数据加载器中数据的维度是[B, C, H, W],我们每次只拿一个数据出来就是[C, H, W],而matplotlib.pyplot.imshow要求的输入维度是[H, W, C],所以我们需要交换一下数据维度,把通道数放到最后面。
一、【pytorch】带batch的tensor类型图像显示
1、tensor转成numpy进行transpose,调用pyplot显示。
import matplotlib.pyplot as plt
import numpy as np
# ****************************可以通过运行test_data函数查看数据类型**************************************
def test_data():
print("train_dataloade len", len(train_dataloader))
for images, labels in train_dataloader:
print(labels)
print("label len", len(labels))
img = images[0]
img = img.numpy()
img = np.transpose(img, (1, 2, 0)) # C*H*W -> H*W*C
plt.imshow(img)
plt.show()
break2、tensor直接调用torch.permute进行维度转换
这里用到pytorch里面的permute方法(transpose方法也行,不过要交换两次,没这个方便,numpy中的transpose方法倒是可以一次交换完成),用法示例如下:参考文章《【pytorch】带batch的tensor类型图像显示》
另外说一下:
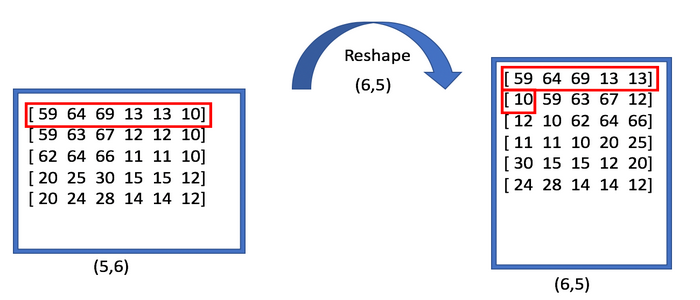
1) 在Numpy中,numpy.reshap操作首先将多维数组转为一维向量,然后按照你重新定义的形状,再把这个列表截断拼成新的形状。reshape改变原数组形状后,数组元素还是根据原来的顺序依次排列的。
numpy.transpose该函数是用于实现矩阵的转置。而对于高维矩阵则该函数也可实现维度交换,但与reshape不一样。此处是基于转置的交换维度,排列顺序不会与原始相同。
2)Pytorch中的reshpe() 和 view() 两个函数满足条件时可以根据需要设置维度,而 transpose() 和 permute() 两个函数只能在已有的维度之间进行变换,另外 transpose() 函数在 pytorch 和 numpy 中略有不同,numpy 中的 transpose() 函数相当于 pytorch 中的 permute() 函数。《pytorch:深入理解 reshape(), view(), transpose(), permute() 函数_听 风、的博客-CSDN博客_pytorch reshape参数》
3)如果对 tensor,使用transpose或permute之后,若要使用view(),必须先contiguous()。transpose与permute会实实在在的根据需求(要交换的dim)把相应的Tensor元素的位置进行调整, 而view 会将Tensor所有维度拉平成一维 (即按行,这也是为什么view操作要求Tensor是contiguous的原因),然后再根据传入的的维度(只要保证各维度的乘积=总元素个数即可)信息重构出一个Tensor。

#%% 导入模块
import torch
import matplotlib.pyplot as plt
from torchvision.utils import make_grid
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
#%% 下载数据集
train_file = datasets.MNIST(
root='./dataset/',
train=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]),
download=True
)
#%% 制作数据加载器
train_loader = DataLoader(
dataset=train_file,
batch_size=9,
shuffle=True
)
#%% 训练数据可视化
images, labels = next(iter(train_loader))
print(images.size()) # torch.Size([9, 1, 28, 28])
plt.figure(figsize=(9, 9))
for i in range(9):
plt.subplot(3, 3, i+1)
plt.title(labels[i].item())
plt.imshow(images[i].permute(1, 2, 0), cmap='gray')
plt.axis('off')
plt.show()
这里以mnist数据集为例,演示一下显示效果。我这个代码其实还有一点小问题。数据增强的时候我不是进行标准化了嘛,就是在第7行代码:Normalize((0.1307,), (0.3081,))。所以,如果你想查看训练集的原始图像,还得反标准化。
- 标准化:
image = (image-mean)/std - 反标准化:
image = image*std+mean
二、读取本地图像显示
1)、第一种是opencv的cv2.imread方法
注意输出数据类型是“<class 'numpy.ndarray'>”。
import cv2
img = cv2.imread("./studyTest/liushishi.png")
#cv2.resizeWindow("img",255,255)#这里可以设置窗口的大小,名称须保持一致
height,width = img.shape[:2] #获取原图像的水平方向尺寸和垂直方向尺寸。
img=cv2.resize(img,(int(width/4),int(height/4)),interpolation=cv2.INTER_NEAREST)
# cv2.WINDOW_NORMAL # 用户可以改变这个窗口大小
# cv2.WINDOW_AUTOSIZE # 窗口大小自动适应图片大小,并且不可手动更改。
# cv2.WINDOW_FREERATIO # 自适应比例
# cv2.WINDOW_KEEPRATIO # 保持比例
# cv2.WINDOW_OPENGL # 窗口创建的时候会支持OpenGL
cv2.namedWindow("img",cv2.WINDOW_AUTOSIZE)
cv2.imshow("img", img)
print(type(img)) # <class 'numpy.ndarray'>
cv2.waitKey(0) # 持续刷新图像
cv2.destroyAllWindows() # 删除所有窗口
<class 'numpy.ndarray'>
输出:

