昇腾(Ascend)CANN(Compute Architecture for Neural Networks)是华为推出的一款面向AI处理器的软件开发工具包,用于支持各种AI应用的开发和部署。它的深度神经网络应用开发流程可以分为以下几个主要步骤
AscendCL应用开发,深度学习网络推理应用开发流程主要步骤如下:
- 准备模型:首先,使用 TensorFlow、PyTorch、Caffe等主流深度学习框架训练一个深度神经网络模型。完成训练后,将模型导出为相应的格式,如 TensorFlow 的 *.pb文件,PyTorch 的 *.pth 文件,Caffe 的 *.prototxt 和 *.caffemodel 文件。
- 模型转换:使用昇腾CANN中的ATC(AI Tensor Compiler)工具将训练好的模型转换为昇腾处理器可以识别和执行的离线模型(OM文件)。在这个过程中,可能需要对模型进行优化和量化,以提高在昇腾处理器上的执行效率。
- 开发应用程序:根据实际应用需求,使用昇腾提供的软件组件(如 AscendCL、AICPU等)和APIs开发深度神经网络应用程序。这可能包括输入数据预处理、模型加载、模型输入输出,推理执行、输出数据后处理等操作,其流程如下图所示。
- 编译和部署:将开发好的应用程序编译成可执行文件,并将它与转换后的离线模型(OM文件)一起部署到昇腾AI处理器设备上。昇腾处理器设备可以是云端服务器、边缘设备等。
- 执行和优化:在昇腾AI处理器上运行部署好的深度神经网络应用程序。在执行过程中,可以通过分析和调试工具找出性能瓶颈并进行相应的优化,以进一步提高应用程序的性能和效率。
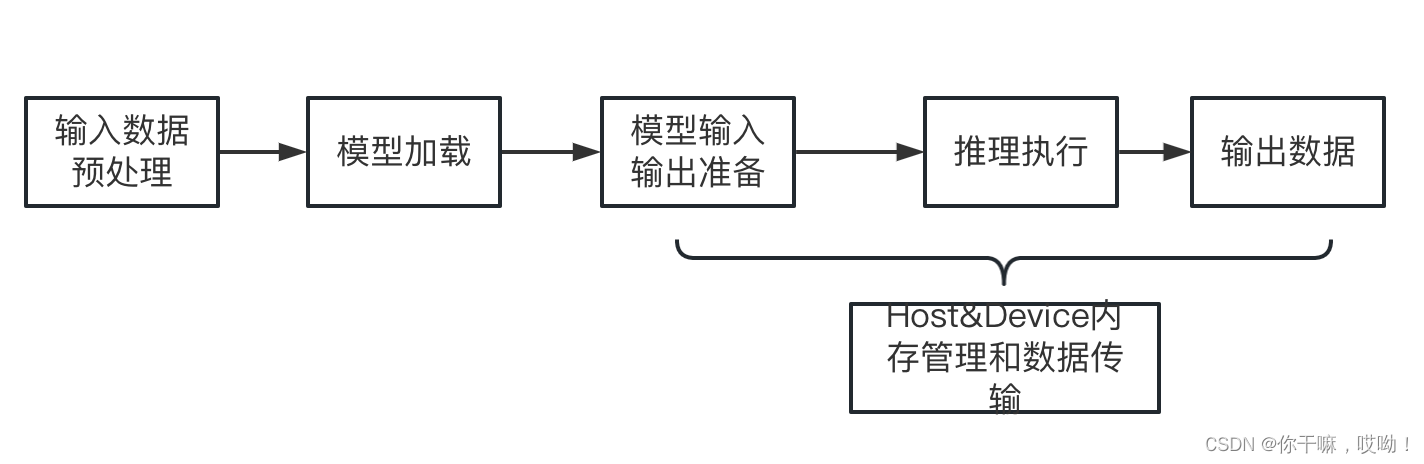
通过以上五个步骤,用户可以使用昇腾CANN工具包开发、部署并优化针对昇腾AI处理器的深度神经网络应用程序
文本主要讲解ATC和开发应用程序的部分内容
2023 · CANN训练营第一季:AscendCL应用开发深入讲解学习笔记
