目录
7.拷贝构造函数(等同于C语言中的int a=2;int b=a;)
一、初识C++
1.C++与C的区别
(1)具备严格的数据类型检查
例如:
C: 数据类型检查不严格
const int a=50;
a=60; //报错
int *p;
p=&a
*p=40; //成功C++:具备严格的数据类型检查
const int a=50;
a=60; //报错
int *p;
p=&a
*p=40; //报错(2)新增了变量权限
C语言:
作用域可以看成变量的权限
C++:
作用域、public、private、protected
(3)新增里命名空间或名字空间
向内存里的一块空间命一个名称
(4)新增面向对象
类和对象、继承&多继承、多态、联编等等
(5)新增了泛型编程
泛型:数据的类型是广泛的或不定的
(6)新增变量引用:&
变量引用:
为已经存在的变量取一个别名
格式:
数据类型 & 别名 = 已经存在的变量例如:
int a =10;
int & num = a ; #相当于给变量a取一个别名为num注意:
a、引用一旦存在就必须进行初始化工作
b、别名的数据类型要与已经存在的变量的数据类型一致
c、已经存在的变量的别名可以有多个,但是一个别名只能对应一个已经存在的变量
面试题分享:指针和引用的区别?
- 引用必须被初始化,但是不分配存储空间。指针不声明时初始化,在初始化的时候需要分配存储空间。
- 引用初始化后不能被改变,指针可以改变所指的对象。
- 不存在指向空值的引用,但是存在指向空值的指针。
2、C++特性及专业术语
(1)类:class
类是指一类事物的统称,是泛指现实世界中的一些事物,人类-----特征:头发、手、脚、肤色、身高;行为:吃饭、走路、打球等等,类具备了行为和特征
(2)对象
对象是对类的实例化,是特指现实世界中一些事物,人类----实例化---张三(张三具备人类的一些特征和行为)
(3)继承
继承是指一个类继承另一个类的特征或行为
(4)特征&属性
特征在程序是指变量
(5)行为&方法
行为在程序里是指函数
(6)多态
多种形态,程序里一般是指“一种接口,多种实现方式”
(7)静态联编(静态绑定)
一个表达式或者一个函数的地址在编译时就已经确定
(8)动态联编(动态绑定)
一个表达式或者一个函数的地址在运行时才确定
3、C++程序编译过程
C++的程序编译是跟C一样
(1)预处理
a、将除源文件以外的内容全部加入到源文件中
b、宏替换工作
c、条件编译(#ifndef #define #endif)
d、删除掉注释
(2)编译
a、将用户编写的源代码翻译成汇编语言
b、检查用户编写的代码是否符合C/C++语法规范
(3)汇编
将汇编语言翻译成机器语言
(4)链接
生成可执行文件
4、第一个C++代码
//第一个C++程序
#include<iostream>
using namespace std; //表示使用命名空间std里的内容,该空间里有cout、endl、cerr、clog、cin等等
int mian()
{
//"<<"和“>>”符号表示数据流向,
// “<<”表示数据从内存里流出,一般流出到控制台或显示器,一般和cout结合;
// “>>”表示数据从控制台或显示器流入到内存,一般和cin结合使用
cout << "hello world"<<endl ; //“hello world”表示输出到控制台或显示器的数据
return 0; //return函数的返回值
}注:
#include "iostream" //#include 宏,<iostream>,将iostream文件里的内容加入到本文件中
iostream后面是没有.h
如果<>里面的文件没有加.h的话,那就说明该文件是属于C++标准库里的文件
如果<>里面的文件加了.h的话,那就说明该文件是用户自己创建的头文件
"" :程序执行的时候是首先去当前工程路径下去寻找该文件,然后再去标准库里去寻找该文件
<> :程序执行的时候会首先去标准库里去寻找<>里的文件,然后再去当前工程路径去寻找该文件
二、内存模型与名字空间
1.名字空间或命名空间
如果程序中有两个相同的变量,例如:int a=10; int a=20; 编译器执行时,到底是执行的等于10的a还是等于20的a 。C++提出了命名空间或名字空间解决标识符重名的问题。
如何解决:在全局范围内,定义两个命名空间,将重名的标识符分别放到不同的命名空间里(注:每一个.cpp文件都是一个无名的名字空间)
(1)有命名空间的声明格式 :命名空间是属于全局范围的一部分
关键字:namespace
格式:
namespace 标识符
{
变量;
函数;
类;
.....
} ;例如:
namespace zhang
{
int a=10;
int c=20;
};(2)无名的命名空间声明格式
关键字:namespace
格式:
namespace
{
变量;
函数;
类;
.....
};例如:
namespace
{
int a=10;
int c=20;
};(3)嵌套的命名空间
关键字:namespace
格式:
namespace zhang
{
int a=10;
namespace yong
{
int a=50;
......
}
}2.命名空间的访问
(1)命名空间直接访问
a.有名的命名空间
符号:::
格式:
命名空间名称 :: 命名空间里的内容
例如:
namespace yong
{
int a = 50;
};
访问:
yong :: ab.无名的命名空间
符号:::
格式:
::无名的命名空间里的内容
例如:
namespace
{
int a = 50;
};
访问:
:: a(2)使用关键字using访问命名空间里的内容
格式:
using 命名空间名称 ::命名空间里的内容
例如:
namespace yong
{
int a = 50;
};
using yong :: a; //(注:告诉当前表达式后面使用的a是属于命名空间yong里的a)
cout << "a="<< a<<endl; //表示使用的a是属于命名空间yong里的a(3)使用关键字using和namespace结合来访问命名空间里的内容
格式:
using namespace 命名空间名称
例如:
namespace yong
{
int a = 50;
int b=60;
};
using namespace yong ; //(注:告诉当前表达式后面使用a或者是b就表示使用的是命名空间里的a或b)
cout<<"a="<<a<<endl;
cout<<"b="<<b<<endl;(4)嵌套的命名空间的访问
例如:
namespace zhang
{
int a =10;
namespace yong
{
int a=20;
}
}格式:
命名空间名称1 ::命名空间名称2::....::访问的内容
例如:
zhang :: yong ::a ;
实现代码:
//关于研究命名空间的问题
#include<iostream>
using namespace std;
namespace zhang
{
int a = 10;
}
namespace wu
{
int a = 20;
int b = 21;
}
namespace
{
int a = 5;
}
namespace zhou
{
int a = 10;
namespace zhu
{
int a = 11;
}
}
int main()
{
//1.直接访问
cout << "a=" << wu::a << endl;//有名命名空间访问
cout << "a=" << a << endl;//无名命名空间访问
cout << "a=" << ::a << endl;//无名命名空间访问
//2.关键字using访问
using wu::a;
cout << "a=" << a << endl;
//3.using和namespace结合
