一、Nodejs 模块机制
首先在开始之前先简单介绍一下 Nodejs 里面的模块引入机制。
1. Node.js 核心模块
例如 fs、net、path 这样的模块,代码在 nodejs 源码(lib目录下)中,通过 API 来暴露给开发者,这些核心模块都有自己的预留标识,当 require() 函数传入的标识和核心模块相同时,就会返回核心模块的 API。
const fs = require('fs');2. 文件模块
文件模块则分为两种方式:
2.1 第三方模块
这些模块以 Nodejs 依赖包的形式存在。例如一些常见的 npm 包 axios、webpack等等。
Nodejs require 这一类模块的话是会去找该模块项目下面的 package.json 文件,如果 package.json 文件合法,则会解析 main 字段的那个路径。
当 require() 函数中传入一个第三方模块,例如 axios,那么 Nodejs 对于寻找这个 axios 目录的路径的过程是这样的:
- 去当前文件目录下 node_modules 中找
- 没找到就去当前文件父目录下的 node_modules 中找
- 还没找到就再往上一层
- 还没找到就重复3,直到找到符合的模块或者根目录为止
以一个 monorepo 项目为例子,一般在 monorepo 中一些包管理工具例如 yarn workspace 下会把一些依赖提升到外层的目录中来,那么子项目就是这样去寻找外层的依赖的:
node_modules -> find axios here
packages
package-a
node_modules -> axios not found
index.js -> const axios = require('axios');2.2 项目模块
在项目中执行 require() 来载入 "/"、"./" 或者 "../" 开头的模块就是项目模块。这里根据相对路径或者绝对路径所指向的模块去进行加载。通过加载模块的时候如果不指定后缀名,Nodejs 则会通过枚举去尝试后缀名。后缀名依次是 .js 、.json 和 .node ,其中 .node后缀的文件就是 C++ 拓展。
例如目录下有个 addon.node 文件,我们可以 require 去加载(nodejs 是默认支持的):
const addon = require('./addon');二、什么是 Nodejs C++ 拓展
本质
Node.js 是基于 C++ 开发的(底层用 chrome v8 做 js 引擎 && libuv 完成事件循环机制),因此它的所有底层头文件暴露的 API 也都是适用于 C++ 的。
上一节中提到 nodejs 模块寻径的时候会默认找 .node 为后缀名的模块,实际上这是个 C++ 模块的二进制文件,即编译好之后的 C++ 模块,本质上是个动态链接库。例如 (Windows dll/Linux so/Unix dylib)
在 Nodejs 在调用原生的 C++ 函数和调用 C++ 拓展函数的本质区别在于前者的代码会直接编译成 Node.js 可执行文件,而后者则是在动态链接库中。
C++ 拓展加载方式
C++ 拓展的加载过程源码可以参考:
https://github.com/nodejs/node/blob/master/src/node_binding.cc#L415
通过 uv_dlopen 这个方法去加载动态链接库文件来完成
C++ 拓展模块(.node二进制链接库文件)的具体加载过程:
- 在用户首次执行 require 时使用 uv_dlopen 来加载cpp addon 的 .node 链接库文件
- 链接库内部把模块注册函数赋值给 mp
- 将执行 require 时传入的 module 和 exports 两个对象传入模块注册函数(mp 实例)进行导出
相关加载代码参考:
void DLOpen(const FunctionCallbackInfo<Value>& args) {
Environment* env = Environment::GetCurrent(args);
uv_lib_t lib;
...
Local<Object> module = args[0]->ToObject(env->isolate());
node::Utf8Value filename(env->isolate(), args[1]);
// 使用 uv_dlopen 函数打开 .node 动态链接库
const bool is_dlopen_error = uv_dlopen(*filename, &lib);
// 将加载出来的动态链接库的句柄转移给 node_module 的实例对象上来
node_module* const mp = modpending;
modpending = nullptr;
...