2)matplotlib方法:image.imread()方法
注意输出数据类型也是<class 'numpy.ndarray'>。
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
if __name__ == '__main__':
img = mpimg.imread("./liushishi.png")
plt.imshow(img) ##相当于对图像进行了处理,但不能显示,需要配合plt.show()
plt.axis('off') ##没有这一步最后的图像会有坐标轴
plt.show()
输出:

注意:opencv读入的图像是BGR格式,而其他通用的都是RGB,所以根据Img = img[:, :, ::-1]可以实现RGB和BGR的转换。
3)PIL中的Image类,输出可以直接通过img.show()
可以利用PIL中的Image类来读取图片,Image是一个类,它的常用方法有open(),save(),show(),spilt()和merge()等。
该方法读取出来的就是一个PIL Image类,可以直接调用上述方法,img.show()显示图片。
img.save(outfile)将图片保存到对应路径,r,g,b = im.split()将Mode=RGB的图像分开,得到的结果其类型依旧是Image类,但是其Mode=L。同样我们可以利用merge()将三个Mode=L的灰度图合成彩色图片new_im = Image.merge("RGB",(r,g,b))
from PIL import Image
import numpy as np
if __name__ == '__main__':
file_path = './liushishi.png'
img = Image.open(file_path)
print(img.mode) # RGBA 格式
img.show()
print(type(img)) # <class 'PIL.PngImagePlugin.PngImageFile'>
im_data = np.array(img)
print(type(im_data)) # <class 'numpy.ndarray'>
img_from_array = Image.fromarray(im_data)
print(type(img_from_array)) # <class 'PIL.Image.Image'>
r, g, b,alpha_channel= img.split()
new_im = Image.merge("RGB", (r, g, b))
img.save(new_im)
Image类可以和numpy中的矩阵相互转化,转化后的im_data的数据类型为unit8,也就是标准的图片数据类型0~255,其形状是(length,width,3),需要注意的是3在最后一维(RGB图像)RGBA图像是4。
4)pytorch中的torchvision.utils.save_image
一般来说,需要将tensor转变为numpy类型的数组从而保存图片,这样的过程比较繁琐,Pytorch提供了save_image()函数,可直接将tensor保存为图片,若tensor在cuda上也会移到CPU中进行保存。

参数:
tensor (Tensor or list): Image to be saved. If given a mini-batch tensor, saves the tensor as a grid of images by calling make_grid.
**kwargs: Other arguments are documented in make_grid.
其中从第三个参数开始为函数make_grid()的参数。
根据官方文档的描述,make_grid()函数主要用于生成雪碧图,何为雪碧图(sprite image)?即由很多张小图片组成的一张大图。如下图所示。

结论:torchvision.utils包中提供了save_image()函数可以很方便的将tensor数据保存为图片,其中如果tensor由很多小图片组成,则会自动调用make_grid()函数将小图片拼接为大图片再保存。
5)Image.open()和cv2.imread(), PIL Image和OpenCV,两者之间的相互转换:
-
img = Image.open(ImgPath)打开的图片是PIL类型,默认RGB。
将PIL类型转化为numpy类型:im = numpy.array(img)
才能看到shape属性,是(height, width, channel)数组,channel的通道数据是RGB。 -
cv2.imread(path, 读取方式):
path: 图片的路径;
读取方式: cv2.IMREAD_COLOR:读入一副彩色图片;cv2.IMREAD_GRAYSCALE:以灰度模式读入图片;cv2.IMREAD_UNCHANGED:读入一幅图片,并包括其alpha通道。
默认为cv2.IMREAD_COLOR。
返回值是(height,width,channel)数组,channel的顺序是BGR顺序 -
两者之间的相互转换
PIL Image转化为OpenCV格式:img = Image.open()img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)import cv2 from PIL import Image import numpy as np if __name__ == '__main__': file_path = './liushishi.png' img = Image.open(file_path) img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR) # np.asarray()不会拷贝对象。 cv2.imshow("img", img) cv2.waitKey(0) # 持续刷新图像 cv2.destroyAllWindows() # 删除所有窗口 -
OpenCV转化为PIL Image格式:
img = cv2.imread()img2 = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))import cv2 from PIL import Image import numpy as np if __name__ == '__main__': file_path = './liushishi.png' img = cv2.imread(file_path) img2 = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) img2.show() -
判断图像数据是否为OpenCV格式:
isinstance(img, np.ndarray)