浅谈Transformer
其他
2020-05-03 13:29:10
阅读次数: 0
浅谈Transformer
来源
- 源自谷歌论文《Attention Is All You Need》,论文链接
self attention自注意力机制
- 使用self attention自注意力机制来计算文本输入和输出的表示,摒弃RNN和CNN的结构。RNN的缺点:难以并行。CNN的缺点:卷积仅考虑局部信息,要卷积得到全局信息的话得用层级卷积,但还是会有信息丢失,且缺少上下文依赖。
- self attention是指Attention机制中的Q、K、V三者中,K和V是相同的输入序列。在具体问题中具体分析,比如在问答系统中,Q是问题,K和V是答案。在文本分类任务中,Q、K、V三者都取相同的值。
- 自注意力机制的示意图如下:
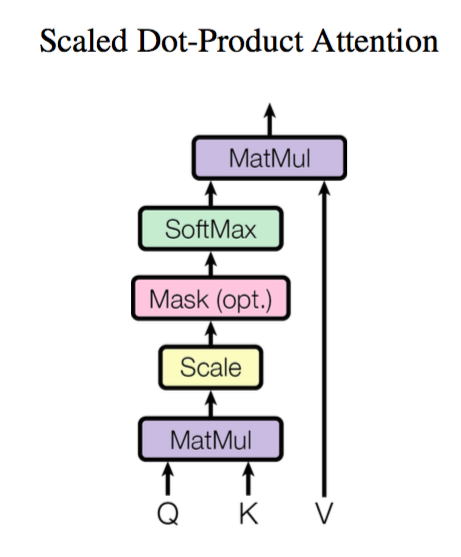
- 计算公式为:
Attention(Q,K,V)=softmax(dk
QK⊤)V,其中因子
dk
起到调节作用,使得内积不至于过大。自注意力机制计算结果是将Q这一个
n×dk的索引矩阵转换为一个
n×dv矩阵,即将
n×dk的序列Q编码成了一个新的
n×dv的序列。
multi-head attention多头注意力机制
- 其实这里的multi-head指的是做h次不共享、不重复的self-attention,最后拼接起来,得到一个KaTeX parse error: Undefined control sequence: \d at position 19: …times h \times \̲d̲_v的序列。
- 多头注意力机制如图所示:

- 具体来说就是:
headi=Attention(QWiQ,KWiK,VWiV),然后
MultiHead(Q,K,V)=Concat(head1,...,headh)
position encoding位置编码
- 因为attention机制实际上是计算一个索引到key-value值的加权权重,所以在这里位置信息并没有体现到,无法捕捉到位置信息。只有RNN序列模型才能够在计算时考虑到序列的前后顺序对当前embedding表示的影响。
