文章目录
Pytorch专栏
Pytorch框架学习路径(一:张量简介与创建)
Pytorch框架学习路径(二:张量操作)
Pytorch框架学习路径(三:线性回归)
Pytorch框架学习路径(四:计算图与动态图机制)
Pytorch框架学习路径(五:autograd与逻辑回归)
Pytorch框架学习路径(七:数据读取机制DataLoader与Dataset)
ReadMe(注意)
本文前面的Debug部分是请参考上一篇博客(与上一篇博客Pytorch框架学习路径(七:数据读取机制DataLoader与Dataset) 是关联的),这里为了方便大家回忆和理解,我也会贴出Debug过程图片,但在上一篇博客(Pytorch框架学习路径(七:数据读取机制DataLoader与Dataset))中详细讲解的过程不再讲解。
(一)transforms 运行机制
1.1、torchvision:计算机视觉工具包
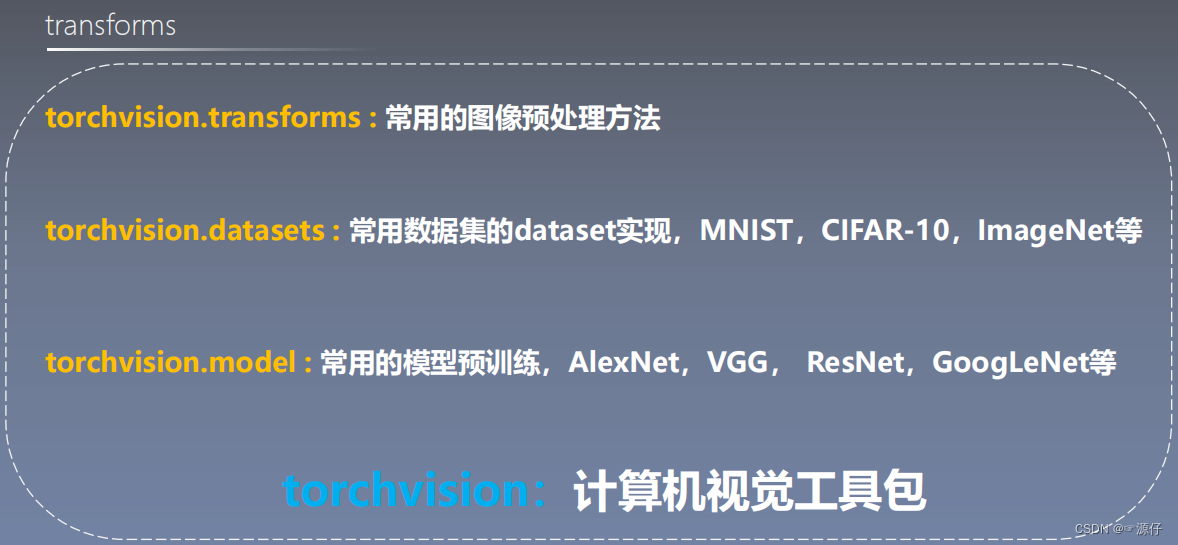
