点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

作者简介
王梓枫
美国东北大学博士生,主要研究方向持续学习(Continual Learning)。
个人主页:https://kingspencer.github.io/
报告题目
SparCL: 边缘设备上的稀疏持续学习
SparCL: Sparse Continual Learning on the Edge (作者团队来自Northeastern University)
最近在看2022NeurIPS关于连续学习的文章,不得不感叹nips的文章太“Mathy”了!这对于我这种数学功底薄弱的人很不友好,许多文章看下来都是一知半解。不过这篇SparCL并没有太多数学推导的内容,而且文章写得清晰易读,阅读过程中的疑问往下读一读就被解答了。
说回这篇本章本身,SparCL的效果比State of the art提升不多,其主要优势在于训练效率的提升,这种特性能有效适配最需要连续学习加持的边缘设备(如家用机器人等),这为连续学习在实际应用场景中的落地创造了有利条件。接下来我们就详细解读一下这篇文章。
01
什么是剪枝?
首先,我们讲一下Sparsity以及剪枝(pruning)。
神经网络示意图,圆圈表示neuron,连线表示weights
在一个训练好的神经网络中,最经典的剪枝方法是统计所有权重的大小,将数值大的权重保留,将数值小的权重置0,他们的比例sparse ratio是人为确定的。值得注意的是,这里的置0也不是真的把权重数值改成0,而是使用一个binary mask,在用到神经网络时用这个mask来进行筛选操作。
除了最简单的直接看权重大小,还有很多其他的剪枝方法,比如通过查看梯度值大小,以及用到黑赛矩阵等更fancy的方法,这里不再赘述。
02
为什么要剪枝?
经常看到文章说,只用5%的权重,就能达到多少多少的性能。这传递了一种剪枝似乎能够降低模型大小,加速训练的功效。但我细想之后就产生了疑问,如果模型中很多权重直接设置为0,那么这些0也是浮点数,同样要占据空间的呀。此外,如果是用mask来达到置0的目的,这储存开销甚至还要增大不少吧。对这个疑问在网上搜索了一番,可能是关键词不对,竟没有找到太多资料。最终找到了一些(不是很权威但make sense的)解释:
剪枝分为structured 剪枝和unstructured 剪枝
前者可以把权重tensor做整行消除的操作,相当于减少了全连接层的一个neuron或者一个卷积层的channel,这确实可以压缩模型。(但这并不是sparsity领域的主要研究方向)
后者unstructured 剪枝是sparsity领域的主要研究内容,这多了个mask,其实并没有在空间上以及时间上提高效率。此外,当前的gpu搞稀疏矩阵乘法的效率反而比常规模型效率更低。
03
剪枝的意义在哪?
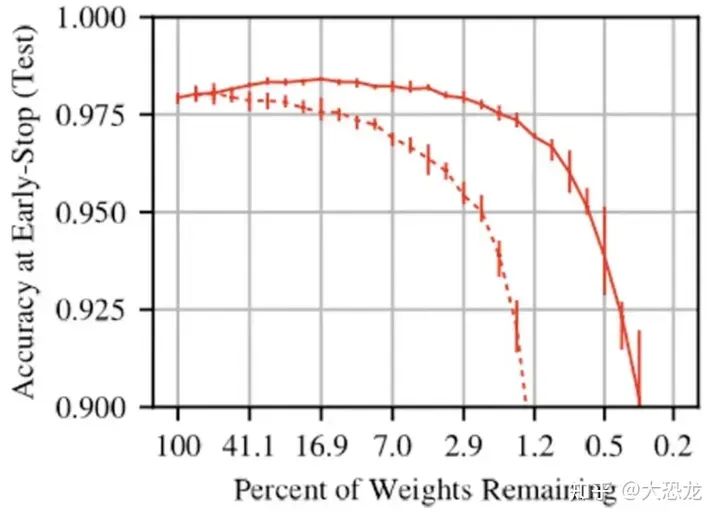
