
入门
刚接触区块链世界,希望通过创建您的第一个 NFT 收藏进入该领域?在本文中,我们将通过逐步创建我们的第一个智能合约,使用它来铸造全新的 NFT 集合,最后,将其上架到 NFT 市场,我们可以从我们的数字藏品中获利!
写在开头
在实际编写任何代码之前,我们应该了解几个概念。我将非常简要的介绍它们中的每一个,但是,如果您希望进一步熟悉这些,我还将附上一些外部资源,建议您自行探索。
基本要素
为了简洁起见,我假设如果您正在阅读这篇文章,您已经对区块链有一些了解,并且对 Python 等编程语言有一些基本的了解(这就是我们今天将使用的!)。如果没有,我建议您在继续之前先查看以下资源,因为这将大大减少我们今天继续进行时的困惑:
以太坊和智能合约
以太坊是一个支持智能合约执行的区块链;这些程序位于以太坊区块链上的唯一地址。这些合约实际上是以太坊账户的类型,它们可以像任何其他账户一样接收和发送资金,但是,它们由在将它们部署到区块链时指定的程序逻辑控制。
请注意,以太坊区块链的原生代币称为以太币(表示为 ETH),并且需要拥有该以太币才能促进交易。
有关更多信息,请查看以下内容:
ERC-721:非同质化代币标准
由 ERC-721 标准定义的 NFT 是驻留在区块链上的唯一代币,并与符合该标准的特定智能合约相关联。每个属于智能合约的 NFT 在该合约中都有一个唯一的代币 ID,这样它就可以与集合中的其他代币区分开来。每个 NFT 都可以与其合约地址和代币 ID 之外的其他数据相关联。而我们的目的,这些数据将是对一些数字艺术作品的引用(我们稍后会谈到这一点),当然,它也可能是许多其他数据。
如果您想了解更多信息,请查看这些资源:
ERC-721 非同质代币标准 | ethereum.org
使用 MetaMask 创建我们的第一个加密钱包
为了参与加密世界并与这些区块链交互,我们需要某种接口。许多人选择使用的一个这样的接口是加密钱包,例如 MetaMask。
想要使用,请按照此处的说明进行操作:
请务必仔细按照他们的说明,记住您的助记词。这非常非常重要,因为失去访问权限可能会无法访问钱包,或让其他人控制您的资金。为测试部署创建一个单独的钱包,而不是你保存真实代币的地方!
获取一些测试货币
使用真正的 ETH 可能非常昂贵,当我们学习时,在以太坊主网络上的实验可能有很多。即使在像 Polygon 这样试图抑制以太坊昂贵的交易费用的第 2 层网络上,我们每次想要改变区块链的状态时都需要花费真实的代币。幸运的是,以太坊有一些只需要测试代币的测试网络。
首先,让我们确保我们的 MetaMask 允许我们与这些测试网络进行交互。在 MetaMask 中,单击您的帐户图标,然后单击settings → Advanced → Toggle “Show test networks”切换为开启。我们现在可以在 MetaMask 上看到测试网络。从现在开始,我们将继续使用 Rinkeby 测试网络。
现在让我们在我们的帐户中获取一些测试货币。导航到https://faucets.chain.link/rinkeby。您可能需要将您的 MetaMask 连接到该站点;只需遵循此处提供的步骤操作即可。然后确保网络设置为Ethereum Rinkeby,选择 10 test LINK,0.1 test ETH,并确认您实际上不是机器人。最后,发送请求,您应该很快就会在您的帐户中看到资金。我们现在可以用这个测试币来改变区块链的状态!
