前言:
一直都想学Python,之前粗略看过【Python学习手册(第4版)】,现在基本忘光了,毕竟没怎么用它来写代码。重新翻开这本书时感觉有些老了,于是随便找了本先看着,快要读完时又发现了宝藏——【Python语言程序设计】(据说是斯坦福大学的教材),等这本书看完后再拿那本书巩固、补充好了。
变量
用法:变量 = 赋值内容
answer = 42
print()
用法:print(内容)
print(answer) print('hello world!')file = open('D:/PythonCode/file.txt', 'w') file.write('hello world')
字符串
用法:可用单引号、双引号或三个引号(连接换行的文本)来表示
加法
what_he_does = ' plays ' his_instrument = 'guitar' his_name = 'Robert Johnson' artist_intro = his_name + what_he_does + his_instrument print(artist_intro)类型转换
num = 1 string = '1' num2 = int(string) print(num + num2)乘法
words = 'words' * 3 print(words)word = 'a loooooong word' num = 12; string = 'bang!' total = string * (len(word) - num) print(total)分片与索引
[x:y] --> [x,y)
[x:] --> [x,len]
[:x] --> [0, x)
正向索引:从前往后字符下标依次为0、1、…、len-1
反向索引:从后往前字符下标依次为-1、-2、…、-len
字符串的方法
search = '168' num_a = '1386-168-0006' num_b = '1681-222-0006' print(search + ' is at ' + str(num_a.find(search)) + ' to ' + str(num_a.find(search) + len(search)) + ' of num_a') print(search + ' is at ' + str(num_b.find(search)) + ' to ' + str(num_b.find(search) + len(search)) + ' of num_b')字符串格式化符
print('{} a word she can get what she {} for.'.format('With', 'came')) print('{preposition} a word she can get what she {verb} for'.format(preposition = 'With', verb = 'came')) print('{0} a word she can get what she {1} for.'.format('With', 'came'))
函数
内建函数
自定义函数
定义
def function(arg1, arg2): # 不要漏掉冒号 return 'Something'举例(摄氏度转化为华氏度)
def fahrenheit_converter(C): fahrenheit = C * 9 / 5 + 32 return str(fahrenheit) + '°F'
传递参数与参数类型
位置参数:将数值传到对应位置上,如function(1, 2)。
关键词参数:通过在参数列表里填写
对应变量名 = 数值,如function(arg1 = 1, arg2 = 2)。注意:通过关键词参数传参时位置可不用对应;通过位置参数传参时位置需对应。
简单函数设计
在桌面写入的文件名称和内容的函数
def text_create(name, msg): desktop_path = 'C://Users/a/Desktop/' full_path = desktop_path + name + '.txt' # 文件路径 file = open(full_path, 'w') # 'w'代表写入模式,如果没有就在该路径创建一个有该名称文本,有则追加覆盖文本内容 file.write(msg) # 写入传入的参数msg,即内容 file.close() # 关闭文本 print('Done') text_create('hello', 'hello world')敏感词替换器
def text_filter(word, censored_word = 'lame', changed_word = 'Awesome'): return word.replace(censored_word, changed_word) print(text_filter('Python is lame!'))在桌面上创建一个文本可以在其中输入文字,如果信息中有敏感词将默认过滤后写入文件。
def text_create(name, msg): desktop_path = 'C://Users/a/Desktop/' full_path = desktop_path + name + '.txt' file = open(full_path, 'w') file.write(msg) file.close() print('Done') def text_filter(word, censored_word = 'lame', changed_word = 'Awesome'): return word.replace(censored_word, changed_word) def censored_text_create(name, msg): clean_msg = text_filter(msg) text_create(name, clean_msg) censored_text_create('try', 'lame!lame!lame!')
