目录
PyTorch加载数据集
PyTorch是一个广泛使用的深度学习框架,它提供了许多方便的函数和工具,用于加载和处理各种数据集。在本文中,我们将介绍PyTorch中加载数据集的步骤。
1. 准备数据集
在加载数据集之前,我们需要准备好相应的数据集。这可能包括从本地文件系统或远程服务器获取数据集,将数据集转换为PyTorch可识别的格式,以及将数据集分为训练集、验证集和测试集等。
在PyTorch中,我们通常将数据集表示为一个`Dataset`对象。这个对象包含所有数据样本以及用于获取和处理这些样本的函数。PyTorch提供了许多内置的`Dataset`对象,如`ImageFolder`、`CIFAR10`和`MNIST`等,我们还可以自己定义一个`Dataset`对象来适应特定的数据集。
2. 创建数据加载器
在准备好数据集之后,我们需要创建一个`DataLoader`对象来加载数据集。`DataLoader`对象可以将数据集分成小批量,以便在训练过程中逐批处理数据。它还可以设置数据集的并行加载,以加快数据处理速度。
在创建`DataLoader`对象时,我们需要指定一些参数,如批量大小、是否打乱数据、并行加载的进程数量等。例如,以下代码创建了一个`DataLoader`对象,用于加载名为`my_dataset`的数据集:
from torch.utils.data import DataLoader
batch_size = 64
shuffle = True
num_workers = 4
my_loader = DataLoader(my_dataset, batch_size=batch_size, shuffle=shuffle, num_workers=num_workers)3. 迭代数据集
创建`DataLoader`对象后,我们可以使用它来迭代数据集。在每次迭代中,`DataLoader`对象会返回一个小批量的数据样本,我们可以将这些样本输入模型进行训练或测试。
以下是一个简单的数据集迭代示例:
for batch_idx, (data, target) in enumerate(my_loader):
# 处理数据批量
# data:一个形状为[batch_size, ...]的张量,包含一个批量的数据样本
# target:一个形状为[batch_size, ...]的张量,包含一个批量的标签或类别
# ...在迭代数据集时,我们还可以使用PyTorch提供的一些内置函数和工具,如数据增强、数据标准化、数据可视化等,以便更好地处理和分析数据集。
PyTorch提供了一个简单而强大的数据加载和处理框架,使我们能够轻松地加载和处理各种数据集。通过使用PyTorch提供的数据加载器和数据迭代器,我们可以更高效地训练和测试深度学习模型,从而实现更好的性能和结果。
高纬数组数据
在很多情况下,我们需要从文本(如csv文件)中读取高维数组数据,这类数据的特征是每个样本都有很多个预测变量(特征)和一个被预测变量(目标标签),特征 通常是数值变量或者离散变量,被预测变量如果是连续的数值,则对应着回归问题的预测,如果是离散变量,则对应着分类问题。在使用PyTorch建立模型对数据 进行学习时,通常要对数据进行预处理,并将它们转化为网络需要的数据形式。
1.回归类型数据集
import numpy as np # 导入NumPy库,用于处理数组和矩阵 import torch # 导入PyTorch库,用于构建和训练深度学习模型 import torch.utils.data as Data # 导入PyTorch中的数据工具 from sklearn.datasets import load_linnerud, load_iris # 导入scikit-learn中的数据集 # 加载Linnerud数据集,并将特征和标签分别存储到l_x和l_y中 l_x, l_y = load_linnerud(return_X_y=True) # 打印l_x和l_y的数据类型 print("bx.type", l_x.dtype) print("by.type", l_y.dtype) # 将l_x和l_y转换成PyTorch张量,并将数据类型设置为float32 train_xt = torch.from_numpy(l_x.astype(np.float32)) train_yt = torch.from_numpy(l_y.astype(np.float32)) # 打印train_xt和train_yt的数据类型 print("train_xt.type", train_xt.dtype) print("train_xt.type", train_xt.dtype) # 使用TensorDataset将train_xt和train_yt打包成一个数据集对象 train_data = Data.TensorDataset(train_xt, train_yt) # 创建一个数据加载器对象,用于加载train_data中的数据 train_loader = Data.DataLoader( dataset=train_data, # 指定要加载的数据集对象 batch_size=32, # 指定每个数据批次的大小 shuffle=True, # 指定是否对数据进行随机洗牌 ) count = 0 # 初始化数据批次计数器 for i, (l_x, b_y) in enumerate(train_loader): # 迭代数据加载器对象,每次返回一个数据批次 if i == 0: # 如果是第一个数据批次 # 打印数据批次l_x和l_y的形状和数据类型 print("b_x.shape", l_x.shape) print("b_y.shape", l_y.shape) print("b_x.type", l_x.dtype) print("b_y.type", l_y.dtype) count += 1 # 计算已处理的数据批次数量 # 打印数据批次数量,即数据集大小 print("data size:", count)
