概要
在大数据量高并发访问时,经常会出现服务或接口面对暴涨的请求而不可用的情况,甚至引发连锁反映导致整个系统崩溃。此时你需要使用的技术手段之一就是限流,当请求达到一定的并发数或速率,就进行等待、排队、降级、拒绝服务等。
缓存
缓存比较好理解,在大型高并发系统中,如果没有缓存数据库将分分钟被爆,系统也会瞬间瘫痪。使用缓存不单单能够提升系统访问速度、提高并发访问量,也是保护数据库、保护系统的有效方式。大型网站一般主要是“读”,缓存的使用很容易被想到。在大型“写”系统中,缓存也常常扮演者非常重要的角色。比如累积一些数据批量写入,内存里面的缓存队列(生产消费),以及HBase写数据的机制等等也都是通过缓存提升系统的吞吐量或者实现系统的保护措施。甚至消息中间件,你也可以认为是一种分布式的数据缓存。
降级
服务降级是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。降级往往会指定不同的级别,面临不同的异常等级执行不同的处理。根据服务方式:可以拒接服务,可以延迟服务,也有时候可以随机服务。根据服务范围:可以砍掉某个功能,也可以砍掉某些模块。总之服务降级需要根据不同的业务需求采用不同的降级策略。主要的目的就是服务虽然有损但是总比没有好。
限流
限流可以认为服务降级的一种,限流就是限制系统的输入和输出流量已达到保护系统的目的。一般来说系统的吞吐量是可以被测算的,为了保证系统的稳定运行,一旦达到的需要限制的阈值,就需要限制流量并采取一些措施以完成限制流量的目的。比如:延迟处理,拒绝处理,或者部分拒绝处理等等。
限流算法
令牌桶(Token Bucket)、漏桶(leaky bucket)和计数器算法是最常用的三种限流的算法。
计数器限流算法也是比较常用的,主要用来限制总并发数,比如数据库连接池大小、线程池大小、程序访问并发数等都是使用计数器算法。也是最简单粗暴的算法。使用计数器限流示例1:
- public class CountRateLimiterDemo {
- private static AtomicInteger count = new AtomicInteger(0);
- public static void exec() {
- if (count.get() >= 5) {
- System.out.println("请求用户过多,请稍后在试!"+System.currentTimeMillis()/1000);
- } else {
- count.incrementAndGet();
- try {
- //处理核心逻辑
- TimeUnit.SECONDS.sleep(1);
- System.out.println("--"+System.currentTimeMillis()/1000);
- } catch (InterruptedException e) {
- e.printStackTrace();
- } finally {
- count.decrementAndGet();
- }
- }
- }
- }
使用AomicInteger来进行统计当前正在并发执行的次数,如果超过域值就简单粗暴的直接响应给用户,说明系统繁忙,请稍后再试或其它跟业务相关的信息。
弊端:使用 AomicInteger 简单粗暴超过域值就拒绝请求,可能只是瞬时的请求量高,也会拒绝请求。
使用计数器限流示例2
- public class CountRateLimiterDemo {
- private static Semaphore semphore = new Semaphore(50);
- public static void exec() {
