转载自:PyTorch 70.einops:优雅地操作张量维度
einops 三大操作
from einops import rearrange, reduce, repeat
einops通过rearrange, reduce, repeat这3个方法,可以起到 stacking, reshape, transposition, squeeze/unsqueeze, repeat, tile, concatenate, view 以及各种reduction操作的效果,大大简化了原来复杂的高维张量操作,提高了代码可读性,支持 numpy、pytorch、tensorflow 等等。
导入6张测试图片:
# There are 6 images of shape 96x96 with 3 color channels packed into tensor
print(ims.shape, ims.dtype)
# (6, 96, 96, 3) float64
# (b,h,w,c)
ims[0]
ims[1]


转换张量维度
旧:
y = x.transpose(0, 2, 3, 1)
新:
y = rearrange(x, 'b c h w -> b h w c')
rearrange:重新安排维度
交换维度、压缩维度、分解维度、
rearrange(ims[0], 'h w c -> w h c') # 交换维度

rearrange(ims, 'b h w c -> (b h) w c') # 压缩维度 (b和h)


# or compose a new dimension of batch and width
rearrange(ims, 'b h w c -> h (b w) c') # 压缩维度 (b和w)
# length of newly composed axis is a product of components
# [6, 96, 96, 3] -> [96, (6 * 96), 3] -> [96, 576, 3]
rearrange(ims, 'b h w c -> h (b w) c').shape
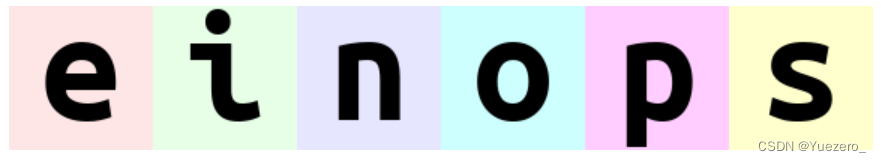
# decomposition is the inverse process - represent an axis as a combination of new axes
# several decompositions possible, so b1=2 is to decompose 6 to b1=2 and b2=3
rearrange(ims, '(b1 b2) h w c -> b1 b2 h w c ', b1=2).shape # 分解维度,原始b=6, 指定b1=2, b2自动计算=6/b1
# (2, 3, 96, 96, 3)
# finally, combine composition and decomposition:
rearrange(ims, '(b1 b2) h w c -> (b1 h) (b2 w) c ', b1=2) # 分解维度b,并将b1和h、b2和w进行压缩

#height变为2倍,width变为1半:
rearrange(ims, 'b h (w w2) c -> (h w2) (b w) c', w2=2) # 分解维度w(w1=w/2),将h和w2合并,即h*2,将b和w1合并,即6张图横向排列,宽为w1

rearrange(ims, 'b h w c -> h (b w) c')

注意前面我们压缩维度时,只要涉及b都是b在前,如(b w)、(b h)、(b w1)等,括号里的顺序是有意义的。
# 与上例做个对比, leftmost digit is the most significant
rearrange(ims, 'b h w c -> h (w b) c') # b在

# what if b1 and b2 are reordered before composing to width?
rearrange(ims, '(b1 b2) h w c -> h (b1 b2 w) c ', b1=2) # 原始batch中图片顺序 'einops'
rearrange(ims, '(b1 b2) h w c -> h (b2 b1 w) c ', b1=2) # 重排序为 'eoipns'
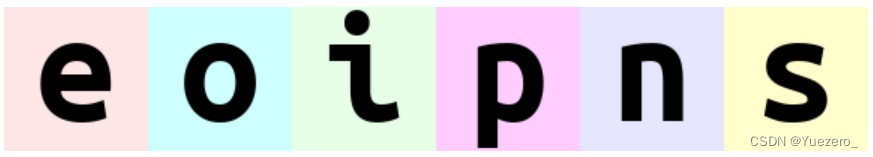
reduce
# average over batch
reduce(ims, 'b h w c -> h w c', 'mean') # 对张量的b维度取平均值

