作者只提供了单路摄像头的解决方法,我要实现多路摄像头
放两张效果图,第一张是我弄了6个不同的视频,第二张由于缺乏测试摄像头,于是我就把一个摄像头取6次
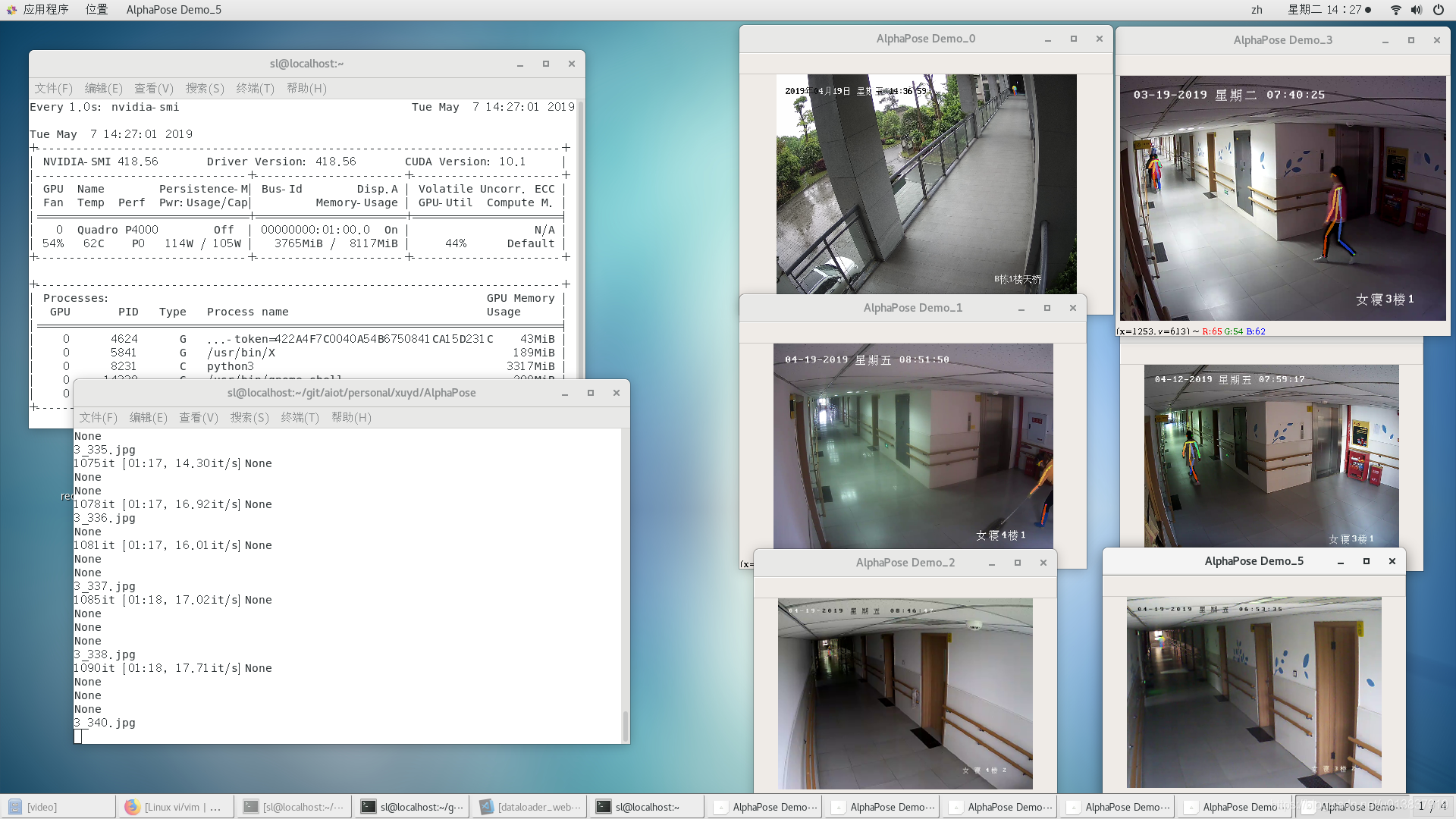
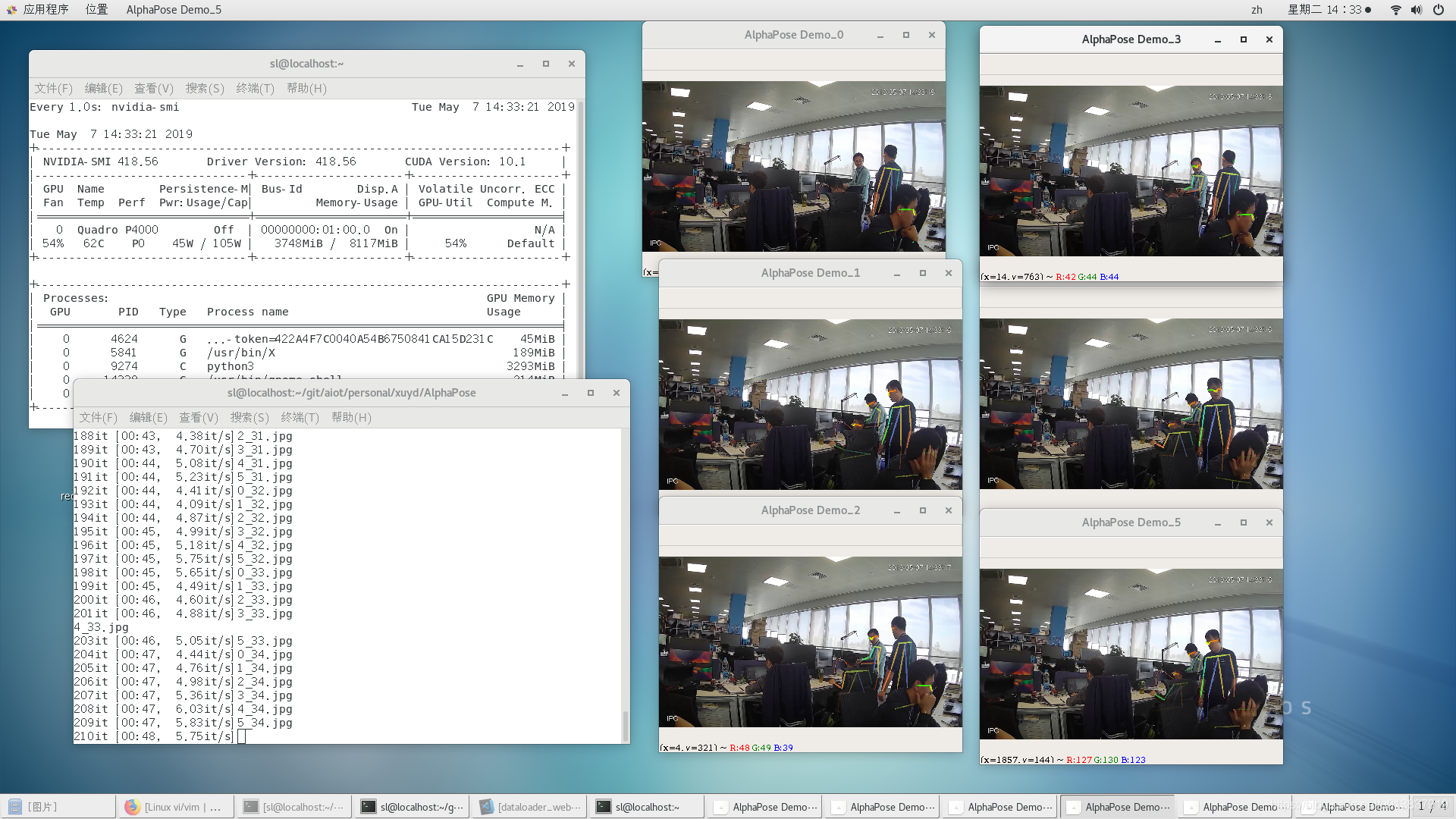
我做了以下尝试:
1.把多路信号放到一个列表,然后循环取每一路信号,放到一个batch里,送给模型识别,当然,这里没有封装,你也可以把地址放到opt.py里
url_dir = ['1', '2',‘3’,‘4’,'5','6']
lushu = len(url_dir) for
n,url in enumerate(url_dir):
locals()['stream_' + str(n)] = cv2.VideoCapture(url)
2.中间直接利用作者的DetectionLoader得到数据塞进DetectionProcessor,发现只能识别两路信号(第一路和最后一路)。这个让我觉得很奇怪,于是打印每一个步骤的列表信息,发现在DetectionLoader结束的那个for循环结束,都能把多路信号的识别结果塞进self.Q,但是一结束循环,Q里就只剩一路信号了,而且后面的每一步里,都只有这一路信号,更奇怪的是,即使只有一路信号,每次识别的结果却是两路信号。最终的解决方案是把DetectionLoader和DetectionProcessor内容合并,这样就可以看到Q里有多路信号了。
for k in range(len(orig_img)):
boxes_k = boxes[dets[:,0]==k]
if isinstance(boxes_k, int) or boxes_k.shape[0] == 0:
if self.Q.full():
time.sleep(2)
self.Q.put((orig_img[k], im_name[k],
None, None, None, None, None))
continue
inps = torch.zeros(boxes_k.size(0), 3, opt.inputResH,
opt.inputResW)
pt1 = torch.zeros(boxes_k.size(0), 2)
pt2 = torch.zeros(boxes_k.size(0), 2)
if self.Q.full():
time.sleep(2)
inp = im_to_torch(cv2.cvtColor(orig_img[k], cv2.COLOR_BGR2RGB))
inps, pt1, pt2 = crop_from_dets(inp, boxes_k, inps, pt1, pt2)
self.Q.put((inps, orig_img[k], im_name[k], boxes_k,
scores[dets[:,0]==k], pt1, pt2))
3.考虑到GPU的识别速度,我这边用的是P4000显卡,性能介于1060和1070之间,所以只能多帧取一帧来解决识别速度问题。
if num_frames % 25 == 0:
(grabbed, frame) = locals()['stream_' + str(n)].read()
4.最后每一路得出的结果按名字分成各路信号显示出来
pic_name = im_name.split('_')[0]
if boxes is None:
if opt.save_img or opt.save_video or opt.vis:
img = orig_img
if opt.vis:
# print('none')
# print('im_name='+str(im_name))
cv2.namedWindow('AlphaPose Demo_{}'.format(pic_name),
cv2.WINDOW_NORMAL)
cv2.imshow("AlphaPose Demo_{}".format(pic_name), img)
cv2.waitKey(30)
5.webcam_demo.py的代码只要把49/50行改写成一行代码
det_processor = DetectionLoader(data_loader, batchSize=args.detbatch).start()
以及79行的读取顺序改成跟你匹配的
(orig_img, im_name, boxes, scores, inps, pt1, pt2) = det_processor.read()
