以打开浏览器后模仿人的行为,直接提取网页上的各种信息。
(2)数据预测模块设计
精准的销售预测可以有效减少因库存积压或库存短缺造成的利益损失、帮助管理者更好地制定市场营销策略以及提升客户满意度水平, 从而使社区电商建立起长期的竞争优势。数据预测部分需要提前对数据进行分析,了解数据的基本特征,根据数据的特征对其进行预处理,将数据转换成机器学习需要的格式。使用机器学习多元线性回归算法构建预测模型,我们可以基于数据池进行训练集、验证集与测试集的划分。训练集数据用于模型的训练, 使模型能够对特征值与目标变量之间的映射关系进行学习。通过损失函数最小化,对模型性能进行评估,在选择正确的算法后,可以尝试超参数调整对其进行改进以获得更好的性能;最后,对模型在测试集上完成评估后应用。
(3)数据可视化模块设计
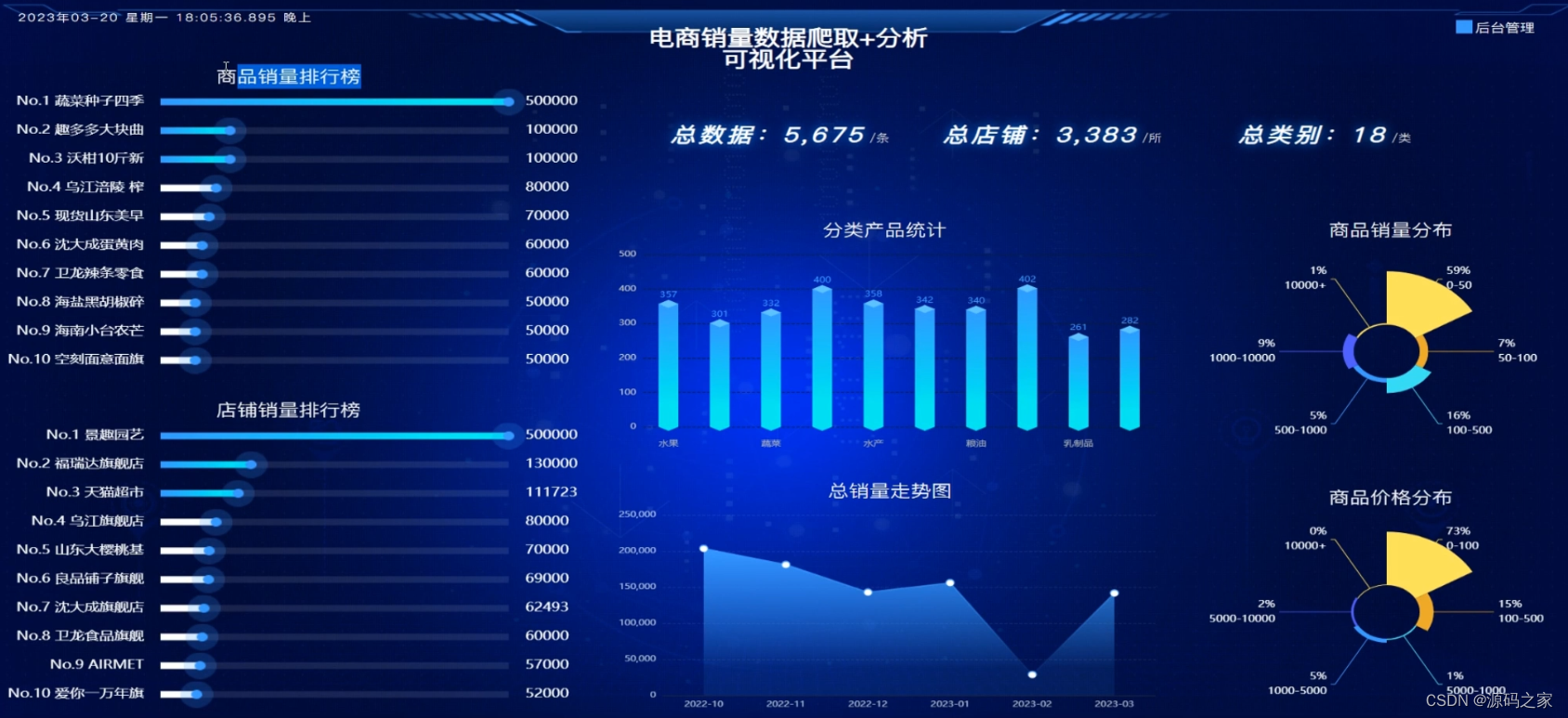
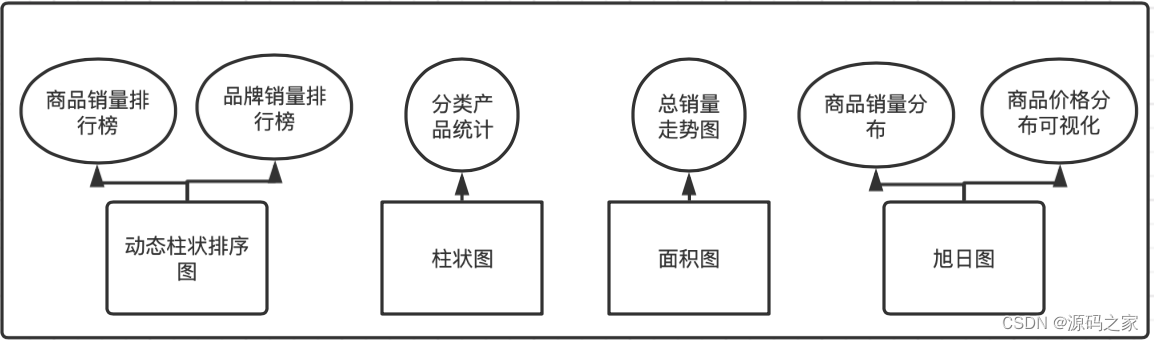
可视化分为历史商品销量排行榜,品牌销量排行榜、分类产品统计、总销量走势图、商品销量分布、商品价格分布可视化。商品销量排行榜和品牌销量排行榜爬取淘宝销量和产品名称、品牌销量和品牌名称,根据数据的特点和数据可视化图表的特点,在echarts中选择了动态柱状排序图,更直观的看出产品销量数据和品牌销量数据;分类产品统计图根据淘宝爬取的商品数据进行分类,对产品类别数量进行统计,根据产品类别数量的特点选择柱状图来展示;爬取并以月为单位对销量进行统计,此时我们选用面积图来渲染,可通过面积变化看到销量的变化;根据产品销量的分布情况和商品价格分布情况选用旭日图渲染。可视化展示页面要对社区电商数据分析平台所展示的数据进行总计,应包括:总店铺数、总数据量、总类别三个部分。
