你怎么教一台从未见过人脸的机器学会绘出人脸?计算机可以存储字节级的照片,但它却不知道怎样的一堆像素组合才具有与人类相似的外表。多年以来,已经出现了很多各种各样旨在解决这一问题的生成模型。它们使用了各种不同的假设来建模数据的基本分布,有的假设太强,以至于根本不实用。对于我们目前的大多数任务来说,这些方法的结果仅仅是次优的。使用隐马尔可夫模型生成的文本显得很笨拙,而且可以预料;变分自编码器生成的图像很模糊,而且尽管这种方法的名字里面有「变」,但生成的图像却缺乏变化。所有这些缺陷都需要一种全新的方法来解决,而这样的方法最近已经诞生了。在这篇文章中,我们将对生成对抗网络(GAN)背后的一般思想进行全面的介绍。
GAN 的发明
目前深度学习领域可以分为两大类,其中一个是检测识别,比如图像分类,目标识别等等,此类模型主要是VGG, GoogLenet,residual net等等,目前几乎所有的网络都是基于识别的;另一种是图像生成,即解决如何从一些数据里生成出图像的问题,生成类模型主要有深度信念网(DBN),变分自编码器(VAE)。而某种程度上,在生成能力上,GAN远远超过DBN、VAE。经过改进后的GAN足以生成以假乱真的图像。2014 年,Ian Goodfellow 及其蒙特利尔大学的同事引入了生成对抗网络(GAN)。这是一种学习数据的基本分布的全新方法,让生成出的人工对象可以和真实对象之间达到惊人的相似度。
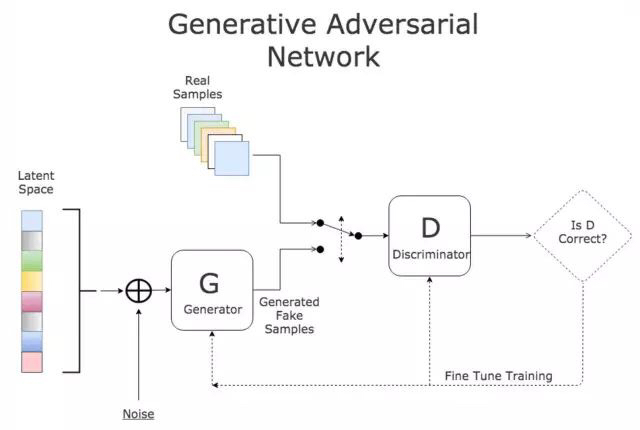
这张图给出了生成对抗网络的一个大致概览。目前最重要的是要理解 GAN 差不多就是把两个网络放到一起工作的方法——生成器和鉴别器都有它们自己的架构。
对抗样本
在我们详细描述 GAN 之前,我们先看看一个有些近似的主题。给定一个训练后的分类器,我们能生成一个能骗过该网络的样本吗?如果我们可以,那看起来又会如何?
事实证明,我们可以。
不仅如此,对于几乎任何给定的图像分类器,都可以通过图像变形的方式,在新图像看起来和原图像基本毫无差别的情况下,让网络得到有很高置信度的错误分类结果!这个过程被称为对抗攻击(adversarial attack),而这种生成方式的简单性能够给 GAN 提供很多解释。
对抗样本(adversarial example)是指经过精心计算得到的旨在误导分类器的样本。下图是这一过程的一个示例。图像分类器所判断的左边的熊猫所属的分类就和右边的不一样,右边的图被分类为了长臂猿。

图片来自:Goodfellow, 2017
可以看出,当给一张照片添加上随机噪声后,即使人类肉眼看上去,两张图片并没有明显的差别,但是在分类器的内部所处理的都是图片像素值的向量数据,加入随机噪声后的向量数据与图片的原始数据将会有很大的差别,所以分类器会给出错误的判断。
生成器和鉴别器
现在我们已经简单了解了对抗样本,如果我们前文所述的图像分类是二分类器,即理想情况下输出为0(不是原始图片)或1(是原始图片),根据 Goodfellow 等人那篇原始论文的说法,我们称之为鉴别器(Discriminator)。
现在让我们增加一个网络,让其可以生成会让鉴别器错误分类的图像。这个过程和我们在对抗样本部分使用的过程完全一样,这个网络称为生成器(Generator)。
在训练的每一步,鉴别器都要区分真样本和一些假样本的图像,这样它区分真假的能力就越来越强。同时,生成器也会增强自己生成假样本图像的能力,最后双方博弈的结果就是,生成器生成的假样本与真样本几乎没有差别,从而导致鉴别器不能区分真样本还是假样本,此时整个训练结束,我们说生成器和鉴别器达到了平衡。而这个训练好的生成器,就是我们想要的,它可以帮助我们生成与真实样本近似相同的样本。下图体现了该过程。

GAN的整个训练过程主要是基于下面的损失函数:
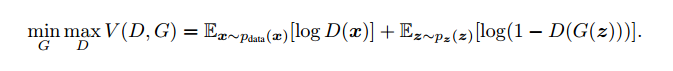
我们将在后续的博文中对该函数进行具体的理论推倒。