通过剪枝可以提升模型性能
如果不能提高效率,那剪枝到底有啥用呢?可以概括为以下三点:
一些剪枝算法可以提高模型性能。比如上图中红色实线为一篇文章提出的剪枝方法,在保留权重比例大于7%的时候,剪枝后的模型准确率都有所提高。
有理论上的价值。比如 Lottery Ticket Hypothesis 就提供了why deep learning works的解释。
虽然单独的剪枝不能压缩模型,但和模型蒸馏(Distillation)结合使用,确实可以达到减小模型大小的目的。
Sparse Continual Learning (SparCL)
铺垫了一些背景知识后,我们来看这篇文章的主要内容。SparCL定位为一个插件型的算法,其对memory bank有独特的设计,因此这个插件型算法仅能用在 rehearsal-based 的连续学习算法上。文章中的实验也主要是将SparCL与ER和DER++这两个算法结合来验证其有效性。
具体地,SparCL模型分为三个部分:
Task-aware Dynamic Masking (TDM) for weight sparsity
Dynamic Data Removal (DDR) for data efficiency
Dynamic Gradient Masking (DGM) for gradient sparsity
这三个部分有着各自的目标。TDM是最接近常规剪枝算法的,其目的是实现权重的稀疏化。DDR则是本文中提升训练效率的主要因素,其能使得训练数据被更高效地利用。DGM将权重稀疏化的思路用在了梯度稀疏化上面,希望能进一步提升模型在连续学习任务上的表现。
Task-aware Dynamic Masking (TDM)
TDM使得模型在训练过程中,通过维护一个mask,来定期地去除不重要的权重,并适时地增加未使用权重来增强模型的表征能力。
04
如何来确定各个权重的重要性呢?
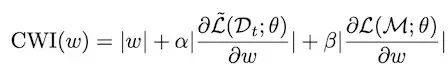
Continual weight importance (CWI)
用CWI公式来计算各权重的重要性,其中第一项是权重的绝对值大小,第二项是当前任务训练时的梯度,第三项是包含所有过去类数据 (memory buffer) 计算出的梯度。这三者对总重要性的影响通过系数alpha和beta来调控。
ps:公式中的 Dt表示当前任务的数据集, θ表示模型参数, M表示memory buffer, L表示囊括了模型和算法的损失函数。这里第二项的 L~ ,表示在对当前任务数据集训练时,分类头将非当前类的output neuron给mask掉了,是和第三项中使用memory buffer的完整模型有区别,因此用tilde加以区分。
接下来我们看TDM的详细算法步骤图

这个算法步骤图中,最关键的是 inter-task adjustment 和 intra-task adjustment
