1、基础知识
计算机程序非常详细地告诉计算机完成一个任务所需要的一系列步骤。
硬件物理计算机和外部设备统称为硬件。
软件计算机执行的程序。
编程设计和实现计算机程序的活动。
计算机的核心是中央处理机(CPU),CPU执行程序控制和数据处理,即CPU定位和执行程序指令,执行加减乘除等算术运算,从外部存储器或设备中读取数据并存储处理后的数据。
存储设备有两种,即主存和辅存。主存由内存条组成,即在供电时能够存储数据的电子电路。辅存提供了廉价而低速的存储能力,并且能够在断电的情况下长久保存。其中,硬盘就是比较常见的一种辅存。
计算机同时存储数据和程序。数据和程序存放在辅存中并在程序执行时加载到内存中,程序更新内存中的数据并把修改后的数据写回到辅存。
环境变量:是指在操作系统指定的运行环境中的一组参数,它包含一个或多个应用程序使用的信息。环境变量一般是多值的,即一个环境变量可以有多个值。 对于Windows、linux等操作系统来说,它们都有一个系统级的环境变量PATH(路径)。当用户要求操作系统运行一个应用程序,却没有指定应用程序的完整路径时,操作系统首先会在当前路径下寻找该应用程序,如果找不到,便会到环境变量PATH指定的路径集合中寻找。若找到了,就会执行它,否则,就给出错误提示,用户可以通过设置环境变量来指定程序运行的位置。
python知识点速查




中文处理
如果脚本中带有中文(中文注释或者中文字符串,中文字符串要在前面加u),那么需要在文件头注明编码,并且还要将脚本保存为UTF-8 编码方式
# -*- coding: utf-8 -*
print u'世界,你好!'
2、安装配置Python
Python 简介
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。
Python 是一种解释型语言: 这意味着开发过程中没有了编译这个环节。类似于PHP和Perl语言。
Python 是交互式语言: 这意味着,您可以在一个 Python 提示符 >>> 后直接执行代码。
Python 是面向对象语言: 这意味着Python支持面向对象的风格或代码封装在对象的编程技术。
Python 是初学者的语言:Python 对初级程序员而言,是一种伟大的语言,它支持广泛的应用程序开发,从简单的文字处理到 WWW 浏览器再到游戏。
Python解释器
一个Python程序包含一行或多行可被翻译并由Python解释器执行的指令或语句。
Python程序由Python解释器负责解释和执行,解释器读取程序并执行它。
Python语言的特点
语法简单、跨平台、可扩展、开放源码、类库丰富
Python的历史
1990年 Python诞生
2000年 Python2.0发布
2008年 Python3.0发布
2010年 python2.7发布(最后一个2.X版本)
Python源码与文档
Python最新源码,二进制文档,新闻资讯等可以在Python的官网查看到:
Python官网:https://www.python.org/
你可以在以下链接中下载 Python 的文档,你可以下载 HTML、PDF 和 PostScript 等格式的文档。
Python文档下载地址:https://www.python.org/doc/
Window 平台安装 Python
以下为在 Window 平台上安装 Python 的简单步骤:
打开 WEB 浏览器访问https://www.python.org/downloads/windows/
在下载列表中选择Window平台安装包,包格式为:python-xyz.msi 文件 , xyz 为你要安装的版本号。
要使用安装程序 python-xyz.msi, Windows 系统必须支持 Microsoft Installer 2.0 搭配使用。只要保存安装文件到本地计算机,然后运行它,看看你的机器支持 MSI。Windows XP 和更高版本已经有 MSI,很多老机器也可以安装 MSI。
下载后,双击下载包,进入 Python 安装向导,安装非常简单,你只需要使用默认的设置一直点击"下一步"直到安装完成即可。
环境变量配置
在 Windows 设置环境变量
一|、在环境变量中添加Python目录:
在命令提示框中(cmd) : 输入
path=%path%;C:\Python 按下"Enter"。
注意: C:\Python 是Python的安装目录。
二、也可以通过以下方式设置:
右键点击"计算机",然后点击"属性"
然后点击"高级系统设置"
选择"系统变量"窗口下面的"Path",双击即可!
然后在"Path"行,添加python安装路径即可(我的D:\Python32),所以在后面,添加该路径即可。 ps:记住,路径直接用分号";“隔开!
最后设置成功以后,在cmd命令行,输入命令"python”,就可以有相关显示。
从IDLE启动Python:IDLE是一个Python Shell,shell 是一个通过键入文本与程序交互的途径。打开后如下图所示:

3、第一次使用Python
几种重要数据类型区别
字符串对象是不可变的
列表数据项不需要具有相同的类型,可以修改
元组的元素不能修改
字典元素可变,可存储任意类型对象
**集合(set)**是一个无序的不重复元素序列,可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典
python注释
解释代码,不参与运算
代码行:#
代码行:control+/ (#的快捷键)
函数中的注释:‘’‘/“”“
print语句
语法:
print(value1,value2,…,valuen)
#所有参数都是可选的,如果不指定任何参数,就输出一个空行
第一个Python程序
print("Hello World!") #在屏幕上输出 Hello World!
注意:Python区分大小写。
Python可以用做计算器

用+实现字符串连接及用*实现字符串重复

编写一个猜数字游戏
print("......你好......")
temp = input("你来猜猜我心里想的是哪个数字:")
guess = int(temp)
if guess == 6:
print("哇!你也太棒了吧!")
print("你怎么知道我心里想的什么?")
else:
print("啊哦!我现在心里想的是6!")
print("游戏结束,下次再玩")
内置函数(BIF == Built- in functions)
怎么查看Python中有哪些内置函数?
在Shell中输入dir(__builtins__) 其中纯小写的是BIF

怎么查看BIF的作用?
以input为例,在Shell中输入help(input)即可查看input的功能

4、变量和字符串
变量
变量赋值举例:

注意:
1.在使用变量之前,需要对其先赋值
2.变量名可以包括字母、数字、下划线,但变量名不能以数字开头
3.区分大小写,例如a和A对Python来说是完全不同的两个名字
4.等号(=)是赋值的意思,左边是变量名,右边的变量的值,不可以反过来写
字符串

1+1 与 “1”+"1"是完全不同的
注意:
1.单引号’ 或双引号 " 必须成对出现
2.如果想打印 Let’s go!
方法一: print("Let's go!")
方法二: 使用转义字符(\)对字符串中的引号进行转义: print('Let\'s go!')