# the previous is identical to familiar:
ims.mean(axis=0) # 使用老方法应该这么写
# but is so much more readable
# besides mean, there are also min, max, sum, prod
reduce(ims, 'b h w c -> h w', 'min') # 除了mean 还可以求min, max, sum, prod

# this is mean-pooling with 2x2 kernel
# image is split into 2x2 patches, each patch is averaged
reduce(ims, 'b (h h2) (w w2) c -> h (b w) c', 'mean', h2=2, w2=2) # 图像分割为2x2的patch,每个patch分别进行mean,并压缩b和w显示
# 效果就是变小了

# yet another example. Can you compute result shape?
reduce(ims, '(b1 b2) h w c -> (b2 h) (b1 w)', 'mean', b1=2)

将张量放入list中,einops 会默认按batch划分,即6张图像,对该list操作效果等同于对原始张量操作
# rearrange can also take care of lists of arrays with the same shape
x = list(ims)
# that's how we can stack inputs
# "list axis" becomes first ("b" in this case), and we left it there
rearrange(x, 'b h w c -> b h w c').shape
# (6, 96, 96, 3)
rearrange(x, 'b h w c -> h w c b').shape
# (96, 96, 3, 6)
numpy.array_equal(rearrange(x, 'b h w c -> h w c b'), numpy.stack(x, axis=3)) # rearrange交换维度 等价于 numpy.stack
# True
增加或删除张量维度
x = rearrange(ims, 'b h w c -> b 1 h w 1 c') # functionality of numpy.expand_dims
#(6, 1, 96, 96, 1, 3)
rearrange(x, 'b 1 h w 1 c -> b h w c').shape # functionality of numpy.squeeze
#(6, 96, 96, 3)
# compute max in each image individually, then show a difference
x = reduce(ims, 'b h w c -> b () () c', 'max') - ims
rearrange(x, 'b h w c -> h (b w) c')

# interweaving pixels of different pictures
# all letters are observable
rearrange(ims, '(b1 b2) h w c -> (h b1) (w b2) c ', b1=2)

# interweaving along vertical for couples of images
rearrange(ims, '(b1 b2) h w c -> (h b1) (b2 w) c', b1=2)

# disproportionate resize
reduce(ims, 'b (h 4) (w 3) c -> (h) (b w)', 'mean')

# interweaving lines for couples of images
# exercise: achieve the same result without einops in your favourite framework
reduce(ims, '(b1 b2) h w c -> h (b2 w) c', 'max', b1=2)

# spilt each image in two halves, compute mean of the two
reduce(ims, 'b (h1 h2) w c -> h2 (b w)', 'mean', h1=2)

# split in small patches and transpose each patch
rearrange(ims, 'b (h1 h2) (w1 w2) c -> (h1 w2) (b w1 h2) c', h2=8, w2=8)

rearrange(ims, '(b1 b2) (h1 h2) (w1 w2) c -> (h1 b1 h2) (w1 b2 w2) c', h1=3, w1=3, b2=3)

