重要的事情说三遍
距离报名截止只剩半个月!
距离报名截止只剩半个月!
距离报名截止只剩半个月!

大赛官网报名链接:https://sourl.cn/G5RJKD
【最强福利,赛题干货直播分享】
9月14日-16日,连续3天,每天2位专家线上直播,详解赛题内容,不可错过的干货知识。
直播链接:https://live.bilibili.com/25865198



1 擂台制赛题解读(500G+学术数据集开放下载)
- 擂台制赛道·超高学术含金量 -
由大赛组织方邀请领域内的顶尖专家教授作为赛题定义者,根据学术领域的研究与认知,设计具有科学性和前瞻性的赛题,瞄准解决国家重大需求的基础算法。
赛题1.古籍文档图像分析与识别
赛题说明:为解决我国海量古籍数字化难题,赛题旨在征集先进的人工智能算法,解决高精度古籍文字检测、文本行识别、端到端古籍识别技术难题,推动古籍OCR技术进步,为古籍数字化保护、整理和利用提供人工智能支撑方法,特此举办本次比赛。
古籍图像OCR数据集
训练集、验证集与测试集各包括1000幅古籍文档图像(共3000张图像),数据选自四库全书、历代古籍善本、乾隆大藏经等多种古籍数据。

赛题2.预训练语言模型应用调优算法:
赛题说明:近年来,预训练语言模型极大地推动了自然语言处理领域的发展。基于预训练语言模型,仅通过少量标注样本即可在诸多下游任务上取得不错的性能。然而,出于运行成本和商业盈利考虑,许多大规模语言模型的参数并不公开,而是通过开放模型推理API的形式向用户提供服务。如何仅通过调用语言模型推理API来完成常见的自然语言处理任务成为一个重要的研究方向。赛题聚焦大规模预训练语言模型的调优,要求参赛队伍仅在调用预训练语言模型推理能力的前提下,针对6个自然语言理解相关的小样本学习任务进行模型调优。
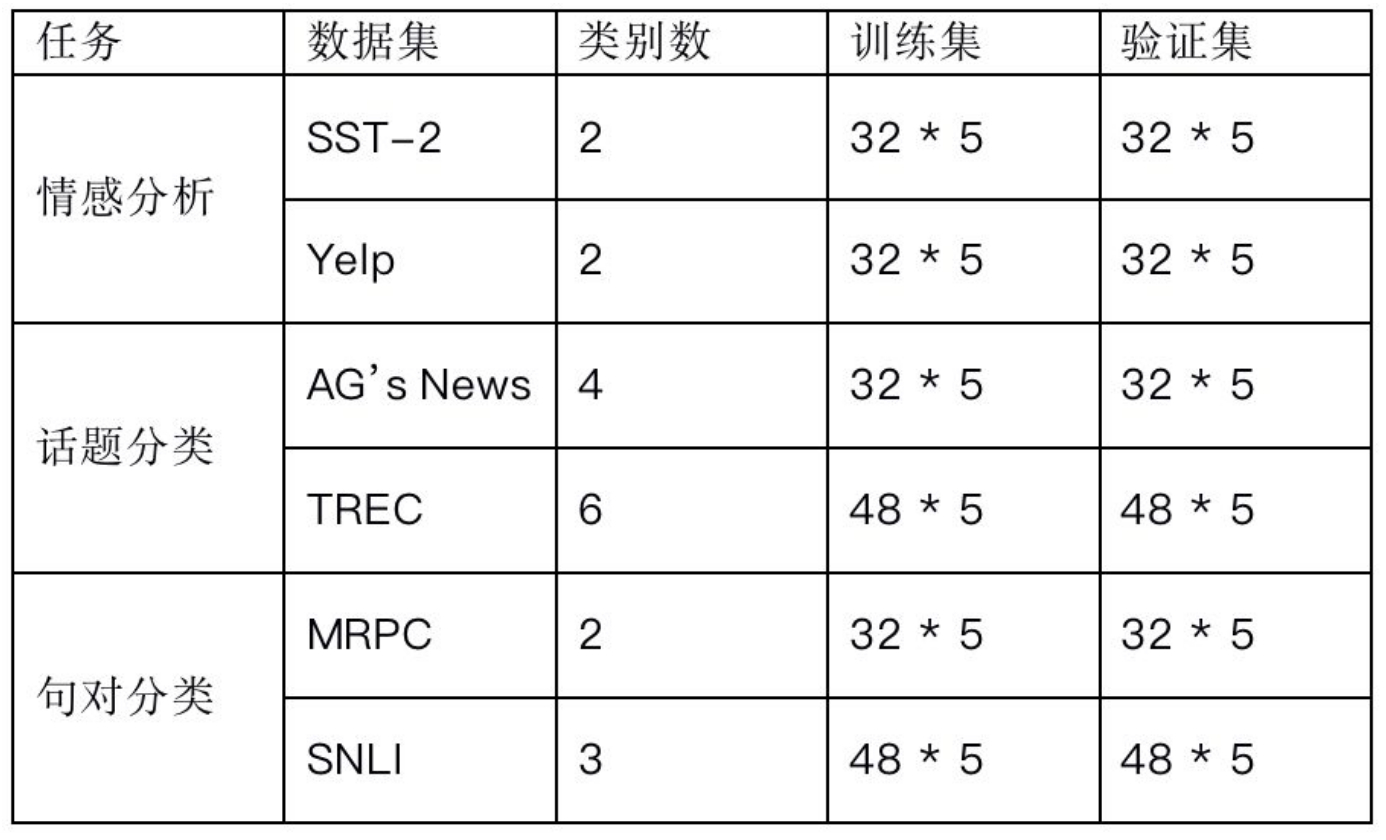
语言分类数据集
SST-2是一个带有情感标注的电影评论数据集,Yelp情感分析数据集基于Yelp网站上的评论构建,AG’s News话题分类数据集中包括从超过两千个新闻源中收集的大量新闻语料,TREC是一个问题分类数据集, MRPC是一个句对分类数据集,SNLI是一个自然语言推理数据集。
赛题3.数据选择与标记校正算法设计:
赛题说明:深度神经网络很容易过拟合到训练数据集中的噪音标记,从而导致其在测试数据集中表现不佳。这一问题限制了深度神经网络在更多真实问题中的表现。为了能够让深度学习技术在更多真实应用场景落地,研究发展新的分类算法,使得在具有标记噪音的训练数据集上训练获得的深度神经网络,能够在测试数据集具有良好性能,是后深度学习时代研究中的一个非常重要而基础的科学问题。
本擂台赛结合噪音标记的特点,发展高效、格式简洁、对噪音标记问题普适的分类算法。
CIFAR-10、CIFAR-100 微型图像分类数据集
本任务采用的基准数据集是CIFAR-10、CIFAR-100、Tiny ImageNet、Twitter、SST,包括更多仿真和真实噪音标签数据集实验任务,具体的任务形式和数据会在决赛公开。
赛题4.近似低秩矩阵的奇异值分解与求逆:
赛题说明:矩阵计算是信息处理最基础的计算任务,也是共认大数据计算的“七大巨人问题”之一。开展针对近似低秩矩阵的奇异值分解(SVD)与求逆算法的研究,对信息处理、大数据基础理论的发展有重要贡献,可推动相关核心技术的革新。
本赛题聚焦一类有特别重要意义的近似低秩矩阵奇异值分解与求逆问题。对于给定的矩阵以及该矩阵非零最大奇异值个数所占比例的条件约束,本赛题要求参赛队开发快速高效的矩阵奇异值分解与求逆算法。
近似低秩矩阵奇异值数据集
矩阵计算是信息处理最基础的计算任务,也是大数据计算公认的“七大巨人问题”之一。矩阵基础计算理论的每一次进步,都会对大数据分析、信息与通信等相关产业产生广泛的影响,引发一系列的技术变革,大幅促进生产力的发展。
赛题5.深度学习模型的对抗鲁棒防御算法:
赛题说明:当前广泛使用的深度学习模型在一些数据的自然变化的条件存在模型脆弱性的不足,受到人眼不可见的对抗样本欺骗,导致模型判断失准。为了提升深度学习模型的鲁棒性,发展安全可靠的新一代深度学习。本擂台赛面向图像分类任务,旨在发掘更加高效的对抗防御技术,提升计算机视觉模型在对抗攻击下的鲁棒性。
ImageNet计算机视觉数据集:
比赛所采用ImageNet数据集是计算机视觉系统识别任务所采用的经典数据集,由斯坦福大学的李飞飞教授带领创建。本比赛推荐使用数据集为ImageNet的分类任务的子集,是每年举办的ILSVRC图像识别大赛所采用的标准训练、测试数据。ImageNet数据集和ILSVRC竞赛对计算机视觉技术以及深度学习模型的发展具有重要意义,本大赛期望在经典的图像分类任务上进一步探究深度学习模型在大型数据集上的鲁棒性。

