在进行特征提取之前,都要对原始序列做一系列的预处理,目的是消除因为人类发声器官本身和由于采集语音信号的设备所带来的混叠、高次谐波失真、高频等等因素,对语音信号质量的影响。尽可能保证后续语音处理得到的信号更均匀、平滑,为信号参数提取提供优质的参数,提高语音处理质量。
端点检测
其实就是找到语音信号的起始点和结束点。
预加重
目的是为了对语音的高频部分进行加重,去除口唇辐射的影响,增加语音的高频分辨率。因为高频端大约在800Hz以上按6dB/oct (倍频程)衰减,频率越高相应的成分越小,为此要在对语音信号进行分析之前对其高频部分加以提升。
一般通过传递函数为高通数字滤波器来实现预加重,其中a为预加重系数,0.9<a<1.0。设n时刻的语音采样值为x(n),经过预加重处理后的结果为y(n))=x(n)-ax(n-1),这里取a=0.98。



分帧
傅里叶变换要求输入信号是平稳的,但是语音信号从整体上来讲是不平稳的,嘴巴一动,就game over,如果把不平稳的信号作为输入,傅里叶变换将无意义。虽然语音信号具有时变特性,但是在一个短时间范围内(一般认为在10~30ms),其特性基本保持不变即相对稳定,因而可以将其看作是一个准稳态过程,即语音信号具有短时平稳性。(如下图中的红框内的信号),因此我们需要将语音信号进行分帧处理。

帧长一般即取为10~30Ms。这样,对于整体的语音信号来讲,分析出的是由每一帧特征参数组成的特征参数时间序列。
分帧一般采用交叠分段的方法,这是为了使帧与帧之前平滑过渡,保持其连续性。前一针和后一帧的交叠部分称为帧移。帧移与帧长的比值一般取为0~1/2。

图中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。
加窗
窗的目的是可以认为对抽样n附近的语音波形加以强调而对波形的其余部分加以减弱。对语音信号的各个短段进行处理,实际上就是对各个短段进行某种变换或施以某种运算,其实加窗相当于把每一帧里面对应的元素变成它与窗序列对应元素的乘积。用得最多的三种窗函数是矩形窗、汉明窗(Hamming)和汉宁窗(Hanning);以汉明窗举例如下:
汉明窗函数如下:
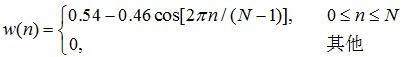
汉明窗的时域和频域波形,窗长N=61,窗函数的宽度其实就是帧长

从上图可以看到,可以认为对抽样n附近的语音波形加以强调而对波形的其余部分加以减弱;