模型转换(ATC)
ATC(AI Tensor Compiler)是昇腾CANN工具包中的一个重要组件,主要用于将来自不同深度学习框架的模型转换成昇腾AI处理器能够识别和执行的离线模型(OM文件)。
ATC的主要功能和特点如下:
- 支持多种深度学习框架:ATC 支持将 TensorFlow、PyTorch、Caffe、ONNX等主流深度学习框架的模型转换为昇腾处理器可以执行的模型。
- 模型优化:在模型转换过程中,ATC 能够对模型进行优化,提高模型在昇腾AI处理器上的执行效率。优化手段包括操作融合、算子优化等。
- 量化支持:ATC 支持将浮点模型转换为低精度的定点模型(如int8),以降低模型体积和计算资源需求,同时在保持较高推理精度的前提下,提升模型在昇腾AI处理器上的运行速度。
- 离线模型生成:经过ATC转换后,用户将获得一个适用于昇腾AI处理器的离线模型(OM文件)。这个模型可以直接部署到 Ascend
系列设备上进行推理计算。
要使用ATC进行模型转换,用户需要根据源模型的深度学习框架和转换需求选择适当的转换参数。转换完成后,用户可以使用昇腾提供的其他软件组件(如 AscendCL、AICPU 等)在 Ascend AI处理器上运行和部署离线模型,ATC工具功能架构图如下:
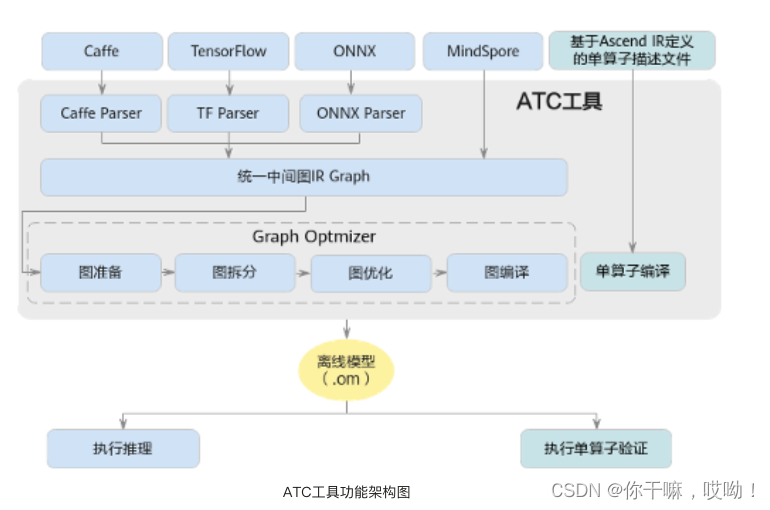
在上图中,开源框架网络模型经过Parser解析转换为中间态IR Graph,中间态IR经过图准备,图拆分,图优化,图编译等一系列操作后,转成适配昇腾AI处理器离线模型,用户可通过AscendCL接口加载模型件实现推理
ATC转换流程
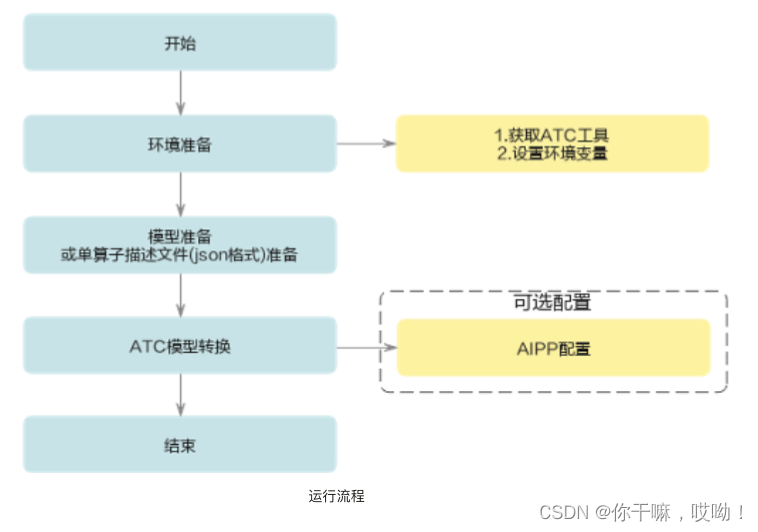
ATC的流程可以概括为以下几个步骤:
- 环境准备:获取ATC工具,设置环境变量
- 准备源模型:首先,使用 TensorFlow、PyTorch、Caffe等主流深度学习框架训练一个深度神经网络模型。完成训练后,将模型导出为相应的格式,如 TensorFlow 的 *.pb文件,PyTorch 的 *.onnx 文件,Caffe 的 *.prototxt 和 *.caffemodel 文件。