逻辑控制与循环
逻辑判断:True、False
比较运算:>、<、>=、<=、==、!=
成员运算符与身份运算符
in:表示归属关系的布尔运算符。
判断一个元素是否在列表/字典中/元组/集合…中。
is:表示身份鉴别的布尔运算符。
与==的区别:is比较的是地址,==比较的是内容。
布尔运算符:not、and、or
条件控制
格式
if condition: do something else: do something例子
def account_login(): password = input('Passowrd:') if password == '12345': print('Login success!') else: print('Wrong password or invalid input!') account_login() account_login()else if的写法
if condition: do something elif condition: do something else: do something例子
password_list = ['*#*#', '12345'] def account_login(): password = input('Passowrd:') password_correct = password == password_list[-1] password_reset = password == password_list[0] if password_correct: print('Login success!') elif password_reset: new_password = input('Enter a new password:') password_list.append(new_password) print('Your password has changed successfully!') account_login() else: print('Wrong password or invalid input!') account_login() account_login()
循环
for循环
格式:
for item in iterable: do something例子:
for every_letter in 'Hello world': print(every_letter)for num in range(1, 11): print(str(num) + ' + 1 =', num + 1)songslist = ['Holy Diver', 'Thunderstruck', 'Rebel Rebel'] for song in songslist: if song == 'Holy Diver': print(song, '- Dio') elif song == 'Thunderstruck': print(song, '- AC/DC') elif song == 'Rebel Rebel': print(song, '- David Bowie')
嵌套循环
格式:
for item1 in iterable1: for item2 in iterable2: do something例子:
for i in range(1, 10): for j in range(1, 10): print('{} X {} = {}'.format(i, j, i * j))
while循环
格式:
while condition: do something举例:
count = 0 while True: print('Repeat this line !') count = count + 1 if count == 5: break上面的登陆函数增加新功能:输入密码错误超过3次就禁止再次输入密码
password_list = ['*#*#', '12345'] def account_login(): tries = 3; while tries > 0: password = input('Passowrd:') password_correct = password == password_list[-1] password_reset = password == password_list[0] if password_correct: print('Login success!') elif password_reset: new_password = input('Enter a new password:') password_list.append(new_password) print('Your password has changed successfully!') account_login() else: print('Wrong password or invalid input!') tries = tries - 1 print(tries, 'times left') else: print('Your account has been suspended') account_login()
练习题
设计一个函数,在桌面上创建10个文本,以数字给它们命名。
def create_files(): desktop_path = 'C://Users/a/Desktop/' for i in range(1, 11): full_path = desktop_path + str(i) + '.txt' file = open(full_path, 'w') file.close()设计一个复利计算函数invest(),它包含三个参数amount、rate、time。输入每个参数后调用函数,应该返回每一年的资金总额。
def invest(amount, rate, time): for i in range(1, time + 1): amount = amount * (1 + rate) print('year {}: ${}'.format(i, amount))打印1~100内的偶数
for i in range(1, 101): if i & 1 == 0: print(i)
综合练习
设计一个猜大小的小游戏