使用 Python Brownie SDK 和 Infura 设置我们的项目
为了开始区块链开发,我们将使用 Brownie,这是一个很好的框架。Brownie 将通过使用 Python 脚本部署和与我们的智能合约交互,帮助我们灵活地启动和运行我们的 NFT 项目。除了 Brownie,我们还将使用 Infura,这是一种基础设施即服务产品,可以让我们轻松地与区块链进行交互。
安装 Brownie
继续并按照此处列出的说明进行操作:
请注意,Brownie 的创建者建议使用 pipx,但是也可以使用 pip。
创建一个 Brownie 项目
现在我们已经安装了 Brownie,让我们开始我们的第一个项目。
首先,打开命令行并导航到您想要创建新项目目录的位置。从这里创建项目目录。我们将其称为“NFT-demo”。
mkdir NFT-demo
cd NFT-demo
现在我们可以使用以下命令初始化我们的新项目:
brownie init
现在,在我们的 NFT-demo 目录中,我们应该看到以下子目录:
contracts/: 合约来源interfaces/: 接口来源scripts/: 用于部署和交互的脚本tests/: 用于测试项目的脚本build/:项目数据,例如编译器工件和单元测试结果reports/: 在 Brownie GUI 中使用的 JSON 报告文件
配置项目
除了上述子目录之外,我们还需要 NFT-demo 项目根目录中的两个附加文件:一个环境变量文件,用于隐藏我们的敏感变量,以及一个 brownie-config 文件,用于告诉 Brownie 在哪里可以找到这些变量,以及配置任何依赖项。
.env
从环境变量文件开始,在 NFT-demo 目录中创建一个新文件 .env。首先,包括以下代码:
PRIVATE_KEY=''
WEB3_INFURA_PROJECT_ID=''
PINATA_API_KEY=''
PINATA_API_SECRET=''
ETHERSCAN_TOKEN=''
现在,除了我们的 PRIVATE_KEY 变量之外,我们将把所有内容都留空。现在,请前往您的 MetaMask 账户 → Menu → Account details → Export private key。从这里输入您的 MetaMask 密码并替换第一行,使其现在显示为PRIVATE_KEY=<YOUR_PRIVATE_KEY> 。其余部分,我们慢慢填写。
有关环境变量的更多信息,请查看以下资源:
brownie-config.yaml
现在让我们创建我们的 Brownie 配置文件。在一个名为brownie-config.yaml(同样,在 NFT-demo 目录中)的文件中,输入以下代码:
dotenv: .env
dependencies:
- smartcontractkit/chainlink-brownie-contracts@0.4.0
- OpenZeppelin/openzeppelin-contracts@4.5.0
compiler:
solc:
remappings:
- '@chainlink=smartcontractkit/[email protected]'
- '@openzeppelin=OpenZeppelin/[email protected]'
wallets:
from_key: ${
PRIVATE_KEY}
几个重要的点:
dotenv,告诉 Brownie 在哪里可以找到我们的环境变量- 在高层次上,
dependencies和compiler映射使我们能够轻松地与外部库进行交互(有关更多信息,请参阅下面的资源) wallets,为我们提供了一种以编程方式访问私钥的简单方法,以便我们可以像自己一样与区块链进行交互
使用 Infura 连接到区块链
在编写可以部署到区块链的合约之前,我们需要一种方法来轻松与它们交互,而无需运行我们自己的节点。要开始使用 Infura,请按照此处提供的步骤操作:
一旦有了 Infura 项目设置后,获取项目 ID 并将其添加到我们的.env文件中,第二行现在读取WEB3_INFURA_PROJECT_ID=<YOUR_PROJECT_ID> 。 Brownie 将在后台使用它来将我们连接到区块链网络,因此我们从此不必担心这一点。
我们现在准备开始编写我们的第一个 NFT 智能合约!