- 安装ATC工具:确保已经安装了昇腾CANN工具包,其中包括ATC工具。通常,CANN工具包安装完成后,ATC工具会自动安装在相应的路径中。
- 配置转换参数:为了使用ATC工具进行模型转换,需要为源模型设置一些转换参数,如输入和输出节点、数据类型、优化选项等。这些参数取决于源模型的深度学习框架、网络结构和转换需求。
- 执行模型转换:运行ATC命令并提供正确的转换参数,以启动模型转换过程。在转换过程中,ATC会将源模型转换为适用于昇腾AI处理器的离线模型(OM文件),同时进行模型优化和量化(如果需要)。
- 验证转换结果:转换完成后,使用转换后的离线模型(OM文件)进行推理测试,以确保模型转换正确且性能满足预期。在必要时,可以对转换参数进行调整并重新执行模型转换,以获得最佳的推理性能。通过以上五个步骤,用户可以使用ATC工具将各种深度学习框架的模型转换为昇腾AI处理器上可执行的离线模型(OM文件)。
开发应用程序
数据预处理
受网络结构和训练方式等因素的影响,绝大数神经网络模型对输入数据都有数据都有格式上的限制,在计算机视觉领域,这个限制大多体现在图像的尺寸、色域、归一化参数等,如果源图或视频的尺寸、格式等与网络模型的要求不一致时,我们需要将源图或视频处理成符合模型要求的图或视频。
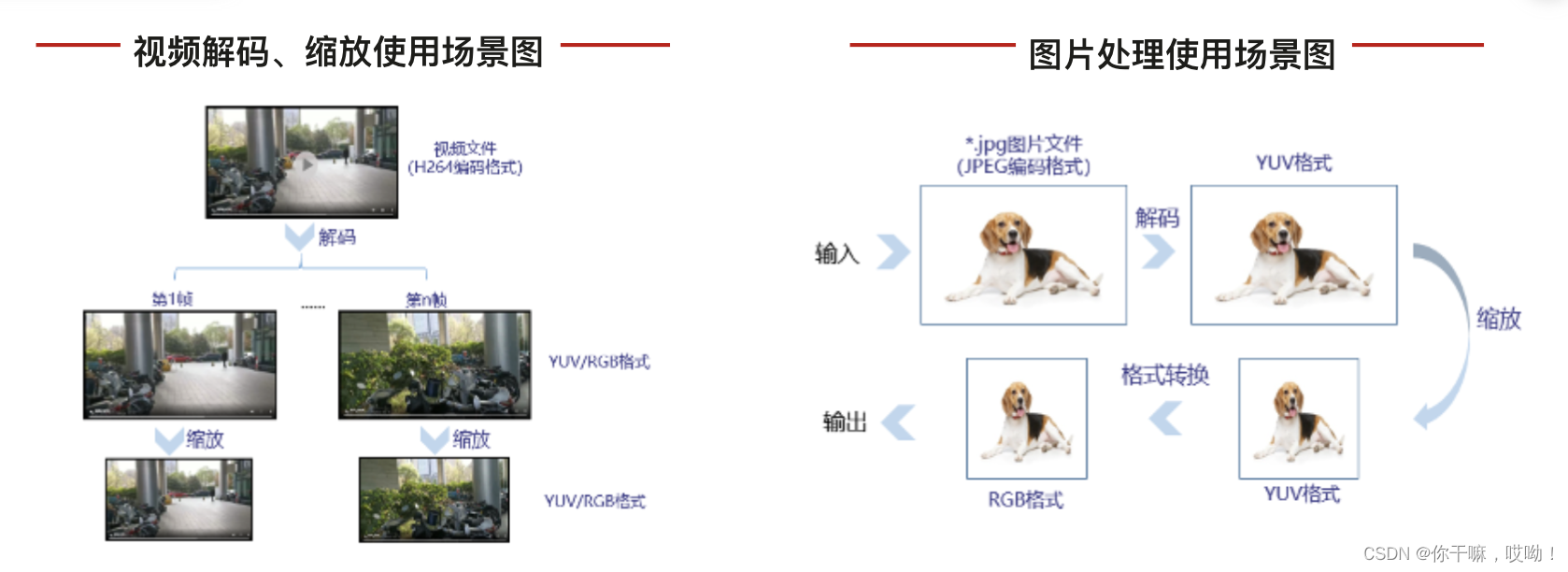
CANN提供了两套用于数据预处理的方式:AIPP和DVPP,下面是一个表格,描述了AscendCL数据预处理方式AIPP和推理DVPP的主要特点和差异:
| 预处理方式 | AIPP | DVPP |
|---|---|---|
| 目的 | AI模型推理前的图像预处理 | 视频处理中的图像预处理 |
| 处理对象 | 静态图像 | 动态视频序列 |
| 设备 | 昇腾AI处理器(Ascend) | 昇腾AI处理器(Ascend) |