以下是完整的dataloader_webcam.py的代码(import就不加上了,都没改动)
class WebcamLoader:
def __init__(self, webcam, batchSize=1, queueSize=0):
# initialize the file video stream along with the boolean
# used to indicate if the thread should be stopped or not
# self.stream = cv2.VideoCapture(webcam)
# # self.stream.set(cv2.CAP_PROP_FPS,10)
# assert self.stream.isOpened(), 'Cannot capture source'
self.stopped = False
# initialize the queue used to store frames read from
# the video file
self.batchSize = batchSize
self.Q = LifoQueue(maxsize=queueSize)
def start(self):
# start a thread to read frames from the file video stream
t= Thread(target=self.update, args=())
t.daemon = True
t.start()
return self
def update(self):
# keep looping infinitely
num_frames = 0
i = 0
url_dir = ['1', '2',‘3’,‘4’,'5','6']
lushu = len(url_dir)
for n,url in enumerate(url_dir):
locals()['stream_' + str(n)] = cv2.VideoCapture(url)
assert locals()['stream_' + str(n)].isOpened(), 'Cannot capture source'
while True:
# otherwise, ensure the queue has room in it
if not self.Q.full():
img = []
orig_img = []
im_name = []
im_dim_list = []
num_frames += 1
for n,url in enumerate(url_dir):
for k in range(self.batchSize):
(grabbed, frame) = locals()['stream_' + str(n)].read()
if num_frames % 25 == 0:
# if the `grabbed` boolean is `False`, then we have
# reached the end of the video file
if not grabbed:
self.stop()
return
inp_dim = int(opt.inp_dim)
img_k, orig_img_k, im_dim_list_k = prep_frame(frame, inp_dim)
img.append(img_k)
orig_img.append(orig_img_k)
im_name.append('{}_{}.jpg'.format(n,i))
im_dim_list.append(im_dim_list_k)
if len(img) !=0:
# print(len(img))
with torch.no_grad():
# Human Detection
img = torch.cat(img)
im_dim_list = torch.FloatTensor(im_dim_list).repeat(1,2)
self.Q.put((img, orig_img, im_name, im_dim_list))
i = i+1
# print(self.Q.get()[2])
else:
with self.Q.mutex:
self.Q.queue.clear()
def getitem(self):
# return next frame in the queue
return self.Q.get()
def videoinfo(self):