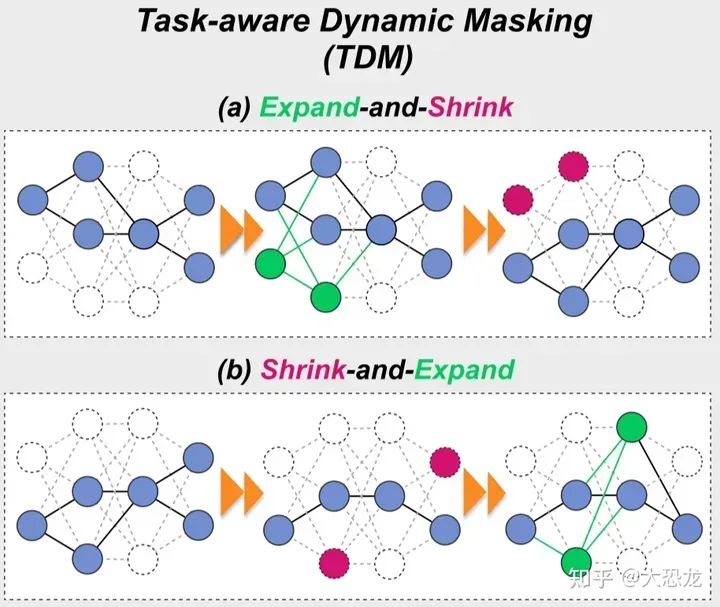
上图中(a)为inter-task adjustment. 在每次引入新任务时,因为在上一个任务的训练时,已经充分将留存的sparse权重训练过了,如果直接训练新任务,那么很有可能将对上一个任务重要的权重更改。因此,先对模型expand,“故意”留一些空白权重出来,让新任务的knowledge更多地被这些空白权重学到,这样就不会mess up之前任务的权重了。然后在训练过 delta k step 之后,再shrink使得模型恢复之前的sparse ratio。
图中(b)为intra-task adjustment. 这里采用了先shrink 再 expand 来更新mask的方法。通过将less important的weights 除掉,然后一段时间后再随机增加weights来恢复模型的learning capacity。
Dynamic Data Removal
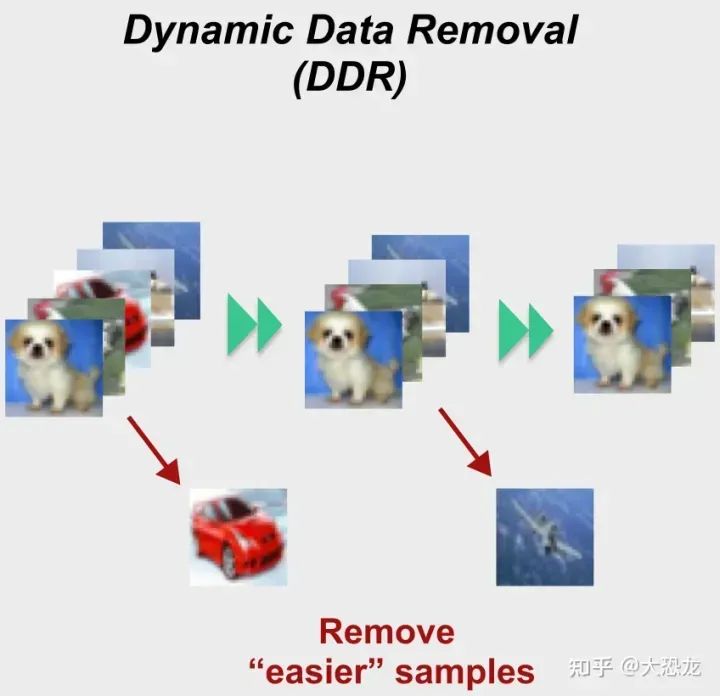
我们前面已经分析过,靠常规的网络稀疏化是无法提升效率的。那本文的最大特色训练速度大幅提升是怎么实现的呢?就是通过这里的DDR实现的。
DDR是一个非常简单的方法,它通过训练过程中各个数据项的错误分类次数,判断谁是easy example,谁是hard example,然后将easy examples从训练数据中删掉。
具体地,在TDM算法中,每 δk个epoch会进行一个intra-task adjustment,那么这里DDR在这intra-task adjustment时就来做data removal。Kt为当前任务的总epoch数;δk为进行intra-task adjustment的inverval;因此 Nt即为进行intra-task adjustment 的次数。

ρ是人为设定的removal ratio;cutoff是执行data removal的次数,下方公式表示一共 Nt次intra-task
adjustment,只有前cutoff次执行data removal,每次remove ρi 的数据。
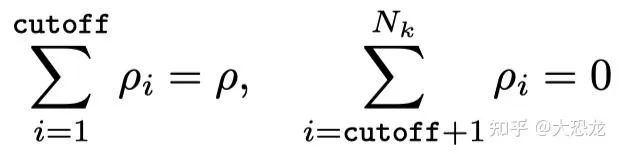
这个DDR在减少了训练数据量的同时,还产生了一些其他的效果:
由于训练数据中少了那些easy example,那么在每个任务结束时将当前数据集添加进memory buffer时,就能把那些更hard、更imformative的example添加进去。
rehearsal-based方法通常还会面临数据不平衡问题。因为memory buffer通常不能太大,这样current task dataset和memory buffer的大小比例就会比较悬殊。而这里对训练数据进行了“瘦身”,因此能有效缓解这个不平衡问题。