- if(semphore.getQueueLength()>100){
- System.out.println("当前等待排队的任务数大于100,请稍候再试...");
- }
- try {
- semphore.acquire();
- // 处理核心逻辑
- TimeUnit.SECONDS.sleep(1);
- System.out.println("--" + System.currentTimeMillis() / 1000);
- } catch (InterruptedException e) {
- e.printStackTrace();
- } finally {
- semphore.release();
- }
- }
- }
相对Atomic优点:如果是瞬时的高并发,可以使请求在阻塞队列中排队,而不是马上拒绝请求,从而达到一个流量削峰的目的。
Redis
漏桶算法
漏桶算法即leaky bucket是一种非常常用的限流算法,可以用来实现流量整形(Traffic Shaping)和流量控制(Traffic Policing)。贴了一张维基百科上示意图帮助大家理解:
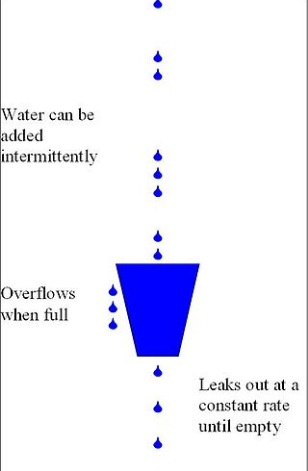
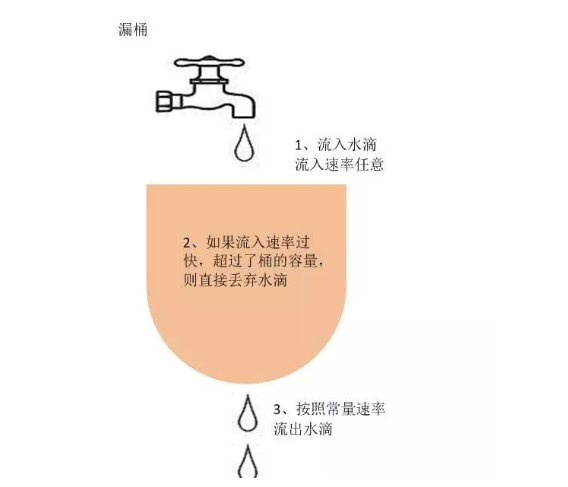
漏桶算法的主要概念如下:
-
一个固定容量的漏桶,按照常量固定速率流出水滴;
-
如果桶是空的,则不需流出水滴;
-
可以以任意速率流入水滴到漏桶;
-
如果流入水滴超出了桶的容量,则流入的水滴溢出了(被丢弃),而漏桶容量是不变的。
它的主要目的是控制数据注入到网络的速率,平滑网络上的突发流量,数据可以以任意速度流入到漏桶中。漏桶算法提供了一种机制,通过它,突发流量可以被整形以便为网络提供一个稳定的流量。 漏桶可以看作是一个带有常量服务时间的单服务器队列,如果漏桶为空,则不需要流出水滴,如果漏桶(包缓存)溢出,那么水滴会被溢出丢弃。
漏桶算法比较好实现,在单机系统中可以使用队列来实现(.Net中TPL DataFlow可以较好的处理类似的问题,你可以在这里找到相关的介绍),在分布式环境中消息中间件或者Redis都是可选的方案。
令牌桶算法
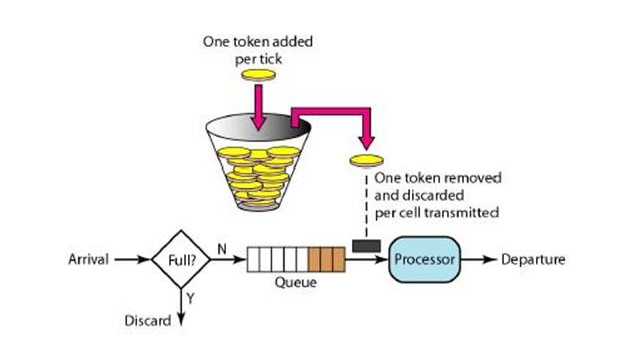
令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。 当桶满时,新添加的令牌被丢弃或拒绝。
令牌桶算法是一个存放固定容量令牌(token)的桶,按照固定速率往桶里添加令牌。令牌桶算法基本可以用下面的几个概念来描述:
- 令牌将按照固定的速率被放入令牌桶中。比如每秒放10个。
- 桶中最多存放b个令牌,当桶满时,新添加的令牌被丢弃或拒绝。
- 当一个n个字节大小的数据包到达,将从桶中删除n个令牌,接着数据包被发送到网络上。
- 如果桶中的令牌不足n个,则不会删除令牌,且该数据包将被限流(要么丢弃,要么缓冲区等待)。
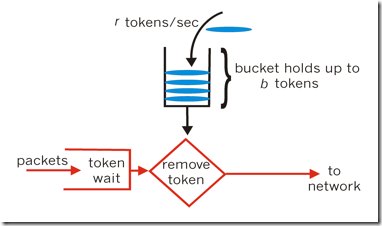
令牌算法是根据放令牌的速率去控制输出的速率,也就是上图的to network的速率。to network我们可以理解为消息的处理程序,执行某段业务或者调用某个RPC。
漏桶和令牌桶的比较
令牌桶可以在运行时控制和调整数据处理的速率,处理某时的突发流量。放令牌的频率增加可以提升整体数据处理的速度,而通过每次获取令牌的个数增加或者放慢令牌的发放速度和降低整体数据处理速度。而漏桶不行,因为它的流出速率是固定的,程序处理速度也是固定的。
整体而言,令牌桶算法更优,但是实现更为复杂一些。