mp->nm_dso_handle = lib.handle;
mp->nm_link = modlist_addon;
modlist_addon = mp;
Local<String> exports_string = env->exports_string();
// exports_string 其实就是 `"exports"`
// 这句的意思是 `exports = module.exports`
Local<Object> exports = module->Get(exports_string)->ToObject(env->isolate());
// exports 和 module 传给模块注册函数导出出去
if (mp->nm_context_register_func != nullptr) {
mp->nm_context_register_func(exports, module, env->context(), mp->nm_priv);
} else if (mp->nm_register_func != nullptr) {
mp->nm_register_func(exports, module, mp->nm_priv);
} else {
uv_dlclose(&lib);
env->ThrowError("Module has no declared entry point.");
return;
}
}

C++ 拓展的一些优点以及缺点
- C++ 比 js 高效
- 相同意思的代码,在 js 解释器中执行 js 代码效率比直接执行一个 Cpp 编译好后的二进制文件要低(后续会用 demo 验证)
- 一些已有的 C++ 轮子可以拿来用
- 例如一些常用的算法市面上只有 Cpp 实现且代码太过复杂,用 JS 实现不现实(例如 Bling Hashes 字符串 hash 摘要算法、Open SDK)
- 一些系统底层 API 或者 V8 API 没法通过 js 调用,可以封装一个 cpp addon 出来(例如: 缓解Node.js因生成heap snapshot导致进程退出的一种办法)
缺点:
- 开发维护成本比较高,需要掌握一门 native 语言
- 增加了 native addon 的编译流程以及拓展发布流程
三、发展历史
这里介绍几种开发 Nodejs 拓展的方式:
原始方式
这种方式比较暴力,直接使用 nodejs 提供的原生模块来开发头文件,例如在 C++ 代码中直接使用 Nodejs 相关的各种 API 以及 V8 的各种 API。需要开发者对 nodejs 以及 v8 文档比较熟悉。而且随着相关 API 迭代导致无法跨版本去进行使用。
NAN
Native Abstractions for Node.js,即 Node.js 原生模块抽象接口集
本质上是一堆宏判断,在上层针对 libuv 和 v8 的 API 做了一些兼容性的处理,对用户侧而言是比较稳定的 API 使用,缺点是不符合 ABI(二进制应用接口) 稳定,对于不同版本的 Node.js 每次即使每次重新安装了 node_modules 之后还需要对 C++ 代码进行重新编译以适应不同版本的Nodejs,即代码只需要编写一次,但需要使用者去到处编译。
N-API
N-API 相比于 NAN 则是将 Nodejs 中底层所有的数据结构都黑盒处理了,抽象成 N-API 中的接口。
不同版本的 Node.js 去使用这些接口,都是稳定的、ABI 化的。使得在不同的 Node.js 版本下,代码只需要编译一次就可以直接使用,不需要去重新进行编译。在 Nodev8.x 时发布。
- 以 C 语言风格提供稳定的 ABI 接口
- 消除 Node.js 版本差异
- 消除 js 引擎差异(例如 Chrome v8、Microsoft ChakraCore 等)
Node-Addon-API
目前 Node.js 社区推崇的写 Cpp addon 的方式,实际上是基于 N-API 的一层 C++ 封装(本质上还是 N-API)。
支持的最早版本是 Nodev10.x(在 v10.x 之后逐步稳定)。
- API 更简单
- 文档良心,编写和测试都更方便
- 官方维护
今天介绍的也是这种方式来编写 C++ 拓展。
四、开发样例demo
环境安装
- 安装 node-gyp
npm i node-gyp -gnode-gyp 这里是个 nodejs 官方维护的 C++ 的构建工具,几乎所有的 Nodejs C++ 拓展都是由它来构建。基于 GYP (generate your project,谷歌的一个构建工具)进行工作,简单来说,可以想象成面向 C++ 的 Webpack。
作用是将 C++ 文件编译成二进制文件(即前面提到的后缀名为 .node 的文件)。
- node-gyp 附带的一些依赖环境(参考官方文档,以 macos 为例子)
- Python(一般 unix 系统都会自带)
- Xcode
同时 node-gyp 也需要在项目下有个 binding.gyp 的文件去进行配置,写法上和 json 类似,不过可以在里面写注释。
例如:
{
"targets": [
{
# 编译之后的拓展文件名称,例如这里就是 addon.node
"target_name": "addon",
# 待编译的原 cpp 文件
"sources": [ "src/addon.cpp" ]
}
]
}简单的demo
这一节主要是通过一些简单的 demo 来入门 C++ Addon 的开发:
Hello World
在做好一些准备工作之后,我们可以先来利用 node-addon-api 开发一个简单的 helloworld
- 初始化
mkdir hello-world && cd hello-world
npm init -y
# 安装 node-addon-api 依赖
npm i node-addon-api
# 新建一个 cpp 文件 && js 文件
touch addon.cpp index.js- 配置 binding.gyp
{
"targets": [
{
# 编译出来的 xxx.node 文件名称,这里是 addon.node
"target_name": "addon",
# 被编译的 cpp 源文件
"sources": [
"addon.cpp"
],
# 为了简便,忽略掉编译过程中的一些报错
"cflags!": [ "-fno-exceptions"],
"cflags_cc!": ["-fno-exceptions"],
# cpp 文件调用 n-api 的头文件的时候能找到对应的目录
# 增加一个头文件搜索路径
"include_dirs": [
"<!@(node -p \"require('node-addon-api').include\")"
],
# 添加一个预编译宏,避免编译的时候并行抛错
'defines': [ 'NAPI_DISABLE_CPP_EXCEPTIONS' ],
}
]
}- 写原生的 cpp 拓展
这里贴两份代码,为了便于去做个区分比较:
原生 Node Cpp Addon 版本:
// 引用 node.js 中的 node.h 头文件
#include<node.h>
namespace demo {
using v8::FunctionCallbackInfo;
using v8::Isolate;
using v8::Local;
using v8::Object;