1.2、常用的图像预处理方法

1.3、transforms(含本人录制视频讲解)
本人对一下内容做的详细讲解视频链接:https://pan.baidu.com/s/1Ovn2dMiU0WRUFd0DFLUITg
提取码:dcbo
在我们详细讲解transforms之前,我们先看下图,transforms在我们数据导入过程中分布的位置。

首先我们看一下 Debug的过程:如下动态图
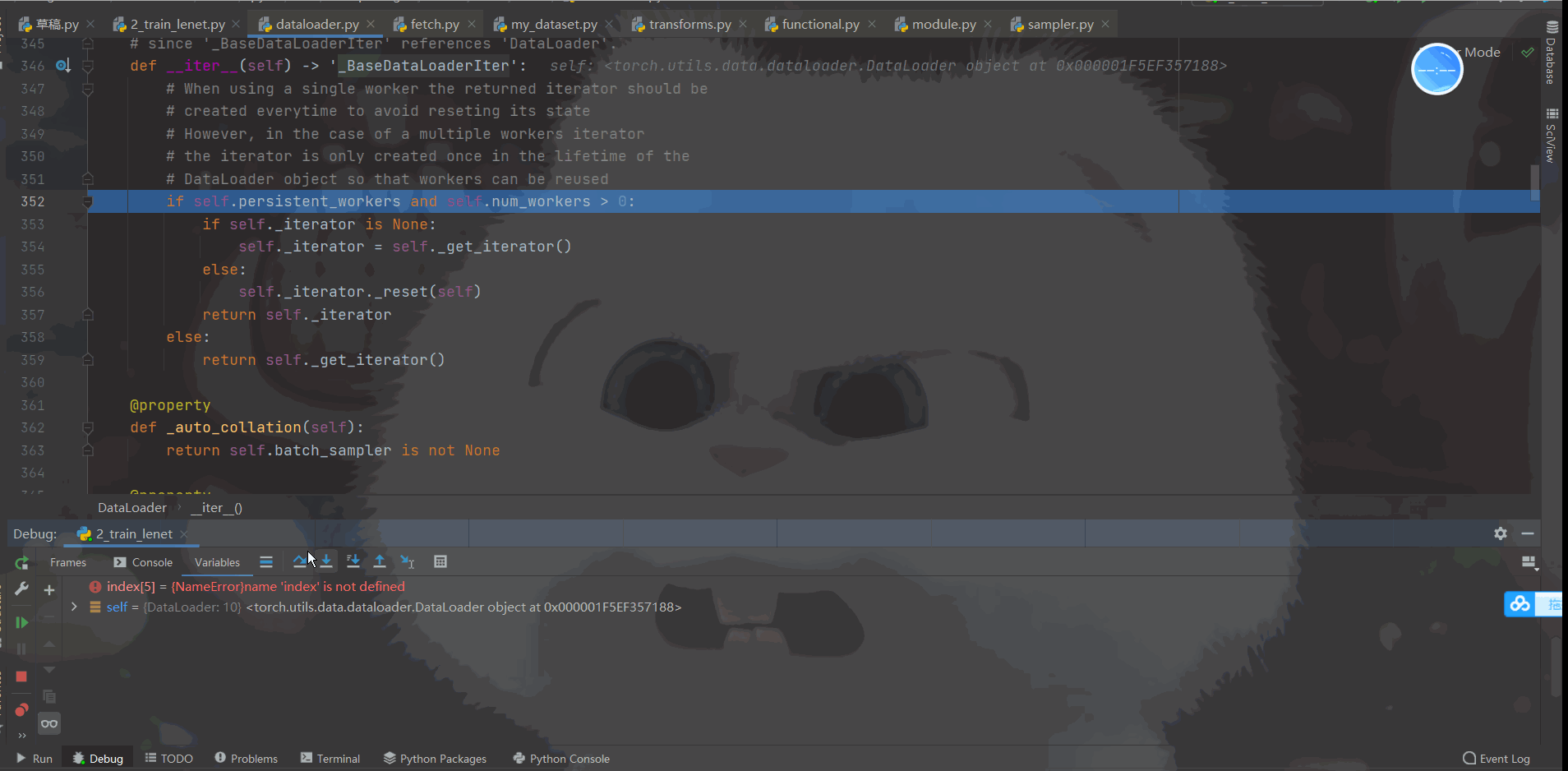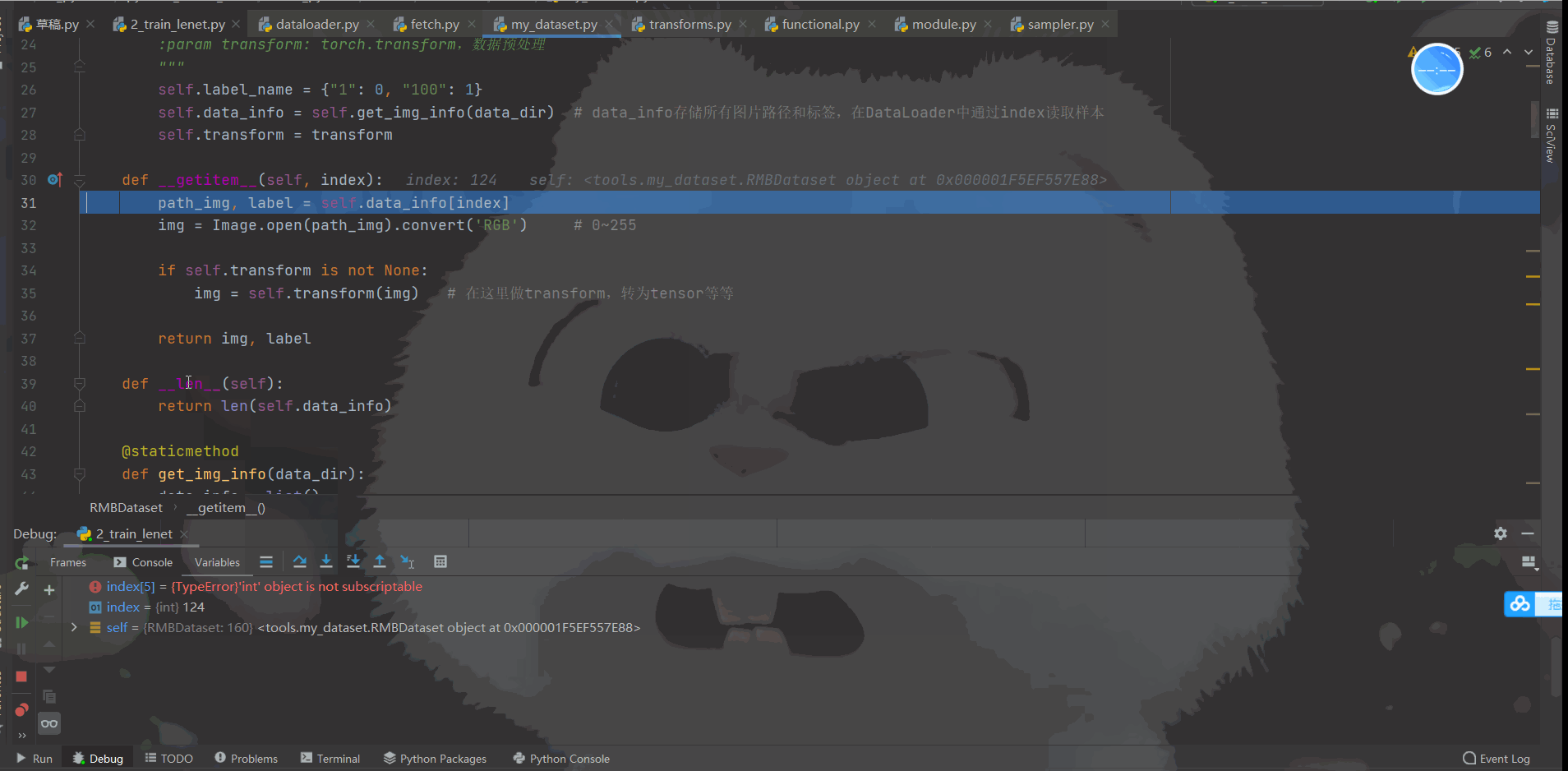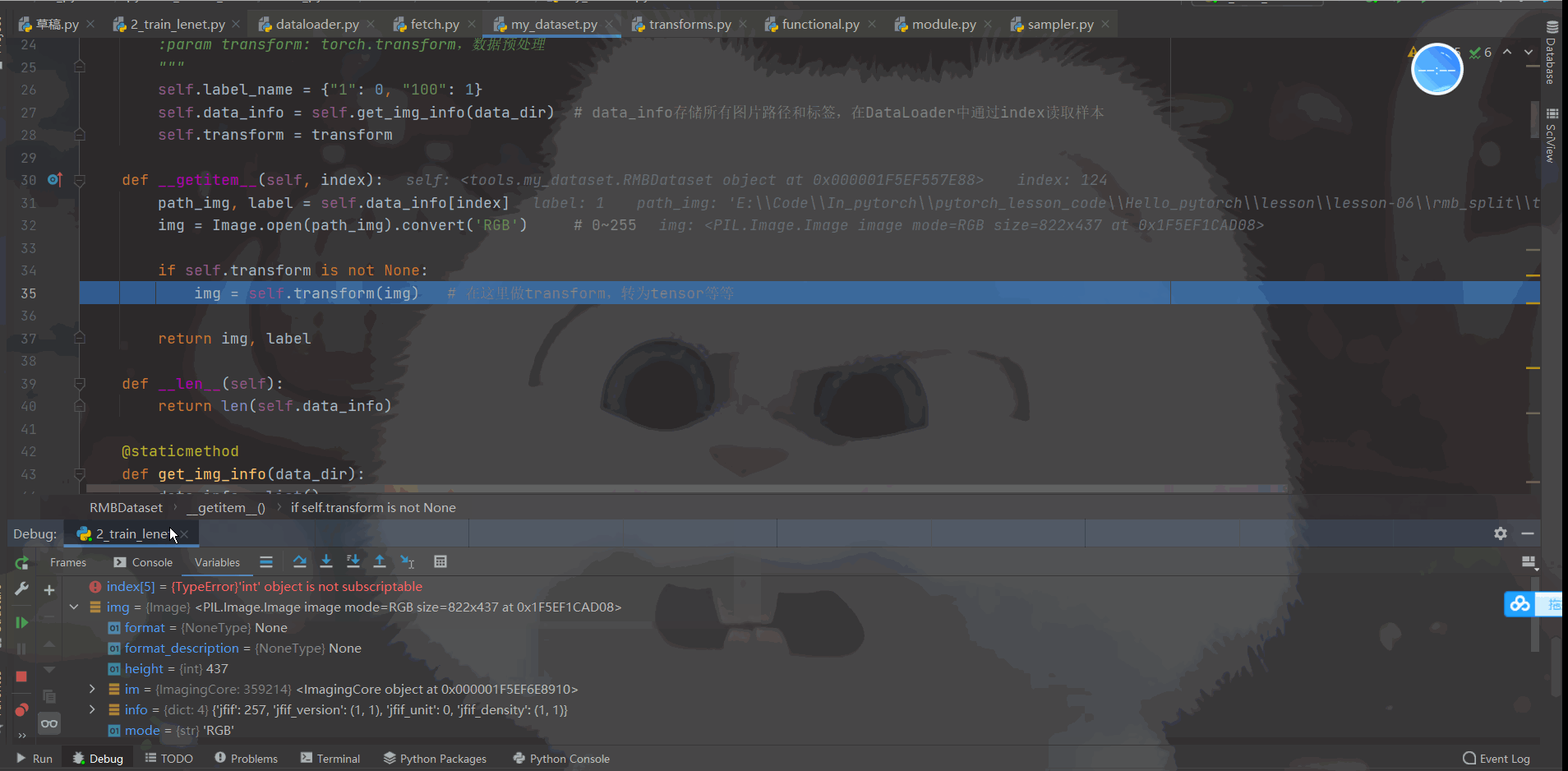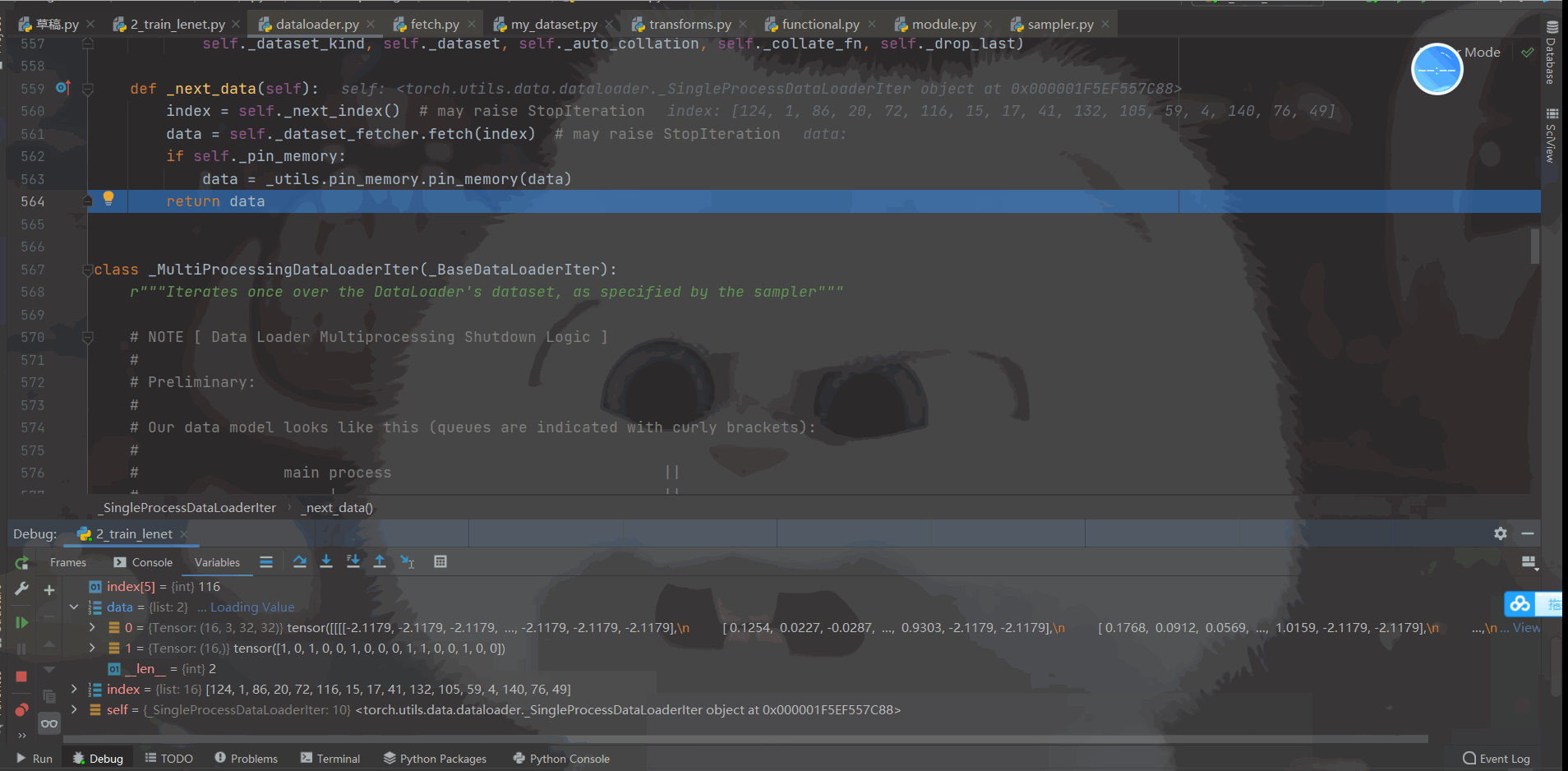
| 对以上DeBug过程做了视频讲解(这部分文字很难描述) |
我相信大家对这个动态图看的迷糊,所以我单独录制了视频进行讲解。这里附上百度网盘链接,
