初次接触学习崔大神的python爬虫时候,其中利用requests.get进行网页抓取时候涉及UA(浏览器标识信息)问题。开始没有看明白,大神也只是简单提示爬虫的时候必须添加,其他息没有提示。最后自己给也给忽视了。
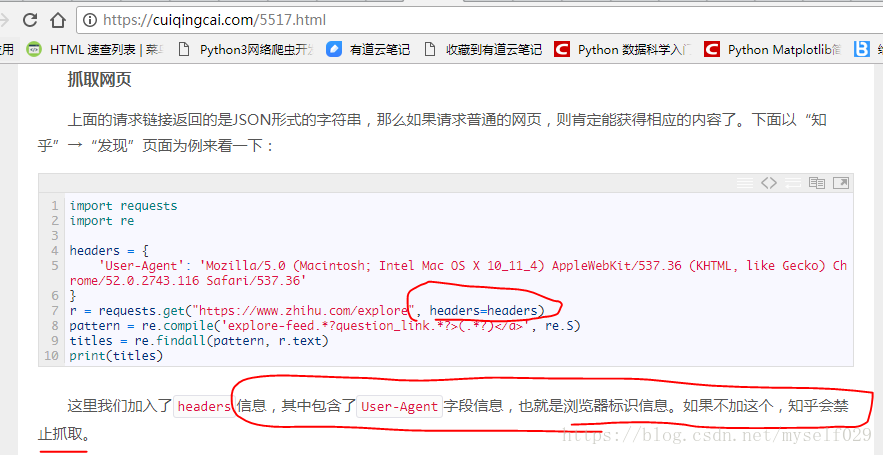
今天学习别人的爬虫代码,又碰到了上面类似的 UA 代码,不理解。所以百度了下,下面分享下,供IT小白同道人参考。
1.什么是UA
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
具体可以快速了解下百度百科吧。点击打开链接
2.爬虫时候提供UA的作用(百度转载别人的。。。)
- 通过这个标识,用户所访问的网站可以显示不同的排版,从而为用户提供更好的体验或者进行信息统计。例如,百度、新浪等网站用手机访问和电脑访问是不一样的,这是因为网站根据访问者的UA判断后,进行了不同的设置和处理。
- 使用User-Agent伪造浏览器,谎称身份欺骗服务器IE,FireFox,Opera,Maxthon,Chrome,Safari,iPhone,ipad..qq空间说说,微薄转发,有个通过ipad发布。。通过iphone..就是读取User-Agent,当然这个可以伪装的
- 用于seo,有一种SEO的技术,就是判断 user-agent,如果是搜索引擎的爬虫,就把内容显示出来,否则的话,只显示给付费用户。所以有的网站能够被Google搜索到,点击链接进去以后 却显示“未注册”、“还不是会员”。通过伪装user-agent可以达到相应的目的。。
3.如何自己获取自己浏览器的UA
扫描二维码关注公众号,回复:
151074 查看本文章

- 1.地址栏中输入:about:version(推荐方法,亲测可用)
- 2. 地址栏中输入:javascript:alert(navigator.userAgent) (没成功。。。可能网络连接问题
- 3. 另附两个在线获取的网站:(亲测可用)
http://www.useragentstring.com/
http://tools.jb51.net/table/useragent