using v8::String;
using v8::Value;
void Method(const FunctionCallbackInfo<Value>& args) {
// 通过 v8 中的隔离实例(v8的引擎实例,有各种独立的状态, 包括推管理、垃圾回收等)
// 存取 Nodejs 环境的实例
Isolate* isolate = args.GetIsolate();
// 返回一个 v8 的 string 类型,值为 "hello world"
args.GetReturnValue().Set(String::NewFromUtf8(ioslate, "hello world"));
}
void init(Local<Object> exports) {
// nodejs 内部宏,用于导出一个 function
// 这里类似于 exports = { "hello": Method }
NODE_SET_METHOD(exports, "hello", Method);
}
// 来自 nodejs 内部的一个宏: https://github.com/nodejs/node/blob/master/src/node.h#L839
// 用于注册 addon 的回调函数
NODE_MODULE(addon, init);
}
Node-addon-api 版本:
// 引用 node-addon-api 的 头文件
#include<napi.h>
// Napi 这个实际上封装的是 v8 里面的一些数据结构,搭建了一个从 JS 到 V8 的桥梁
// 定义一个返回值为 Napi::String 的 函数
// CallbackInfo 是个回调函数类型 info 里面存的是 JS 调用这个函数时的一些信息
Napi::String Method(const Napi::CallbackInfo& info) {
// env 是个环境变量,提供一些执行上下文的环境
Napi::Env env = info.Env();
// 返回一个构造好的 Napi::String 类型的值
// New是个静态方法,一般第一个参数是当前执行环境的上下变量,第二个是对应的值
// 其他参数不做过多介绍
return Napi::String::New(env, "hello world~");
}
// 导出注册函数
// 这里其实等同于 exports = { hello: Method }
Napi::Object Init(Napi::Env env, Napi::Object exports) {
exports.Set(
Napi::String::New(env, "hello"),
Napi::Function::New(env, Method)
);
return exports;
}
// node-addon-api 中用于注册函数的宏
// hello 为 key, 可以是任意变量
// Init 则会注册的函数
NODE_API_MODULE(hello, Init);
这里代码里面的 Napi:: 命名空间里面的一些类型实际上是对 v8 原生的一些数据结构做了包装,调用的时候更简单,数据结构相关的文档可以参考:https://github.com/nodejs/node-addon-api API 文档那一节。
这里的 Napi 本质上就是 C++ 和 JS 之间的一座相互沟通的桥梁。
这里拆分讲解一下这些函数的作用, Method 函数是我们的一个执行函数,执行该函数会返回一个 "hello world" 的字符串值。
CallbackInfo 对应 v8 里面的 FunctionCallbackInfo 类型(里面有一些函数回调信息,存在 info 这个地址里面),里面包含了 JS 函数调用这个方法的时候需要的一些信息。
- 在 js 代码中调用 cpp addon
我们通过对上面的 cpp 进行进行 node-gyp 的编译,得到一个 build 的目录里面存放的是编译产物,里面会有编译出来的 二进制动态链接文件(后缀名为 .node):
$ node-gyp configure build
# 或者为了更简便一点会直接使用 node-gyp rebuild,这个命令包含了清除缓存并重新打包的功能
$ node-gyo rebuild编译之后我们直接在 js 代码中引入即可:
// hello-world/index.js
const { hello } = require('./build/Release/addon');
console.log(hello());
A + B
在上一节我们讲到了 Napi::CallbackInfo& info info 中会存 JS 调用该函数时的一些上下文信息,因此我们在 js 中给 cpp 函数传参数也可以在 info 中获取到,于是可以写出下面一个简单的 a + b 的 cpp addon demo:
#include<napi.h>
// 这里为了做演示,把 Napi 直接通过 using namespace 声明了
// 只要该文件不被其他的 cpp 文件引用就不会出现 namespace 污染 这里主要为了简洁
using namespace Napi;
// 因为这里可能会遇到抛 error 的情况,因此返回值类型设置为 Value
// Value 包含了 Napi 里面的所有数据结构
Value Add(const CallbackInfo& info) {
Env env = info.Env();
if (info.Length() < 2) {
// 异常处理相关的 API 可以参考
// 不过这里可以看到 cpp 里面抛异常代码很麻烦... 建议这里可以在 js 端就处理好
// https://github.com/nodejs/node-addon-api/blob/main/doc/error_handling.md
TypeError::New(env, "Number of arg wrong").ThrowAsJavaScriptException();
return env.Null();
}
double a = info[0].As<Number>().Doublevalue();
double b = info[1].As<Number>().DoubleValue();
Number num = Number::new(env, a + b);
return num;
}
// exports = { add: Add };
Object Init(Env env, Object exports) {
exports.Set(String::New(env, "add"), Function::new(env, Add));
}
NODE_API_MODULE(addon, Init);
Js 调用只需要:
const { add } = require('./build/Release/addon');
// output is 5.2
console.log(add(2, 3.2));
callback
回调函数也是一样,通过 info 这个也可以拿到,再贴个 cpp addon 的 demo:
// addon.cpp
#include<napi.h>
// 这一节用 namespace 包裹一下,提前声明一些数据结构
// 省得调用的时候一直 Napi::xxx ...