2 1000万奖池、吸纳人才
大赛设立重磅奖金,吸引全球人工智能人才及团队,形成一批具有国际竞争力的人工智能创新型产业集群。大赛将设立总奖池1000万,每个赛题高达100万奖金激励,或成为史前最高奖金金额的算法大赛。

3 参赛须知
1.大赛报名时间:8月6日-10月7日
大赛比赛时间:8月6日-11月15日
2.大赛面向全社会开放,个人、高等院校、科研单位、企业、创客团队等人员均可报名参赛;每位选手仅能加入一支参赛队伍,每只队伍组队上限5人。
注:
(1)大赛组织机构单位中除了擂台赛,涉及题目编写、数据接触的人员禁止参赛;
(2)主办方和竞赛制赛道出题方可参赛,不参与排名。
- 扫描大赛官方二维码或登录琶洲实验室(黄埔)官方活动页面:https://sourl.cn/G5RJKD
在竞赛选题中点击对应赛题的“立即报名”按钮,完成报名信息,即可报名参赛。
注:确保报名信息、组队信息准确有效,如查出小号、冒名等情况将被取消参赛资格、成绩及奖金等。
4 大赛组织结构
指导单位:鹏城实验室;广州市科学技术局;广州市工业和信息化局
支持单位:广州市黄埔区人民政府;广州开发区管理委员会;广州高新区管理委员会
主办单位:琶洲实验室(黄埔)
协办单位:中国工业与应用数学学会(大数据与人工智能专业委员会);中国计算机学会;中国指挥与控制学会;中国人工智能学会;工业和信息化部电子第五研究所;西安电子科技大学广州研究院