using namespace wu;//使用的都是wu里面的a,b
cout << "a=" << a << endl;
cout << "b=" << b << endl;
//4.嵌套问题的访问 zhou::zhu::a
cout << "a=" << zhou::zhu::a << endl;
return 0;
}三、动态内存与作用域
1.动态内存
动态内存是 指程序在运行的时候才去向内存里申请的内存空间,称为“动态内存”,类似于C语言的malloc/free,C++提供了new来申请动态内存空间,使用delete来释放new申请的动态内存空间,注:malloc和new都是在堆内存里申请空间
(1)new操作符
new跟C语言里的malloc一样,都是用于向堆区申请内存空间
格式:
数据类型 * 标识符=new 数据类型;
或数据类型 * 标识符;标识符=new 数据类型;
向堆区申请一块内存空间,并用标识符指向该内存空间
例如:
int * p=new int;
或 int *p;p=new int;
表示在堆区开辟一个int类型大小的空间,并用变量p指向该空间,后期就可以使用p来操作内存空间
(2)new开辟变量地址空间的同时赋初值
格式:
数据类型 * 标志符=new 数据类型(初始值)
向堆区申请一块内存空间,并用标识符指向该内存空间,开辟的空间大小就是数据类型的大小,并且在这个内存空间里存放了一个初始值
例如:
int * p=new int(50);
表示在堆区开辟一个int类型大小的空间,并用P指向该空间,该空间存放了初始值50
(3)new开辟数组地址空间
格式:
数据类型 *标识符=new 数据类型[数组的大小]
表示为向堆区申请一块内存空间,并用标识符指向该内存空间,指定了数组的大小
例如:
int * p=new int[5];
表示在堆区开辟了内存空间,并用p指向该空间,p数组的大小为5
(4)new开辟数组地址空间的同时向空间里存放初始值
格式:
数据类型 *标识符=new 数据类型[数组的大小] (初始值)
表示为向堆区申请一块内存空间,并用标识符指向该内存空间,指定了数组的大小,还赋予了初始值
例如:
int * p=new int[5]{1,2,3,4,5};
(5)delete操作符
在栈区申请的空间,用户使用完之后,编译器会自动回收用户使用的栈区的空间;在堆区申请的空间,用户使用完之后,编译器不会自动回收该堆空间,如果用户没有手动释放该堆空间,那么很容易造成内存泄露。在C++中给用户提供了delete操作符来释放用户申请的堆空间。
a.delete 释放变量地址空间
格式:
delete 标识符
例如:
int*p=new int(50);
delete p;//释放开辟的堆空间
b. delete 释放数组地址空间
格式:
delete [] 标识符
例如:
int*p=new int [5] {1 ,2,3,4,5};
delete [] p;//释放开辟的堆空间
面试题分享: malloc/free和new/delete异同点
相同点:malloc和new都是开辟堆内存空间,free和delete 都是释放堆内存空间
不同点:
(1)malloc和free是函数,new/delete是操作符
(2)malloc开辟空间的时候需要手动计算空间大小,new开辟空间时自动计算空间的大小
(3)malloc函数返回值类型为void*,使用时需要强制类型转换,new后面跟的是空间的类型,不需要
(4)malloc函数开辟空间的时候没有对空间进行初始化的工作,new开辟空间的时候可以对该空间进行初始化赋值操作
(5)malloc函数只能用于基本的数据类型,不能用于自定义类型(结构体除外),new不仅可以用于基本的数据类型,也可以用于自定义类型。
2.作用域
(1)全局作用域
存在于函数的外部,代码块{}外部、循环等的外部,称之为全局作用域,全局作用域里的数据对整个文件都是可见的,它的生命周期是从文件的开始直到文件结束
(2)局部作用域
存在于函数的内部,代码块{}内部、循环等的内部,称之为局部作用域,局部作用域里的数据对整个局部都是可见的,一旦超过局部作用域或生命周期就结束
(3)命名空间类型
存在于全局,是属于全局的一部分(它是{}括起来的,所以命名空间里的内容是属于局部的内容)
(4)类作用域
存在于全局,是属于全局的一部分(它也是{}括起来的,所以类里面的内容是属于局部的内容)
四、标准输入、输出流
iostream:istream(输入流类) + ostream(输出流类)
1.输入流cin
标准的输入流,用于将从输入设备得到的数据存到内存里
符号:cin------consle input
istream类:
istream类实例化的对象为 cin,控制台输入,istream类的对象cin是在iostream里的命名空间std里进行实例化
格式:
cin >> 内存变量;
或
cin >>内存变量1>>内存变量2>>.......;
或
cin >>内存变量1
>>内存变量2
>>内存变量3
.....2.输出流cout
cout (consle out):控制台输出,ostream类的对象cout是在iostream里的命名空间std里进行实例化
格式:
cout << 基本类型的数据;
或
cout<<基本类型的数据1<<基本类型的数据2<<.......;
或
cout<<基本类型的数据1
<<基本类型的数据2
<<基本类型的数据3
.....3.输出格式控制符
(1)输出进制的控制
a、十进制:dec
指定输出的数据是以十进制形式输出
格式:
cout << dec << 50 ;//表示格式控制符dec后的内容都是以十进制的形式进行输出
b、八进制:oct
指定输出的数据是以八进制形式输出
格式:
cout << oct <<50; //表示格式控制符oct后的内容都是以八进制的形式进行输出
c、十六进制:hex
指定输出的数据是以十六进制形式输出
格式:
cout<< hex<<50; //表示格式控制符hex后的内容都是以十六进制的形式进行输出
(2)其他类型的输出控制
编译器会自动解析输出的数据
(3)输出的位宽
setw(int n)//设置输出的内容的位宽为n位,是包含在iomanip内
格式:
cout<<setw(10)<<50<<endl; //设置输出的50的位宽为10位,默认是右对齐进行输出,如果不足位宽的那么就补空格
(4)输出位宽填充的数据
setfill(char x) //设置输出的内容位宽不足时,填充字符
格式:
cout<<setfill('*')<<setw(10)<<50<<endl;
(5)输出数据的对齐方式
setiosflags(ios :: statusflag)
a、右对齐:ios::right
cout<<setiosflags(ios ::right)<<setw(10)<<50<<endl;
b、左对齐:ios::left
cout<<setiofflags(ios::left)<<setw(10)<<50<<endl;
(6)输出数据的有效位数
setprecision(int n) //设置输出的数据有效的位数
格式:
cout<<setprecision(3)<<5.666666<<endl; //设置输出的数据有效的位数为3位
(7)指定输出数据的小数位数
setiosflags(ios::fixed) //固定小数的数据的小数点6位,一般是结合setprecision一起使用
cout<<setiosflags(ios::fixed)<<2.6<<endl; //固定小数的小数点后6位
结合setprecision(int n)
cout<<setiosflags(ios::fixed)<<setprecision( 5)<<2.66<<endl ;//表示数据2.66输出是保留小数点后5位,小数点后不足5位,用0补充