链接:https://pan.baidu.com/s/1Ovn2dMiU0WRUFd0DFLUITg
提取码:dcbo
1.4、transforms.Normalize
在
1.3中我已经在视频中和大家讲解过transforms.Normalize的源码了,下面贴一张图,方便大家理解。
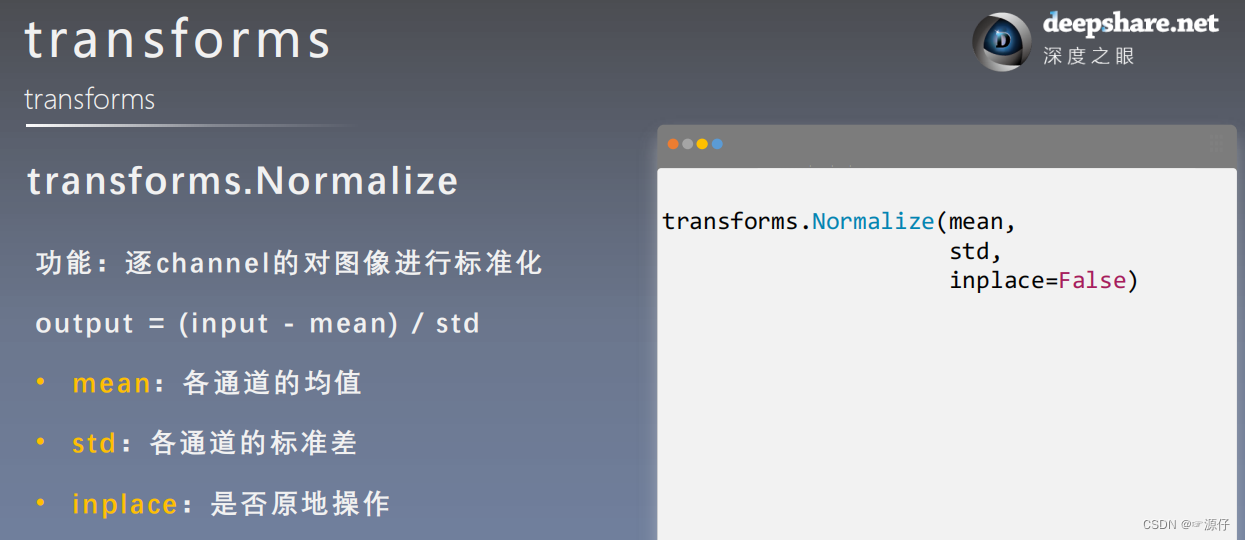
| Normalize的作用 |
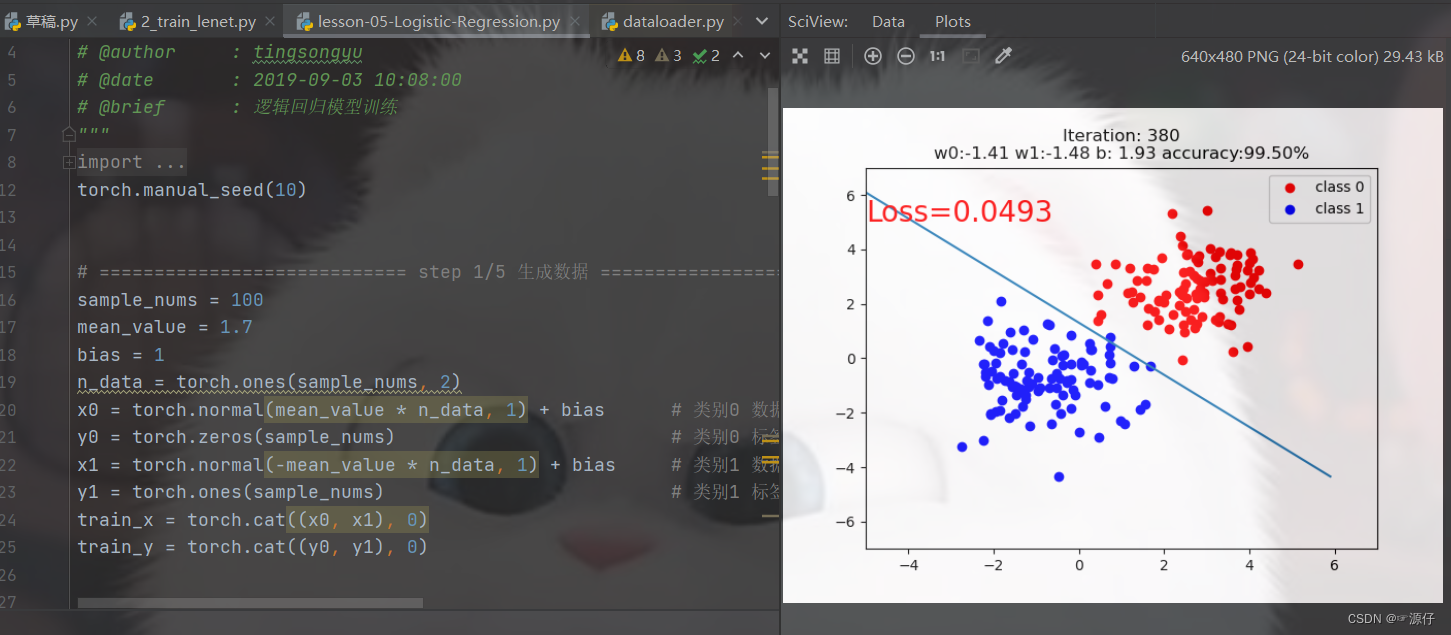
