一. Python 的安装
1. Window 平台安装 Python
- 打开 WEB 浏览器访问:https://www.python.org/downloads/windows/
- 在下载列表中选择Window平台安装包,包格式为:
python-XYZ.msi文件 , XYZ 为你要安装的版本号。 - 下载后,双击下载包,进入Python安装向导,安装非常简单,你只需要使用默认的设置一直点击”下一步”直到安装完成即可。
- 环境变量设置:在命令行框中 (cmd) 输入:
path=%path%;C:\Python,按下enter
2. Linux 创建多版本 Python 环境
- 下载 Anaconda : https://www.anaconda.com/download/#linux, 如下载的包为:
Anaconda2-5.0.0.1-Linux-x86_64.sh - 安装 Anaconda: 在shell命令行输入
bash Anaconda2-5.0.0.1-Linux-x86_64.sh,一直按enter 和 yes 直至结束 - 创建linux python 3环境:
conda create -n py35(环境名称) python=3.5 (python版本) - 添加路径到
.bashrc文件:
export PATH="/home/hansry/anaconda2/bin:$PATH" #其中 /home/hansry/anaconda2 为安装包的路径
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda-8.0/bin:$PATH5.激活环境: source activate py35 ,直至出现用户名前面有 (py35) 字样则安装成功。如下图所示:

二.Python 的使用
1. 交互式解释器
$ python # Unix/Linux
或者
C:>python # Windows/DOS2. 命令行脚本
$ python script.py # Unix/Linux
或者
C:>python script.py # Windows/DOS 3. 集成开发环境(IDE: Integrated Development Environment): PyCharm , Spyder

三. Python 的基本语法
1. 行和缩进
学习 Python 与其他语言最大的区别就是,Python 的代码块不使用大括号 {} 来控制类,函数以及其他逻辑判断。python 最具特色的就是用缩进来写模块。
缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行。如下所示:
if True: if(true){
print "True" cout<<"True"<<endl;}
else: else{
print "False" cout<<"False"<<endl;}以下代码将会执行错误:
if True:
print "Answer"
print "True"
else:
print "Answer"
# 没有严格缩进,在执行时会报错
print "False"如果出现IndentationError: unexpected indent 则说明没有对齐,格式出错,python 对格式要求非常严格
2.常见的循环条件语句
1) while 循环语句:
count = 0 count=0
while (count < 9): while(count<9){
print('The count is:', count) cout<<'The count is:'<<count<<endl;
count = count + 1 count=count+1
}
print "Good bye!" cout<<"Good bye"<<endl;2) 条件语句:
flag = False
name = 'luren'
if name == 'python': # 判断变量否为'python'
flag = True # 条件成立时设置标志为真
print 'welcome boss' # 并输出欢迎信息
else:
print name # 条件不成立时输出变量名称3) for 循环语句
for i in range(10):
print(i)0
1
2
3
4
5
6
7
8
93. Python 标识符
在python 里,标识符由字母、数字、下划线组成。
在 python中,所有标识符可以包括英文、数字以及下划线(_),但是不能以数字开头。
Python 中的标识符是区分大小写的。
以下划线开头的标识符是有特殊意义的。以单下划线开头 _foo 的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用 from xxx import * 而导入;
以双下划线开头的 _foo 代表类的私有成员;以双下划线开头和结尾的 __foo_ 代表 Python 里特殊方法专用的标识,如 init() 代表类的构造函数。
4.Python 模块的使用
Test1.py
class hello_world: #类
def __init(self):pass
def f(self):print('Hello, World!')