为方便管理员和用户进入对应后台管理,设置了后台管理按钮进行跳转,若没有登陆则跳转至登陆页面,若已经登陆,则直接跳转至后台管理页面。
项目源码部分:

对于社区电商产生的大量数据,通过数据分析平台对数据进行深度挖掘,找出其对企业及用户的价值所在,社区电商企业可以利用这些数据并根据当下疫情情况及商品销量,做出相关决策和市场营销战略,在如今井喷般涌入的社区电商平台中占领有利地位。
面对繁杂的商品数据和疫情当下不稳定的经济市场,通过爬取社区电商数据,并使用与数据特性相符合的多元线性回归算法对销量进行预测,再用简洁的数据可视化展示出来的社区电商数据分析平台一站式解决了数据采集、数据存储、数据分析、数据可视化和平台管理的问题。不仅仅是社区电商,其他产业比如金融、矿业、媒体类都可以搭建类似的数据分析平台,分析商品数据、优先获取数据信息背后的附加价值、加强企业竞争力。
论文的主要工作如下:
第一,分析了社区电商平台的现状。
第二,对本平台所用到的香港技术进行深入分析,合理使用Flask、Bootstrap、Lay-UI框架,分析内部框架和基本原理,同时对Ajax、Echarts、Selenium、机器学习进行了介绍和具体分析。
第三,分析了整个平台的系统设计,重点设计了本系统的两大核心板块——数据爬取和销量预测,再一步步构建起整个系统。
第四,对平台进行功能性测试和非功能性测试。
项目源码分享,相互学习,相互进步~