五、类和对象(重点)
1.类(关键字:class)
是指抽象的描述现实世界中的事物,具体描述的是事物的一些特征(属性)和行为(方法)

(1)类的声明
例如:人
人的特征:肤色、高矮 人的行为:学习、吃饭
格式
class 类名
{
特征;
行为;
};//分号不能省略例如:
class people
{
特征:
int year;//年龄
char sex; //性别
................
行为:
Void study()
{
} //学习
Void run()
{
} //跑步
.........
};
注:类里的函数的声明和定义都已都在类里,也可以将函数的声明放在类里,函数的定义或实现放在类外
格式:
返回值类型 类名 ::函数名(参数列表)
{
}例如:
class num
{
int height;
int weight;
void code(); //函数的声明
};
Void class :: code();2.对象
指对类的实例化,是实实在在存在的事物,或者说是对类具体化的过程,两种方式实例化用户的描述类
(1)在栈区对类进行实例化
用户用完类的实例化的对象时,那么编译器会自动回收内存
格式:
类名 对象名 //类名和对象名都是标识符例如:
class People
{
int year;
int sex;
void run()
};
People zhangsan ;(2)在堆区对类进行实例化
在堆区进行实例化的对象,需要用户注意手动释放改对象占据的内存空间
格式:
类名 * 对象名 = new 类名例如:
class People
{
int year ;
int sex ;
void run()
{
//代码块
}
} ;
People * lisi = new People ;3.类的成员访问方式
根据类的实例化方式不同,类的成员访问方式也不同
(1)在栈区实例化类时
格式:
对象名 . 成员例如:
class People
{
int year ;
char sex ;
void run()
{
//代码块
}
} ;
People Zhangsan ;
Zhangsan.run();
Zhangsan.year=20;
Zhangsan .sex='男';(2)在堆区实例化类时
格式:
对象名 -> 成员例如:
class People
{
int year ;
char sex ;
void run()
{
//代码块
}
} ;
People * lisi = new People ;
lisi -> year ;
lisi ->run();4、类成员访问修饰符
是指对类的成员访问时加以限制,C++提供了三种类的成员访问修饰符:public、private、protected
(1)public
该成员访问修饰符修饰类的成员时,是表示该类的成员属于公共属性
a、类的成员使用public进行修饰时,就表示类的成员对于类的外部可以进行访问
b、类的成员使用public进行修饰时,表示类的成员对于类的内部也可以进行访问
c、类的成员使用public进行修饰时,表示类的成员对于派生类也可以进行访问
d、类的成员使用public进行修饰时,表示类的成员对于友元函数也可以进行访问
格式:
public:后面紧跟着是类的成员,它的作用范围从“:”后面的第一条语句开始一直遇到下一个类的成员访问修饰符或类的后括号}结束
class Box
{
public:
double length; // 盒子的长度
double breadth; // 盒子的宽度
double height; // 盒子的高度
};(2)private
该成员访问修饰符修饰类的成员时,是表示该类的成员属于私有属性
a、类的成员使用private进行修饰时,就表示类的成员对于类的外部不可以进行访问
b、类的成员使用private进行修饰时,表示类的成员对于类的内部可以进行访问
c、类的成员使用private进行修饰时,表示类的成员对于派生类不可以进行访问
d、类的成员使用private进行修饰时,表示类的成员对于友元函数也可以进行访问
格式:
private:后面紧跟着是类的成员,它的作用范围从“:”后面的第一条语句开始一直遇到下一个类的成员访问修饰符或类的后括号}结束
class Box
{
private:
double length; // 盒子的长度
double breadth; // 盒子的宽度
double height; // 盒子的高度
};(3)protected
该成员访问修饰符修饰类的成员时,是表示该类的成员属于受保护属性
a、类的成员使用protected进行修饰时,就表示类的成员对于类的外部不可以进行访问
b、类的成员使用protected进行修饰时,表示类的成员对于类的内部可以进行访问
c、类的成员使用protected进行修饰时,表示类的成员对于派生类可以进行访问
d、类的成员使用protected进行修饰时,表示类的成员对于友元函数也可以进行访问
格式:
protected:后面紧跟着是类的成员,它的作用范围从“:”后面的第一条语句开始一直遇到下一个类的成员访问修饰符或类的后括号}结束
class Box
{
protected:
double length; // 盒子的长度
double breadth; // 盒子的宽度
double height; // 盒子的高度
};注意:
(1)如果类的内部没有类的成员访问修饰符,默认类的成员是属于类的成员访问修饰符private下
(2)一般规定是将变量放在private属性下,函数放在其它的属性(public、protected)下(具体情况具体放置)
5、构造函数
构造函数是c++里提供的一种特殊函数,目的是为了初始化类的成员变量,它与普通的函数有一定的区别;构造函数在每个类都会存在一个,如果用户没有显示的写出构造函数,那么编译器会默认给类生成一个隐式的构造函数,如果用户显示的写出构造函数,那么编译器就不会默认生成一个隐式的构造函数
(1)构造函数的声明格式:(注:构造函数存在于类里)
格式:
类名 (参数列表)
{
类名()//构造函数与类名同名
//代码块
}例如:
class People
{
People() //该函数就称为构造函数
{
cout<<"构造函数调用"<<endl;
}
} ;(2)构造函数初始化类的成员变量
a、构造函数传参的方式
格式:
类名 (参数1 , 参数2 ,......)
{
类的成员变量1=参数1;
类的成员变量2=参数2;
.....
}b、构造函数带初始化列表的方式
格式:
类名 () : 成员变量1(初始值1),成员变量2(初始值2),........
{
//代码块
}注:
(1)构造函数没有返回值
(2)实例化类一次,那么就调用构造函数一次
(3)类的实例化对象时所带的参数一定要跟构造函数带的参数一致