原始字符串
1.可以用反斜杠对自身进行转义
2.在字符串前面加一个英文字母r即可

长字符串
如果希望得到一个跨越多行的字符串,需要用到三重引号字符串!
例输出下面的一首诗:
茅檐元未觉,
竹瓦偶先知。
被冷浑忘寐,
窗明得屡窥。

5、常用操作符
比较操作符
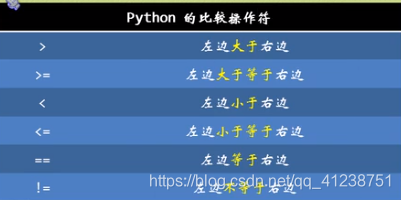
Python的条件分支语法(if…else…)
if 条件:
执行语句 #条件为真(True)执行的操作
else:
执行语句 #条件为假(False)执行的操作
第3节游戏代码该进
print("......你好......")
temp = input("你来猜猜我心里想的是哪个数字:")
guess = int(temp)
if guess == 6:
print("哇!你也太棒了吧!")
print("你怎么知道我心里想的什么?")
else:
if guess > 6:
print("猜大啦!")
else:
print("猜小咯!")
print("游戏结束,下次再玩")
while循环
while 条件:
执行语句 #条件为真时执行
加上while循环:
print("......你好......")
temp = input("你来猜猜我心里想的是哪个数字:")
guess = int(temp)
while guess != 6:
temp = input("哎呀,猜错了,请重新的输入:")
guess = int(temp)
if guess == 6:
print("哇!你也太棒了吧!")
print("你怎么知道我心里想的什么?")
else:
if guess > 6:
print("猜大啦!")
else:
print("猜小咯!")
print("游戏结束,下次再玩")
逻辑操作符
逻辑运算符可以将任意表达式连接在一起,并得到一个布尔类型的值。
and(与)两边都为真时,结果为真(True)
or(或) 两边条件只要有一个为真时,即为真
not(非) 与结果相反
a and b 如果x为False,则a and b 返回False,否则返回y的计算值
a or b 如果x非0,则返回x的值,否则返回y的计算值
not x 如果x为True,则返回False;如果x为False,则返回True


random模块
random模块中有一个函数叫做:randint(),它会返回一个随机的整数
利用randint()改编游戏:
import random
secret = random.randint(1,10)
print("......你好......")
temp = input("你来猜猜我心里想的是哪个数字:")
guess = int(temp)
while guess != secret:
temp = input("哎呀,猜错了,请重新的输入:")
guess = int(temp)
if guess == secret:
print("哇!你也太棒了吧!")
print("你怎么知道我心里想的什么?")
else:
if guess > secret:
print("猜大啦!")
else:
print("猜小咯!")
print("游戏结束,下次再玩")
6、Python的数据类型
基本数据类型
整型(int)
浮点型(float)
字符串(str)
布尔型(bool)
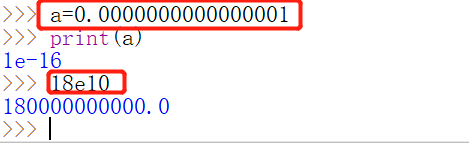
PS: e记法 (10e5代表10的5次方)
数据类型的转换
整型:int()
浮点型: float()
字符串: str()
浮点型转换成整型举例:(直接截取整数部分)

整型转换成浮点型举例:

整型转换成字符串型举例:

使用type()函数获取数据类型
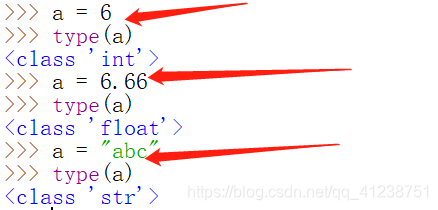
使用isinstance()函数判断数据类型

7、Python常用操作符
+= -= *= /
a +=1 相当于 a = a+1
a -=1 相当于 a = a-1
a =1 相当于 a = a1
a /=1 相当于 a = a/1
% // **
a%b 求余 , a除以b的余数
a//b 取整 , a除以b的商
a**b 幂运算 ,a的b次方

优先级
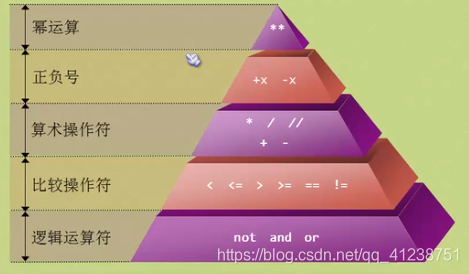
() > not > and > or
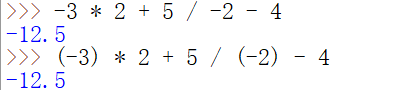
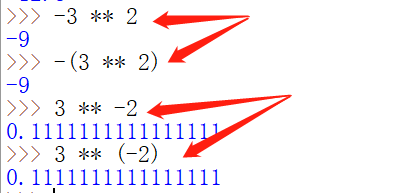
** 的优先级比较特殊,比左侧 一元操作符 优先级高,比右侧 一元操作符 优先级低
8、分支和循环1
打飞机框架:
加载背景音乐
播放背景音乐(设置单曲循环)
我方飞机诞生
interval = 0
while True:
if 用户是否点击了关闭按钮:
退出程序
interval +=1
if interval ==50
interval = 0
小飞机诞生
小飞机移动一个位置
屏幕刷新
if 用户鼠标产生移动:
我方飞机中心位置=用户鼠标位置
屏幕刷新
if 我方飞机与小飞机发生肢体冲突:
我方挂,播放撞机音乐
修改我方飞机图案
打印"Game Over"
停止背景音乐,最好淡出
9、分支和循环2
条件表达式(三元操作符)
x,y = 4,5
if x<y:
small = x
else:
small = y
相当于:
small = x if x<y else y
断言(assert)

10、分支和循环3
while循环
语法:
while 条件:
循环体
for循环
语法:
for 目标 in 表达式:
循环体
举例:


enumerate(sequence, [start=0])
sequence – 一个序列、迭代器或其他支持迭代对象。
start – 下标起始位置。
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。

seq = ['a','b','c','d']
for index,key in enumerate(seq):
print('seq [{0}] = {1}'.format(index,key))
#输出
#seq [0] = a
#seq [1] = b
#seq [2] = c
#seq [3] = d
range()函数

举例:

range()函数中只有一个参数与for结合使用:
(默认从0开始)

range()函数中只有两个参数与for结合使用:
(默认step为1)

range()函数中只有三个参数与for结合使用:

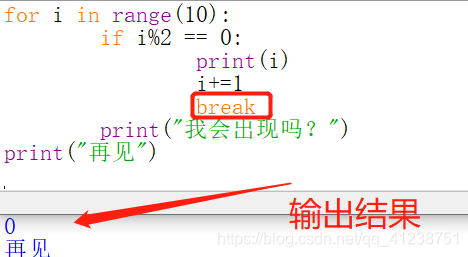
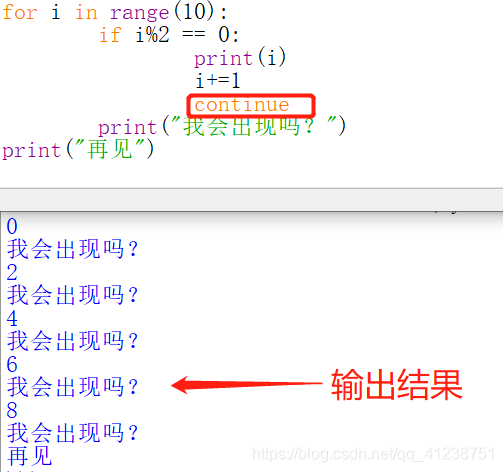
break与continue
break 终止当前循环(跳出循环体)
continue 终止本轮循环并跳到循环开始位置判断条件决定是否开始下一轮循环
举例:
break
continue
11.列表list(一)
如何创建列表
1.创建普通列表

2.创建一个混合列表

3.创建空列表

如何向列表添加元素
append()
只有一个参数,参数是要插入的元素,一次只能添加一个元素(默认添加到末尾)
注意:append()只能添加一个元素

extend()
只有一个参数,参数是要插入的元素,extend()可以一次添加多个元素,但是参数必须是列表才可以,(默认添加到末尾)

insert()
insert(a,b)里面有两个参数,第一个参数代表在列表中哪一个位置(下标)插入元素,第二个参数代表插入什么元素
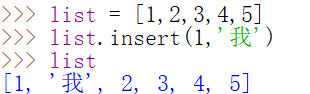
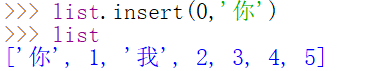
12.列表list(二)
如何从列表中获取元素