# indicate the video info
fourcc=int(self.stream.get(cv2.CAP_PROP_FOURCC))
fps=self.stream.get(cv2.CAP_PROP_FPS)
frameSize=(int(self.stream.get(cv2.CAP_PROP_FRAME_WIDTH)),int(self.stream.get(cv2.CAP_PROP_FRAME_HEIGHT)))
return (fourcc,fps,frameSize)
def len(self):
# return queue size
return self.Q.qsize()
def stop(self):
# indicate that the thread should be stopped
self.stopped = True
class DetectionLoader:
def __init__(self, dataloder, batchSize=1, queueSize=0):
# initialize the file video stream along with the boolean
# used to indicate if the thread should be stopped or not
self.det_model = Darknet("yolo/cfg/yolov3-spp.cfg")
self.det_model.load_weights('models/yolo/yolov3-spp.weights')
self.det_model.net_info['height'] = opt.inp_dim
self.det_inp_dim = int(self.det_model.net_info['height'])
assert self.det_inp_dim % 32 == 0
assert self.det_inp_dim > 32
self.det_model.cuda()
self.det_model.eval()
self.stopped = False
self.dataloder = dataloder
self.batchSize = batchSize
# initialize the queue used to store frames read from
# the video file
self.Q = LifoQueue(maxsize=queueSize)
def start(self):
# start a thread to read frames from the file video stream
t = Thread(target=self.update, args=())
t.daemon = True
t.start()
return self
def update(self):
# keep looping the whole dataset
while True:
img, orig_img, im_name, im_dim_list = self.dataloder.getitem()
with self.dataloder.Q.mutex:
self.dataloder.Q.queue.clear()
with torch.no_grad():
# Human Detection
img = img.cuda()
prediction = self.det_model(img, CUDA=True)
# print(len(prediction))
# NMS process
dets = dynamic_write_results(prediction, opt.confidence,
opt.num_classes, nms=True, nms_conf=opt.nms_thesh)
if isinstance(dets, int) or dets.shape[0] == 0:
for k in range(len(orig_img)):
if self.Q.full():
time.sleep(2)
self.Q.put((orig_img[k], im_name[k], None, None, None, None, None))
continue
dets = dets.cpu()
im_dim_list = torch.index_select(im_dim_list,0, dets[:, 0].long())