| 功能 | 色域转换 | 色域转换 |
| 图像裁剪 | 图像裁剪 | |
| 数据格式转换(如FP32到FP16 | 数据格式转换(如FP32到FP16 | |
| 通道重排 | 通道重排 | |
| 应用场景 | AI模型推理 | 视频处理(如视频解码、编码等) |
DVPP可以分开独立使用,也可以组合使用,组合场景下, 一般先使用DVPP对图片/视频进行解码、抠图、缩放等基础处理,但由于 DVPP硬件上约束,DVPP处理后的图片格式、分辨率有可能不满足模型的要求,因此还需要再经过AIPP进一步做色域转换、抠图、填充等处理
下面举例一个场景:输入一张JPEG图片文件(源图格式为YUV420),经过JEPGD+VPC后,输出一张YUV420SP格式图片,再通过AIPP将图片格式转为RGB,同时进行归一化配置,最后将图片送给模型进行推理
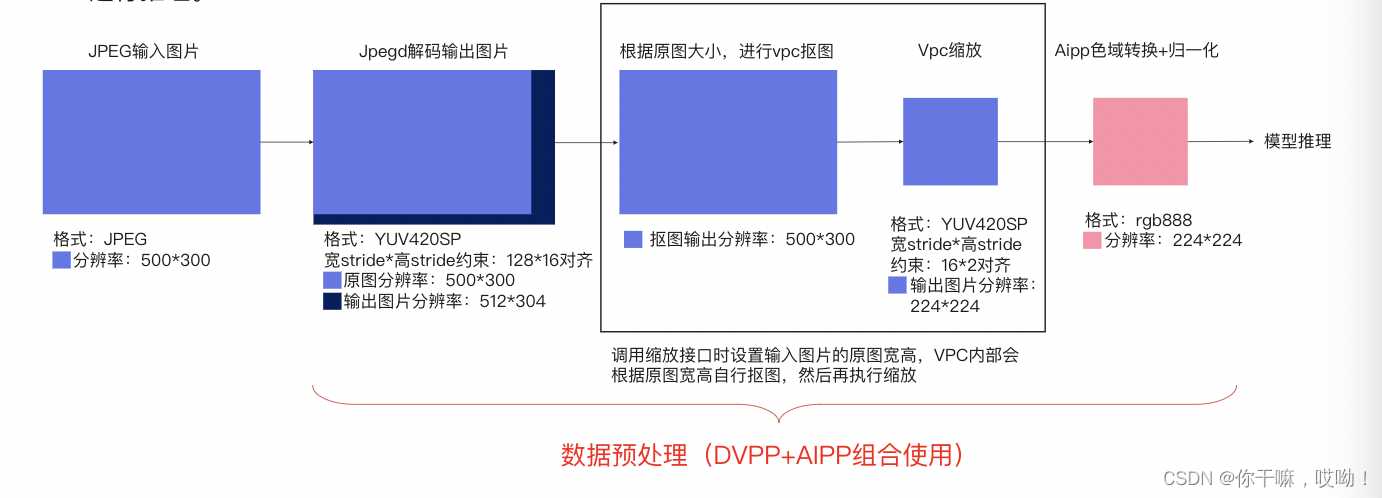
DVPP关键功能
DVPP(Digital Video Processing Platform)在昇腾AI处理器中负责数字视频处理。其主要功能模块包括解码与编码、图像处理等。这里,我们将详细介绍 JPEGD 图片解码、VPC 视觉预处理以及 JPEGD+VPC 模块的功能。
1.JPEGD 图片解码
JPEGD(JPEG Decoder)是 DVPP 中负责 JPEG 图像解码的功能模块。JPEGD 可以将 JPEG 编码的图像数据解码为其他像素格式,例如 YUV420SP、YUV422SP 和 RGB 等。JPEG 图片解码在许多 AI 应用中都很常见,因为图像数据通常以 JPEG 格式存储和传输,而 AI 模型则需要其他像素格式的数据。
2.VPC 视觉预处理
VPC(Visual Processing Component)是 DVPP 中负责视觉预处理的功能模块。VPC 提供了一系列图像处理功能,包括:色域转换:将图像从一种色域转换为另一种色域,例如从 YUV 到 RGB。图像缩放:改变图像尺寸,可以实现图像的放大或缩小。图像裁剪:从原始图像中截取一个特定区域,以满足特定的尺寸或比例要求。通道重排:对图像通道进行重新排序,以满足模型输入的通道顺序要求。
