单选20道,多选10道,编程2道
单选
1、低维嵌入可以防止过拟合吗?
不能
链接: https://cloud.tencent.com/developer/article/1327163
在高维情形下出现的数据样本稀疏、距离计算困难等问题,是所有机器学习方法共同面临的严重障碍,被称为维数灾难。缓解维数灾难的一个重要途径是降维,亦称为维数约简,即通过某种数学变换将原始高维属性空间转变为一个低维子空间。在这个子空间中样本密度大幅提高,距离计算也更为容易。
2、图像处理中衡量对点间不同维度距离:
(1)canberra
(2)euclidean
(3)manhattan
(4)chebyvhev
选(4),切比雪夫。(3)是曼哈顿,(2)是欧几里得
切比雪夫距离(Chebyshev distance)二个点之间的距离定义是其各坐标数值差绝对值的最大值
D ( x , y ) = m a x ( ∣ x i − y i ∣ ) D(x,y)=max(|x_i-y_i|) D(x,y)=max(∣xi−yi∣)

def ChebyshevDistance(x, y):
import numpy as np
x = np.array(x)
y = np.array(y)
return np.max(np.abs(x-y))
3、后序遍历和前序遍历
前序遍历:根-左-右
1、递归
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
res = []
def dfs(root):
if not root:
return
res.append(root.val)
dfs(root.left)
dfs(root.right)
dfs(root)
return res
2、迭代(用栈的方式)
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
res,stk = [],[]
while stk or root:
while root:
stk.append(root)
res.append(root.val)
root = root.left
root = stk.pop()
root = root.right
return res
中序遍历:左-根-右
1、递归
class Solution:
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
res = []
def dfs(root):
if not root:
return
dfs(root.left)
res.append(root.val)
dfs(root.right)
dfs(root)
return res
2、迭代(用栈的方式)
class Solution:
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
res,stk = [],[]
while stk or root:
while root:
stk.append(root)
root = root.left
root = stk.pop()
res.append(root.val)
root = root.right
return res
后序遍历:左-右-根
1、递归
class Solution:
def postorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
res = []
def dfs(root):
if not root:
return
dfs(root.left)
dfs(root.right)
res.append(root.val)
dfs(root)
return res
2、迭代(用栈的方式)
class Solution:
def postorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
# 把(根右左)翻转
res,stk = [],[]
while root or stk:
while root:
stk.append(root)
res.append(root.val)
root = root.right
root = stk.pop()
root = root.left
return res[::-1]
4、集成学习方法
-
Bagging
- 随机森林 Boosting
- AdaBoost
- GBDT
- XGBoost
- LightGBM
- CatBoost Stacking
- Stacking Blending
- Blending
5、防止过拟合的方法
交叉验证、剪枝、集成学习(将多个弱学习器Bagging)
6、判别式模型
线性回归
逻辑回归
线性判别分析
支持向量机(SVM)
CART(classfication and regression tree)
神经网络
高斯过程
条件随机场(CRF)
7、生成式模型
朴素贝叶斯
K近邻
混合高斯模型
隐马尔科夫模型(HMM)
贝叶斯模型
Sigmoid Belief Networks
马尔可夫随机场(Markov Random Fields)
深度信念网络(DBN)
LDA文档主题生成模型
8、适用于对动态查找表进行高效率查找的组织结构是?
二叉排序表
9、解决类别不平衡的办法
扩大数据集、类别均衡采样、人工产生数据样本,添加少类别样本的loss惩罚项
类别均衡采样:
把样本按类别分组,每隔类别生成一个样本列表,训练过程中先随机选择1个或几个类别,然后从各个类别所对应的样本列表里选择随机样本。这样可以保证每个类别参与训练的机会比较均衡
10、基尼数与数据样本纯度的关系:
数据样本纯度(信息熵越低,数据纯度越高)
基尼指数反映数据集D中随机抽取两个样本,其类别标记不一致的概率,不一致的概率越小集合就越纯。
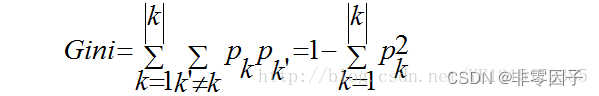
11、时间复杂度o(n2)的排序算法
冒泡:两两比较,找到大的放后面
选择:选出最大的放在最后面,后面是有序序列,前面是无序序列,从无序序列中选出,放到后面的有序序列中。
插入:从前面无序序列中按顺序插入到后面有序序列的相应位置上。
12、语音识别中使用的声学特征
MFCC、PLP、FBANK
13、模型压缩常用方法
- 模型蒸馏 Distillation,使用大模型的学到的知识训练小模型,从而让小模型具有大模型的泛化能力
- 量化Quantization,降低大模型的精度,减小模型
- 剪枝 Pruning,去掉模型中作用比较小的连接
- 参数共享,共享网络中部分参数,降低模型参数数量