编写我们的第一个智能合约
让我们通过在 contracts 子目录中创建一个名为WaterCollection.sol 的文件,这将是我们新的 NFT 集合的合约。
我们的项目目录结构现在应该如下所示:
- NFT-demo
| - build
| - contracts
| - WaterCollection.sol
| - interfaces
| - reports
| - scripts
| - tests
请注意,Solidity 是一种流行的智能合约开发编程语言。如需更深入地了解,请查看他们的文档:
首先,让我们添加以下几行:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
import "@openzeppelin/contracts/token/ERC721/extensions/ERC721URIStorage.sol";
import "@openzeppelin/contracts/token/ERC721/ERC721.sol";
在这里,首先,我们定义一个许可证。暂时不要太担心这一点,只要知道 MIT 许可证本质上意味着我们正在开源我们的合同。
其次,我们正在定义我们的solidity 版本。同样,不要太担心,但如果您对这些版本感到好奇,请查看上面的文档。
最后,我们从 OpenZeppelin 导入合约,它可以被认为是一组可信的智能合约。我们将为我们自己的合约继承这些合约的一些属性。
继承 OpenZeppelin 实现
为了利用 OpenZeppelin 提供的现有实现,我们将创建我们的合约,使其具有 OpenZeppelin 合约的功能。具体来说,我们将使用他们的 ERC721URIStorage 模块,该模块类似于他们的基础 ERC721 模块,增加了通过称为代币 URI 的引用将数据附加到 NFT 的能力。这将使我们能够将 NFT 与我们的艺术品相关联。请在此处阅读有关该模块的更多信息:
更新我们的WaterCollection.sol文件:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
import "@openzeppelin/contracts/token/ERC721/extensions/ERC721URIStorage.sol";
import "@openzeppelin/contracts/token/ERC721/ERC721.sol";
contract WaterCollection is ERC721URIStorage {
uint256 public tokenCounter;
}
我们现在有了 WaterCollection 合约的大纲,它继承 OpenZeppelin 合约。
请注意,我们还添加了一个合约变量 tokenCounter,使我们能够记录我们的合约创建的 NFT 数量。
定义合约构造函数
构造方法允许我们在部署时定义合约的行为。
让我们再次更新我们的WaterCollection.sol文件:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
import "@openzeppelin/contracts/token/ERC721/extensions/ERC721URIStorage.sol";
import "@openzeppelin/contracts/token/ERC721/ERC721.sol";
contract WaterCollection is ERC721URIStorage {
uint256 public tokenCounter;
constructor() public
ERC721("Water Collection", "DRIP")
{
tokenCounter = 0;
}
}
在这里,我们调用 OpenZeppelin ERC721 构造函数,定义其名称为“Water Collection”,其标记符号为“DRIP”。此外,我们将合约的代币计数器设置为 0,因为在部署时,我们还没有创建 NFT。
创建 NFT 的方法
现在让我们定义一个方法,允许我们用我们的合约真正的去创建 NFT。
我们将再次更新合约:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
import "@openzeppelin/contracts/token/ERC721/extensions/ERC721URIStorage.sol";
import "@openzeppelin/contracts/token/ERC721/ERC721.sol";
contract WaterCollection is ERC721URIStorage {
uint256 public tokenCounter;
constructor() public
ERC721("Water Collection", "DRIP")
{
tokenCounter = 0;
}
function createToken(string memory tokenURI)
public returns (bytes32){
require(tokenCounter < 100, "Max number of tokens reached");
uint256 tokenId = tokenCounter;
_safeMint(msg.sender, tokenId);
_setTokenURI(tokenId, tokenURI);
tokenCounter++;
}
}
我们编写了一个将代币 URI 字符串作为参数的方法。让我们回顾一下逻辑。
首先,我们要求此合约最多可以创建 100 个 NFT。这是一种设计选择,不一定需要这样做,但是,在我们的例子中,如果有人尝试创建第 101 个 NFT,他们会收到一条错误消息并且不会创建。
接下来,我们将 token ID 设置为当前 tokenCounter,以便我们可以调用 ERC721的 _safeMint方法和 ERC721URIStorage 的 _setTokenURI方法。
_safeMint方法为我们的合约创建或造“mints”一个新 token,并将其所有者设置为调用 createToken方法的人,其token ID 为tokenCounter.
然后,_setTokenURI方法将该 token 的代币 URI 设置为传递给我们函数的字符串。我们将在稍后讨论这应该是什么。
最后,我们增加 token 计数器以更新集合中的代币数量。
我们的合约现在已经完成并准备好部署了!