scaling_factor = torch.min(self.det_inp_dim / im_dim_list, 1)[0].view(-1, 1)
# coordinate transfer
dets[:, [1, 3]] -= (self.det_inp_dim - scaling_factor * im_dim_list[:, 0].view(-1, 1)) / 2
dets[:, [2, 4]] -= (self.det_inp_dim - scaling_factor * im_dim_list[:, 1].view(-1, 1)) / 2
dets[:, 1:5] /= scaling_factor
# print('dets.shape='+str(dets.shape))
for j in range(dets.shape[0]):
dets[j, [1, 3]] = torch.clamp(dets[j, [1, 3]], 0.0, im_dim_list[j, 0])
dets[j, [2, 4]] = torch.clamp(dets[j, [2, 4]], 0.0, im_dim_list[j, 1])
boxes = dets[:, 1:5]
scores = dets[:, 5:6]
for k in range(len(orig_img)):
boxes_k = boxes[dets[:,0]==k]
if isinstance(boxes_k, int) or boxes_k.shape[0] == 0:
if self.Q.full():
time.sleep(2)
self.Q.put((orig_img[k], im_name[k], None, None, None, None, None))
continue
inps = torch.zeros(boxes_k.size(0), 3, opt.inputResH, opt.inputResW)
pt1 = torch.zeros(boxes_k.size(0), 2)
pt2 = torch.zeros(boxes_k.size(0), 2)
if self.Q.full():
time.sleep(2)
inp = im_to_torch(cv2.cvtColor(orig_img[k], cv2.COLOR_BGR2RGB))
inps, pt1, pt2 = crop_from_dets(inp, boxes_k, inps, pt1, pt2)
self.Q.put((orig_img[k], im_name[k], boxes_k, scores[dets[:,0]==k], inps, pt1, pt2))
def read(self):
# return next frame in the queue
return self.Q.get()
def len(self):
# return queue len
return self.Q.qsize()
class DataWriter:
def __init__(self, save_video=False,
savepath='examples/res/1.avi', fourcc=cv2.VideoWriter_fourcc(*'XVID'), fps=25, frameSize=(640,480),
queueSize=1024):
if save_video:
# initialize the file video stream along with the boolean
# used to indicate if the thread should be stopped or not
self.stream = cv2.VideoWriter(savepath, fourcc, fps, frameSize)
assert self.stream.isOpened(), 'Cannot open video for writing'
self.save_video = save_video
self.stopped = False
self.final_result = []
# initialize the queue used to store frames read from
# the video file
self.Q = Queue(maxsize=queueSize)
if opt.save_img:
if not os.path.exists(opt.outputpath + '/vis'):
