KMP算法原理,谈谈对 “j = next[j]”的理解
为什么要写这篇文章
最近在学数据结构,这两天刚好学习KMP算法,对于KMP算法的逻辑很好理解,但是却被卡在了代码部分,其实主要是卡在了 j=next[j] 这条语句上,中间翻了很多的资料,费了很长时间,才将这个这条语句搞明白。写下这篇文章,一是记录一下自己的学习成果,二是希望能帮助到有需要的人,因为我找了很多文章和视频,基本上没有将这里讲明白的,正好也补充一下这里的空缺吧(个人认为的空缺)。
什么是KMP算法
KMP 算法(Knuth-Morris-Pratt 算法)是一个著名的字符串匹配算法,效率很高,因为该算法是由 D.E.Knuth,J.H.Morris 和 V.R.Pratt 共同提出的,所以就叫KMP算法。
KMP算法核心思想
KMP 算法其实说白了就是找最长公共前缀子串的问题,啥意思呢,大家看下面的图:

在这里,指向主串的指针和指向模式串的指针分别指到了【E】和【F】(图片中红色部分)那么如何计算最长公共前缀子串呢?这个主要看上图中绿色部分。

看上图,上图两个红框里的数据是一样的(都是ABC),而且在图中不能找到比他们更长的数据串来满足要求,这个就是最长公共前缀子串。然后再:

上图就是KMP算法的核心思想了,因为这篇文章主要要说的是 next数组 ,所以KMP的思想就大致说到这里,如果大家需要更详细的解释,可以找一下其他博主的文章。
令人头大的next数组
下面这张图是严蔚敏(C语言版)上的关于生成next数组的代码

其实这段代码前面部分比较容易理解,主要是对第五行代码有疑问

那么接下来咱们就好好说一下这个 j=next[j] 的问题
详谈 j=next[j]
“最长前缀公共子串”和主串无关,它完全是模式串的一个属性。 相信这点大家应该都已经了解了,但是用代码来求next数组却成了一个问题。

继续看这张图,先来说一下标号为 2 的代码,大家可以将这行代码理解成下面这张图,将两个指针 i 和 j 初始化,分别指向图中位置,而将 next[1] 直接赋值 0

大家不知道是否困惑一点,因为在上文介绍,我们是比较指针前面的绿色部分(K个字符),并不包含指针所指的那个字符,如下图

但标号为4的代码却是直接比较指针 i 和 j 所指元素的值?其实这里是没有错的,大家看是先比较的值,然后指针加一,最后才是给定next的值。简单的说就是先比较,完了之后再将指针后移并给next数组赋值。不知道这样说大家是否明白,事实上便是如此。这里用到的逻辑是这样的:

求 next 数组就是求最大公共前缀子串,如上图,假如模式串中某元素(D)对应的 next [i] 刚好为 j ,也就是上图中 j 指针的位置【这里实际上也就只有 j-1 个字符是相匹配(如上图两个绿色部分,可以为零),不要搞混!】,那么接下来就是解决 i+1 的问题了。这时呢又分两种情况:
情况一:新的字符 D 和第 j 个字符s[j] 相同,如下图:

这种情况下,next[i+1] = next[i] + 1,这个比较容易理解,相信大家一看就能想到。
情况二:新的字符 D 和第 j 个字符s[j] 不相同,如下图:

很多人看KMP算法就是卡在了这一步上,相信今天看这篇文章的许多人也是冲着这里来的,臭名昭著的回退操作——j = next[j] 就是在这里出现的。
这时候原来的绿色部分就不能用了,为了满足最长公共前缀子串的要求,我们需要缩小绿色的部分,也就像下面这个样子:

其中蓝色的格子中的 “?” 表示暂时不知道里面放的字符是什么。而用橙色大括号括起来的两部分(上图中标new的部分)就是我们需要重新对比的部分。
为什么会这样找呢?由前文假设是s[j]和s[i]两个字符不同,导致匹配失败。这个时候就需要重新找到一个最长公共前缀子串,难道我们还要从头一点点找吗?不可能,绝对不可能!而且也大可不必如此,要是再从头找和BF算法有什么区别呢,增加了时间复杂度,非常不划算。同志们,不要忘了,我们手里可是还有很多底牌呢,怕啥,干就完了!
现在我们先捋一下手里的牌,对方要求我们提供 next[i+1] ,因为 s[j] 和 s[i] 两个字符不匹配导致我们不能按照第一种情况的常规套路出牌了,但饿死的骆驼比马大,老子手里可还捏着 netx[i] 等一系列的牌呢。next[i] 是啥呢,也就是下面图中 j 的数值,即 next[i]=j 啊