让我们运行brownie compile 确保一切正常。我们应该看到一条消息,断言我们的项目已经编译。
将合约部署到测试网的脚本
现在我们的合约已经完成,我们可以自己编写一个 Python 脚本,将其部署到我们选择的区块链上。在我们的项目的子目录scripts中新建一个新文件,叫deploy_water.py,然后编写以下代码调用:
from brownie import WaterCollection, accounts, config
def main():
dev = accounts.add(config['wallets']['from_key'])
WaterCollection.deploy(
{
'from': dev}
)
在这里,我们将通过我们在 brownie-config.yaml 文件中引用的私钥获得的有关帐户的信息存储到 dev 变量中。
有了这个帐户信息,我们让 Brownie 将我们的合约部署到区块链,并使用我们的信息和{'from': dev}代码片段签署交易,以便区块链可以将我们识别为此状态更改的发送者。
我们的项目目录现在应该如下所示:
- NFT-demo
| - build
| - contracts
| - WaterCollection.sol
| - interfaces
| - reports
| - scripts
| - deploy_water.py
| - tests
让我们使用 Brownie 运行此脚本,将其部署到 Ethereum Rinkeby 测试网络。切换到 NFT-demo 目录运行:
brownie run scripts/deploy_water.py --network rinkeby
我们现在应该看到类似于以下的内容:
Running 'scripts/WaterCollection/deploy_water.py::main'...
Transaction sent: 0xade52b4a0bbabdb02aeda6ef4151184116a4c6429462c28d4ccedf90eae0d36d
Gas price: 1.033999909 gwei Gas limit: 1544657 Nonce: 236
WaterCollection.constructor confirmed Block: 10423624 Gas used: 1404234 (90.91%)
WaterCollection deployed at: 0xE013b913Ca4dAD36584D3cBFCaB6ae687c5B26c5
为确保一切按预期进行,我们可以访问 https://rinkeby.etherscan.io/。这是一项允许我们探索区块链的服务。复制部署 WaterCollection 的地址,并将其粘贴到 Etherscan Rinkeby 搜索栏中。保留此地址以备后用!
我们应该在合约下看到一个代表我们创建合约的交易。
非常不错!我们已部署到 Rinkeby ,接下来准备了解去中心化存储。
区块链存储和 IPFS
正如我们之前提到的,我们需要一种方法将我们的艺术作品与我们的 NFT 关联起来。由于我们的目标是确保我们代币的未来所有者拥有与其代币相关的艺术品的不变的访问权和所有权,只要他们拥有所述代币,我们希望我们的 NFT 直接包含其艺术品的二进制数据。 但是,我们必须认识到,在区块链上存储大量数据可能非常昂贵,并且高分辨率图像甚至一组帧可能需要大量存储。我们就要考虑通过前面提到的代币 URI 间接关联数据。此 URI 是指向存储我们数据的外部资源的链接。
为什么去中心化存储?
由于我们将使用外部链接,我们的直觉可能是简单地使用指向某些云存储提供商(例如 Google Drive 或 AWS S3)的地址的链接,但是,仔细思考,我们发现这在概念上是有问题的.
由于 NFT 的一大优点是,它们是分散管理的,因此我们不必依赖任何单个的组织来确保它们继续存在。因此,如果我们将我们的艺术作品存储在这些云提供商之一中,我们将通过依赖一个中心机构来保存我们的艺术作品,这就破坏了 NFT 的核心目的之一。诚然,谷歌或 AWS 不太可能突然不复存在,但是,为了保留 NFT 的去中心化特性,我们将寻求一种去中心化的存储方法。
IPFS
幸运的是,我们拥有InterPlanetary File System (IPFS),它是一个点对点分布式文件系统,我们可以使用它来存储我们的数据。有关 IPFS 的更多信息,请查看他们的网站:
IPFS Powers the Distributed Web
使用 Pinata 将数据绑定到 IPFS
与 IPFS 交互并将数据持久保存到 IPFS 的一种好方法是通过名为 Pinata 的服务。创建一个免费的 Pinata 帐户。以下指南将引导您获取 API 密钥和秘密(我们需要这两个密钥和密码),并解释更多关于使用 Pinata 固定数据的信息:
一旦你有了 API 密钥和秘密,让我们回到我们的.env文件并填写它们。它现在应该类似于:
PRIVATE_KEY=<YOUR_PRIVATE_KEY>
WEB3_INFURA_PROJECT_ID=<YOUR_PROJECT_ID>
PINATA_API_KEY=<YOUR_PINATA_KEY>
PINATA_API_SECRET=<YOUR_PINATA_SECRET>
ETHERSCAN_TOKEN=''
为 IPFS 准备我们的作品
现在我们几乎准备好将我们的作品上传到 IPFS,我们应该考虑我们想要包含什么。在本文中,我选择使用 100 张这样的水图片:
您可以选择任何您喜欢的艺术作品!