如何交换列表中元素顺序
举例:交换第一个元素和第三个元素

如何从列表中删除元素
remove()
参数是元素值,不是元素的位置

del()
参数是元素的位置

del 列表名 可以删除整个列表
pop()
pop()方法默认是从列表中取出最后一个元素,并返回

也可以取出指定位置的元素

pop 与 remove 对比
pop 移除的是索引位置对应的元素,即需要提供元素位置,同时返回该元素值
remove 移除的是列表中第一个匹配的元素,即需提供要移除的元素值,并且没有返回值
列表分片(slice)


13.列表list(三)
列表的内置函数

比较操作符
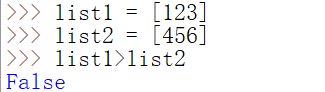

逻辑操作符
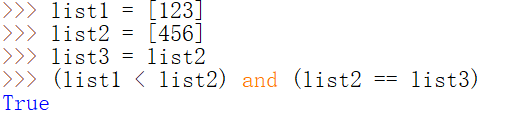
列表拼接
用+实现若干个列表拼接在一起
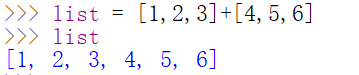
注意:
+不能实现添加新元素

列表重复
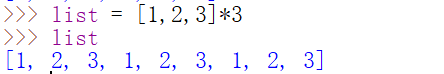
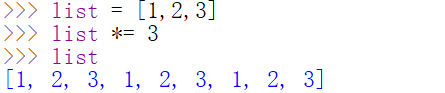
成员关系操作符
in 元素a in 列表list中
(若在就返回True,否则返回Flase)
not in 元素a not in 列表list中
(若不在就返回True,否则返回Flase)


访问列表中的列表的元素
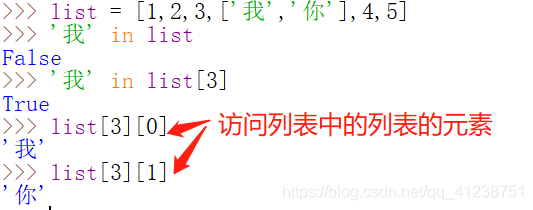
count()
可计算元素(参数)在列表中出现的次数
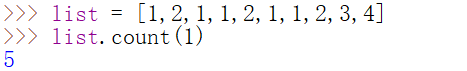
index()
返回参数在列表中第一次出现的位置
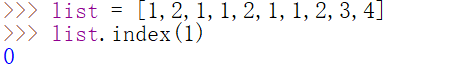
也可以指定范围,例如指定范围(4,7),该范围内1第一次出现的位置
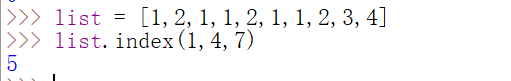
reverse()
逆置列表中的元素,默认不需要参数
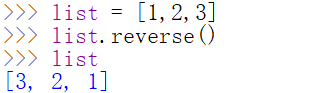
sort()与sorted()
sort()
按指定的方式对列表成员进行排序
默认不需要参数,默认是元素从小到大排序
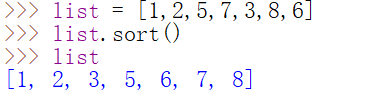
如何从大到小排序?举例如下:
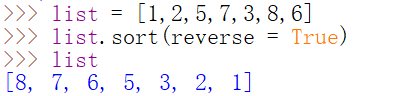
使用列表的内置方法sort()对列表排序会修改列表本身的数据,而全局内置函数sorted()则不同,它会复制原始列表的一个副本,然后在副本上进行排序操作,在排序后原始列表不变。
关于分片”拷贝“概念的补充
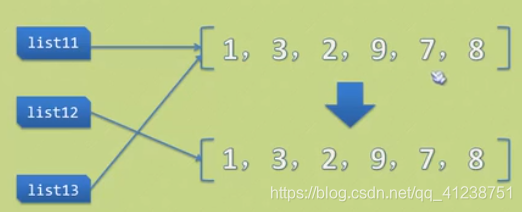

结论:
分片”拷贝“ 仅仅相当于备份一份,原列表改变不会导致分片”拷贝“的列表改变
用原列表名直接赋值给新列表名的方法”拷贝“ 相当于新列表也指向了原列表,原列表改变会同时导致新列表的改变
列表推导式(以及字典、集合推导式)
一、列表推导式
语法:[生成表达式 for 变量 in 序列或迭代对象]
以下两段代码功能相同
aList = [x**2 for x in range(4)]
print('aList:',aList)
#输出aList: [0, 1, 4, 9]
aList = []
for x in range (4):
aList.append(x**2)
#输出aList: [0, 1, 4, 9]
1.过滤原始序列中不符合条件的元素
(例:把一个列表中的整数提取出来,并作做平方处理)
a_list = [1,'4',9,'a',0,5,'hello']
squared_ints = [e**2 for e in a_list if type(e) == int]
print('squared_ints:',squared_ints) #squared_ints: [1, 81, 0, 25]
2.使用列表推导式实现嵌套列表的平铺
(利用两层for循环将嵌套列表平铺成一个列表的示例)
vec = [[1,2,3],[4,5,6],[7,8,9]]
flat_vec = [num for elem in vec for num in elem]
print(flat_vec)
#[1, 2, 3, 4, 5, 6, 7, 8, 9]
这个列表推导式中包括两个for循环,第一个for循环可视为外循环,第二个for循环可视为内循环,外循环每读取一个元素(某个内部列表元素,如[1,2,3]),内循环要遍历列表元素中的三个子元素(如1,2,3),显然,外循环跑的慢,而内循环跑的快,方括号最前方的那个num,就是输出表达式。
3.多条件组合构造特定列表
(下面的列表推导式将两个不同列表中的元素整合到了一起)
需要注意,如果表达式是一个元组,如第一行的(x,y),那么必须给它加上括号
new_list = [(x,y) for x in [1,2,3] for y in [3,1,4] if x != y]
print(new_list)
#[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
二、字典推导式
字典推导式和列表推导式的使用方法比较类似,只是需要把列表中的[],变成花括号{}
mcase = {
'a':10,'b':30,'c':50}
kv_exchange = {
v:k for k,v in mcase.items()}
print(mcase.items())
#dict_items([('a', 10), ('b', 30), ('c', 50)])
print(kv_exchange)
#{10: 'a', 30: 'b', 50: 'c'}
三、集合推导式
squared = {
x**2 for x in [1,1,2,-2,3]}
#对每个元素实施平方操作
print(squared)#集合可以达到去重的效果,输出{1, 4, 9}
14.元组tuple(不可改变的数据类型)
创建和访问一个元组

()并非是判断元组的标志性符号

,(逗号)是判断元组的标志性符号

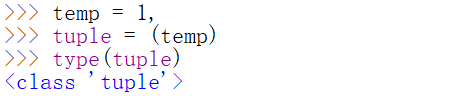
重复元组
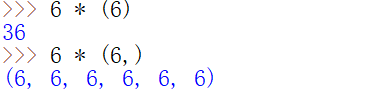
如何创建一个空元组?