对于 next[i]=j 这句话说白话就是 对于模式串来说,从第i个字符(不包含第i个字符)向前数 j-1 个字符得到的字串刚好和从模式串开头向后数 j-1 个字符而得到的子串,两个字串是相等的,即上图绿色部分。而 s[j] 和 s[i] 内字符的不同导致我们需要重新匹配,其想法就是在靠近 s[i] 的字符中选择尽可能长的子串来满足KMP算法的条件。
在这里,我们必须要先明白为什么修整完的绿色部分只会比原来的短,而不可能超过原来的绿色部分,这里简单说明一下,感觉自己已经完全明白的可以跳过这一点继续往下看。下图是我们已经验证的最长公共前缀子串(绿色部分)

当我们遇到第二种情况时,即s[j] 和 s[i] 内字符不匹配,然后假设现在延申最长公共前缀子串的长度可以满足要求(假设延长m个字符刚好符合要求),如下图:

看下面这张图片,刚才的已经验证的最长公共前缀子串(绿色部分)被延长了,这和已知是相悖的,所以我们可知最长公共前缀子串是不可能被延长的。

好了,证明了最长公共前缀子串不可能被延长,而又不会保持不变,那就只能是会缩短了。缩短需要缩短到什么程度呢?一次缩短多少呢?这就和 next 数组有关了。继续拿回这张图:

最重要的想必大家已经看出来了,就是 new 中绿色部分。而绿色部分就是我们手中的牌啊兄弟们,就是 s[i] 的最长公共前缀子串。
啥意思呢,看下面这张图(也就是上面那张图的上半部分),其实我们的任务也就是要在Area1 和 Area2 这两块区域来找 s[i+1] 的最长公共前缀子串。
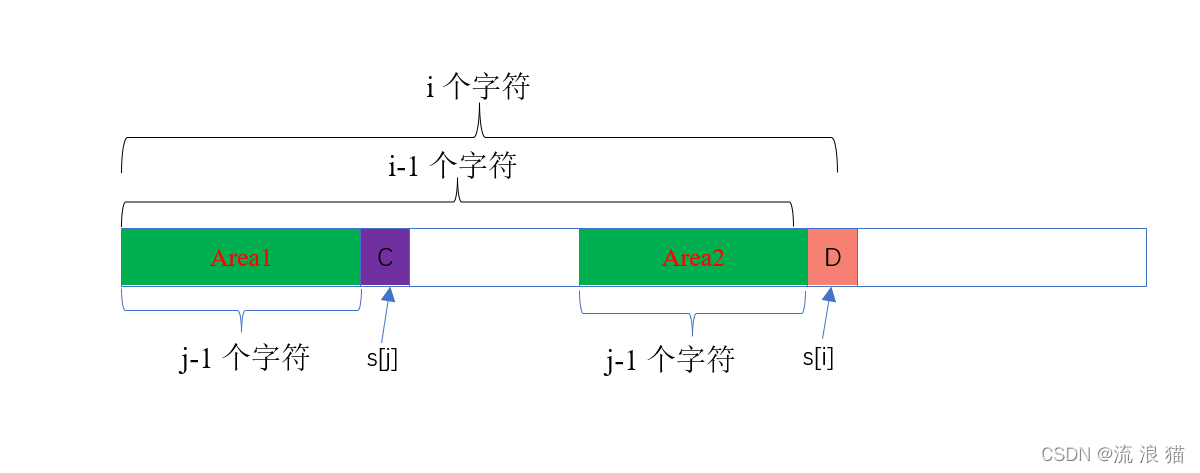
又刚好这两块区域的字符串是一模一样的,那么我们只需研究其中一块就好了。那我们就研究Area1,我们将Area1取出,
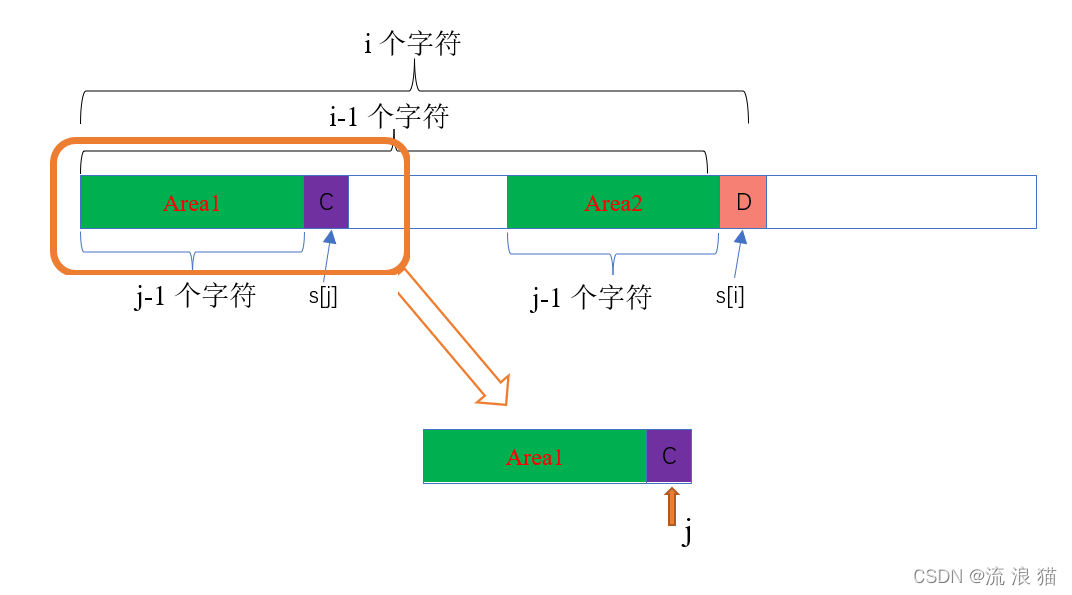
大家看,这时的指针 j 还指向图中的紫色部分呢。而next[j]不就是要找 s[j] 的最长公共前缀子串嘛!也就是:

