1.传感器
自动驾驶中的传感器主要用到激光雷达,毫米波雷达,摄像头,超声波,优缺点如下:
1)激光雷达的测距精度、测距范围及对温度和光照的适应性很强,缺点线束低的情况,识别不好,也可能会漏掉目标(尤其是非金属物体)
2)相机对环境细节信息多,但是光照影响太大。
3)毫米波最大优点探测角度比较大,抗干扰性强,性能比较稳定,缺点就是分辨率和精度差
4)超声波雷达精度差,探测距离短,只有3m。
2.标定
传感器标定主要包括内参和外参。内参主要是焦距,光圈,相机中心偏移等参数,可直接获取或者简单算法测定。这里主要说的是外参标定,外参是描述了传感器与其他给定坐标之间的相对位置关系,所以这里的外参描述为,长焦相机与短焦相机之间的外参,相机与雷达之间的外参,又或者是雷达与雷达之间的外参, 都需要分别进行标定。
标定的方式有使用标定间标定,或者使用算法进行标定。使用标定间进行标定,设置一些参照物,多为有角点的物体,方便定位。标定完也可进行误差修正。具体方法:
(1)相机标定: 多点图像数据 VS 多点参照物相应角点数据 方法:PNP算法
(2)点云标定: 多点点云坐标 VS 多点参照物点云数据 方法:ICP算法
不同相机使用PNP得到一个矩阵,将两个矩阵进行传递,一般用一个矩阵得逆乘以另一个矩阵就得到了外参,点云也是这样。
3.检测
2D图像检测常用算法:SSD;yolo系列;centernet
3D点云检测常用算法:
(1)分割:birdview分割;(2)检测:MV3D
流行算法:VoxelNet,SECOND, PointPillars,Centerpoint
PointPillars
Pillars每个点其实是有xyz或者其他特征的,所以点本身也是一个特征向量。然后通过我们的全连接层,Bath Norm,ReLU,还有Max Pooling这些常规的操作之后,来转换成一个Pillar里的global的特征,一个代表Pillar的特征向量。这个过程其实是对于VoxelNet转化成Voxel过程的一个简化,是VoxelNet对Voxel编码的学习的过程。VoxelNet在最后Voxel得到一个global的特征之后,它还要把global特征再Concat的回去,也就是说每人复制一份再领回去原来的点,然后再继续去迭代这样的过程,在最后的内存里边才是用最后的global的特征作为VoxelNet整个的特征向量。所以PFE其实是一个简化,加快了迭代过程。

损失函数:
PointPillars原来是用了Focal loss作为它分类的损失函数。Focal loss是在2018年的时候提出的,也是用于二维的目标检测,用来改进一个类别不均衡的问题,正负样本比例不均衡的问题。公式有两个参数α和γ。这两个参数要预先设定一个超参数,这个超参数本身是需要通过先验调整。实际的测试中发现这些参数不是特别好调整,因为需要利用一些先验的信息,所以就换成了加权的softmax loss,它的泛化性更好,因为没有那些超参数,泛化后的检测效果有改善,这个加权的意思就是给了一些类比更大的权重。
Pillar特征编码:
左边的结构是原来的,右边的是改进之后的,在拿到点的特征的时候,原本是包含点的xyz坐标和反射率的intensity,当然还有可能有其他的特征,先做一个radius的替换,就是对里面的特征做一个初步的变换。之后再进行后面的操作,Linear,Batch Norm,Relu,MaxPooling,得到最后的一个global的Pillar的特征。
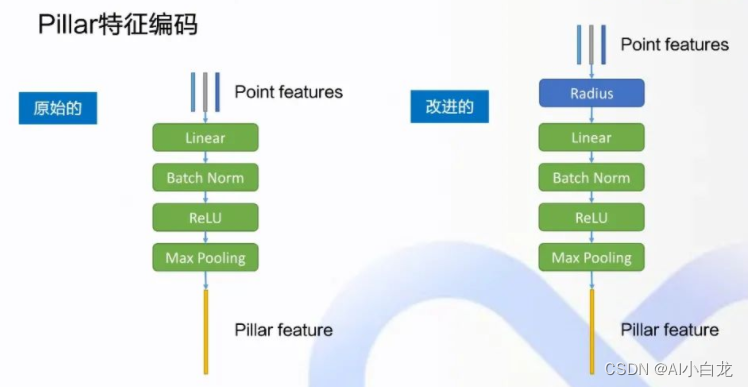
接下来用Radius替换点特征:在右边的这张BEV这个视角下的点云图里面,坐标系的原点O,其实是车上的lidar的传感器,朝前的是x的正方向,左方是Y轴正方向,先计算一个radius,就是xy的二范数,也就是说在这个BEV视角xy平面上,这个点与原点的距离就是radius,用它替代点的原始特征xy,再加上Y intensity,组成这个点变换之后的特征。激光雷达的点云是一圈一圈的点组成的,是几乎不间断的通过旋转激光反射器来获得的。此外,在这个BEV视角下的目标检测里面,X和Y的地位其实是相等的,所以把xy替换成了radius,把这个radius当成点的基本特征去看待,更符合点云是一圈一圈的这个原始的特点,对于网络的提升有帮助。