更新和删除一个元组
更新和删除元组的成员,可以利用+拼接的方法(拼接两边数据类型必须一致)

删除整个元组
del 元组名
15.字符串操作(一)
分片

利用拼接的方法进行更新和删除

字符串的方法及注释
find(sub[, start[, end]])
检测 sub 是否包含在字符串中,如果有则返回索引值,否则返回 -1,start 和 end 参数表示范围,可选。

index(sub[, start[, end]]) 跟 find 方法一样,不过如果 sub 不在 string 中会产生一个异常。

capitalize() 把字符串的第一个字符改为大写

casefold() 把整个字符串的所有字符改为小写

center(width) 将字符串居中,并使用空格填充至长度 width 的新字符串

count(sub[, start[, end]]) 返回 sub 在字符串里边出现的次数,start 和 end 参数表示范围,可选。

encode(encoding=‘utf-8’, errors=‘strict’) 以 encoding 指定的编码格式对字符串进行编码。
endswith(sub[, start[, end]])
检查字符串是否以 sub 子字符串结束,如果是返回 True,否则返回 False。start 和 end 参数表示范围,可选。

expandtabs([tabsize=8]) 把字符串中的 tab 符号(\t)转换为空格,如不指定参数,默认的空格数是 tabsize=8。

isalnum() 如果字符串至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False。

isalpha() 如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False。

| isdecimal() | 如果字符串只包含十进制数字则返回 True,否则返回 False。 |
|---|---|
| isdigit() | 如果字符串只包含数字则返回 True,否则返回 False。 |
| isspace() | 如果字符串中只包含空格,则返回 True,否则返回 False。 |
| islower() | 如果字符串中至少包含一个区分大小写的字符,并且这些字符都是小写,则返回 True,否则返回 False。 |
| istitle() | 如果字符串是标题化(所有的单词都是以大写开始,其余字母均小写),则返回 True,否则返回 False。 |
| isupper() | 如果字符串中至少包含一个区分大小写的字符,并且这些字符都是大写,则返回 True,否则返回 False。 |
| – | – |
| join(sub) | 以字符串作为分隔符,插入到 sub 中所有的字符之间。 |
| ljust(width) | 返回一个左对齐的字符串,并使用空格填充至长度为 width 的新字符串。 |
| isnumeric() | 如果字符串中只包含数字字符,则返回 True,否则返回 False。 |
| lower() | 转换字符串中所有大写字符为小写。 |
| lstrip() | 去掉字符串左边的所有空格 |
| – | – |
| partition(sub) | 找到子字符串 sub,把字符串分成一个 3 元组 (pre_sub, sub, fol_sub),如果字符串中不包含 sub 则返回 (‘原字符串’, ‘’, ‘’) |
| replace(old, new[, count]) | 把字符串中的 old 子字符串替换成 new 子字符串,如果 count 指定,则替换不超过 count 次。 |
| – | – |
| rfind(sub[, start[, end]]) | 类似于 find() 方法,不过是从右边开始查找。 |
| rindex(sub[, start[, end]]) | 类似于 index() 方法,不过是从右边开始。 |
| – | – |
| rjust(width) | 返回一个右对齐的字符串,并使用空格填充至长度为 width 的新字符串。 |
| rpartition(sub) | 类似于 partition() 方法,不过是从右边开始查找。 |
| isnumeric() | 如果字符串中只包含数字字符,则返回 True,否则返回 False。 |
| rstrip() | 删除字符串末尾的空格。 |
| splitlines(([keepends])) | 在输出结果里是否去掉换行符,默认为 False,不包含换行符;如果为 True,则保留换行符。。 |
| – | – |
| split(sep=None, maxsplit=-1) | 不带参数默认是以空格为分隔符切片字符串,如果 maxsplit 参数有设置,则仅分隔 maxsplit 个子字符串,返回切片后的子字符串拼接的列表。 |
| upper() | 转换字符串中的所有小写字符为大写。 |
| – | – |
| zfill(width) | 返回长度为 width 的字符串,原字符串右对齐,前边用 0 填充。 |
| title() | 返回标题化(所有的单词都是以大写开始,其余字母均小写)的字符串。 |
| strip([chars]) | 删除字符串前边和后边所有的空格,chars 参数可以定制删除的字符,可选。 |
| swapcase() | 翻转字符串中的大小写。 |
| translate(table) | 根据 table 的规则(可以由 str.maketrans(‘a’, ‘b’) 定制)转换字符串中的字符。 |
| startswith(prefix[, start[, end]]) | 检查字符串是否以 prefix 开头,是则返回 True,否则返回 False。start 和 end 参数可以指定范围检查,可选。 |
16.字符串格式化
位置参数

关键字参数

如果混用位置参数与关键字参数,位置参数必须放置关键字参数前面
"{a} love {1}".format(a="I","you")
#输出 SyntaxError: positional argument follows keyword argument
"{0} love {b}".format("I",b="you")
#输出 'I love you'
字符串格式化符号含义
%c 格式化字符及其 ASCII 码

%s 格式化字符串
%d 格式化整数

%o 格式化无符号八进制数

%x 格式化无符号十六进制数
%X 格式化无符号十六进制数(大写)

%f格式化浮点数字,可指定小数点后的精度
%e用科学计数法格式化浮点数
%E作用同 %e,用科学计数法格式化浮点数
 %g根据值的大小决定使用 %f 或 %e
%g根据值的大小决定使用 %f 或 %e
%G作用同 %g,根据值的大小决定使用 %f 或者 %E

格式化操作符辅助命令



Python 的转义字符及其含义

17.序列
内置方法

list()把一个可迭代对象转换为列表
list() 无参数 ,新建一个空列表
list(iterable) 有参数,(iterable是一个迭代器)

tuple([iterable])把一个可迭代对象转换为元组

str(obj) 把obj对象转换为字符串
len(sub)返回sub的长度
max()返回序列或参数集合中的最大值
min()返回序列或参数集合中的最大值
max()、min()中的参数类型必须一致


sum(iterable[,start=0]) 返回序列iterable和可选参数start的总和
sorted() 使用方法与list.sort()一样

(注意) reversed(seq)
seq – 要转换的序列,可以是 tuple, string, list 或 range。
# 字符串
seqString = 'Runoob'
print(list(reversed(seqString)))
# 元组
seqTuple = ('R', 'u', 'n', 'o', 'o', 'b')
print(list(reversed(seqTuple)))
# range
seqRange = range(5, 9)
print(list(reversed(seqRange)))
# 列表
seqList = [1, 2, 4, 3, 5]
print(list(reversed(seqList)))
['b', 'o', 'o', 'n', 'u', 'R']
['b', 'o', 'o', 'n', 'u', 'R']
[8, 7, 6, 5]
[5, 3, 4, 2, 1]
enumerate() 函数
enumerate(sequence, [start=0])
用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。

enumerate()在for循环中的使用
例1
i = 0
tuple = ("a",1,'b',2)
for element in tuple:
print(i,tuple[i])
i+=1
输出
0 a
1 1
2 b
3 2
例2
tuple = ("a",1,'b',2)
for i,element in enumerate(tuple):
print(i,element)
输出
0 a
1 1
2 b
3 2
zip()

18&19.函数

函数的返回值用return语句返回

形参与实参

关键字参数

默认参数
定义了默认值的参数,调用时如果没有传递参数,会自动使用默认参数

可变参数

可变参数+其他的参数,后面的参数要用关键字参数访问,否则会出错,最好把其他函数定义为默认参数

20.函数(二)
局部变量与全局变量
正确代码:
def discounts(price,rate):
final_price = price*rate
return final_price
old_price = float(input("请输入原价:"))
rate = float(input("请输入折扣率:"))
new_price = discounts(old_price,rate)
print("打折后的价格是:",new_price)