def vision(): #函数
print('machine vision')
if __name__=='__main__':
hello_world().f()1). 若在shell窗口直接运行 python Test1,得到:
Hello, World!因为此时__name__== '__main__' 成立,所以直接运行 hello_world().f()
2). 若是直接在 shell 窗口直接运行 import Test1,则此时 Test1 会被当做一个对象来使用,而不会运行到hello_world().f()
>>> import Test1
>>> Test1.__name__
'Test1'若写另一文件 Test2.py:
import Test1
Test1.vision()执行 Test2.py 文件,可得:
>>> python Test2.py
machine vision因此,python文件既可以当做执行文件来使用,也可以当做对象来使用,这一点和 MALATB 十分相似。
5.Python 的类和实例
1). 在面向对象中,最重要的概念就是类(class)和实例(instance),类是抽象的模板,而实例是根据类创建出来的一个个具体的 “对象”。
学生是个较为抽象的概念,同时拥有很多属性,可以用一个 Student 类来描述,类中可定义学生的分数、身高等属性,但是没有具体的数值。
而实例是类创建的一个个具体的对象, 每一个对象都从类中继承有相同的方法,但是属性值可能不同,如创建一个实例叫 hansry 的学生,其分数为 93,身高为 174,则这个实例拥有具体的数值。
class Student(object):
def __init__(self,name,score):
self.name=name
self.score=scorea.(object)表示的是该类从哪个类继承下来的,而object类是每个类都会继承的一个类。
b. __init__ 方法的第一参数永远是 self,用来表示类创建的实例本身,因此,在 __init__ 方法内部,就可以把各种属性绑定到self,因为self 本身就是指向创建的实例本身。(C++ this 指针)
c. 有了 __init__ 方法后,在创建实例的时候,就不能传入空参数,必须传入与 __init__ 方法匹配的参数,但self本身不需要传入参数,只需要传入 self 后面的参数即可。
2). 实例: 定义好了类后,就可以通过Student类创建出 Student 的实例,创建实例是通过 类名 + ()实现:
student = Student('hansry', 93)
>>> student.name
'hansry'
>>> student.score
93a. 其中 Student 是类名称,(’name’,93)为要传入的参数
b. self.name 就是 Student类的属性变量,为 Student 类所有。同时, name 是外部传来的参数,不是 Student 类所自带的。故 self.name = name 的意思就是把外部传来的参数 name 的值赋值给 Student类自己的属性变量 self.name .
c. 和普通函数相比,在类中定义函数只有一点不同,就是第一参数永远是类的本身实例变量 self, 并且调用时,不用传递该参数。 除此之外,类的方法(函数)和普通函数没有啥区别。既可以用 默认参数、可变参数或者关键字参数等。
3). 限制外部对类实例属性的访问
如果不想让实例中的内部属性被外部属性访问,则把 name 和 score 变成 __name 和 __score 即可,如下代码所示:
class Student(object):
def __init__(self, name, score):
self.__name = name
self.__score = score
def print_property(self):
print "%s: %d" %(self.__name,self.__score)>>> student= Student("hansry",99)
>>> student.print_property()
>>> student.__name()
hansry:99
Traceback (most recent call last):
AttributeError: 'Student' object has no attribute '__name'4). 开 API 使得外部代码能够访问到里面的属性,并且对其进行修改
class Student(object):
def __init__(self, name, score):
self.__name = name
self.__score = score
def print_property(self):
print "%s: %d" %(self.__name,self.__score)
def reset_name(self,change_name):
self.__name = change_name
def reset_score(self, change_score):
self.__score = change_score student= Student("hansry",99)
student.print_property()
hansry:99
student.reset_name("simona")
student.reset_score(91)
student.print_property()
simona:915). self 的仔细用法
A. self代表类的实例,而非类。
class Student(object):
def print_self(self):
print(self)
print(self.__class__)student=Student()
student.print_self()
<__main__.Student object at 0x7fd9095aed90>
<class '__main__.Student'>从上面例子可得,self代表的只是类的实例,而 self.class 才是类。
B. 定义类的时候,self最好写上,因为它代表了类的实例。
四. Tensorflow 的安装
1. Tensorflow 在 windows 的安装和运行