RPN网络设计:
RPN是最初针对二维目标检测,在Fast-RCN里面提出的一个编码解码的网络,通过预先在网格点上设定好初始的检测框,然后对应到特征图上面,经过后续的处理,得到的这些候选框包含的概率分数值和目标类别,最后再去做进一步的筛选,得到的最终的检测框。而那些初始的候选框proposals,一开始是需要先在这个原始的图上面去取一些初始的anchor,来提供初始的框。在二维的目标检测里边,也就是针对图像的目标检测里面,由于同一个目标,在不同的拍摄角度,在图像上的尺寸是不同的,有些远近关系,那么因此就要设定multi-anchor图像的目标检测里面,可以通过不同大小,不同的长宽比例尽可能去覆盖匹配图像里的这些目标。
Multi-head对RPN的改进:Apollo的PointPillars模型支持9个类别,其中有4个是个头比较大的类别(Large head),比如说轿车、卡车、公交车,还有工程车。另外5个Small head、行人、bicycle、motorcycle、雪糕筒等,那他们在BEV图上所占的尺寸是有差距的,在俯视图视角上这些个头是有一些差距的。所以要把这些类别都分开来,分成两个不同的RPN head去做检测。比如说我们这里在拿到最终的特征图之前,各自先用一个卷积层来输出目标的class类别的概率得分,还有body box的回归值,以及它的direction朝向。
4.融合跟踪
对象跟踪器跟踪分段检测到的障碍物。通常,它通过将当前检测与现有跟踪列表相关联,来形成和更新跟踪列表,如不再存在,则删除旧的跟踪列表,并在识别出新的检测时生成新的跟踪列表。 更新后的跟踪列表的运动状态将在关联后进行估计。 在HM对象跟踪器中,匈牙利算法(Hungarian algorithm)用于检测到跟踪关联,并采用鲁棒卡尔曼滤波器(Robust Kalman Filter) 进行运动估计。
跟踪流程可以分为:
-
预处理;(lidar->local ENU坐标系变换、跟踪对象创建、跟踪目标保存)
-
卡尔曼滤波器滤波,预测物体当前位置与速度;(卡尔曼滤波阶段1:Predict阶段)
-
匈牙利算法比配,关联检测物体和跟踪物体;
-
卡尔曼滤波,更新跟踪物体位置与速度信息。(卡尔曼滤波阶段2:Update阶段)
对每个时刻检测到的Object与跟踪列表中的TrackedObject进行匈牙利算法的二分图匹配,匹配结果分三类:
-
如果成功匹配,那么使用卡尔曼滤波器更新信息(重心位置、速度、加速度)等信息;
-
如果失配,缺少对应的TrackedObject,将Object封装成TrackedObject,加入跟踪列表;
-
对于跟踪列表中当前时刻目标缺失的TrackedObject(Object都无法与之匹配),使用上时刻速度,跟新当前时刻的重心位置与加速度等信息(无法使用卡尔曼滤波更新,缺少观测状态)。对于那些时间过长的丢失的跟踪目标,将他们从跟踪队列中删除。
在跟踪对象信息融合的阶段,Apollo的主要工作是,给定一个被跟踪的物体序列:
(Time_1,TrackedObject_1),
(Time_2,TrackedObject_2),
...,
(Time_n,TrackedObject_n)
每次执行LidarSubNode的回调,都会刷新一遍跟踪列表,那么一个被跟踪物体的信息也将会被刷新(重心位置,速度,加速度,CNN物体分割--前景概率,CNN物体分割--各类别概率)。N次调用都会得到N个概率分布(N个CNN物体分割--前景概率score,N个CNN物体分割--各类物体概率Probs),我们需要在每次回调的过程中确定物体的类别属性,当然最简单的方法肯定是argmax(Probs)。但是CNN分割可能会有噪声,所以最好的办法是将N次结果联合起来进行判断。