(3)构造函数的调用
a、显式调用
需要实例化类的对象,通过类对象调用类的构造函数,称之为显式调用
例如:
class People
{
public:
People(int a)
{
cout<<"构造函数调用"<<endl;
}
}
People str(50);b、隐式调用
不需要实例化类的对象,直接根据构造函数对应的传参即可
格式:
类名(构造函数的参数)例如:
class People
{
public:
People(int a)
{
cout<<"构造函数调用"<<endl;
}
}
People(50);
面试题分享:简述普通函数和构造函数的异同点
相同点:
普通函数和构造函数都是函数,都可以实现特定功能
不同点:
A.普通函数具有返回值,构造函数没有返回值
B.普通函数不具备初始化列表的形式去初始化变量,而构造函数支持初始化列表的形式
C.普通函数与构造函数的调用时机不同,普通函数手动调用(显式),构造函数具备显示调用和隐式调用
D.普通函数不能发生重载(不能同名),构造函数可以发生重载
6.析构函数
析构函数也是C++提供的一种特殊函数,它存在于类中,类似于构造函数;如果用户没有显式的写出析构函数,那么编译器会自动生成一个默认的析构函数;如果用户显式的写出析构函数,那么编译器就不会自动生成。
作用:为了释放类的对象所占的空间
(1)格式
~ 类名()
{
}例如:
class Text
{
public:
Test()
{
}
~Text()
{
}
}(2)析构函数的调用(栈区自动释放内存,自动生成;堆区由程序员申请,要显式写出)
类的对象使用完成之后,就会自动调用析构函数,那么在程序内部就去释放对象所占内存;也可以理解为实例化对象之后,main函数体结束就会调用一次类的析构函数;如果类的对象在堆区实例化,那么delete对象之后才会调用一次析构函数(注:如果在类的对象里有成员在堆区开辟空间,那么一般在析构函数里去对该空间进行释放)

让我来总结一下:
A.析构函数没有返回值,只有符号“~”,表示函数是析构函数
B.析构函数的作用是为了释放对象数据成员所占的内存
C.析构函数在每一个类里只存在一个(如用户未写,则自动生成)
D.析构函数不允许带参数
7.拷贝构造函数(等同于C语言中的int a=2;int b=a;)
拷贝:复制构造函数的作用:用已经初始化的对象来初始化新的对象,拷贝构造函数存在于类中,如果用户没有写,则编译器自动生成
(1)拷贝函数原型
复制构造函数的参数可以是 const 引用,也可以是非 const 引用。 一般使用前者,这样既能以常量对象(初始化后值不能改变的对象)作为参数,也能以非常量对象作为参数去初始化其他对象。
类名 (类名 const & obj)
{
}
或
类名(const 类名 & obj)
{
}例如:
#include <iostream>
using namespace std;
class Test{
public:
int a;
Test(int x)
{
a=x;
}
Test( const Test &test){
cout<<"拷贝构造函数"<<endl;
a=test.a;
}
};
int main() {
Test t1(1);
Test t2=t1; //用一个对象初始化另外一个对象
return 0;
}(2)拷贝构造函数:浅拷贝和深拷贝
浅拷贝:指用一个已经存在对象去初始化新的对象,拷贝的仅仅是标识符和标识符里存储的内容
深拷贝:深拷贝拷贝的不仅仅是标识符和标识符里存储的内容,还拷贝它的地址(一般出现在类里有指针对象需要开辟空间的场景)
注:
浅拷贝只是值的拷贝,使两个对象指向同一个地址,在结束的时候,会造成同一块内存资源析构流程,造成程序崩溃
如果类类里面没有涉及到开辟堆空间,那么深拷贝与浅拷贝相同