VPC 对于视频处理和 AI 应用的前处理非常重要,因为它们需要对原始图像数据进行预处理,以适应后续处理和分析的需求。
3.JPEGD+VPC 模块
JPEGD+VPC 模块是将 JPEGD 图片解码和 VPC 视觉预处理功能结合起来的一个组合模块。使用这个模块,开发者可以方便地将 JPEG 编码的图像数据解码为其他像素格式,并在解码过程中直接应用 VPC 提供的图像处理功能。这种集成方式有助于简化数据预处理流程,并提高处理效率。
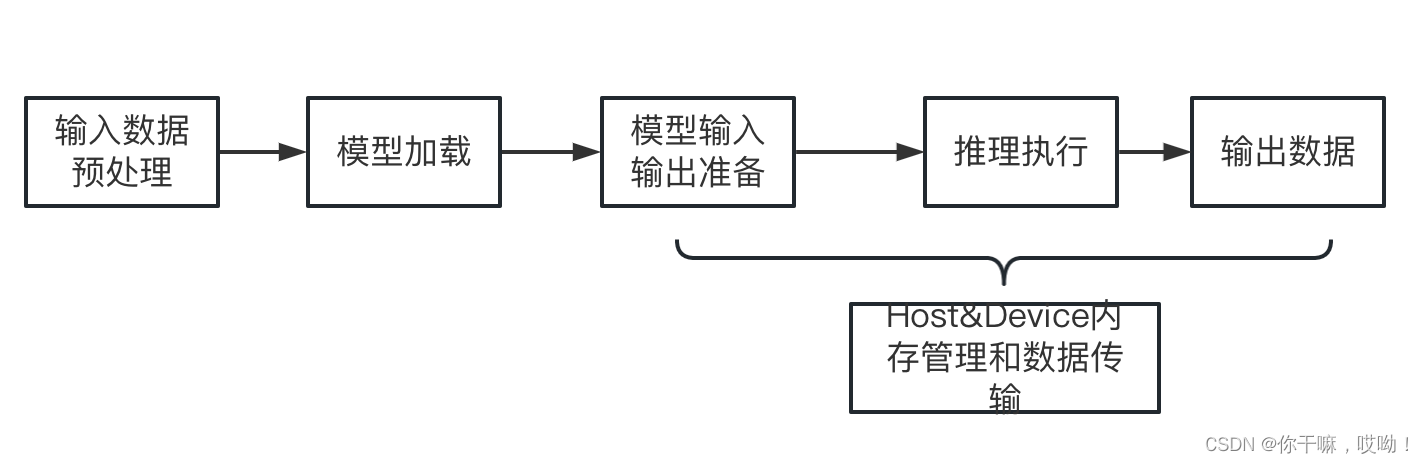
Host&Device内存管理和数据传输
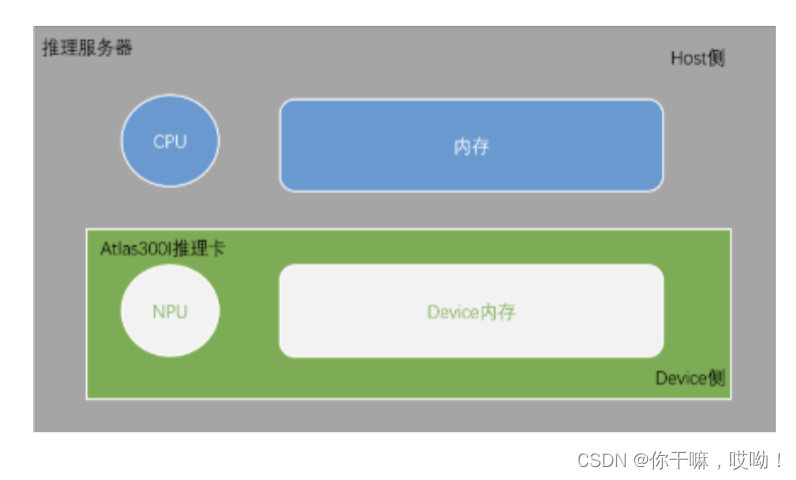
在AscendCL中,Host(即内存和CPU)和Device(即Ascend AI处理器(NPU和Device内存))之间需要进行内存管理和数据传输以便在推理任务中共同工作。
在应用开发代码中加载输入数据时,需要申请Host内存进行存储,当输入数据处理完毕后,,需要将处理完成的数据从Host内存拷贝到Device的模型输入内存中,以便Device进行模型推理的专用计算。
以下是实现内存管理和数据传输的主要方法:
内存管理
Host端内存申请与释放:
使用aclrtMallocHost和aclrtFreeHost进行Host端内存的申请和释放。它们用于在Host端分配一段可用的内存区域,以便存储需要在Host和Device之间传输的数据
void* hostBuffer;
size_t bufferSize = ...; // 分配所需内存大小
aclError ret = aclrtMallocHost(&hostBuffer, bufferSize);
// 使用 hostBuffer 进行一些操作,如数据加载等