但是问题由来了,因为我们要的是 s[i+1] 的最长公共前缀子串,所以我们需要保证字符 s[i+1] 前面的元素要和开头的元素完全相匹配,就面临了下面的问题,看图:
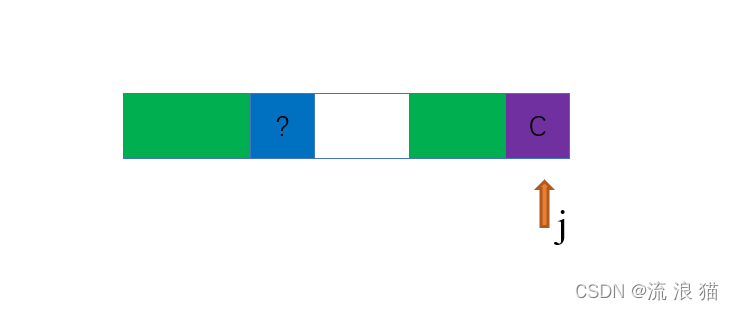
是的,也就是我们只能保证图中绿色部分是相同的,但却不能保证带问号的蓝色方格和 s[i] 是相匹配的,如果不太理解这句话,借助下面的图片或许更能帮到你:

以上就是 j=next[j] 的作用了,将指针 j 所指的位置移动后,我们需要继续对比 s[i] 和 s[j] 内的字符是否相同,但这是程序又一轮循环了。相同就是情况一,不同又是情况二,一直试到成功或者公共前缀的长度为0时为止。
python代码
写文章真的好累啊,接下来给大家附上一段python代码,该代码只是为了求 next 数组,所以难免不规范,大家如果需要就自取吧。
# KMP 算法求next[i]的值
nex = [0]
ch = ("ABCABDABCABCM") # 要求的模式串
i = 1
nex.insert(1, 0)
j = 0
q = [1]
u = [1]
while i < len(ch):
if j == 0 or ch[i-1] == ch[j-1]:
i += 1
j += 1
q = ch[i - 1]
nex.insert(i, j)
else:
j = nex[j]
u = ch[j - 1]
print(nex[1:])