repeat
# pixelate: first downscale by averaging, then upscale back using the same pattern
averaged = reduce(ims, 'b (h h2) (w w2) c -> b h w c', 'mean', h2=6, w2=8)
repeat(averaged, 'b h w c -> (h h2) (b w w2) c', h2=6, w2=8)
rearrange(ims, 'b h w c -> w (b h) c')
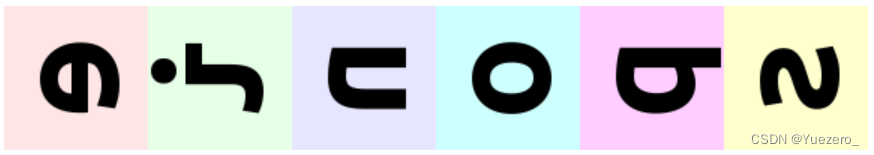
einops操作PyTorch张量
生成张量
from einops import rearrange, reduce
import numpy as np
x = np.random.RandomState(42).normal(size=[10, 32, 100, 200])
from utils import guess
# select one from 'chainer', 'gluon', 'tensorflow', 'pytorch'
flavour = 'pytorch'
print('selected {} backend'.format(flavour))
if flavour == 'tensorflow':
import tensorflow as tf
tape = tf.GradientTape(persistent=True)
tape.__enter__()
x = tf.Variable(x) + 0
elif flavour == 'pytorch':
import torch
x = torch.from_numpy(x)
x.requires_grad = True
elif flavour == 'chainer':
import chainer
x = chainer.Variable(x)
else:
assert flavour == 'gluon'
import mxnet as mx
mx.autograd.set_recording(True)
x = mx.nd.array(x, dtype=x.dtype)
x.attach_grad()
type(x), x.shape
# (torch.Tensor, torch.Size([10, 32, 100, 200]))
y = rearrange(x, 'b c h w -> b h w c')
guess(y.shape)
# (torch.Tensor, torch.Size([10, 100, 200, 32]))
y = rearrange(x, 'b c h w -> b (c h w)')
y.shape
# (torch.Tensor, torch.Size([10, 640000]))
y = rearrange(x, 'b c (h h1) (w w1) -> b (h1 w1 c) h w', h1=2, w1=2)
y.shape
# (torch.Tensor, torch.Size([10, 128, 50, 100]))
y = rearrange(x, 'b (c h1 w1) h w -> b c (h h1) (w w1)', h1=2, w1=2)
y.shape
# (torch.Tensor, torch.Size([10, 8, 200, 400]))
反向传播
y0 = x
y1 = reduce(y0, 'b c h w -> b c', 'max')
y2 = rearrange(y1, 'b c -> c b')
y3 = reduce(y2, 'c b -> ', 'sum')
if flavour == 'tensorflow':
print(reduce(tape.gradient(y3, x), 'b c h w -> ', 'sum'))
else: # pytorch等
y3.backward()
print(reduce(x.grad, 'b c h w -> ', 'sum'))
转化成numpy
from einops import asnumpy
y3_numpy = asnumpy(y3)
print(type(y3_numpy), y3_numpy.shape)
# <class 'numpy.ndarray'>
张量增加与删除维度
Squeeze and unsqueeze (expand_dims):
# models typically work only with batches,
# so to predict a single image ...
image = rearrange(x[0, :3], 'c h w -> h w c')
# ... create a dummy 1-element axis ...
y = rearrange(image, 'h w c -> () c h w')
# ... imagine you predicted this with a convolutional network for classification,
# we'll just flatten axes ...
predictions = rearrange(y, 'b c h w -> b (c h w)')
# ... finally, decompose (remove) dummy axis
predictions = rearrange(predictions, '() classes -> classes')
per-channel mean-normalization for each image:
y = x - reduce(x, 'b c h w -> b c 1 1', 'mean')
y.shape
(torch.Tensor, torch.Size([10, 32, 100, 200]))
per-channel mean-normalization for whole batch:
y = x - reduce(y, 'b c h w -> 1 c 1 1', 'mean')
y.shape
(torch.Tensor, torch.Size([10, 32, 100, 200]))
拼接张量
concatenate over the first dimension:
tensors = rearrange(list_of_tensors, 'b c h w -> (b h) w c')
tensors.shape
(torch.Tensor, torch.Size([1000, 200, 32]))
打乱
channel shuffle:
y = rearrange(x, 'b (g1 g2 c) h w-> b (g2 g1 c) h w', g1=4, g2=4)
y.shape
(torch.Tensor, torch.Size([10, 32, 100, 200]))
分割维度
Example: when a network predicts several bboxes for each position
Assume we got 8 bboxes, 4 coordinates each. To get coordinated into 4 separate variables, you move corresponding dimension to front and unpack tuple.
bbox_x, bbox_y, bbox_w, bbox_h = \