import random def roll_dice(numbers = 3, points = None): print("<<<<< ROLE THE DICE! >>>>>") if points is None: points = [] while numbers > 0: point = random.randrange(1, 7) points.append(point) numbers = numbers - 1 return points def roll_result(total): isBig = 11 <= total <= 18 isSmall = 3 <= total <= 10 if(isBig): return 'Big' elif(isSmall): return 'Small' def start_game(): print("<<<<< GAME STARTS! >>>>>") choice = ['Big', 'Small'] your_choice = input('Big or Small: ') if your_choice in choice: points = roll_dice() total = sum(points) youWin = your_choice == roll_result(total) if youWin: print('The points are', points, 'You win !') else: print('The points are', points, 'You lose !') else: print('Invalid Words') start_game() start_game()
练习题
在猜大小基础上增加如下功能:
- 初始金额为1000元;
- 金额为0时游戏结束;
- 默认赔率为1倍,押对了能得到相应金额,押错了会输掉相应金额。
import random def roll_dice(numbers = 3, points = None): print("<<<<< ROLE THE DICE! >>>>>") if points is None: points = [] while numbers > 0: point = random.randrange(1, 7) points.append(point) numbers = numbers - 1 return points def roll_result(total): isBig = 11 <= total <= 18 isSmall = 3 <= total <= 10 if(isBig): return 'Big' elif(isSmall): return 'Small' def start_game(): money = 1000 while money > 0: print("<<<<< GAME STARTS! >>>>>") choice = ['Big', 'Small'] your_choice = input('Big or Small: ') rate = int(input('How much you wanna bet ? -')) if rate > money or rate < 0: print('Invalid Money') else: if your_choice in choice: points = roll_dice() total = sum(points) youWin = your_choice == roll_result(total) if youWin: print('The points are', points, 'You win !') money += rate print('You gained {}, You have {} now'.format(rate, money)) else: print('The points are', points, 'You lose !') money -= rate print('You lost {}, you have {} now'.format(rate, money)) else: print('Invalid Words') else: print('GAME OVER') start_game()设计一个检验号码真实性的函数,检验规则如下:
号码长度为11位;
是移动、联通、电信号段中的一个电话号码(移动、联通、电信号段如下);
CN_mobile = [134,135,136,137,138,139,150,151,152,157,158,159,182,183,184,187,188,188,147,178,1705]
CN_union = [130,131,132,155,156,185,186,145,176,1709]
CN_telecom = [133,153,180,181,189,177,1700]输入的号码外的其他字符可以忽略。
def Phone_check(): while True: CN_mobile = [134,135,136,137,138,139,150,151,152,157,158,159,182,183,184,187,188,147,178,1705] CN_union = [130,131,132,155,156,185,186,145,176,1709] CN_telecom = [133,153,180,181,189,177,1700] number_str = input('Input your number:') number = 0 for i in range(len(number_str)): if number_str[i] >= '0' and number_str[i] <= '9': number = number * 10 + int(number_str[i]) first_three = int(str(number)[0:3]) first_four = int(str(number)[0:4]) if len(str(number)) == 11: if first_three in CN_mobile or first_four in CN_mobile: print('Operater : China Mobile') print('We\'re sending verification code via text to your phone:', number) break if first_three in CN_union or first_four in CN_union: print('Operater : China Union') print('We\'re sending verification code via text to your phone:', number) break if first_three in CN_telecom or first_four in CN_telecom: print('Operater : China Telecom') print('We\'re sending verification code via text to your phone:', number) break else: print('No such a operater') else: print('Invalid length, your number should be in 11 digits') Phone_check()
数据结构
列表
特征:
(1).表中的每个元素都是可变的;
(2).表中的元素都是有序的,都有自己的位置;
(3).列表可以容纳Python中的任何对象。
定义
fruit = ['poneapple', 'pear']添加元素