os.mkdir(opt.outputpath + '/vis')
def start(self):
# start a thread to read frames from the file video stream
t = Thread(target=self.update, args=())
t.daemon = True
t.start()
return self
def update(self):
# keep looping infinitely
# i = 0
while True:
# if the thread indicator variable is set, stop the
# thread
if self.stopped:
if self.save_video:
self.stream.release()
return
# otherwise, ensure the queue is not empty
if not self.Q.empty():
(boxes, scores, hm_data, pt1, pt2, orig_img, im_name) = self.Q.get()
orig_img = np.array(orig_img, dtype=np.uint8)
pic_name = im_name.split('_')[0]
if boxes is None:
if opt.save_img or opt.save_video or opt.vis:
img = orig_img
if opt.vis:
cv2.namedWindow('AlphaPose Demo_{}'.format(pic_name), cv2.WINDOW_NORMAL)
cv2.imshow("AlphaPose Demo_{}".format(pic_name), img)
cv2.waitKey(30)
if opt.save_img:
cv2.imwrite(os.path.join(opt.outputpath, 'vis', im_name), img)
if opt.save_video:
self.stream.write(img)
else:
# location prediction (n, kp, 2) | score prediction (n, kp, 1)
preds_hm, preds_img, preds_scores = getPrediction(
hm_data, pt1, pt2, opt.inputResH, opt.inputResW, opt.outputResH, opt.outputResW)
result = pose_nms(boxes, scores, preds_img, preds_scores)
result = {
'imgname': im_name,
'result': result
}
self.final_result.append(result)
if opt.save_img or opt.save_video or opt.vis:
img = vis_frame(orig_img, result)
if opt.vis:
# print('im_name='+str(im_name))
cv2.namedWindow('AlphaPose Demo_{}'.format(pic_name), cv2.WINDOW_NORMAL)
cv2.imshow("AlphaPose Demo_{}".format(pic_name), img)
cv2.waitKey(30)
if opt.save_img:
cv2.imwrite(os.path.join(opt.outputpath, 'vis', im_name), img)
if opt.save_video:
self.stream.write(img)
else:
time.sleep(0.1)
def running(self):
# indicate that the thread is still running
time.sleep(0.2)
return not self.Q.empty()
def save(self, boxes, scores, hm_data, pt1, pt2, orig_img, im_name):
# save next frame in the queue
self.Q.put((boxes, scores, hm_data, pt1, pt2, orig_img, im_name))