现在为了简单起见,我将我的图像命名为1.jpg, 2.jpg, …, 100.jpg,但如果你想要更有创意,也可以更改名字;您只需要确保以某种方式将它们的名称映射到数字,以便我们即将编写的脚本可以找到它们中的每一个。
让我们创建一个新的images子目录并上传我们的作品。项目目录现在应该如下所示:
- NFT-demo
| - build
| - contracts
| - WaterCollection.sol
| - images
| - 1.jpg
| - ...
| - 100.jpg
| - interfaces
| - reports
| - scripts
| - deploy_water.py
| - tests
现在,我们有一个地方可以让我们的脚本(我们将要编写的)找到我们的艺术品。
将艺术品和元数据保存到 IPFS 的脚本
我们已经设置好了 Pinata,我们的作品也准备好了。让我们编写另一个脚本来与这些数据进行交互。在 scripts 子目录中创建一个名为create_metadata.py 的文件。
在我们开始编写代码之前,我们应该快速回顾一下我们正在尝试做的事情。由于 ERC721 (NFT) 标准的规范,我们的数据(我们通过代币 URI 引用的数据)将不是艺术品本身,而是引用实际艺术品的元数据文件。它看起来像这样:
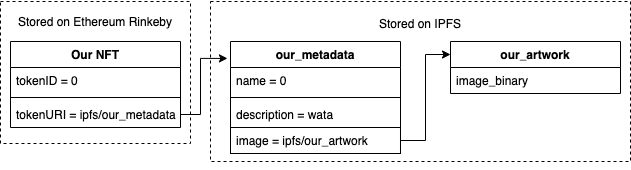
因此,我们必须为每个 NFT 上传 2 个文件到 IPFS:1 个用于艺术品本身,1 个用于引用艺术品的元数据文件。
现在我们已经介绍了这一点,让我们编写我们的脚本create_metadata.py:
import requests
import os
import json
metadata_template = {
"name": "",
"description": "",
"image": ""
}
def main():
write_metadata(100)
def write_metadata(num_tokens):
# We'll use this array to store the hashes of the metadata
meta_data_hashes = []
for token_id in range(num_tokens):
collectible_metadata = metadata_template.copy()
# The filename where we're going to locally store the metadata
meta_data_filename = f"metadata/{
token_id + 1}.json"
# Name of the collectible set to its token id
collectible_metadata["name"] = str(token_id)
# Description of the collectible set to be "Wata"
collectible_metadata["description"] = "Wata"
# Path of the artwork to be uploaded to IPFS
https://img.chengxuka.com_path = f"images/{
token_id + 1}.jpg"
with open(https://img.chengxuka.com_path, "rb") as f:
https://img.chengxuka.com_binary = f.read()
# Upload the image to IPFS and get the storage address
image = upload_to_ipfs(https://img.chengxuka.com_binary)
# Add the image URI to the metadata
image_path = f"<https://ipfs.io/ipfs/{
image}>"
collectible_metadata["image"] = image_path
with open(meta_data_filename, "w") as f:
# Write the metadata locally
json.dump(collectible_metadata, f)
# Upload our metadata to IPFS
meta_data_hash = upload_to_ipfs(collectible_metadata)
meta_data_path = f"<https://ipfs.io/ipfs/{
meta_data_hash}>"
# Add the metadata URI to the array
meta_data_hashes.append(meta_data_path)
with open('metadata/data.json', 'w') as f:
# Finally, we'll write the array of metadata URIs to a file
json.dump(meta_data_hashes, f)
return meta_data_hashes
def upload_to_ipfs(data):
# Get our Pinata credentials from our .env file
pinata_api_key = os.environ["PINATA_API_KEY"]
pinata_api_secret = os.environ["PINATA_API_SECRET"]
endpoint = "<https://api.pinata.cloud/pinning/pinFileToIPFS>"
headers = {
'pinata_api_key': pinata_api_key,
'pinata_secret_api_key': pinata_api_secret
}
body = {
'file': data
}
# Make the pin request to Pinata
response = requests.post(endpoint, headers=headers, files=body)
# Return the IPFS hash where the data is stored
return response.json()["IpfsHash"]
简而言之,它会将我们所有的艺术作品保存到 IPFS,创建以下格式的元数据文件:
{
"name": "<TOKEN_ID>",
"description": "Wata",
"image": "<https://ipfs.io/ipfs/><ARTWORK_IPFS_HASH>"
}
将这个文件在本地 metadata 子目录下(我们将立即创建)写入名为<TOKEN_ID>.json 的文件和 IPFS。最后,在同一子目录中,它将 IPFS 元数据哈希列表保存到 data.json 调用的文件中。
在 NFT-demo 目录的命令行中运行以下命令:
mkdir metadata
brownie run scripts/create_metadata.py --network rinkeby
如果一切按预期进行,我们现在将拥有以下项目结构:
- NFT-demo
| - build
| - contracts
| - WaterCollection.sol
| - images
| - 1.jpg
| - ...