8.this指针
防止出现二义性问题(例如同名同姓,叫一个人,全站起来),this指针存在于类的普通成员函数里,指向当前类。即可以通过this指针访问类的成员
例如:
#include <iostream>
using namespace std;
#include <math.h>
class Point{
public:
Point(int x, int y)
{
this->x = x;//当形参和成员变量同名时,可用this指针来区分
this->y = y;
}
float dis(Point &obj)
{
return sqrt( (x-obj.x)*(x-obj.x) + (y-obj.y)*(y-obj.y) );
}
private:
int x, y;
};
int main(int argc, char *argv[])
{
Point p1(3, 0), p2(0, 4);
cout << p1.dis(p2) << endl;
}注:
this参数是隐式的,并且存在类的成员函数里
static声明的成员函数不带this指针
类的友元函数里没有this指针
9.C++中static关键字
在C++里,如果将static成员声明为static类型,那么这个成员虽然是声明在类里面,但是它数据存放在全局
(1)static成员变量
格式:
Class 类名
{
static int a;
static int b;..........
}
注:类里的静态变量虽然是放在类里,但是是存放在全局,故初始化时需要在全局进行初始化类外初始化成员变量格式:
数据类型 类名::变量名=初始值;例如:
class people
{
static int a;
static int b;
};
int people::a=20;
int people::b=30;(2)static成员函数
格式:
class 类名
{
Static void fun();//static声明静态函数
};
类的静态成员函数不能使用类的非静态成员
类的静态成员函数能使用类的静态成员
类的静态成员函数没有this指针
类的非静态成员函数可以使用类的静态成员

10.const关键字
声明一个变量为常属性,只允许读,在C++中与C一致,用const声明的窜函数表示该成员函数是只读的性质。
(1)const修饰成员变量
格式:
class 类名
{
const int a=10;
const int b=20;
}(2)const修饰成员函数
class 类名
{
void function()const //在该函数里对于类的成员可读,不允许更改
}11.友元函数
C++友元分为友元函数和友元类
作用:给类的外部提供一个访问类的私有成员的接口
(1)友元函数
是将普通函数声明为友元类型,并且放在已经存在的类中,虽然友元函数是放在类中,但是不属于类的成员函数
关键字:friend
格式:
friend 函数返回值 函数名(参数列表)
{
}(2)友元类
给类的外部的类提供一个访问类的私有成员的接口
关键字:friend
格式:
class Text1
{
public:
friend class Text2;//将Text2声明为Text1的友元类,之后就可以在Text2访问Text1里的私有成员
private:
int a=10;
};
class text2
{}友元函数和友元类的实现:
#include <iostream>
using namespace std;
class Box
{
double width;
public:
friend void printWidth(Box box);
friend class BigBox;
void setWidth(double wid);
};
class BigBox
{
public :
void Print(int width, Box &box)
{
// BigBox是Box的友元类,它可以直接访问Box类的任何成员
box.setWidth(width);
cout << "Width of box : " << box.width << endl;
}
};
// 成员函数定义
void Box::setWidth(double wid)
{
width = wid;
}
// 请注意:printWidth() 不是任何类的成员函数
void printWidth(Box box)
{
/* 因为 printWidth() 是 Box 的友元,它可以直接访问该类的任何成员 */
cout << "Width of box : " << box.width << endl;
}
// 程序的主函数
int main()
{
Box box;
BigBox big;
// 使用成员函数设置宽度
box.setWidth(10.0);
// 使用友元函数输出宽度
printWidth(box);
// 使用友元类中的方法设置宽度
big.Print(20, box);
getchar();
return 0;
}六、运算符重载
1.重写、重载、隐藏(覆盖)
(1)重写:将原本的数据重新写一遍(原来的还存在)
多态:就是将类里的函数重新写(实现)一遍
(2)隐藏(覆盖):将原来的数据给覆盖/隐藏(原本的数据被覆盖,不存在),类似继承
(3)重载:以函数为例,函数名相同,函数的参数个数、顺序、类型不同

2.运算符重载
对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型

(1)成员函数运算符重载:是指运算符重载的函数是属于类的成员函数
格式:
返回值类型(自定义数据类型) operator 可以被重载的运算符 (参数列表) //参数列表是类类型的参数
{
}
(2)友元函数运算符重载
是指在类里声明运算符重载函数,但是在类外实现或定义,它其实质不属于类
格式:
friend 返回值类型(自定义数据类型) operator 可以被重载的运算符(参数列表)
{
}例如:
class Test
{
public:
int a = 10;
int b = 20;
friend Test operator -(const Test& obj1, const Test& obj2); //类里声明
};
Test operator -(const Test& obj1, const Test& obj2) //类外定义
{
Test test;
test.a = obj1.a - obj2.a;
test.b = obj1.b - obj2.b;
return test;
}(3)一般函数运算符重载(不是类的成员函数)
是指在类外声明和定义运算符重载函数,实现两个自定义的类类型的基本运算
格式:
返回值类型(自定义数据类型) operator 可以被重载的运算符(参数列表)
{
}例如:
class Test
{
public:
int a = 10;
int b = 20;
};
Test operator +(const Test& obj1, const Test& obj2)
{
Test test;
test.a = obj1.a + obj2.a;
test.b = obj1.b + obj2.b;
return test;
}七、类的继承与多态(重点)
1.类的继承
一个新类共享(继承)了另一个或多个已经存在的类的属性和方法(如儿子继承父亲的特征)。新的类称为子类(或派生类),已经存在的类称为父类(或基类)。如果子类继承一个父类为单继承,如果是子类继承多个父类为多继承。
(1)单继承格式
class 新的类(子类或派生类):继承权限 已经存在的类(父类或基类)
{
.........
}例如:
class Father
{
public:
int age;
int sex;
.......
}
class Son : public father
{
int age;int sex;//son具备age,sex
int height;//son本身特征
int weight;
}(2)多继承格式
Class 新的类:继承权限1 已经存在的类1,继承权限2 已经存在的类2...........
{
....................
}例如:
Class son:public father1,public father2
{
//son继承了father1和father2的属性和方法
}
1. 继承下来的属性和方法会自动被隐藏
2 .如果子类和父类有相同的属性和方法,调用的是子类的属性和方法
3 .如果子类继承父类,那么父类的private属性下的成员没有被继承到子类
4.父类的构造函数和析构函数没有继承到子类
5. 继承时父类构造/析构函数和子类构造/析构函数的调用时机:
构造时,先调用父类的构造函数,在调用子类的构造函数;析构时,先调用子类的析构函数,再调用父类的析构函数