rearrange(x, 'b (coord bbox) h w -> coord b bbox h w', coord=4, bbox=8)
# now you can operate on individual variables
max_bbox_area = reduce(bbox_w * bbox_h, 'b bbox h w -> b h w', 'max')
guess(bbox_x.shape)
guess(max_bbox_area.shape)
(torch.Tensor, torch.Size([10, 8, 100, 200]))
(torch.Tensor, torch.Size([10, 100, 200]))
rearrange实现卷积
Finally, how to convert any operation into a strided operation?
(like convolution with strides, aka dilated/atrous convolution)
# each image is split into subgrids, each is now a separate "image"
y = rearrange(x, 'b c (h hs) (w ws) -> (hs ws b) c h w', hs=2, ws=2)
y = convolve_2d(y)
# pack subgrids back to an image
y = rearrange(y, '(hs ws b) c h w -> b c (h hs) (w ws)', hs=2, ws=2)
assert y.shape == x.shape
reduce实现池化
Simple global average pooling:
y = reduce(x, 'b c h w -> b c', reduction='mean')
y.shape
#(torch.Tensor, torch.Size([10, 32]))
max-poolingwith a kernel 2x2:
y = reduce(x, 'b c (h h1) (w w1) -> b c h w', reduction='max', h1=2, w1=2)
y.shape
#(torch.Tensor, torch.Size([10, 32, 50, 100]))
1d, 2d and 3d pooling are defined in a similar way
for sequential 1-d models, you’ll probably want pooling over time
reduce(x, '(t 2) b c -> t b c', reduction='max')
reduce(x, 'b c (x 2) (y 2) (z 2) -> b c x y z', reduction='max')
定义网络结构Layers
For frameworks that prefer operating with layers, layers are available.
You’ll need to import a proper one depending on your backend:
from einops.layers.torch import Rearrange, Reduce
Einops layers are identical to operations, and have same parameters.
(for the exception of first argument, which should be passed during call):
# example given for pytorch, but code in other frameworks is almost identical
from torch.nn import Sequential, Conv2d, MaxPool2d, Linear, ReLU
from einops.layers.torch import Reduce
model = Sequential(
Conv2d(3, 6, kernel_size=5),
MaxPool2d(kernel_size=2),
Conv2d(6, 16, kernel_size=5),
# combined pooling and flattening in a single step
Reduce('b c (h 2) (w 2) -> b (c h w)', 'max'),
Linear(16*5*5, 120),
ReLU(),
Linear(120, 10),
)
经典网络的变化
Simple ConvNet:
老代码:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
conv_net_old = Net()
新代码:
conv_net_new = nn.Sequential(
nn.Conv2d(1, 10, kernel_size=5),
nn.MaxPool2d(kernel_size=2),
nn.ReLU(),
nn.Conv2d(10, 20, kernel_size=5),
nn.MaxPool2d(kernel_size=2),
nn.ReLU(),
nn.Dropout2d(),
Rearrange('b c h w -> b (c h w)'),
nn.Linear(320, 50),
nn.ReLU(),
nn.Dropout(),
nn.Linear(50, 10),
nn.LogSoftmax(dim=1)
)
Channel shuffle (from shufflenet):
老代码:
def channel_shuffle_old(x, groups):
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
# reshape
x = x.view(batchsize, groups,
channels_per_group, height, width)
# transpose
# - contiguous() required if transpose() is used before view().
# See https://github.com/pytorch/pytorch/issues/764
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x
新代码:
def channel_shuffle_new(x, groups):
return rearrange(x, 'b (c1 c2) h w -> b (c2 c1) h w', c1=groups)
Simple attention:
老代码:
class Attention(nn.Module):
def __init__(self):
super(Attention, self).__init__()
def forward(self, K, V, Q):
A = torch.bmm(K.transpose(1,2), Q) / np.sqrt(Q.shape[1])
A = F.softmax(A, 1)
R = torch.bmm(V, A)
return torch.cat((R, Q), dim=1)
新代码:
def attention(K, V, Q):
_, n_channels, _ = K.shape
A = torch.einsum('bct,bcl->btl', [K, Q])
A = F.softmax(A * n_channels ** (-0.5), 1)