1) 安装docker: 首先要安装 docker,就是类似于给你提供一个类似于linux的窗口,具体见官网的文档或者百度。到 docker 官网下载 Docker Toolbox,下载的版本可以为 DockerToolbox-1.10.2(备注:如果在window7 下安装没成功的就换 window 8或者 window 10), 然后安装方法参照docker官网或者百度,这个比较简单。
2) 安装 tensorflow,进入tensorflow官网,版本选择 0.6.0。DockerToolbox (即上面的软件) 装好之后,桌面会有个Docker Quickstart Terminal 的快捷键 
docker run -it b.gcr.io/tensorflow/tensorflow回车后就会自动下载,保持网速良好,可能会等比较长时间,下载完成后会有:
3) 等上述下载结束后,打开windows命令提示符 (cmd),输入以下命令:
FOR /f "tokens=*" %i IN ('docker-machine env --shell cmd default') DO %i运行成功后如下图所示:
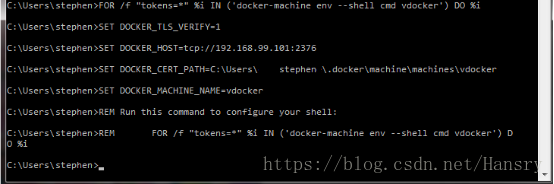
4) 回到 Docker Quickstart Terminal,输入以下命令:
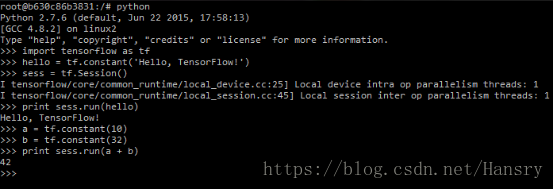
docker run -it b.gcr.io/tensorflow/tensorflow-full待下载完成后,系统会自动进入linux shell,输入python,开始你的tensorflow之旅吧,如下图:
2. Tensorflow 在 linux 下 的安装和运行
在上述中已经提到如何安装anaconda,当安装成功后,安装tensorflow就显得容易很多:
1) source activate py35 激活anaconda环境
2) conda install tensorflow 直接安装tensorflow五. Tensorflow 的基本介绍
1. 为什么要学 Tensorflow ?
Tensorflow 支持异构设备分布式计算。
异构设备: 指CPU、GPU 等核心进行有效地协同合作。与只依靠CPU相比,性能更高,功耗更低。
分布式: 分布式架构的目的在于帮助我们调度和分配计算资源, 使得上千万、上亿数据量的模型能够有效地利用机器资源进行计算。
2.Tensorflow 的基本概念
1) TensorFlow的数据中央控制单元是tensor(张量),一个tensor由一系列的原始值组成,这些值被形成一个任意维数的数组。
import tensorflow as tf 上面的是TensorFlow 程序典型的导入语句,作用是:赋予Python访问TensorFlow类(classes),方法(methods),符号(symbols)
3.The Computational Graph
TensorFlow 核心程序由2个独立部分组成:
a.Building the computational graph 构建计算图
b.Running the computational graph 运行计算图
一个 computational graph(计算图) 是一系列的 TensorFlow 操作排列成一个节点图:
node1 = tf.constant(3.0, dtype=tf.float32) #定义浮点精度类型的张量
node2 = tf.constant(4.0) # also tf.float32 implicitly
print(node1, node2) Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0",shape=(), dtype=float32) 上面 print 出来的结果只是告诉我们这张图里面有什么东西,并没有真正运行这个张量图,运行张量图需要经过 Running the computational graph :
sess = tf.Session()
print(sess.run([node1, node2])) [3.0, 4.0]因为这张图没有添加计算,所以只是简单的离散的张量,直接把他们输出来而已。
4.Tensorflow 的节点操作
我们可以组合Tensor节点操作(操作仍然是一个节点)来构造更加复杂的计算:
node3 = tf.add(node1, node2)
print("node3:", node3)
print("sess.run(node3):", sess.run(node3)) node3:Tensor("Add:0", shape=(), dtype=float32)
sess.run(node3):7.0 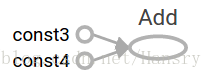
5.Placeholders 和 feed_dict 的使用
一个计算图可以参数化的接收外部的输入,作为一个placeholders(占位符),一个占位符是允许后面提供一个值的。
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
adder_node = a + b # + provides a shortcut for tf.add(a, b) 我们定义了2个输入参数a和b,然后提供一个在它们之上的操作,但是我们并没有提供给他们具体的值,即没有具体的张量提供计算,但是图是已经建好的。
feed_dict(传递字典)参数传递具体的值到run方法的占位符来进行多个输入,从而来计算这个图。
sess = tf.Session()
print(sess.run(adder_node, {a:3, b:4.5}))
print(sess.run(adder_node, {a: [1,3], b: [2,4]})) 7.5
[ 3. 7.]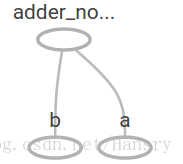
增加另外的操作来让计算图更加复杂,比如
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
adder_node = a + b # + provides a shortcut for tf.add(a, b)
add_and_triple = adder_node *3.