2.继承权限
三种继承权限:
(1)public
父类public下的成员被继承到子类的public下
父类protected下的成员被继承到子类的protected下
父类private下的成员没有被继承到子类
(2)protected
父类public下的成员被继承到子类的protected下
父类protected下的成员被继承到子类的protected下
父类private下的成员没有被继承到子类的private下
(3)private
父类public下的成员被继承到子类的private下
父类protected下的成员被继承到子类的private下
父类prvate下的成员没有被继承到子类
3.多态
多态是指多种形态(多种方法),一种接口,多种方法。发生在具有继承关系的类中,是通过父类接口访问不同的方法。
构成多态的条件:
1.具有继承关系的两个类
2.父类中含有虚函数
3.子类重写父类的虚函数
(1)虚函数:在函数的返回值前加上一个关键字“virtual”就表示该函数为虚函数,虚函数是构成多态的必要条件
格式:
Virtual 返回值类型 函数名(参数列表)
{
//代码
}(2)多态的格式:
例如:
Class Father
{
Public:
Virtual void buy()
{
Cout<<”成人票:10”<<endl;
}
}
Class Son:public Father
{
Public:
Virtual void buy()
{
Cout<<”儿童票:5”<<endl;
}
}(3)多态的调用时机
基类的指针指向子类
基类的引用指向子类
(4)子类继承父类时,子类和父类的虚函数不同
继承时,将父类的虚函数继承到子类的虚函数表中,如果通过父类的指针指向子类,父类访问子类的成员时,只能访问从父类继承下来的虚函数,子类可以访问父类的虚函数
(5)子类继承父类时,子类和父类的虚函数相同
继承时,将父类的虚函数继承到子类的虚函数表中,如果通过父类的指针指向子类,父类可以访问子类与父类相同的虚函数,子类可以访问与父类不相同的虚函数
4.静态联编(绑定)
表达式或函数的地址在编译阶段就已经确定,例如C++里函的数重载,C语言里的普通函数
5.动态联编(绑定)
表达式或函数的地址在运行阶段才确定,例如多态
6.抽象类
一个类中没有足够的信息来描绘一个具体的对象(类里面含有纯虚函数),抽象类只能抽象的描述特征和行为,不具体实现行为,具体实现在子类中实现。
(1)纯虚函数:虚函数等于0
格式:
Virtual void func()=0; //表示该函数是纯虚函数(2)抽象类格式
class 类名
{
public:
virtual void func()=0; //表示该类是一个抽象类
} ;例如:
class Test
{
public:
virtual void func()=0; //表示Test类为抽象类
};
class Son : public Test
{
public:
virtual voiud func()
{
//具体实现
}
};
a、抽象类不能被实例化为具体的对象
b、抽象类只能作为子类的父类(基类)

7、虚析构函数
虚析构引入C++的目的是为了解决当基类指针指向子类,释放基类指针时,不会调用子类的析构函数的问题;在析构函数前加上关键字virtual,表示该函数是虚析构函数
格式:
virtual ~ 函数名 ()
{
}例如:
virtual ~ Test() //表示Test函数是虚析构函数
{
}8、虚继承
虚继承引入C++的目的是为了解决菱形(多)继承造成的二义性问题。如子类3同时继承子类1和2,会出现访问错误,此时虚继承可以解决
虚继承的格式:
class 子类 : virtual 继承权限 父类
{
}9、限制构造函数(了解)
构造函数不称限制构造函数。主要应用于一些特殊的场合。析构函数同理。
情况1:私有private ,提供构造对象的友元函数接口,限定对象的生成方式。如 对象只允许生成在堆区。通过友元函数 调用构造器实现对象创建
情况2:保护protected, 限制构造函数或析构函数只能通过继承方式,使用子类的构造或析构函数实现基类构造或析构的调用
此种方式一般用于抽象类,不允许直接创建对象,只能用于继承。使用继承时,应注意虚析构函数,基类指针delete的问题,即虚析构函数问题。同时,若析构函数受保护,则不能通过基类指针来调用,只能使用友元函数的方式。
八、异常
C++是一种支持容错机制的语言,C++支持发生错误,能主动抛出错误(异常),并捕获解决
关键字:throw、try、catch
1、throw
该关键字的作用是用于抛出异常
格式:
throw 异常 //它可以在程序的任何地方抛出异常2、try
该关键字的作用是用于检测异常
格式:
try
{
异常 ; //使用try来检测异常
}
3、catch
该关键字的作用是捕获并解决异常
格式:
catch(异常的类型)
{
异常的解决方案 ;
}注:
(1)一旦产生异常并捕获异常,程序自动终止,不会继续往后执行,如果没有产生异常,程序正常运行
(2)如果异常已经确定产生,但是没有写捕获该异常的catch块,那么异常会继续往上一层去抛出,如果上一层还没有解决,那么继续往上抛,如果最后main函数里没有解决该异常,那么会调用windows的termlate来终止程序运行
(3)try模块后面紧跟着至少一个catch块
(4)异常捕获的顺序是按照catch块的顺序进行捕获
(5)异常可以发生嵌套,如果内层没有捕获到异常,那么就在外层进行捕获,依次类推
(6)catch (...) //捕获所有异常,是指只要产生了异常,不管是什么类型都会捕获到
4、标准的异常类
std::exception 该异常是所有标准 C++ 异常的父类。
std::bad_alloc 该异常可以通过 new 抛出。
std::bad_cast 该异常可以通过 dynamic_cast 抛出。
std::bad_exception 这在处理 C++ 程序中无法预期的异常时非常有用。
std::bad_typeid 该异常可以通过 typeid 抛出。
std::logic_error 理论上可以通过读取代码来检测到的异常。
std::domain_error 当使用了一个无效的数学域时,会抛出该异常。
std::invalid_argument 当使用了无效的参数时,会抛出该异常。
std::length_error 当创建了太长的 std::string 时,会抛出该异常。
std::out_of_range 参数超出有效范围
std::runtime_error 理论上不可以通过读取代码来检测到的异常。
std::overflow_error 当发生数学上溢时,会抛出该异常。
std::range_error 当尝试存储超出范围的值时,会抛出该异常。
std::underflow_error 当发生数学下溢时,会抛出该异常。5、自定义异常类
自定义异常类需要继承异常的父类:exception类,具有异常exception的属性和方法,需要重写what方法
例如:
class MyException :public exception //例如该异常类是字符串异常
{
public:
const char* num;
MyException(const char* obj)
{
num = obj;
}
const char * what()
{
return num;
}
};
try
{
throw MyException("自定义字符串异常");
}
catch (MyException &obj)
{
cout << "捕获到了该异常" << endl;
cout << "异常的类型:" << obj.what() << endl;
}九、模版
模板是指作为一种参考(模型),用户可以向模型里放置任意类型的数据,C++里模板是指模板里的数据的类型可以是任意的数据类型,模板分为函数模板和类模板,泛型编程:数据的类型可以变的(广泛)
1.函数模板
关键字:template、typename、class
格式:
template<模板形参1 ,模板形参2 ,......> 函数的返回值 函数的名称 (函数形参1,函数形参2,.....)
{
//代码块
}例如:
template<typename T1 , typename T2 ,......> void function( T1 a , T2 b )
{
//代码块
}注:
(1)template关键字用于声明函数为模板
(2)typename/class用于声明模板形参
(3)模板形参T1、T2等等可以代表任意数据类型:自定义类型、int、char、const char *等等
(4)模板形参里的T1、T2等是与函数形参里的T1、T2是对应的
(5)函数模板遵循函数重载
2、函数模板的调用
(1)与普通函数的调用一致
格式:
函数名 (实参);例如:
function(20,30);(2)指定模板形参的数据类型
格式:
函数名 <数据类型1 ,数据类型2,.....>(实参);例如:
function(int , char) (50 , ‘a’);3、类模板
格式:
template <模板形参1 , 模板形参2 ,........> class 类名
{
} ;例如:
template <typename T1 , typename T2 ,.....> class Test //表示Test是模板类
{
}(1)实例化模板类
格式:
类名 <数据类型1 ,数据类型2,......> 对象名 ;例如:
Test <int , char > test ;