R = torch.einsum('bct,btl->bcl', [V, A])
return torch.cat((R, Q), dim=1)
Transformer’s attention needs more attention:
老代码:
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
self.softmax = nn.Softmax(dim=2)
def forward(self, q, k, v, mask=None):
attn = torch.bmm(q, k.transpose(1, 2))
attn = attn / self.temperature
if mask is not None:
attn = attn.masked_fill(mask, -np.inf)
attn = self.softmax(attn)
attn = self.dropout(attn)
output = torch.bmm(attn, v)
return output, attn
class MultiHeadAttentionOld(nn.Module):
''' Multi-Head Attention module '''
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.w_qs = nn.Linear(d_model, n_head * d_k)
self.w_ks = nn.Linear(d_model, n_head * d_k)
self.w_vs = nn.Linear(d_model, n_head * d_v)
nn.init.normal_(self.w_qs.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k)))
nn.init.normal_(self.w_ks.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k)))
nn.init.normal_(self.w_vs.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_v)))
self.attention = ScaledDotProductAttention(temperature=np.power(d_k, 0.5))
self.layer_norm = nn.LayerNorm(d_model)
self.fc = nn.Linear(n_head * d_v, d_model)
nn.init.xavier_normal_(self.fc.weight)
self.dropout = nn.Dropout(dropout)
def forward(self, q, k, v, mask=None):
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, _ = q.size()
sz_b, len_k, _ = k.size()
sz_b, len_v, _ = v.size()
residual = q
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
q = q.permute(2, 0, 1, 3).contiguous().view(-1, len_q, d_k) # (n*b) x lq x dk
k = k.permute(2, 0, 1, 3).contiguous().view(-1, len_k, d_k) # (n*b) x lk x dk
v = v.permute(2, 0, 1, 3).contiguous().view(-1, len_v, d_v) # (n*b) x lv x dv
mask = mask.repeat(n_head, 1, 1) # (n*b) x .. x ..
output, attn = self.attention(q, k, v, mask=mask)
output = output.view(n_head, sz_b, len_q, d_v)
output = output.permute(1, 2, 0, 3).contiguous().view(sz_b, len_q, -1) # b x lq x (n*dv)
output = self.dropout(self.fc(output))
output = self.layer_norm(output + residual)
return output, attn
新代码:
class MultiHeadAttentionNew(nn.Module):
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head
self.w_qs = nn.Linear(d_model, n_head * d_k)
self.w_ks = nn.Linear(d_model, n_head * d_k)
self.w_vs = nn.Linear(d_model, n_head * d_v)
nn.init.normal_(self.w_qs.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k)))
nn.init.normal_(self.w_ks.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k)))
nn.init.normal_(self.w_vs.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_v)))
self.fc = nn.Linear(n_head * d_v, d_model)
nn.init.xavier_normal_(self.fc.weight)
self.dropout = nn.Dropout(p=dropout)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, q, k, v, mask=None):
residual = q
q = rearrange(self.w_qs(q), 'b l (head k) -> head b l k', head=self.n_head)
k = rearrange(self.w_ks(k), 'b t (head k) -> head b t k', head=self.n_head)
v = rearrange(self.w_vs(v), 'b t (head v) -> head b t v', head=self.n_head)
attn = torch.einsum('hblk,hbtk->hblt', [q, k]) / np.sqrt(q.shape[-1])
if mask is not None:
attn = attn.masked_fill(mask[None], -np.inf)
attn = torch.softmax(attn, dim=3)
output = torch.einsum('hblt,hbtv->hblv', [attn, v])
output = rearrange(output, 'head b l v -> b l (head v)')
output = self.dropout(self.fc(output))
output = self.layer_norm(output + residual)
return output, attn