任务要求
1、爬取深圳市龙华区在 58 同城上的租房信息(租房价格 2000-4000)
① 打开 58 同城,确定筛选条件
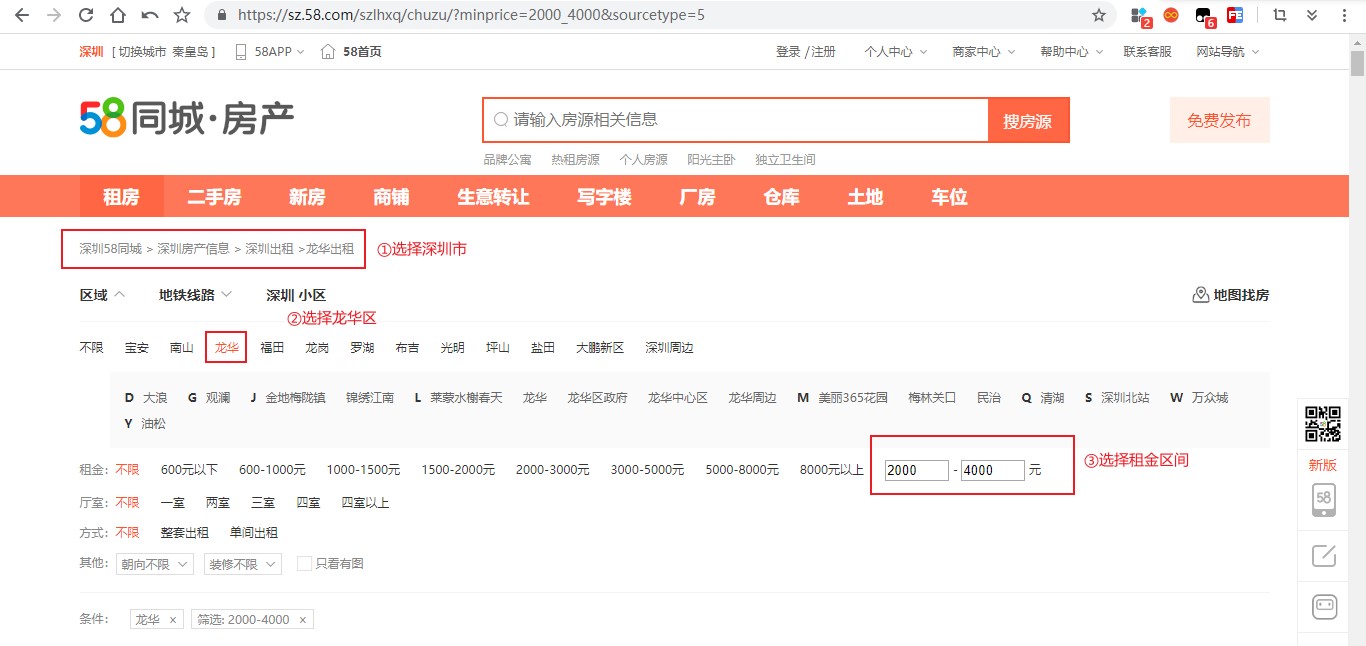
② 确定页数以及单页 xpath 提取规则