十、智能指针
智能指针之前出现的问题:
(1)用户使用普通指针去申请堆空间,忘记释放
(2)堆空间在一个类中使用完之后立马进行释放,有时候堆空间不仅在这一个类中有使用,还在其他类中使用
智能指针:
C++提出智能指针的作用是帮助用户去管理裸指针开辟的堆空间,防止造成内存泄露;智能指针它实质不是一个指针,而是一个类,该类重载了指针的运算(->,.,*等等),就具备普通指针的一些特性;智能,体现在不需要用户管理堆空间,该指针自动帮助用户管理堆空间
C++提供了四种智能指针:
atuo_ptr(自动管理指针)、shared_ptr(共享指针)、weak_ptr(弱指针)、unique_ptr(唯一指针);注意,auto_ptr指针在C++11之后就被舍弃不用
1、shared_ptr
该指针用于帮助用户管理用裸指针开辟的堆空间,当用户没有使用开辟的堆空间时,该指针自动帮助用户释放该堆空间,shared译为共享,是指该指针可以和其他shared_Ptr管理同一块内存空间。
shared_ptr遵循内存空间管理权共享的概念,多个共享指针使用同一个引用计数机制空间
(1)引用机制
当一个shared_ptr管理一个堆空间时,内部会通过引用机制进行计数,管理一个堆空间引用计数加1;当shared_ptr解绑一个堆空间时,内部的引用计数机制就减1,当引用计数机制减到0时,相当于没有任何一个地方使用该堆空间,shared_ptr自动释放该堆空间。
(2)该智能指针释放堆空间的原理
a、shared_ptr内部的引用计数机制减到0时,自动释放裸指针开辟的堆空间
b、当shared_ptr对象超出作用域时,也会自动释放裸指针开辟的堆空间
(3)shared_ptr创建时指向的位置
a、指向它所管理的堆空间
b、指向引用计数机制的空间
(4)相关的函数
a、use_count()
查看引用计数
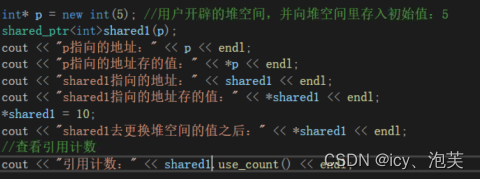
b、swap()
交换智能指针管理权利

c、reset()
释放管理堆空间的权利
2、weak_ptr
它是一种弱指针,弱绑定,C++引入弱指针的目的是为了解决共享指针shared_ptr循环占据资源,资源得不到释放的问题,它实质也是一个类,重载了(*,->等等)指针的符号,所以也称为指针
class Test3
{
public:
weak_ptr<Test4>shared1;
~Test3()
{
cout << "test3资源被释放" << endl;
}
};
class Test4
{
public:
weak_ptr<Test3>shared2;
~Test4()
{
cout << "test4资源被释放" << endl;
}
};
Test3* test3 = new Test3;
Test4* test4 = new Test4;
shared_ptr<Test3>shared11(test3);
shared_ptr<Test4>shared22(test4);
test3->shared1 = shared22;
test4->shared2 = shared11;3、unique_ptr
unique_ptr称为唯一指针,是指它只允许有一个智能指针管理一个堆空间。如果有超过两个唯一指针管理堆空间时,程序会报错(出现异常)
唯一指针:与共享指针类似,是一种受限制的共享指针,绑定一个指针指向对象。
unique_ptr 是 C++ 11 提供的用于防止内存泄漏的智能指针中的一种实现,独享《被管理对象指针》所有权的智能指针。unique_ptr对象包装一个原始指针,并负责其生命周期。当该对象被销毁时,会在其析构函数中删除关联的原始指针。
unique_ptr具有->和*运算重载符,因此它可以像普通指针一样使用。
格式:
unique_ptr<类型>对象名(指针对象)例如:
int *a = new int;
unique_ptr <int>unique(a);//使用unique来管理a指向的内存成员函数:
(1)reset()
重置unique_ptr为空,delete其关联的指针
(2)release()
释放关联指针的所有权,重置unique为空,不delete其关联的指针
(3)get()
返回关联指针(原始指针)的地址
十一、标准STL
标准模板库,算法库、容器库等等,例如:动态数组、队列、双向链表等等
1、动态数组:vector
数组,用于存放数据;C++动态数组也是用于存储数据,它在C++里是一个类,被包含在库文件“vector”里
动态:
是指数组的大小可以变化(长度可以变化)