namespace CallBackDemo {
using Napi::Value;
using Napi::CallbackInfo;
using Napi::Env;
using Napi::TypeError;
using Napi::Number;
using Napi::Object;
using Napi::String;
using Napi::Function;
void RunCallBack(const CallbackInfo &info) {
Env env = info.Env();
Function cb = info[0].As<Function>();
cb.Call(env.Global(), { String::New(env, "hello world") } );
}
Object Init(Env env, Object exports) {
return Function::New(env, RunCallback);
}
NODE_API_MODULE(addon, Init);
}
实战 demo
上面简单讲了一些 node native addon 的简单 API 使用,算是做了个简单的入门教学,下面选了个简单的实际 demo 来看一下 node-addon-api 在具体项目中起到的作用:
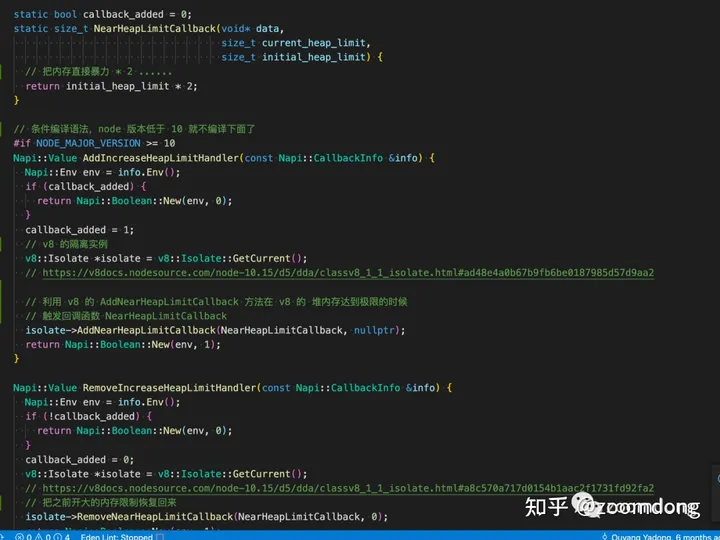
案例展开讲一下,封装了 v8 的 API 用于 debug
参考案例:
缓解Node.js因生成heap snapshot导致进程退出的一种办法26 赞同 · 2 评论文章正在上传…重新上传取消
代码地址:
bytedance/diatgithub.com/bytedance/diat/tree/master/packages/addon正在上传…重新上传取消
主要拓展源码解析部分可以参考:
更多 demo
可以参考:
Nodejs 官方的 addon examples:
https://github.com/nodejs/node-addon-examplesgithub.com/nodejs/node-addon-examples正在上传…重新上传取消
Nodejs 来一打 cpp 拓展随书代码:
https://github.com/XadillaX/nyaa-nodejs-demogithub.com/XadillaX/nyaa-nodejs-demo
五、性能对比
可以通过一个简单的 Demo 去做一下对比:
quickSort (O(nlogn))
我们可以手写个快排分别在 JS 或者 CPP 两边去 run 一下来对比性能:
首先我们的 cpp addon 代码可以这样写:
#include<napi.h>
#include<iostream>
#include<algorithm>
// 快排 时间复杂度 O(nlogn) 空间复杂度 O(1)
void quickSort(int a[], int l, int r) {
if (l >= r) return;
int x = a[(l + r) >> 1], i = l -1, j = r + 1;
while (i < j) {
while (a[++i] < x);
while (a[--j] > x);
if (i < j) {
std::swap(a[i], a[j]);
}
}
quickSort(a, l, j);
quickSort(a, j + 1, r);
}
Napi::Value Main(const Napi::CallbackInfo& info) {
Napi::Env env = info.Env();
Napi::Array arr = info[0].As<Napi::Array>();
int len = arr.Length();
// 存返回值
Napi::Array res = Napi::Array::New(env, len);
// 初始化数组
int* arr2 = new int[len];
// 把 v8 的数据结构转换成 C++ 原生数据结构
for (int i = 0; i < len; i++) {
Napi::Value value = arr[i];
arr2[i] = value.ToNumber().Int64Value();
}
// 运行 快排
quickSort(arr2, 0, len - 1);
// for (int i = 0; i < len; i ++) {
// std::cout << arr2[i] << " ";
// }
// std::cout << std::endl;
// 转回 JS 的数据结构
