本文只是简单介绍这些文章的算法和网络结构,详细内容可以在我的博客内找,这几篇里SRLUT是比较新的(2021)。
原文链接:
RCAN: Image Super-Resolution Using Very Deep Residual Channel Attention Networks
SRLUT: Practical Single-Image Super-Resolution Using Look-Up Table 【CVPR2021】
ESPCN:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
VESPCN: Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation
RCAN
RCAN: Image Super-Resolution Using Very Deep Residual Channel Attention Networks
这篇文章网络是迄今为止最深的(是指该篇文章的时间)。
文章主要目的就是冲着深度去的,训练了一个非常深的网络,提出了RIR结构、提出了通道注意力机制CA。

这篇文章主要两个点:
- 通过多层套娃(三次),训练了一个非常深的网络(超400层),提出了RIR结构。
- 作者认为特征图像不同通道包含不同重要程度的信息,于是提出了通道注意力机制CA。
RCAN主要包括四个部分:浅层特征提取、Residual in Residual(RIR)深度特征提取、上采样和重建部分。
本文的重心放在RIR部分,其他部分和EDSR和RDN基本是一样的,所以不多做介绍。
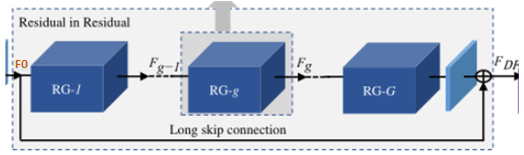
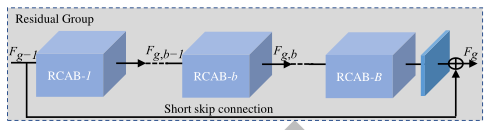
RIR部分总体结构:RIR由RG作为基础模块,由一个长跳跃连接LSC的多个残差群组RG组成。每个RG包含一些具有短跳跃连接SSC的通道残差块RCAB。每个通道注意力残差块RCAB由简单残差块BN和通道注意力机制CA组成。
-
先看第一层(最外层):
RIR由RG作为基础模块,由一个长跳跃连接LSC的G个残差群组RG组成。
长跳跃连接(LSC),能够稳定超深网络的训练,还能简化RGs之间的信息流,而且将浅层信息和深层信息相融合,增强图像信息,减少信息丢失。
-
第二层:每个
RG包含一条短跳跃连接SSC和B个通道残差块RCAB。
短跳跃连接(SSC),能够融合不同层级的局部特征信息。
-
在讲第三层之前先介绍一下通道注意力机制CA,因为在最内层结构中用到了。
不同通道包含的特征信息是不同的,所以需要分配给每个通道不同的权重,让网络更加的关注一些包含重要信息的通道,于是引入了注意力机制。
使用全局平均池化将每个通道的全局空间信息转化为通道描述符(一个常数,其实就是每个通道一个权重值)。
先将每个通道的特征经过全局池化转化为一个常数,再经过卷积1( W D W_D WD)+ReLU+卷积2( W U W_U WU)+sigmoid得到最终的权重值s。
卷积1将通道数缩小到 C r \frac{C}{r} rC,卷积2将通道数放大回C。最后得到的权重s与原本的特征x相乘,得到权重分配后的特征。
CA通过关注通道之间的相互依赖性,自适应地重新分配通道特征的权重.

-
第三层:每个通道注意力残差块
RCAB由简单残差块BN和通道注意力机制CA组成。(最内层)
普通残差块由卷积+ReLU+卷积层构成,串联一个通道注意力机制CA,还有一条跳跃连接。