def stop(self):
# indicate that the thread should be stopped
self.stopped = True
time.sleep(0.2)
def results(self):
# return final result
return self.final_result
def len(self):
# return queue len
return self.Q.qsize()
class Mscoco(data.Dataset):
def __init__(self, train=True, sigma=1,
scale_factor=(0.2, 0.3), rot_factor=40, label_type='Gaussian'):
self.img_folder = '../data/coco/images' # root image folders
self.is_train = train # training set or test set
self.inputResH = opt.inputResH
self.inputResW = opt.inputResW
self.outputResH = opt.outputResH
self.outputResW = opt.outputResW
self.sigma = sigma
self.scale_factor = scale_factor
self.rot_factor = rot_factor
self.label_type = label_type
self.nJoints_coco = 17
self.nJoints_mpii = 16
self.nJoints = 33
self.accIdxs = (1, 2, 3, 4, 5, 6, 7, 8,
9, 10, 11, 12, 13, 14, 15, 16, 17)
self.flipRef = ((2, 3), (4, 5), (6, 7),
(8, 9), (10, 11), (12, 13),
(14, 15), (16, 17))
def __getitem__(self, index):
pass
def __len__(self):
pass
def crop_from_dets(img, boxes, inps, pt1, pt2):
'''
Crop human from origin image according to Dectecion Results
'''
imght = img.size(1)
imgwidth = img.size(2)
tmp_img = img
tmp_img[0].add_(-0.406)
tmp_img[1].add_(-0.457)
tmp_img[2].add_(-0.480)
for i, box in enumerate(boxes):
upLeft = torch.Tensor(
(float(box[0]), float(box[1])))
bottomRight = torch.Tensor(
(float(box[2]), float(box[3])))
ht = bottomRight[1] - upLeft[1]
width = bottomRight[0] - upLeft[0]
if width > 100:
scaleRate = 0.2
else:
scaleRate = 0.3
upLeft[0] = max(0, upLeft[0] - width * scaleRate / 2)
upLeft[1] = max(0, upLeft[1] - ht * scaleRate / 2)
bottomRight[0] = max(
min(imgwidth - 1, bottomRight[0] + width * scaleRate / 2), upLeft[0] + 5)
bottomRight[1] = max(
min(imght - 1, bottomRight[1] + ht * scaleRate / 2), upLeft[1] + 5)
inps[i] = cropBox(tmp_img.clone(), upLeft, bottomRight, opt.inputResH, opt.inputResW)
pt1[i] = upLeft
pt2[i] = bottomRight
return inps, pt1, pt2