- 所以在这里,一个额外的position encoding位置编码就显得格外重要。将每个位置编号,然后每个编号对应一个向量,通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了。
- 这篇文章中谷歌的具体做法是直接使用公式计算,论文中提到他们比较过直接训练出来的位置向量和上述公式计算出来的位置向量,效果是接近的。因此显然我们更乐意使用公式构造的Position Embedding了。
- 计算公式是:
⎩⎪⎨⎪⎧PE2i(p)=sin(p/100002i/dpos)PE2i+1(p)=cos(p/100002i/dpos),这里的意思是将id为
p的位置映射为一个
dpos维的位置向量,这个向量的第
i个元素的数值就是
PEi(p)。
encoder-decoder架构
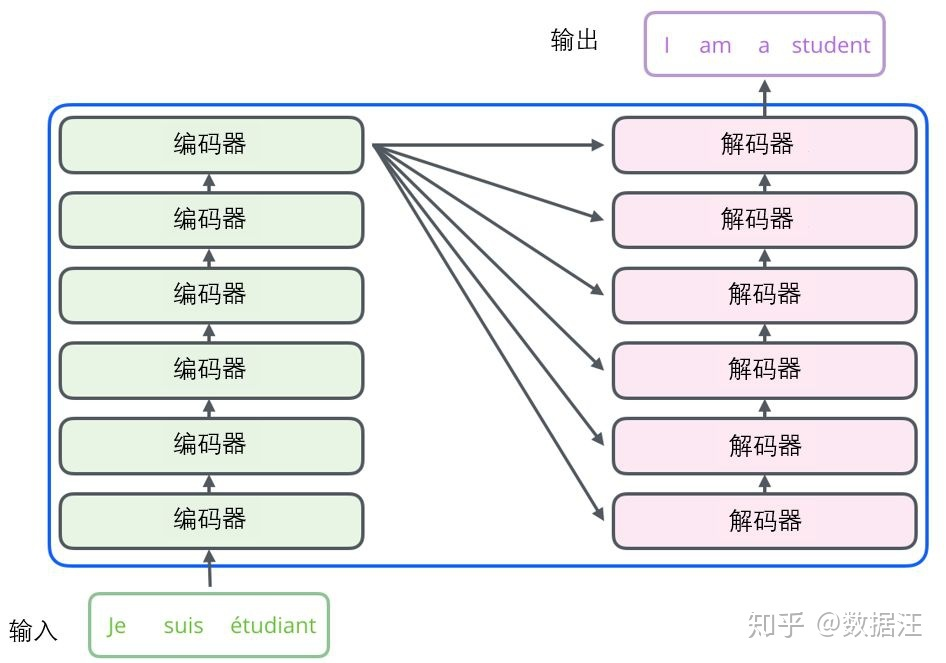
- Transformer原文中提出就是用于机器翻译任务,所以采用的架构也是类似seq2seq的encoder-decoder流水线编码-解码架构,不同的地方就在于这里encoder和decoder都是用attention机制来计算。
- 具体的架构如下图:
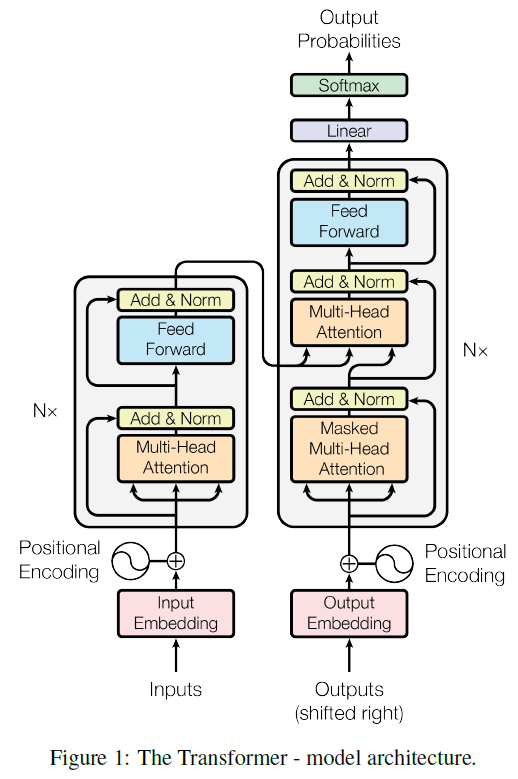
- 文中参数N取值为6,即使用了N个层叠的编码器和解码器。
- 编码器中可分为两部分,第一部分是多头自注意力机制,第二部分是一个position-wise前传神经网络。这里都使用到了残差连接。
- 要注意到解码器中是三部分组成,第一部分是解码器的自注意力计算;第二部分是编码器到解码器的注意力计算,即Q、K、V中Q为编码器输出,K和V仍为解码器输入;第三部分也是前传神经网络。示意图如下:
- 解码器中的第一部分自注意力机制带有一个masked,会遮挡掉当前位置后面的向量表示。因为在前向推理中,我们仅仅只是根据之前输出的值来计算注意力。
模型细节
- 计算自注意力的第一步就是从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量、一个键向量和一个值向量。这三个向量是通过词嵌入与三个权重矩阵后相乘创建的。
- 在解码器中的编码-解码注意力计算部分,Q为解码器上一步的输出,K和V为解码器的输出。
参考资料
转载自blog.csdn.net/HOMEGREAT/article/details/102504367