插入的位置是实际指定位置之前的位置,如指定插入的位置在列表中不存在(实际上超出了指定列表长度)则元素会被放到列表的最后位置。
fruit.insert(1, 'grape') fruit[0:0] = ['orange']删除元素
可以直接remove
fruit.remove('pear')可以直接替换
fruit[0] = 'apple'使用del关键字来声明
del fruit[0:2]查找元素
输入对应位置就返回对应位置上的值
periodic_table = ['H','He','Li','Be','B','C','N','O','F','Ne'] print(periodic_table[0]) print(periodic_table[-2]) print(periodic_table[0:3]) print(periodic_table[-10:-7]) print(periodic_table[-10:]) print(periodic_table[:9])
字典
特征
(1).字典中数据必须是以键值对的形式出现的;
(2).逻辑上讲,键(key)是不能重复的,值(value)可以重复;
(3).字典中,键是不可变的,而值是可以变的,可以是任何对象。
定义
Dic = {key:value}Dic = { 'A':'a', 'B':'b', 'C':'c' }添加元素
添加单一元素
Dic[key] = valueDic['D'] = 'd'添加多个元素
Dic.update({key1:value1, key2:value2})Dic.update({'E':'e', 'F':'f'})删除
使用del方法
del Dic[key]del Dic['A']索引
输入对应key就返回对应value
元组
可以理解为一个稳固版的列表,因为元组不可修改。但元组可以被查看索引。
letters = ('a','b','c','d','e','f','g') print(letters[0])集合
特性:集合中的元素是无序的、不重复的任意对象,可以通过集合去判断数据从属关系、把数据结构中重复的元素减掉。
集合不能被切片也不能被索引,除了做集合运算外,集合元素还可以被添加和删除。
(1).集合运算
a = set('abracadabra') b = set('alacazam') print(a) print(b) print(a - b) # a中包含但b中不包含的元素 print(a | b) # 集合a或b中包含的元素 print(a & b) # 集合a和b中都包含的元素 print(a ^ b) # 不同时包含于a和b的元素(2).添加和删除
a_set = {2,1,1,3,4} print(a_set) a_set.add(5) print(a_set) a_set.discard(5) print(a_set)
数据结构的一些技巧
结合函数使用
num_list = [6, 2, 7, 4, 1, 3, 5] print(sorted(num_list)) print(sorted(num_list, reverse = True))推导式(列表的解析式)
(1).格式
list = [item for item in iterable] Dic = {key:value for item in iterable}a = [i**2 for i in range(1, 10)] b = [j + 1 for j in range(1, 10)] c = [k for k in range(1, 10) if k % 2 == 0] d = [l.lower() for l in 'ABCDEFGHIJKLMN'] e = {i:i+1 for i in range(4)} f = {i:j for i, j in zip(range(1,6), 'abcde')} g = {i:j.upper() for i, j in zip(range(1,6), 'abcde')}(2).将10个元素装进列表中的普通写法VS列表解析式的方法
a = [] for i in range(1, 11): a.append(i) print(a)b = [i for i in range(1, 11)] print(b)(3).循环列表时获取元素的索引 普通写法 VS 用enumerate函数
letters = ['a','b','c','d','e','f','g'] i = 0 for elem in letters: print(i, letters[i]) i += 1for i, elem in enumerate(letters): print(i, elem)
综合项目
做一个词频统计项目
分割单词的方法
lyrics = 'The night begin to shine, the night begin to shine' words = lyrics.split() print(words)词频统计(有问题)
path = 'D://PythonCode/Walden2.txt' with open(path, 'r') as text: words = text.read().split() print(words) for word in words: print('{}-{} times'.format(word, words.count(word)))上面代码的问题:
(1). 带标点的单词被单独统计了;
(2). 有些单词次数出现了多次;
(3). 开头大写的被单独统计了。
解决方法:
(1). 用strip函数移去单词里的标点符号;
(2). 用lower将字符统一转换为小写;
(3). 用set去重,用字典将每个单词出现的次数与单词对应起来。
(4). 最后加序是为了让单词按照出现频率从大到小的顺序依次输出。
代码
import string path = 'D://PythonCode/Walden2.txt' with open(path, 'r') as text: words = [raw_word.strip(string.punctuation).lower() for raw_word in text.read().split()] words_index = set(words) counts_dict = {index : words.count(index) for index in words_index} for word in sorted(counts_dict, key = lambda x : counts_dict[x], reverse = True): print('{} -- {} times'.format(word, counts_dict[word]))
类
定义
类是有一系列有共同特征和行为事物的抽象概念的总和。
在类里赋值的变量就是类的变量,类的变量有一个专有的术语,我们称之为类的属性。
class CocaCola: formula = ['affeine', 'suger', 'water', 'soda']实例化