| - 100.jpg
| - interfaces
| - metadata
| - data.json
| - 1.json
| - ...
| - 100.json
| - reports
| - scripts
| - deploy_water.py
| - create_metadata.py
| - tests
现在我们已经准备好铸造我们的收藏品了!
铸造我们的藏品
现在,我们的合约被部署到了 Rinkeby 网络,并且我们将所有的艺术作品和元数据都写入了 IPFS。现在是时候铸造我们的收藏品了。
通过调用合约来铸造藏品的脚本
让我们在 scripts 子目录下再编写一个脚本文件:create_collection.py
import json
from pathlib import Path
from brownie import (
accounts,
config,
WaterCollection,
)
from scripts.WaterCollection.create_metadata import write_metadata
def main():
# Get our account info
dev = accounts.add(config['wallets']['from_key'])
# Get the most recent deployment of our contract
water_collection = WaterCollection[-1]
# Check the number of currently minted tokens
existing_tokens = water_collection.tokenCounter()
print(existing_tokens)
# Check if we'eve already got our metadata hashes ready
if Path(f"metadata/data.json").exists():
print("Metadata already exists. Skipping...")
meta_data_hashes = json.load(open(f"metadata/data.json"))
else:
meta_data_hashes = write_metadata(100)
for token_id in range(existing_tokens, 100):
# Get the metadata hash for this token's URI
meta_data_hash = meta_data_hashes[token_id]
# Call our createCollectible function to mint a token
transaction = water_collection.createCollectible(
meta_data_hash, {
'from': dev, "gas_limit": 2074044, "allow_revert": True})
# Wait for 3 blocks to be created atop our transactions
transaction.wait(3)
现在,请您自己验证代码,此脚本本质上确保我们可以访问元数据的 IPFS 地址,然后使用这些地址作为我们的代币 URI 一个一个地创建我们的藏品。
现在,我们使用以下命令运行脚本:
brownie run scripts/create_collection.py --network rinkeby
让我们前往https://testnets.opensea.io/ ,并将我们的合约地址放在搜索栏中。加载可能需要几分钟。我们应该会在这里看到我们的收藏!我们现在已经铸造了我们的收藏!剩下的就是列出我们的代币。
在其他网络上重新部署
现在我们已经在 Rinkeby 测试网络上完成了这项工作,您可能想知道我们如何在真实网络上重做这项工作,以便我们可以从我们的辛勤工作和艺术性中获利。幸运的是,它就像更改我们提供给 Brownie 的网络参数一样简单。
假设我们想部署到 Polygon 网络,我们只需要在 Polygon 网络上重新运行我们的脚本(我们可以使用相同的 IPFS 地址):
brownie run scripts/deploy_water.py --network polygon-main
brownie run scripts/create_collection.py --network polygon-main
请注意,我们将需要一些 MATIC(Polygon 的原生代币)来与 Polygon 网络进行交互。如果我们这样做,我们将能够在 https://opensea.io/ 上看到我们的集合,Polygon 网络上的合约地址下(我们将在 Polygon 网络上运行第一个部署脚本时得到这个)。
列出我们的 NFT
最后,让我们在市场上列出我们的 NFT。为此,我们将使用 NFT 市场协议 Zora,但您可以自行探索其他选项。
Zora Asks 模块
Zora 询问模块允许我们通过提供 NFT 合约的地址、要列出的代币的代币 ID、ask 货币、ask 要价(以我们的 ask 货币)、存入资金的地址来列出 NFT出售的 NFT,以及激励推荐给我们 NFT 的发现者费用。你可以在这里查看他们的文档:
Etherscan API