试图输出局部变量:(错误代码)

试图输出全部变量:(不会报错)


global 关键字

内嵌函数

闭包

nonlocal关键字
(同global使用方式一样,但两者不等价)

21&22.lambda表达式
一个参数

两个参数

filter()


map()

23&24&25.递归
求阶乘
非递归方法求阶乘:
def factorial(n):
result = n
for i in range(1,n):
result *= i
return result
number = int(input("请输入一个正整数:"))
result = factorial(number)
print("%d 的阶乘是:%d" % (number,result))
输出
请输入一个正整数:5
5 的阶乘是:120
递归方法求阶乘:
def factorial(n):
if n==1:
return 1
else:
return n*factorial(n-1)
number = int(input("请输入一个正整数:"))
result = factorial(number)
print("%d 的阶乘是:%d" % (number,result))
输出
请输入一个正整数:5
5 的阶乘是:120
斐波那契数列
迭代(非递归)程序:
def F(n):
n1 = 1
n2 = 1
n3 = 1
if n<1:
print("输入错误!")
return -1
while (n-2)>0:
n3 = n1+n2
n1 = n2
n2 = n3
n -=1
return n3
result = F(20)
if result != -1:
print("总共有%d对小兔子!"% result)
总共6765对小兔子诞生!
递归程序:
def F(n):
if n<1:
print("输入有误!")
return -1
if n==1 or n==2:
return 1
else:
return F(n-1)+F(n-2)
result = F(20)
if result != -1:
print("总共%d对小兔子诞生!" % result)
总共6765对小兔子诞生!
汉诺塔
#n个盘子,3个柱子,从左到右依次是X,Y,Z
def hanoi(n,x,y,z):
if n==1:
print(x,'-->',z)
else:
hanoi(n-1,x,z,y)#将前n-1个盘子从x移动到y上
print(x,'-->',z)#将最底下的最后一个盘子从x移动到z上
hanoi(n-1,y,x,z)#将y上的n-1个盘子移动到z上
n = int(input('请输入汉诺塔的层数:'))
hanoi(n,'X','Y','Z')
输出结果如下:
请输入汉诺塔的层数:3
X --> Z
X --> Y
Z --> Y
X --> Z
Y --> X
Y --> Z
X --> Z
26&27.字典
创建和访问字典
格式:、
d = {key1 : value1, key2 : value2 }
键必须是唯一的,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字。(不能是列表类型,因为列表是可变的)

fromkeys()
创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值

keys()&values()&items()

clear() 清空字典
pop(key[,default])
删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。
popitem()
随机返回并删除字典中的最后一对键和值。
radiansdict.get(key, default=None)
返回指定键的值,如果键不在字典中返回 default 设置的默认值
radiansdict.copy()
返回一个字典的浅复制
radiansdict.update(dict2)
把字典dict2的键/值对更新到dict里
28.集合&29文件
如何创建一个集合
1.直接把一堆元素用花括号括起来
2.使用set()函数


唯一性

add()方法 & remove()方法

不可变集合frozenset

例题(考察集合推导式):把不合格的数据删除,或把实际相同但描述不同的对象(比如名字大小写不同)合并,假定有如下列表:
names = [‘Bob’,‘JOHN’,‘alice’,‘bob’,‘ALICE’,‘J’,‘Bob’]
现在我们要求将姓名长度小于2字符的删除(通常姓名的字符长度大于3),将写法相同但大小写不一样的名字合并,并按照习惯变成首字母大写,对于上面的列表,我们希望得到的结果如下:
{‘Alice’,‘Bob’,‘John’}
names = ['Bob','JOHN','alice','bob','ALICE','J','Bob']
name_1 = {
name[0].upper()+name[1:].lower() for name in names if len(name)>2}
print(name_1)
#{'Bob', 'John', 'Alice'}
29.文件
系统函数open()
Python中的 open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:
使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open(file, mode='r')
#open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)
#返回值是stream
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
#file: 必需,文件路径(相对或者绝对路径)。
#mode: 可选,文件打开模式
#buffering: 设置缓冲
#encoding: 一般使用utf8
mode格式
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
|---|---|
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等 |
| – | – |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| – | – |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| t | 文本模式 (默认)。 |
file 对象
file对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| file.close() | 关闭文件。关闭后文件不能再进行读写操作。 |
|---|---|
| file.read([size]) | 从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| file.readline([size]) | 每次读取一整行,包括 “\n” 字符。 |
| – | – |
| file.readlines([sizeint]) | 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| file.seek(offset[, whence]) | 移动文件读取指针到指定位置 |
| – | – |
| file.write(str) | 将字符串写入文件,返回的是写入的字符长度。 |
| file.writelines(sequence) | 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
读操作举例
读取E盘文本文件python-record.txt

解决方案如下:

stream = open("E:\\python-record.txt",'r',encoding = 'utf-8')
container = stream.read()
print(container)
运行结果如下:

试图读word文件会报错(默认是文本文件)
关闭文件之后不可以再读

readable() 判断文件是否是可读的
stream = open("E:\\python-record.txt",'r',encoding = 'utf-8')
result = stream.readable() #判断是否可读
print(result)
#输出True(可以读取E:\\python-record.txt文件,前提:文件存在)
readline()读取整行,包括 “\n” 字符
stream = open("E:\\python-record.txt",'r',encoding = 'utf-8')
line = stream.readline() #读取整行,包括 "\n" 字符
print(line)
#输出第一行和一行空行
用readline()读取全部文本
stream = open("E:\\python-record.txt",'r',encoding = 'utf-8')
while True:
line = stream.readline()
print(line)
if not line:
break
stream.close()
#输出全部文本内容,每输出一行内容,下面都会输出一行空行
readlines()读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。
stream = open("E:\\python-record.txt",'r',encoding = 'utf-8')
lines = stream.readlines()
print(lines)
stream.close()
运行结果:

可以读图片,但是不能显示图片,格式用 二进制形式读 即格式是 'rb’
如果是图片不能使用默认的读取方式,应该mode=‘rb’
写操作举例
1 、在E盘存在一个python-test.txt文件,里面内容是 666
stream = open("E:\\python-test.txt",'r',encoding = 'utf-8')
print(stream.read())
#读取文件内容
#输出 666
2、在上面的基础上(即文件中有内容666)进行 W 操作
stream = open("E:\\python-test.txt",'w',encoding = 'utf-8')
s = '''
你好!
明天你有时间吗?
'''
result = stream.write(s)
print(result)
stream.close()
(w操作会把原来文本内容清除,然后写入新的内容)运行结果如下
3、在2基础上(未关闭文件的情况下)再写入一个内容
stream = open("E:\\python-test.txt",'w',encoding = 'utf-8')
s = '''
你好!
明天你有时间吗?
'''
result = stream.write(s)
print(result)
w2 = stream.write("有时间")
print(w2)
stream.close() #释放资源

多次写操作在关闭文件之前
多次写,直接追加在原文本里

文件复制和OS模块
文件复制:复制一个文件
#把原文件 E:\girl.jpg (原文件在E盘已经存在) 复制到目标文件 D:\girl.jpg
with open("E:\\girl.jpg","rb") as stream: #此格式自动关闭文件,后面不需要close()
container = stream.read() #读取原文件内容
with open("D:\\girl.jpg","wb") as wstream:
wstream.write(container)
print("复制完成!")
#输出: 复制完成!(此时打开D盘可以发现已复制的文件girl.jpg)
文件复制:复制一个文件夹
上面方法不可用,上面是复制一个文件
os模块(里面包含许多函数)
使用os模块里面函数前先导入os模块