③ 确定每页 url 构成规则

完成以上分析步骤之后,就可以开始编写爬虫脚本:
① 找到反爬参数 headers

② 解析页面,找到参数 1——图片链接
扫描二维码关注公众号,回复:
15141790 查看本文章

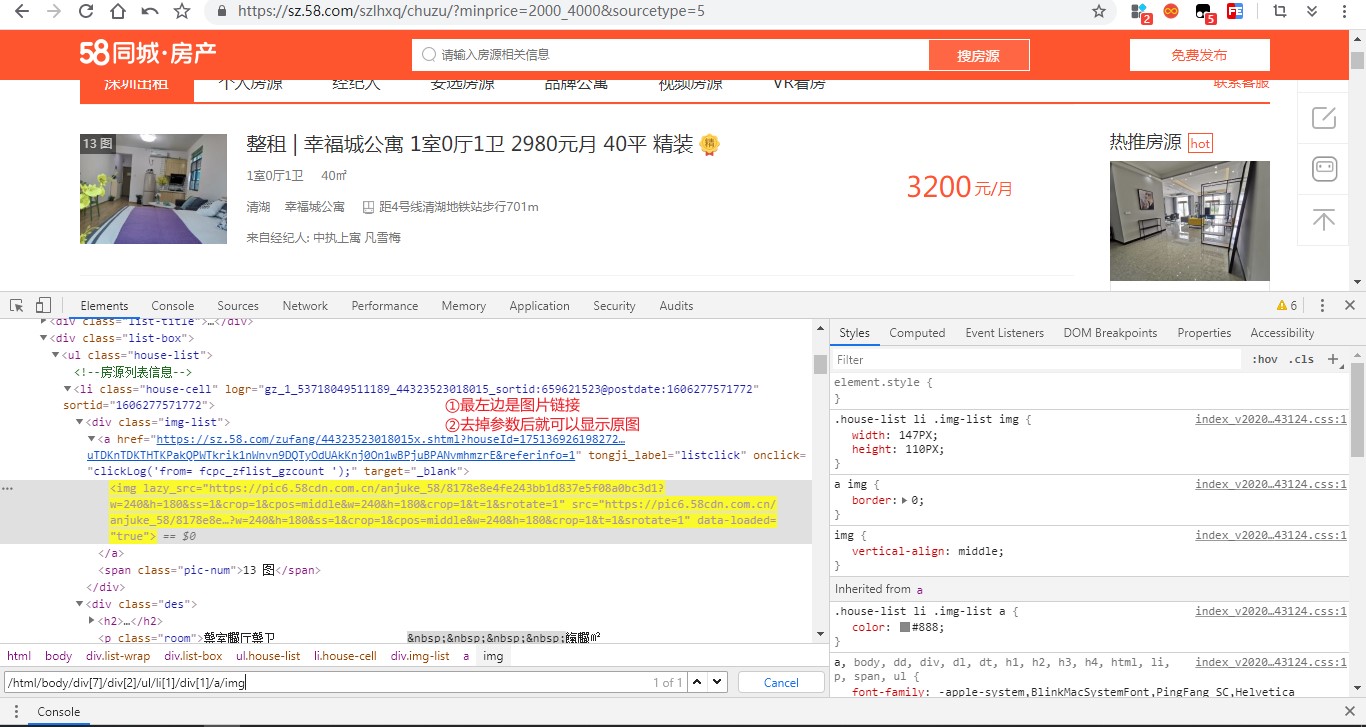
③ 脚本编写完毕!但是 ip 访问次数受到限制

正常情况下只能获取到 1 页房源信息


直接提取 ip:

复制 ip 到 ip.txt 文件替换:

爬取过程很神奇,不知道什么问题:

估计是 ip 的问题,每次爬都会有这个,只是位置不一样
调动高德地图 API,展示房源

下面是 Pycharm 运行截图:

注意事项
① 平时不用的时候,不要爬,要不之前爬的 CSV 文件会被覆盖,演示的时候自己购买 ip 代理池,按照文档要求覆盖 ip.txt 文件内容即可
② 申请的高德 API 默认免费次数是 6000 次,注意使用次数,超过次数需要重新申请,否则报错
③ 目前测试 58 爬取没问题,在网页结构不变时,代码都有效
④ 缺少的 python 第三方模块包,自己下载按照(通过 pip 命令)
⑤ 文件夹中的 task1_爬取 ip 代理.py 别执行,因为爬下来的 ip 都是失效的

添加多进程,加快爬取速度:

终端运行:python -m http.server 3000 浏览器打开:http://0.0.0.0/
鼠标右键运行:task4_调用高德地图 API.html 导入"添加经纬度后 CSV 文件.csv"可以看到效果
ttp://0.0.0.0:3000/)
鼠标右键运行:task4_调用高德地图 API.html 导入"添加经纬度后 CSV 文件.csv"可以看到效果