这段代码的主要作用是加载Linnerud数据集,将其转换成PyTorch张量,并使用数据加载器对象批量读取数据。其中,`load_linnerud`函数用于加载Linnerud数据集,`torch.from_numpy`函数用于将NumPy数组转换成PyTorch张量,`Data.TensorDataset`用于将多个张量打包成一个数据集对象,`Data.DataLoader`用于创建一个数据加载器对象,用于批量读取数据。在批量读取数据时,可以使用迭代器来逐批次读取数据,从而避免一次性加载整个数据集造成内存不足的问题。最后,通过打印数据批次的形状和数据类型,可以检查数据是否正确转换和加载。

2.分类问题的数据集
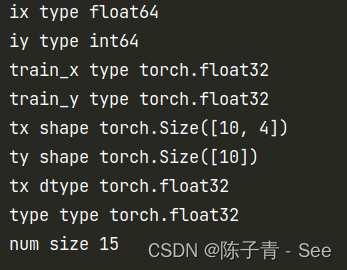
# 导入PyTorch库和相关模块 import torch import torch.utils.data as Data # 导入sklearn中的Iris数据集 from sklearn.datasets import load_iris # 加载Iris数据集,并将特征数据和标签数据分别赋值给ix和iy变量 ix, iy = load_iris(return_X_y=True) # 打印ix和iy的数据类型(dtype) print("ix type", ix.dtype) print('iy type', iy.dtype) # 将ix和iy转换为PyTorch张量,并将其赋值给train_x和train_y变量 train_x = torch.from_numpy(ix.astype(np.float32)) train_y = torch.from_numpy(iy.astype(np.float32)) # 打印train_x和train_y的数据类型(dtype) print("train_x type", train_x.dtype) print("train_y type", train_y.dtype) # 将train_x和train_y封装为PyTorch数据集 train_data = Data.TensorDataset(train_x, train_y) # 创建PyTorch数据加载器,用于将train_data划分为小批量数据并加载到内存中 train_loader = Data.DataLoader( dataset=train_data, batch_size=10, shuffle=True, num_workers=1, ) # 初始化计数器count为0 count = 0 # 遍历train_loader中的每个小批量数据,并打印第一个小批量数据的形状和数据类型(dtype) for i, (tx, ty) in enumerate(train_loader): if i == 0: print("tx shape", tx.shape) print("ty shape", ty.shape) print("tx dtype", tx.dtype) print("type dtype", ty.dtype) count += 1 # 打印小批量数据的总数 print("num size", count)
图像数据集
图像分类问题
ImageFolder是一个PyTorch库中的函数,用于加载和处理文件夹结构的图像分类数据集。该函数的输入是数据集的根目录,它会自动识别子文件夹的名称作为类别标签,然后将每个子文件夹中的所有图像加载为该类别的样本。该函数返回一个torchvision.datasets.ImageFolder的对象,其中包含了训练集和测试集的图像数据和标签,以及一些数据集的元信息。
下面是使用
ImageFolder函数加载分类数据集的一般步骤:1.准备数据集
将数据集的图像按照类别划分到不同的文件夹中,并将这些文件夹放在一个根目录下。每个子文件夹的名称应该是该类别的名称。
2.导入PyTorch库
首先需要导入PyTorch库及其相关模块,包括
torch、torchvision和transforms等。3.定义数据预处理操作import torch import torchvision from torchvision import transforms在使用
ImageFolder函数之前,需要定义一些数据预处理操作,例如将图像缩放到相同的大小、将图像转换为张量、对图像进行归一化等。可以使用transforms模块提供的函数来定义这些操作。例如,以下代码展示了如何将图像缩放为256x256像素,并将图像的像素值归一化到[0, 1]之间:data_transform = transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize(mean=[0.5], std=[0.5]) ])其中,
Resize函数将图像缩放为256x256像素,ToTensor函数将图像转换为张量,Normalize函数将图像的像素值归一化到[-1, 1]之间。这些操作将在后续的数据加载过程中应用到每个图像上。4.加载数据集
使用
ImageFolder函数加载数据集,需要指定数据集的根目录和数据预处理操作。例如,以下代码展示了如何加载名为mydataset的图像分类数据集:dataset = torchvision.datasets.ImageFolder(root='path/to/mydataset', transform=data_transform)其中,
root参数指定数据集的根目录,transform参数指定数据预处理操作。加载数据集后,可以使用len(dataset)和dataset.classes分别获取数据集的大小和类别标签。5.创建数据加载器
使用
DataLoader函数将数据集划分为小批量数据并加载到内存中,以便进行模型的训练和评估。例如,以下代码展示了如何创建训练集和测试集的数据加载器:train_loader = torch.utils.data.DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4) test_loader = torch.utils.data.DataLoader(dataset, batch_size=32, shuffle=False, num_workers=4)其中,
batch_size参数指定每个小批量的大小,shuffle参数指定是否对数据进行洗牌,num_workers参数指定数据加载器使用的线程数。
图像目标检测问题(yolo)
关于图像的目标检测,我一般都是使用开源的yolo项目,关于yolo本专栏后续会进行详细介绍