再复习一下RCAN结构:浅层特征提取、Residual in Residual(RIR)深度特征提取、上采样和重建部分。RIR由RG作为基础模块,由一个长跳跃连接LSC的多个残差群组RG组成。每个RG包含一些具有短跳跃连接SSC的通道残差块RCAB。每个通道注意力残差块RCAB由简单残差块BN和通道注意力机制CA组成。
总结:这篇文章提出的网络深度非常的深,一般很深的网络都难以训练,作者通过嵌套多个块结构和使用长短跳跃连接增加网络训练的稳定性,简化信息流。文章还有一个特点就是提出通道注意力机制,为不同通道分配不同的权重值,优化了网络的性能。
SRLUT
SRLUT: Practical Single-Image Super-Resolution Using Look-Up Table 【CVPR2021】
这篇文章是首次将查表法引入SR领域。将SR网络训练好的缩放像素值存在表中,在测试阶段只需要在表中查找对应值,就能完成图像重建任务。测试阶段可以脱离CNN网络。由于该方法不需要大量的浮点运算,因此可以非常快速地执行。

SR_LUT的整体结构为:训练网络 - 存表 - 测试(读表) (重点部分在于存表和读表)
一张图像放大r倍,可以看成是每个像素放大r倍。文章就是基于这种思想设计的,但每个像素放大后是怎样的,由周围的像素(感受野)来决定。
训练网络: 常规的多个卷积层,获得一个LR到HR的全图映射。
存表:
- 给定感受野大小,使用前面训练好的映射来获取该感受野对应的放大后的对应区域像素值,存到查找表中。比如说给定2×2的感受野。那对应这个区域大小一共有 25 5 4 255^4 2554种像素的排列可能。也就是说,这个像素周围环境一定是这 25 5 4 255^4 2554中的一种。
每一种像素的排列都要存到查找表中,这样以后不论碰到怎么样排列的像素我们都可以根据查找表恢复重建后的像素区域。所以表中一共需要存有 25 5 n 255^n 255n行。 n n n是指定的感受野大小。 放大后对应图像区域仅与放大倍数r有关。给定放大倍数 r r r,每个像素放大后的对应区域大小应该是 r × r r×r r×r。感受野大小是赋予每个像素的,是用来形容这个像素周围环境的,真正的主体还是该像素,所以放大后得到 r × r r×r r×r大小。- 所以整个查找表的存储量为: 25 5 n × r 2 × 8 b i t \bm{255^n \times r^2 \times 8bit} 255n×r2×8bit. (每个像素占8bit内存)
查表: 对图中每个像素位置扩展为感受野的大小,然后在查找表中找到对应的区域值,取出来作为重建块。
以上是常规的网络,但是考虑到 25 5 n 255^n 255n 行,内存消耗太多了。所以作者想出一个办法,提出了sampled-LUT变体:将255种像素值下采样,减少查找表所占的内存。采样间隔为 2 4 2^4 24 ,将输入空间划分为{ 0 , 16 , 32 , 48 , 64 , 80 , 96 , 112 , 128 , 144 , 160 , 176 , 192 , 208 , 224 , 240 , 255 }一共17个采样点。于是 25 5 n 255^n 255n种可能就下降到了 1 7 n 17^n 17n,极大减小了存储量。但这也带来了一个问题,在查表时输入图片的像素如果是非采样点(小数),直接取其最近的采样点值代替的话,图像会损失大量细节,重建效果会非常差。于是在该部分,作者提出了各种对应感受野的插值算法。
总结:这篇文章最主要的优点就是速度快,因为测试阶段脱离CNN,直接读表操作。因为脱离了CNN,所以该网络可以用于手机端,性能方面也有着不错的表现。这种思想也是蛮新颖的。
ESPCN
ESPCN:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
这篇文章提出了一种新的上采样方式:亚像素卷积(PixelShuffle),对于当时SR任务的计算速度和重建效果都有不错的提升。