sess = tf.Session()
print(sess.run(add_and_triple, {a:3, b:4.5})) 22.5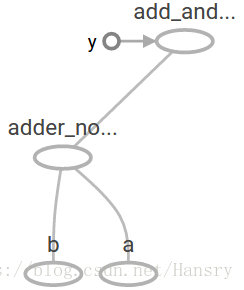
6. tf.Variable( ) 的使用, 并构造线性模型
在训练模型中,我们通常想让一个模型可以接收任意多个输入,比如大于1个,好让这个模型可以被训练,在不改变输入的情况下,
我们需要改变这个计算图去获得一个新的输出。变量允许我们增加可训练的参数到这个计算图中,它们被构造成有一个类型和初始值:
W = tf.Variable([.3], dtype=tf.float32)
b = tf.Variable([-.3], dtype=tf.float32)
x = tf.placeholder(tf.float32)
linear_model = W*x + b 当你调用tf.constant ()时常量被初始化,它们的值是不可以改变的,而变量当你调用tf.Variable()时没有被初始化,
在TensorFlow程序中要想初始化这些变量,你必须明确调用一个特定的操作,如下:
init = tf.global_variables_initializer()
sess.run(init) 要实现初始化所有全局变量的TensorFlow子图的的处理是很重要的,直到我们调用sess.run,这些变量都是未被初始化的。
既然x是一个占位符,我们就可以同时地对多个x的值进行求值linear_model,例如:
print(sess.run(linear_model, {x: [1,2,3,4,5]}))[ 0. 0.30000001 0.60000002 0.90000004 1.20000005]7. 构造损失函数(loss function)
虽然已经建立了一个线性模型,如何在训练数据上对这个模型进行评估,我们需要一个y占位符来提供一个期望的值,并且我们需要写一个loss function(损失函数),一个损失函数度量当前的模型和提供的数据差距有多大。
我们将会使用一个标准的损失模式来线性回归,它的增量平方和(最小二乘)就是当前模型与提供的数据之间的损失,linear_model - y 创建一个向量,其中每个元素都是对应的示例错误增量。这个错误的方差我们称为tf.square。然后
,我们合计所有的错误方差用以创建一个标量,用tf.reduce_sum 计算出所有示例的错误。
W = tf.Variable([.3], dtype=tf.float32)
b = tf.Variable([-.3], dtype=tf.float32)
x = tf.placeholder(tf.float32)
linear_model = W*x + b
y = tf.placeholder(tf.float32)
squared_deltas = tf.square(linear_model - y) #||liner_model - y||^2_{2}
loss = tf.reduce_sum(squared_deltas) #sum
init = tf.global_variables_initializer()
sess=tf.Session()
sess.run(init)
print(sess.run(loss, {x: [1,2,3,4, 5], y: [0, -1, -2, -3, 2]})) 24.38. optimizers(优化器)
Tensorflow提供optimizers(优化器),它能慢慢改变每一个变量以最小化损失函数,最简单的优化器是gradient descent(梯度下降),它根据变量派生出损失的大小, 来修改每个变量。通常手工计算变量符号是乏味且容易出错的,因此,TensorFlow使用函数tf.gradients 来进行迭代优化w 和 b:
import tensorflow as tf
W = tf.Variable([.3], dtype=tf.float32)
b = tf.Variable([-.3], dtype=tf.float32)
x = tf.placeholder(tf.float32)
linear_model = W*x + b
y = tf.placeholder(tf.float32)
squared_deltas = tf.square(linear_model - y) #||liner_model - y||^2_{2}
loss = tf.reduce_sum(squared_deltas) #sum
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
init = tf.global_variables_initializer()
sess=tf.Session()
sess.run(init)# reset values to incorrect defaults.
for i in range(1000):
sess.run(train, {x: [1,2,3,4,5], y: [0, -1, -2, -3, 2]})
print(sess.run([W, b]))[array([ 0.19999912], dtype=float32), array([-1.39999676], dtype=float32)]