获取当前文件所在的文件目录(输出绝对路径)

把E:\girl.jpg---->保存在当前文件所在的目录下
错误代码
错误原因path定位的是一个文件夹,而open只能定位文件

正确代码
#文件复制
#把E:\girl.jpg---->保存在当前文件所在的目录下,并修改文件名为aaa.jpg
import os
with open("E:\\girl.jpg","rb") as stream: #此格式自动关闭文件,后面不需要close()
container = stream.read() #读取原文件内容
path = os.path.dirname(__file__) #获取当前文件所在的文件夹目录
path1 = os.path.join(path,"aaa.jpg") #即在当前文件所在的文件目录后拼接aaa.jpg,并返回一个新的文件目录给path1,(在当前文件所在的文件目录下新建aaa.jpg文件)
with open(path1,"wb") as wstream:
wstream.write(container)
print("复制完成!")
当不知道要复制文件的文件名时,只知道路径,怎么从路径中获取文件名,并把该文件复制到本地文件夹下
#文件复制
#把E:\girl.jpg---->保存在当前文件所在的目录下
import os
with open("E:\\girl.jpg","rb") as stream: #此格式自动关闭文件,后面不需要close()
container = stream.read() #读取原文件内容
print(stream.name) #输出路径
file = stream.name
filename = file[file.rfind("\\")+1:] #截取文件名
path = os.path.dirname(__file__) #获取当前文件所在的文件夹路径
path1 = os.path.join(path,filename)
with open(path1,"wb") as wstream:
wstream.write(container)
print("复制完成!")
相对路径与绝对路径
absolute 绝对的 (完整的路径) 例C:\User\programs
os.path.isabs(path) 判断是否为绝对路径
 相对路径:以当前路径为参照
相对路径:以当前路径为参照
前提:E盘下有两个文件夹分别是 image-test和log ,其中image-test下有一个girl.jpg文件,log里面有一个a1.txt文件
同级 ,找log同级的image-test中的image
r = os.path.isabs('image-test/girl.jpg')
print(r)
#找跟log同级的image-test里面的girl.jpg

上级 a1.txt上级的log的同级image-test下的girl.jpg
r = os.path.isabs('../image-test/girl.jpg')
print(r)
#../代表返回当前文件的上一级log

具体例子:
import os
#输出当前文件所在文件夹路径D:\Python\Python37\file01
path = os.path.dirname(__file__)
print(path)
'''
还可以用以下方法获取当前文件所在文件夹路径
path = os.getcwd()
print(path)
'''
#通过相对路径得到绝对路径 D:\Python\Python37\file01\aa.txt
#aa.txt 与 本文件 a.py是兄弟,所以不用返回是上一级
path1 = os.path.abspath('aa.txt')
print(path1)
#通过相对路径得到绝对路径D:\Python\Python37\image-test\girl.jpg
#girl.jpg 是在当前文件a.py上一级file01的同级image-test里面
path2 = os.path.abspath("../image-test/girl.jpg")
print(path2)
#获取当前文件的绝对路径D:\Python\Python37\file01\a.py
path3 = os.path.abspath(__file__)
print(path3)
os.path常用函数
os.path.split(path)
#获取当前文件名(前面已讲过filename = path[path.rfind('\\')+1:])
#以下方法也可以
path = r'D:\Python\Python37\image-test\girl.jpg'
result1 = os.path.split(path)
print(result1)
#输出一个元组('D:\\Python\\Python37\\image-test', 'girl.jpg')
print(result1[1])#输出girl.jpg
os.path.splittext(path)
#获取当前文件类型(分割文件与文件扩展名)
path = r'D:\Python\Python37\image-test\girl.jpg'
result2 = os.path.splitext(path) #分割文件与文件扩展名
print(result2) #输出('D:\\Python\\Python37\\image-test\\girl', '.jpg')
os.path.getsize(path)
#获取文件大小(单位是字节)
path = r'D:\Python\Python37\image-test\girl.jpg'
size = os.path.getsize(path)
print(size) #输出59559
os.path.join(path,‘file’…)
参数1是路径,参数2、3…是要拼接的文件名
#在当前文件所在文件夹后拼接文件
path = os.getcwd()
print(path)
#输出D:\Python\Python37\file01
result3 = os.path.join(os.getcwd(),'file','qq.jpg')
print(result3)
#输出D:\Python\Python37\file01\file\qq.jpg
文件夹操作(00)
import os
dir = os.getcwd()
print(dir) #输出D:\Python\Python37\file02
all = os.listdir(r"D:\Python\Python37\file01")#返回指定目录下的所有文件和文件夹,保存到列表中
print(all)
#输出['a.py', 'aa.txt']
创建一个文件夹
#创建文件夹(先判断是否存在同名文件夹)
if not os.path.exists(r'D:\Python\Python37\file02\new'):
f = os.mkdir(r'D:\Python\Python37\file02\new')
print(f)
#输出None,但此时打开file02会发现新创建的new文件夹
删除一个文件夹
os.rmdir()只能删除一个空的文件夹
#删除一个文件夹,只能删除一个空的文件夹
result = os.rmdir(r'D:\Python\Python37\file02\new')
print(os.path.exists(r'D:\Python\Python37\file02\new'))#输出False
#下面文件夹file03下面有文件,所以报错
result1 = os.rmdir(r'D:\Python\Python37\file02\file03')
#OSError: [WinError 145] 目录不是空的。: 'D:\\Python\\Python37\\file02\\file03'
删除非空文件夹file03
#删除非空文件夹file03
path = 'D:\\Python\\Python37\\file02\\file03'
filelist = os.listdir(path)
print(filelist) #输出['11.txt', 'qq.txt']
for file in filelist:
path1 = os.path.join(path,file)
os.remove(path1)#删除文件
else:
os.rmdir(path)
print('删除成功!')
#输出 删除成功!
#这是打开file02会发现file03已被删除
切换目录
#切换目录
path1 = os.getcwd()
print(path1) #输出D:\Python\Python37\file02
f = os.chdir(r'E:\bootdo')#切换目录
path2 = os.getcwd()
print(path2) #输出 E:\bootdo
文件夹复制
file01里都是文件,没有文件夹
#把原文件夹 D:\Python\Python37\file01复制到目标文件夹D:\Python\Python37\file02
import os
src_path = r'D:\Python\Python37\file01'
target_path = r'D:\Python\Python37\file02'
#定义copy函数,参数分别是原文件夹和目标文件夹
def copy(src,target):
if os.path.isdir(src) and os.path.isdir(target):#判断是否是文件夹
filelist = os.listdir(src) #返回指定目录下(src下)的所有文件和文件夹,返回的是列表形式
print(filelist) #输出src下所有文件和文件夹['a.py', 'aa.txt']
for file in filelist:#一次读写一个文件,利用for循环读写所有文件
path = os.path.join(src,file)#open读的是文件,
with open(path,'rb') as rstream:
container = rstream.read()#读文件里的内容放在container里
path1 = os.path.join(target,file)#文件名不变的复制到target里
with open(path1,'wb') as wstream:
wstream.write(container)
else:#所有文件读写完成
print("复制完成!")
#调用函数
copy(src_path,target_path)
如果file01里存在文件夹(00)
暂放
29文件(一)
文件打开与读取

fileObject.seek(offset[, whence])
#offset -- 开始的偏移量,也就是代表需要移动偏移的字节数,如果是负数表示从倒数第几位开始。
#whence:可选,默认值为 0。给 offset 定义一个参数,表示要从哪个位置开始偏移;0 代表从文件开头开始算起,1 代表从当前位置开始算起,2 代表从文件末尾算起。
#如果操作成功,则返回新的文件位置,如果操作失败,则函数返回 -1。