这篇文章是一种SISR,但最值得我们学习的是网络的最后一层亚像素卷积层也就是Pixel-Shuffle,上采样方法。
亚像素卷积层一般放在网络的最后一层,不需要额外的计算量。
其实亚像素卷积层和SRLUT中的核心思想是一样的,一张图像放大r倍,就相当于每个像素都放大r倍。
在网络倒数第二层卷积过程输出通道数为 r 2 r^2 r2 与原图同样大小的特征图像,然后经过亚像素卷积层周期性排列,得到 w × r , h × r w×r,h×r w×r,h×r重建图像。
如图中,倒数第二层红色椭圆圈住的九个特征(放大倍数为3)排列后组成箭头所指的最后一层小方框,这就是原图中框住的像素经过网络构成的重建块。这九个像素刚好使原像素的长宽各放大了三倍。
需要注意的是亚像素卷积层虽然有卷积二字,但其实没有进行运算,只是抽取特征然后进行简单排列。
总结:这篇文章的训练网络不复杂,精髓在于上采样的方式,不需要卷积,甚至不需要运算,简单的周期性排列,极大减少了运算复杂度,效果也很不错,在很多实验中超过了基于卷积的上采样。基于这篇文章作者还继续探索提出了下面这篇文章VESPCN,利用时间信息来做视频的重建工作。
VESPCN
VESPCN: Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation
本文提出的VESPCN模型由两方面组成:时序空间网络和运动补偿机制。文章的关键就是怎么利用好时间信息。

VESPCN主要由Motion-Estimation网络和Spatio-Temporal网络组成。(对齐+融合)
运动补偿网络: 以STN网络为基础,预测出前后帧的像素值。
时序空间网络: Spatio-Temporal网络是以ESPCN为基础的SR网络,其主要利用亚像素卷积层来进行上采样,此外该模块需要结合early fusion、slow fusion或者3D卷积来将时间信息加入进来。
由于STN网络本身就是可导的,因此整个运动补偿+时序空间网络的训练是一个端对端的训练。VESPCN中整个运动补偿网络在VSR中本质就是个时间对齐网络,其基于Flow-based方法,属于Image-wise。
事实上没有运动补偿模块,仅靠时序空间网络,也能够实现比较好的重建性能,但运动补偿使得前后帧内容上更加对齐增强了相关性,在时间上更连续。
网络结构:
将多帧相邻图像通过基于STN的运动补偿模块对齐到参考帧,再输入以ESPCN为基础的时序空间网络将时间信息融合提取特征,最后使用亚像素卷积层上采样完成SR重建。
分解开来:
- 输入三帧图像,当前帧 I t L R I_t^{LR} ItLR作为参考帧,前后两帧作为支持帧,前一帧 I t − 1 L R I_{t-1}^{LR} It−1LR和后一帧 I t + 1 L R I_{t+1}^{LR} It+1LR分别与当前帧 I t L R I_t^{LR} ItLR做一个运动补偿得到两张warp后的图像 I ’ t − 1 L R I’_{t-1}^{LR} I’t−1LR和 I ’ t + 1 L R I’_{t+1}^{LR} I’t+1LR。
这个过程的目的是使前一帧 I t − 1 L R I_{t-1}^{LR} It−1LR尽量变换到当前帧 I t L R I_t^{LR} ItLR的位置。当然后一帧也是相同。这也就是前面一直说的对齐。把三张图像减少偏移,尽量保持一致,这样在内容上有更多的相关性,时间上也更加连续。因为支持帧不可能变换到与参考帧完全一样的,还是会有所差别,只是差别变小了,可以看成是两张图中间插入新的一帧,所以运动的连贯性被大大加强了。图中的ME模块是以STN为基础的一个加入时间元素的变体。
- 将得到的三张warp后更加相近的图像输入时序空间网络中进行融合,其实就是结合三张图像一起
提取特征,最后使用亚像素卷积层Pixel-Shuffle上采样重建图像输出 I t S R I_t^{SR} ItSR。
这个融合的过程有三种方式:early fusion、slow fusion、 3D卷积。最简单的早期融合其实就是直接在时间维度上拼接三张图像,然后一起提取特征。融合部分其实是指用怎样的方式去提取特征。
总结:视频重建任务就是在单图像SR基础上加入时间信息,那么怎么利用时间信息,就是其中的关键。对齐多帧图像和融合多帧图像都是为了能够更好的提取时间信息。
未完待续~
最后祝各位科研顺利,身体健康,万事胜意~