for (int i = 0; i < len; i ++) {
res[i] = Napi::Number::New(env, arr2[i]);
}
return res;
}
Napi::Object Init(Napi::Env env, Napi::Object exports) {
exports.Set(
Napi::String::New(env, "quicksortCpp"),
Napi::Function::New(env, Main)
);
return exports;
}
NODE_API_MODULE(addon, Init);
JS侧的代码可以这样写:
// 这里使用 bindings 这个库,他会帮我们自动去寻找 addon.node 对应目录
// 不需要再去指定对应的 build 目录了
const { quicksortCpp } = require('bindings')('addon.node');
// 构造一个随机数组出来
const arr = Array.from(new Array(1e3), () => Math.random() * 1e4 | 0);
// 构造两个一样的数组出来
let arr1 = JSON.parse(JSON.stringify(arr));
let arr2 = JSON.parse(JSON.stringify(arr));
console.time('JS');
const solve = (arr) => {
let n = arr.length;
const quickSortJS = (arr, l, r) => {
if (l >= r) {
return;
}
let x = arr[Math.floor((l + r) >> 1)], i = l - 1, j = r + 1;
while (i < j) {
while(arr[++i] < x);
while(arr[--j] > x);
if (i < j) {
[arr[i], arr[j]] = [arr[j], arr[i]];
}
}
quickSortJS(arr, l, j);
quickSortJS(arr, j + 1, r);
}
quickSortJS(arr, 0, n - 1);
}
solve(arr2);
console.timeEnd('JS');
// C++ 直接调用 拓展里面的函数
console.time('C++');
const a = quicksortCpp(arr1);
console.timeEnd('C++');
这里两侧代码基本上从实现上来说都是一模一样的,在实际运行中,通过去修改数组的长度对比两者的效率,我们可以得到如下的数据:
| 数组长度/时间 | 1e2 | 1e3 | 1e4 | 1e5 | 1e6 |
|---|---|---|---|---|---|
| JavaScript | 0.255ms | 4.391ms | 10.810ms | 26.004ms | 116.914ms |
| C++ | 0.065ms | 0.347ms | 2.908ms | 23.637ms | 234.757ms |
那么我们可以看到在数组长度相对而言比较低的时候,C++ Addon 的快排效率是要完爆 JS 的,但随着数组长度的增长,C++ 就呈现一种被完爆的趋势。
导致这种情况的原因是因为 V8 的数据结构与 C++ 里面原生的数据结构转换所带来的消耗:

该图是在 1e5 数据下单独测试 C++ 中快排的时间
1e5 的数据规模下,实际上 cpp 的 quickSort 算法只跑了大概 6.9ms,而算上数据转换的时间,一共就跑了 28.9ms......
随着数据规模的增大这种转换带来的开销就越来越大,因此在这种时候如果使用 C++ 的话,可能会得不偿失。
综上来看,有时候 C++ 写出来的包确实会在性能上稍微高于 Nodejs 的 JS 代码,但如果高出来的这部分性能还比不过 Nodejs 打开并且执行 C++ Addon 所消耗掉的 I/O 时间或者在 v8 数据结构与 C++ 数据结构之前进行转换的所消耗的时间(例如上面的 Case) ,这个时候用 C++ 可能就得不偿失了。
不过一般情况下,针对并非并行 && 计算密集型代码来说,C++ 效率还是会好于 Nodejs 的。
总结
随着 N_API 体系的发展以及 nodejs 开发团队的不断迭代更新,未来开发 native addon 的成本也会越来越低,在一些特定的场景里面(例如需要用到一些 v8 的 API 场景或者 electron + openCV 场景),nodejs addon 可能会变得极其重要,未来使用场景也会不断的提高。