将E盘文件(python-record.txt)中的数据进行分割并按照以下规律保存起来:
1小明的对话单独保存为boy_.txt的文件(去掉小明说:")
2小红的对话单独保存为girl_.txt的文件(去掉小红说:")
3文件总共有三段对话,分别保存为boy_1.txt, girl_1.txt, boy_2.txt, girl_2.txt, boy_3.txt, girl_3.txt共6个文件(提示:文件中的不同对话已经使用"======"分割)
f = open(r"E:\python-record.txt",'r',encoding = 'utf-8') #打开目标文件
boy = []
girl = []
count = 1
for each_line in f:
if each_line[:6] != '======':
#分割字符串
(role,line_spoken) = each_line.split(":",1)#注意文本里的:是中文
if role == '小明':
boy.append(line_spoken)
if role == '小红':
girl.append(line_spoken)
else:
#字符串分别保存
file_name_boy = 'boy_'+str(count)+'.txt'
file_name_girl = 'girl_'+str(count)+'.txt'
boy_file = open(file_name_boy,'w')
girl_file = open(file_name_girl,'w')
boy_file.writelines(boy)
girl_file.writelines(girl)
boy_file.close()
girl_file.close()
boy = []
girl = []
count += 1
#前两段已保存
file_name_boy = 'boy_'+str(count)+'.txt'
file_name_girl = 'girl_'+str(count)+'.txt'
boy_file = open(file_name_boy,'w')
girl_file = open(file_name_girl,'w')
boy_file.writelines(boy)
girl_file.writelines(girl)
boy_file.close()
girl_file.close()
boy = []
girl = []
count += 1
f.close()

该进代码
def save_file(boy,girl,count):
file_name_boy = 'boy_'+str(count)+'.txt'
file_name_girl = 'girl_'+str(count)+'.txt'
boy_file = open(file_name_boy,'w')
girl_file = open(file_name_girl,'w')
boy_file.writelines(boy)
girl_file.writelines(girl)
boy_file.close()
girl_file.close()
def split_file(file_name):
f = open(r"E:\python-record.txt",'r',encoding = 'utf-8') #打开目标文件
boy = []
girl = []
count = 1
for each_line in f:
if each_line[:6] != '======':
#分割字符串
(role,line_spoken) = each_line.split(":",1)#注意文本里的:是中文
if role == '小明':
boy.append(line_spoken)
if role == '小红':
girl.append(line_spoken)
else:
save_file(boy,girl,count)
boy = []
girl = []
count += 1
#前两段已保存
save_file(boy,girl,count)#保存第三段
f.close()#f.close() 应与for下载同一级别,否则缩进错误ValueError: I/O operation on closed file.
split_file("python-record.txt")
30.模块
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。
os模块

os.path模块

32.pickle模块
pickle提供了一个简单的持久化功能。可以将对象以文件的形式存放在磁盘上。
pickle模块只能在python中使用,python中几乎所有的数据类型(列表,字典,集合,类等)都可以用pickle来序列化,
pickle序列化后的数据,可读性差,人一般无法识别。

读取时用’rb’ 如果内容为空,会报错:EOFError: Ran out of input


把字典city,写成pickle

33&34异常处理
常见错误类型举例
AssertionError 断言语句(assert)失败
AttributeError 尝试访问未知的对象属性

IndexError 索引超出序列的范围

KeyError 字典中查找一个不存在的关键字

NameError 尝试访问一个不存在的变量

try-except语句
格式:
try:
检测范围
except Exception[as reasion]:
出现异常(Exception)后的处理代码

try:
with open(r'D:\111111.txt') as f:
print(f.read())
except OSError as reason:
print('文件出错啦!\n出错的原因是:'+ str(reason))
#输出
#文件出错啦!
#出错的原因是:[Errno 2] No such file or directory: 'D:\\111111.txt'
try:
sum = 1+'1'#程序在某处检测到错误,剩下的语句不会执行
with open(r'D:\111111.txt') as f:
print(f.read())
except OSError as reason:
print('文件出错啦!\n出错的原因是:'+ str(reason))
except TypeError as reason:
print('类型出错啦!\n出错的原因是:'+ str(reason))
#输出
#类型出错啦!
#出错的原因是:unsupported operand type(s) for +: 'int' and 'str'
try-finally语句
try:
检测范围
except Exception[as reason]:
出现异常(Exception)后的处理代码
finally:
无论如何都会执行的代码

1.txt中并没有写入内容,因为f.close()之前的sum = 1+'1’出现异常,所以f.close()没有被执行,即1.txt写入的内容没有保存,该进代码如下:
try:
f = open(r'D:\Python\Python37\1.txt','w')
print(f.write('aaa'))
sum = 1 + '1'
except TypeError as reason:
print('类型出错啦!\n出错的原因是:'+ str(reason))
finally:
f.close()
#输出
#3
#类型出错啦!
#出错的原因是:unsupported operand type(s) for +: 'int' and 'str'
raise语句
35.else语句与with语句

用with语句打开文件,默认关闭,可以避免忘记关闭文件
格式:
with oopen("文件地址",'r') as f:
36.图形用户界面入门:EasyGui
没下载
37&38.介绍对象
对象 = 属性 + 方法
类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
**方法:**类中定义的函数。
**类变量:**类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
局部变量:定义在方法中的变量,只作用于当前实例的类。
**实例变量:**在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用 self 修饰的变量。
**继承:**即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
实例化:创建一个类的实例,类的具体对象。
对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
类定义的格式:
class ClassName: #类名的第一个字母大写。
<statement-1>
.
.
.
<statement-N>
#类实例化后,可以使用其属性,实际上,创建一个类之后,可以通过类名访问其属性。
self代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。即类方法必须包含参数 self, 且为第一个参数,self 代表的是类的实例。(self 不是 python 关键字,我们把他换成 aaa 也是可以正常执行的)
class Test:
def p(self):
print(self)
print(self.__class__)
t = Test()
t.p()
#输出
#<__main__.Test instance at 0x100771878>
#__main__.Test
从以上执行结果可以很明显的看出,self 代表的是类的实例,代表当前对象的地址,而 self.class 则指向类。
class A:
name = 'a'
def f1(self,name):
self.name = name
print(self.name)
def f2(self):
#self.__class__指向类A,self.__class__.name相当于A.name
print(self.__class__.name)
def f3(self,args):
self.__class__.name = args
print(self.__class__.name)
a = A()#实例化对象a
a.f1('qq') #把参数qq传入f1方法中,并输出
a.f2() #输出A.name
a.f3('QQ')#通过f3修改A.name的值
b = A()
b.f2()#输出QQ,因为上面a.f3('QQ')把A.name的值修改了


init(self)