动态数组的访问:
(1)符号[]
[下标] //访问指定下标对应元素

(2)函数at()访问
数组名.at(下标) //访问指定下标对应的元素

相关函数:
//vector<int>vec1; //创建一个空的动态数组,并且数组里的元素的类型是int类型
//vector<int>vec2(5);//创建一个具有5个int类型元素的数组
vector<int>vec3(5, 4);//创建一个具有5个int类型的数组,并且5个元素的值都是4
for (int i = 0; i < 5; i++)
{
cout << vec3.at(i) << endl;
}
//vec3.clear();//清空动态数组里的元素
//for (int i = 0; i < 5; i++)
//{
// cout << vec3.at(i) << endl;
//}
vec3.push_back(10);//向数组的尾部里添加元素
for (int i = 0; i < 6; i++)
{
cout << vec3.at(i) << endl;
}
cout << vec3.back() << endl;;//获取数组里的尾部的元素
cout << "数组大小:" << vec3.size() << endl;//获取数组的大小
//cout << vec3.begin() << endl;//获取数组里的头部元素的迭代器的地址
//vec3.empty();//判断数组是否为空,返回值bool类型,如果为空,true,否则为false
if (!vec3.empty())
{
cout << "数组vec3不为空" << endl;
}
//vec3.front();//获取数组里的头部的元素
cout << "数组头部的元素:" << vec3.front() << endl;
//vec3.cend();//获取数组里的尾部元素的迭代器的地址
//vec3.end();//获取数组里的尾部元素的迭代器的地址
vec3.pop_back();//删除动态数组的尾部的元素
for (int i = 0; i < 5; i++)
{
cout << vec3.at(i) << endl;
}
//该vector类包含了迭代器类
vector<int>::iterator iter=vec3.begin();
for (; iter != vec3.end(); iter++)
{
cout << *iter << endl;
}2、双端队列:deque
用存放数据,在C++里表示一个类,它被包含在库文件“deque”中,合并了 vector 和 list的特点,
优点:
随机访问方便,即支持[]操作符和vector.at(n)
在内部方便的进行插入和删除操作
可在两端进行push、pop
缺点:
占用内存多
区别:
如果你需要高效的随即存取,而不在乎插入和删除的效率,使用vector
如果你需要大量的插入和删除,而不关心随机存取,则应使用list
如果你需要随机存取,而且关心两端数据的插入和删除,则应使用deque
#include "deque"
deque<int> d1; //创建一个空的双端队列d
deque<int>d2(n) ; //创建一个元素个数为n的队列
deque<int>d3(n,num); //创建一个元素个数为n的队列,并且每个元素为num
成员函数:
push_back() //在队尾插入元素
push_front() //在队首插入元素
insert(d.begin()+1,9); //第一个元素之后插入9
size() //双端队列的大小
empty() //判断是否为空
begin() //队首的指针,指向队首元素
end() //队尾元素的下一位作为指针
rbegin() //以最后一个元素作为开始
rend() //以第一个元素的上一位作为指针
erase() //删除某一个元素
clear() //删除所有元素
pop_front() //删除队首元素
pop_back() //删除队尾元素
deque<int>::iterator it; //迭代器3、链表
链表相对于vector向量来说的优点在于:
(a)动态的分配内存,当需要添加数据的时候不会像vector那样,先将现有的内存空间释放,在次分配更大的空间,这样的话效率就比较低了。
(b)支持内部插入、头部插入和尾部插入
缺点:
不能随机访问,不支持[]方式和vector.at()、占用的内存会多于vector(非有效数据占用的内存空间)
(1)初始化list对象的方式
list L0; //空链表
list L1(3); //建一个含三个默认值是0的元素的链表
list L2(5,2); //建一个含五个元素的链表,值都是2
list L3(L2); //L3是L2的副本
list L4(L1.begin(),L1.end()); //c5含c1一个区域的元素[begin, end]。(2)list常用函数
begin():返回list容器的第一个元素的地址
end():返回list容器的最后一个元素之后的地址
rbegin():返回逆向链表的第一个元素的地址(也就是最后一个元素的地址)
rend():返回逆向链表的最后一个元素之后的地址(也就是第一个元素再往前的位置)
front():返回链表中第一个数据值
back():返回链表中最后一个数据值
empty():判断链表是否为空
size():返回链表容器的元素个数
clear():清除容器中所有元素
insert(pos,num):将数据num插入到pos位置处(pos是一个地址)
insert(pos,n,num):在pos位置处插入n个元素num
erase(pos):删除pos位置处的元素
push_back(num):在链表尾部插入数据num
pop_back():删除链表尾部的元素
push_front(num):在链表头部插入数据num
pop_front():删除链表头部的元素
sort():将链表排序,默认升序
.....(3)遍历方式
双向链表list支持使用迭代器正向的遍历,也支持迭代器逆向的遍历,但是不能使用 [] 索引的方式进行遍历。
list<int> List
list<int>::iterator iter = List.begin();
for( ; iter!=List.end() ; iter++)
{
cout<<*iter<<endl ;
}
以上便是此次C++的全部内容了,由于作者水平有限,如有错误,请大家多多指正。喜欢的大家三连支持一下喔