在我们编写脚本来列出这些请求之前,我们需要一种以编程方式访问 Zora 合约的方法。为此,我们将使用 Etherscan 的 API。继续通过创建一个 Etherscan 帐户并按照此处的说明获取免费 API:
获取您的 API 代币并填写.env文件的最后一行,使其显示为ETHERSCAN_TOKEN=<YOUR_ETHERSCAN_API_TOKEN>。现在,Brownie 将能够在后台从以太坊网络中提取合同。
请注意,您可以通过在此处获取 Polyscan API 代币来为 Polygon 网络应用非常相似的过程:
并添加一个新.env条目:POLYGONSCAN_TOKEN=<YOUR_POLYSCAN_API_TOKEN>。
列出 NFT 集合的脚本
现在是我们的最终脚本。再次在scripts子目录中,让我们创建一个名为的新文件set_asks.py:
from brownie import WaterCollection, network, accounts, config, Contract
def main():
# Fill your own MetaMask public key here
creator_address = ""
net = network.show_active()
water_collection = WaterCollection[-1]
# Get the asks contract depening on the network
if net == "polygon-main":
asks_address = "0x3634e984Ba0373Cfa178986FD19F03ba4dD8E469"
asksv1 = Contract.from_explorer(asks_address)
module_manager = Contract.from_explorer("0xCCA379FDF4Beda63c4bB0e2A3179Ae62c8716794")
erc721_helper_address = "0xCe6cEf2A9028e1C3B21647ae3B4251038109f42a"
water_address = "0x0d2964fB0bEe1769C1D425aA50A178d29E7815a0"
weth_address = "0x7ceB23fD6bC0adD59E62ac25578270cFf1b9f619"
elif net == "rinkeby":
asks_address = "0xA98D3729265C88c5b3f861a0c501622750fF4806"
asksv1 = Contract.from_explorer(asks_address)
module_manager = Contract.from_explorer("0xa248736d3b73A231D95A5F99965857ebbBD42D85")
erc721_helper_address = "0x029AA5a949C9C90916729D50537062cb73b5Ac92"
water_address = "0xFA3D765E90b3FBE91A3AaffF1a611654B911EADb"
weth_address = "0xc778417E063141139Fce010982780140Aa0cD5Ab"
dev = accounts.add(config['wallets']['from_key'])
# Give Zora permission to facilitate transactions with the ASK contract
module_manager.setApprovalForModule(asks_address, True, {
"from": dev})
water_collection.setApprovalForAll(erc721_helper_address, True, {
"from": dev})
for token_id in range(100):
price = (100 - token_id) * 10 ** 16
asksv1.createAsk(water_address, # Address of our contract
token_id, # Token ID of the NFT to be listed
price, # Our asking price
weth_address, # The address of the token required to pay for our NFT
creator_address, # The address where the funds will be sent to
0, # A finder reward
{
'from': dev}) # Sign our transaction with our account
这个脚本将访问 Zora asks 合约并使用滑动价格标度列出我们的 NFT。在这里,我们要求用 Wrapped ETH 支付 NFT,但是,如果您愿意,您可以更改此设置。
另外,请注意,此脚本将批准 Zora 合约代表我们转移资金和 NFT。在批准之前验证合同逻辑始终是一种很好的做法,但如果你愿意,你可以相信我的话的合法性。
最后,我们将运行我们的脚本:
brownie run scripts/set_asks.py --network rinkeby
真棒!我们现在已经在 Rinkeby 测试网上列出了我们的收藏。祝你今天过的愉快!