公有与私有
在Python中定义私有变量只需要在变量名或函数名前加上’__'两个下划线,那么这个函数或变量就会变成私有的了

定义私有变量,在外部无法访问

该进

#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我今年 %d 岁了。" %(self.name,self.age))
# 实例化类
p = people('小明',8,30)
p.speak()
#输出
#小明 说: 我今年 8 岁了。
39.继承
派生类的定义格式:
class DerivedClassName(BaseClassName1):
<statement-1>
.
.
.
<statement-N>
#BaseClassName(示例中的基类名)必须与派生类定义在一个作用域内。

如果子类中定义与父类同名的方法或属性,则会自动覆盖父类对应的方法或属性

单继承举例(包括重写父类的方法)
class Parent():
#定义普通属性
name = ''
age = 0
#定义构造方法
def __init__(self,n,a):
self.name = n
self.age = a
def speak(self):
print("%s说他今年%d岁了"%(self.name,self.age))
#单继承
class Child(Parent):
sex = ''
def __init__(self,n,a,s):
Parent.__init__(self,n,a)#调用父类的构造函数
self.sex = s
def speak(self):
print("%s说她今年%d岁了,并且她%s生"%(self.name,self.age,self.sex))
c = Child("小红",5,"女")
c.speak()
#输出
#小红说她今年5岁了,并且她女生
import random as r
class Fish:
def __init__(self):
self.x = r.randint(0,10)
self.y = r.randint(0,10)
def move(self):
self.x -= 1
print("我现在的位置是:",self.x,self.y)
class Goldfish(Fish):
pass
class Carp(Fish):
pass
class Shark(Fish):
def __init__(self):
self.hungry = True
def eat(self):
if self.hungry:
print("我要开始出东西啦")
self.hungry = False
else:
print("太撑了,吃不下")

shark.move()报错是因为,定义子类Shark时的__init__(self)
与父类中的方法相同,父类中的__init__(self)被覆盖
该进方案1:
调用未绑定的父类方法
import random as r
class Fish:
def __init__(self):
self.x = r.randint(0,10)
self.y = r.randint(0,10)
def move(self):
self.x -= 1
print("我现在的位置是:",self.x,self.y)
class Goldfish(Fish):
pass
class Carp(Fish):
pass
class Shark(Fish):
def __init__(self):
Fish.__init__(self)#调用未绑定的父类的方法,此时的self是子类Shark的实例对象
self.hungry = True
def eat(self):
if self.hungry:
print("我要开始出东西啦")
self.hungry = False
else:
print("太撑了,吃不下")

该进方案2:
使用super函数
import random as r
class Fish:
def __init__(self):
self.x = r.randint(0,10)
self.y = r.randint(0,10)
def move(self):
self.x -= 1
print("我现在的位置是:",self.x,self.y)
class Goldfish(Fish):
pass
class Carp(Fish):
pass
class Shark(Fish):
def __init__(self):
super().__init__()#不用给出基类的名字,自动找出基类对应的方法
self.hungry = True
def eat(self):
if self.hungry:
print("我要开始出东西啦")
self.hungry = False
else:
print("太撑了,吃不下")

super使用举例2
class A:
def sub(self,x):
y = x-2
print(y)
class B(A):
def sub(self,x):
super().sub(x)
b = B()
b.sub(9)
#输出
#7
方法重写
class Parent: # 定义父类
def Method(self):
print ('调用父类方法')
class Child(Parent): # 定义子类
def Method(self):
print ('调用子类方法')
c = Child() # 子类实例
c.Method() # 子类调用重写方法
super(Child,c).Method() #用子类对象调用父类已被覆盖的方法
#调用子类方法
#调用父类方法
多重继承
多继承类定义
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-N>
#需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
举例1

例2
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
#单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
#另一个类,多重继承之前的准备
class speaker():
topic = ''
name = ''
def __init__(self,n,t):
self.name = n
self.topic = t
def speak(self):
print("我叫 %s,我是一个演说家,我演讲的主题是 %s"%(self.name,self.topic))
#多重继承
class sample(speaker,student):
a =''
def __init__(self,n,a,w,g,t):
student.__init__(self,n,a,w,g)
speaker.__init__(self,n,t)
test = sample("Tim",25,80,4,"Python")
test.speak() #方法名同,默认调用的是在括号中排前地父类的方法
40拾遗
组合
(把类的实例化放到新类里面,就把旧类组合进去了,就不用继承了)
class Turtle:
def __init__(self,x):
self.num = x
class Fish:
def __init__(self,x):
self.num = x
class Pool:
def __init__(self,x,y):
self.turtle = Turtle(x)
self.fish = Fish(y)
def print_num(self):
print("水池里一共有%d只乌龟,%d条小鱼" %(self.turtle.num,self.fish.num))
#self.turtle是一个类

类、类对象和实例对象(00000)
类中定义的属性和方法是静态的
41.类与对象相关的BIF
issubclass(class,classinfo)
1.一个类被认为是自身的子类
2.如果 class 是 classinfo 的子类返回 True,否则返回 False。

isinstance(object,classinfo)
1.如果第一个参数不是对象,则永远返回False
2.如果对象的类型与参数二的类型(classinfo)相同则返回 True,否则返回 False

hasattr(object,name)
hasattr() 函数用于判断对象是否包含对应的属性,如果对象有该属性返回 True,否则返回 False。

getattr(object, name[, default])
#object -- 对象。
#name -- 字符串,对象属性。
#default -- 默认返回值,如果不提供该参数,在没有对应属性时,将触发 AttributeError。
getattr() 函数用于返回一个对象属性值。

setattr(object, name, value)
#object -- 对象。
#name -- 字符串,对象属性。
#value -- 属性值。
setattr() 函数对应函数 getattr(),用于设置属性值,该属性不一定是存在的,如果属性不存在,则会创建该属性

delattr(object,name)
#object -- 对象。
#name -- 必须是对象的属性。
delattr 函数用于删除属性。
delattr(x, ‘foobar’) 相等于 del x.foobar。

class property([fget[, fset[, fdel[, doc]]]])
#fget -- 获取属性值的函数
#fset -- 设置属性值的函数
#fdel -- 删除属性值函数
#doc -- 属性描述信息
property() 函数的作用是在新式类中返回属性值。

42.构造与析构
init(self)
**情况一:**子类需要自动调用父类的方法:子类不重写__init__()方法,实例化子类后,会自动调用父类的__init__()的方法。
**情况二:**子类不需要自动调用父类的方法:子类重写__init__()方法,实例化子类后,将不会自动调用父类的__init__()的方法。
**情况三:**子类重写__init__()方法又需要调用父类的方法:使用super关键词:
super(子类,self).__init__(参数1,参数2,....)
class Son(Father):
def __init__(self, name):
super(Son, self).__init__(name)
init(self) 返回值一定是None(一般类中需要初始化操作用它)

new(cls[,…]) 对象实例化时调用的第一个方法,返回一个对象,
如果继承不可改变类型且又需要对不可改变类型修改时时,需要重写__new__(cls)

del(self)

43.算术运算1
44.时间 time
1 函数time.time()用于获取当前时间戳
import time
ticks = time.time()
print(ticks)
#输出1600069594.4135377
#时间戳:每个时间戳都以自从1970年1月1日午夜(历元)经过了多长时间来表示。
2 获取当前时间
import time
localtime = time.localtime(time.time())
print(localtime)
#输出time.struct_time(tm_year=2020, tm_mon=9, tm_mday=14, tm_hour=15, tm_min=48, tm_sec=50, tm_wday=0, tm_yday=258, tm_isdst=0)
3 格式化日期
我们可以使用 time 模块的 strftime 方法来格式化日期,:
import time
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
#输出2020-09-14 16:00:33