关于这个DDR,我还想再说几句。这个思想借鉴了机器学习里非常经典的ensamble learning的adaboost算法。adaboost是通过顺序性训练多个小模型集成而得到一个大的模型。每次训练小模型后,会根据misclassification来给数据赋予不同的权重,增加分类错误的的数据的权重,减少分类正确的错误的权重,这样后面的模型就会将主要的精力放在解决那些hard的example上。
那这个思路为什么似乎在深度学习任务上很少见到呢?我认为主要是深度学习的数据集通常都很大。比如训练imagenet时,一个epoch就要跑很久。而对一个example来说,至少需要好几次的试验才能做出合理判断,是否这个真的很easy,可以丢弃掉。那么经过很多epoch试出来哪些是easy的,哪些是hard的,可能模型就差不多收敛了。
但是这个思路真的很适合要跑很多个epoch的小数据集,连续学习任务目前都是在MNIST、CIFAR10、TinyImagenet等小数据集上训练。尤其是在Class-IL情形中,把数据集给split成更小的几份,就更加适合了。所以这个idea可以着重记一下,有可能可以作为一个general的trick来用到所有的连续学习任务上。
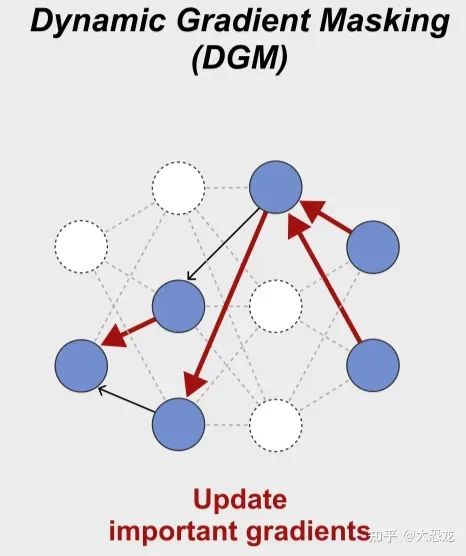
Dynamic Gradient Masking
这部分的算法通过CGI (Continual Gradient Importance) 计算训练过程中各个梯度的重要性。这个CGI的计算和权重重要性(CWI)很相似,除了没有CWI的第一项权重的绝对值,其余两个部分是一样的。
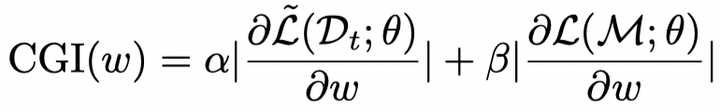
将计算出的重要性通过mask的方式,来将稀疏梯度更新到网络上。
这个模块使得训练能够focus在更重要的梯度上,同时也能够使得一部分权重没有更新,这为不遗忘在过去任务上学到的知识提供了途径和空间。
05
实验部分
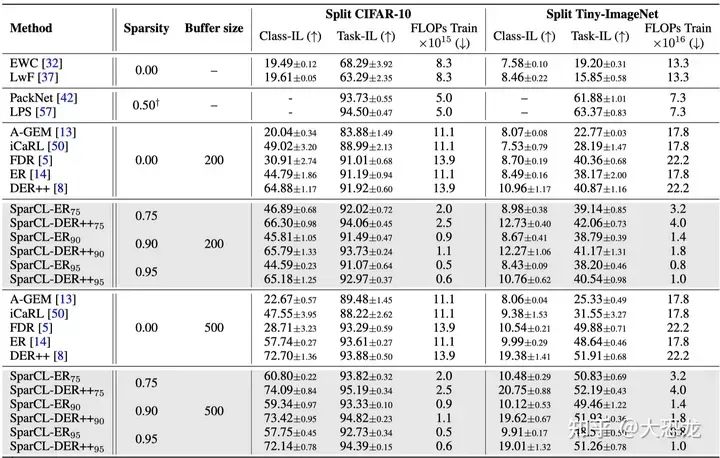
通过实验结果可以看出,SparCL确实能够在很高的sparsity的情况下达到比SOTA(DER++)还要好一些的结果。稀疏性即使达到95%也还是有很高的准确率。而且准确率会随着我们增大buffer size而增加。
06
总结
这篇文章讲的这个关于sparsity的故事完整性很好,不过我最大的收获反而是data removal的方法,我认为这个方法应该对于所有的连续学习算法都有借鉴意义,之后也会尝试跑一跑其代码,实际感受一下本方法的效果。
提
醒
点击“阅读原文”跳转到1:22:01可以查看回放哦!
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1000多位海内外讲者,举办了逾550场活动,超600万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!