...
aclrtFreeHost(hostBuffer); // 在不再需要时释放分配的内存
Device端内存管理:
使用aclrtMalloc和aclrtFree进行Device端内存的分配和释放。它们用于在Device端分配一段可用的内存区域,以便存储需要在Host和Device之间传输的数据。
void* deviceBuffer;
size_t bufferSize = ...; // 分配所需内存大小
aclError ret = aclrtMalloc(&deviceBuffer, bufferSize);
// 使用 deviceBuffer 进行一些操作,如数据传输、模型推理等
...
aclrtFree(deviceBuffer); // 在不再需要时释放分配的内存
数据传输
数据传输是指在Host和Device之间传输数据,通常用于将输入数据传输到Device端以进行模型推理,然后将推理结果传输回Host端。
Host到Device的数据传输
使用aclrtMemcpy函数将数据从Host端内存复制到Device端内存。这个函数需要指定源地址、目标地址以及要复制的数据大小。
aclError ret = aclrtMemcpy(deviceBuffer, bufferSize, hostBuffer, bufferSize, ACL_MEMCPY_HOST_TO_DEVICE);
Device到Host的数据传输
使用aclrtMemcpy函数将数据从Device端内存复制到Host端内存。这个函数需要指定源地址、目标地址以及要复制的数据大小。
aclError ret = aclrtMemcpy(hostBuffer, bufferSize, deviceBuffer, bufferSize, ACL_MEMCPY_DEVICE_TO_HOST);
通过上述内存管理和数据传输方法,AscendCL能够实现Host和Device之间的数据交互和协作,从而完成AI应用的推理任务。