在左边创建一个变量,右边写上类的名称,这种像赋值的行为,我们称之为类的实例化;被实例化后的对象,我们称之为实例,或者说是类的实例。
cola_for_me = CocaCola() cola_for_you = CocaCola()类属性的引用
在类后面输入
.,IDE就会自动联想出我们之前在定义类的时候写在里面的属性,而这就是类属性的引用。由于类的属性会被所有类的实例共享,所以在类的实例后面再加上
.,索引用的属性值是完全一样的。print(CocaCola.formula) print(cola_for_me.formula) print(cola_for_you.formula)实例属性
创建类之后,通过
object.new_attr的形式进行一个赋值,于是我们就得到了一个新的实例的变量,实例的变量就是实例变量,而实例变量有一个专有的术语,我们称之为实例属性。cola_for_China = CocaCola() cola_for_China.local_logo = '可口可乐' print(cola_for_China.local_logo)实例方法
方法就是函数,方法是供实例使用的,因此我们还可以称之为实例方法。
class CocaCola: formula = ['affeine', 'suger', 'water', 'soda'] def drink(self): print('Energy!') cola = CocaCola() cola.drink()更多参数
和函数一样,类的方法也能有属于自己的参数。
class CocaCola: formula = ['affeine', 'suger', 'water', 'soda'] def drink(self, how_much): if how_much == 'a sip': print('Cool~') elif how_much == 'whole bottle': print('Headache!') ice_cola = CocaCola() ice_cola.drink('a sip')“魔术方法”
__init__():如果在类中定义了它,在创建实例时它就自动帮你处理很多事情——如增加实例属性。class CocaCola: formula = ['affeine', 'suger', 'water', 'soda'] def __init__(self): self.local_logo = '可口可乐' def drink(self): print('Energy!') cola = CocaCola() print(cola.local_logo)class CocaCola: formula = ['affeine', 'suger', 'water', 'soda'] def __init__(self): for element in self.formula: print('Cola has {}!'.format(element)) def drink(self): print('Energy!') cola = CocaCola()除了必写的
self参数之外,__init__()同样可以有自己的参数,同时不需要obj.__init__()的方式来调用(因为是自动执行),而是在实例化的时候往类后面的括号中放进参数,相应的所有参数都会传递到这个特殊的__init__()方法中,和函数的参数的用法完全相同。self.local_logo = logo_name中,左边是变量作为类的属性,右边是传入的参数作为变量。class CocaCola: formula = ['affeine', 'suger', 'water', 'soda'] def __init__(self, logo_name): self.local_logo = logo_name def drink(self): print('Energy!') cola = CocaCola('可口可乐') print(cola.local_logo)类的继承
父类
class CocaCola: calories = 140 sodium = 45 total_carb = 39 caffeine = 34 ingredients = [ 'High Fructose Corn Syrup', 'Carbonated Water', 'Phosphoric Acid', 'Natural Flavors', 'Caramel Color', 'Caffeine' ] def __init__(self, logo_name): self.local_logo = logo_name def drink(self): print('You got {} cal energy!'.format(self.calories))子类:父类中的变量和方法可以完全被子类继承,但如需有特殊的改动也可以进行覆盖。
class CaffeineFree(CocaCola): caffeine = 0 ingredients = [ 'High Fructose Corn Syrup', 'Carbonated Water', 'Phosphoric Acid', 'Natural Flavors', 'Caramel Color' ] cola_a = CaffeineFree('CocaCola-FREE') cola_a.drink()类属性与实例属性
Q1:类属性如果被重新赋值,是否会影响到类属性的引用?
Q2:实例属性如果被重新赋值,是否会影响到类属性?
Q3:类属性实例属性具有相同的名称,那么
.后面引用的将会是什么?A1:会。
class TestA: attr = 1 obj_a = TestA() TestA.attr = 42 print(obj_a.attr) #42A2:不会。
class TestA: attr = 1 obj_a = TestA() obj_b = TestA() obj_a.attr = 42 print(obj_b.attr) # 1A3:
class TestA: attr = 1 def __init__(self): self.attr = 42 obj_a = TestA() print(obj_a.attr) # 42解释:
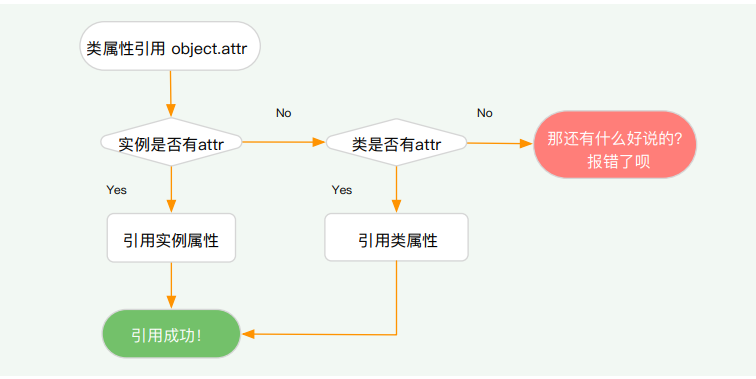
__dict__是一个类的特殊属性,它是一个字典,用于存储类或者实例的属性,即使你不去定义它,它也会存在于每一个类中,是默认隐藏的。让我们在上面代码中添加新的一行,结合代码理解一下:
class TestA: attr = 1 def __init__(self): self.attr = 42 obj_a = TestA() print(TestA.attr) # 1 print(obj_a.attr) # 42Python中属性的引用机制是自内而外的,放你创建了一个实例之后,准备开始引用属性,这时候编译器会首先搜索该实例是否拥有该属性,如果有,则引用;如果没有,将搜索这个实例所属的类是否有这个属性,如果有,则引用,没有就报错。