Normalize的作用:可以加快模型的收敛。那这个怎么去理解呢!我们先回顾一下Pytorch框架学习路径(五:autograd与逻辑回归)中我讲述的逻辑回归代码。结果如下图:
由上图可知,我们的数据距离
(0,0)点都不远,这里模型运行迭代到第400次,loss就达到了0.0493,精度也达到了0.995.
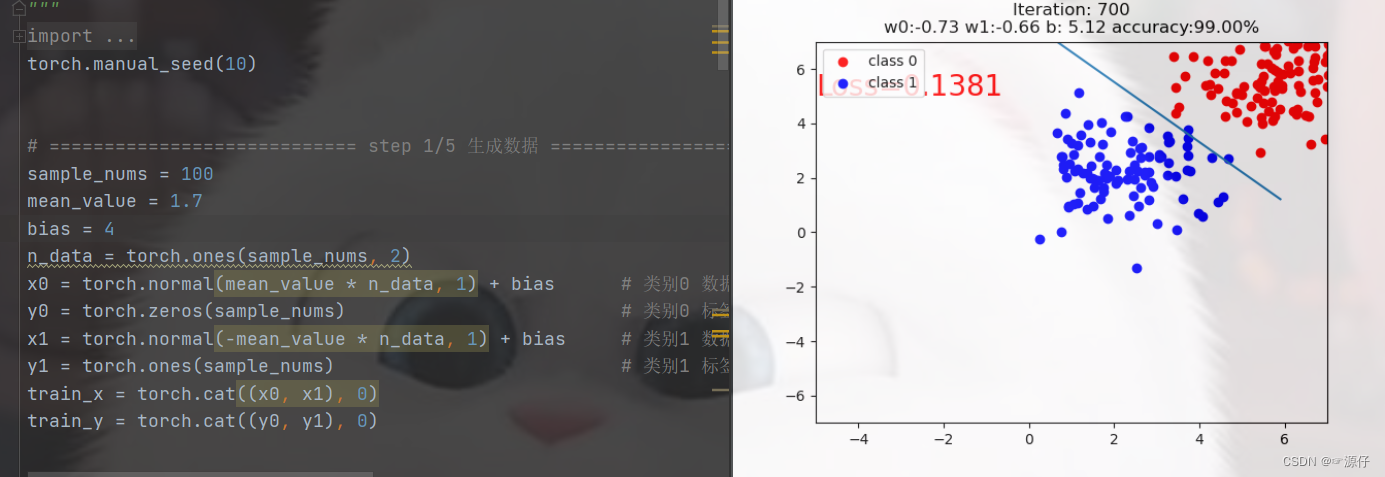
如果我们修改一下数据的分布,使得数据的均值远离这个原点,于是
bias的大小就起作用了,初始化bias=4.
由上图结果可知,当我们迭代到700次,精度才大于等于0.99,并且loss=0.1381,而且在你在自己运行过程中,可以明显发现在第400次迭代后,迭代的速度是很慢的。从这里就可以看出我们的Normalize是有多么的重要了。
(二)下节预告
transforms图像增强(一)
- 数据增强
- transforms ——裁剪
- transforms ——翻转和旋转