目录
会议:MICCAI 发表时间:2021/1
作者:Sharif Amit Kamran1 , Khondker Fariha Hossain1 , Alireza Tavakkoli1 , Stewart LeeZuckerbrod2 , Kenton M. Sanders3 , and Salah A. Baker3
MICCAI介绍:
MICCAI是医学影像分析领域的前沿热点风向标,具有非常强的国际影响力和高学术权威性,属于中高端级别的期刊。 MICCAI是国际公认的跨医学影像计算和计算机辅助介入两个领域的顶级综合性学术会议

1.网络架构
总述:为了更好地进行逐像素分割,所以这篇论文设计了一个既能从图像中提取全局特征又能提取局部特征的架构。具体来说就是采用两个生成器和两个鉴别器,其中生成器Gf 通过提取比如说细小的分支等局部信息来分割图像,相比之下,生成器Gc试图学习和保存全局信息,比如说黄斑分支的结构,同时产生较不那么详细的微血管分割。然后为了有助于整体的对抗训练,我们分别配对了生成器对应的鉴别器。
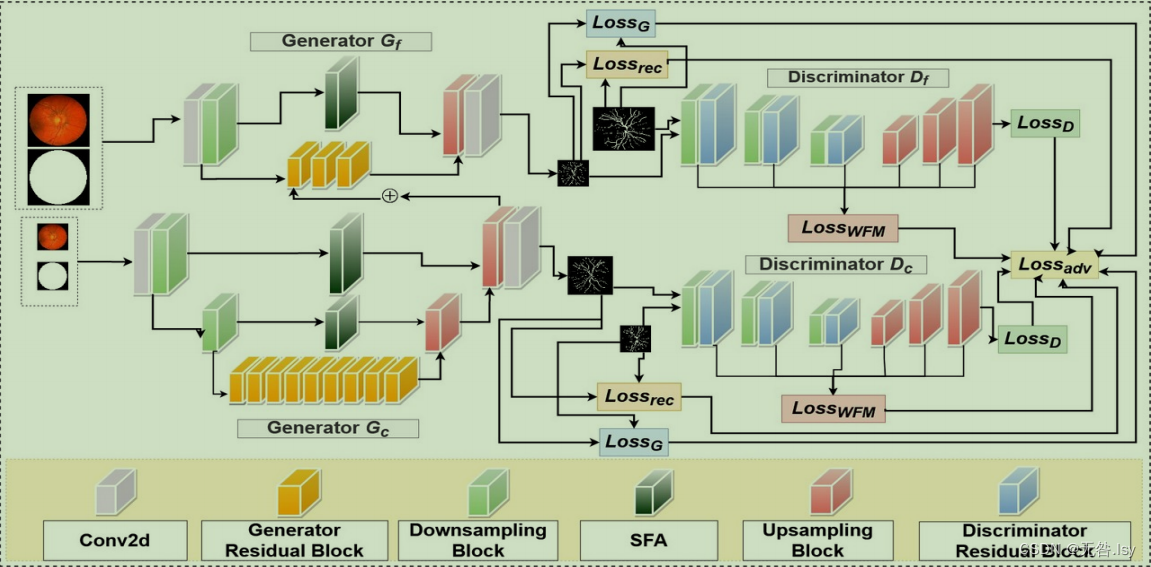
详细来说:
对于Gc,我们可以看到它的输入是两部分,原图(256,256,3)和掩膜(256,256,1)。输入这两部分之后,先将这两部分做了一个拼接的工作,然后在对拼接过后的基础上对图像进行了一个3×3的镜像填充,然后接着才是卷积,卷积完之后是归一化和LeakRelu激活。然后是下采样,其中下采样的模块如下图所示。接下来可以看到我们有两层下采样模块,图像每经过一次下采样通道数就会变成原来的两倍,接下来就是九个残差块,如下图所示。然后就是两个上采样操作,具体来说就是残差块之后的这个输出先进行了一个decoder解码的操作,然后把解码之后的结果与左边的部分进行简单的相加作为下一个上采样的输入,然后同理,将上一步的输入进行上采样操作之后与左边的部分进行简单的加和,加和完之后有两个箭头的指向吧,一个是作为Gf残差块的输入。然后另一个是一个3×3的镜像填充,然后才是卷积,卷积完之后是一个tanh激活。激活完之后的结果就作为生成器特征图的输出,同时也是鉴别器Dc的输入。
对于Gf,可以看到它有三部分的输入,分别是原图(512,512,3),掩膜(512,512,1)和x_coarse(256,256,64)。然后接下来的操作跟Gc是大致相同的。然后说一下不同的地方。第一个不同点是输入图像的大小和有一个来自Gc的输入;第二个不同点是上采样和下采样只有一层,SFA模块也只有一层,还有就是残差块只有三层,整体来说对图像的操作步骤比Gc少。
对于Df,有两部分输入,分别是眼底图像(512,512,3)和标签(512,512,1)。先将这两部分的输入进行一个简单的拼接,然后就是3个下采样和残差块,和3个上采样模块。我们可以看到一共有六部分的操作,代码中设计了一个保存特征图的列表,也就是说每经过一部分就会保存这部分的特征图到列表中。实际上在实行完之后还有Conv2D卷积和tanh激活。
对于Dc,和Df的操作相似

2.损失函数
特征匹配损失:特征匹配损失通过从鉴别器中提取特征来进行语义分割
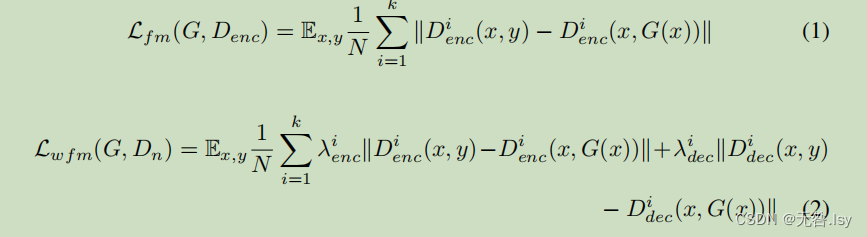
通过连续的下采样和上采样,我们丢失了基本的空间信息和特征;这就是为什么我们需要给整体架构中的不同组件赋予权重。我们提出了一种新的加权特征匹配损失,如等式 1 所示。等式2 它结合了来自编码器和解码器的元素,并优先考虑特定的特征来克服这一点。对于我们的情况,我们实验并看 到给予解码器特征图更大的权重导致更好的血管分割
对于(1),k是指像素点的个数,N是特征图的个数。可以看到它是对于鉴别器中的编码器来说的一个当输入分为原图,标签和原图,生成器生成图时所对应的两个特征图的每一个相对应位置的像素点相减,然后分别再加绝对值,再平方他,求和最后开2次根号。最后除以N求平均。
对于(2),相当于在(1)的基础上对不同输入上的解码器做相同的操作,然后将这两部分加在一起,并添加两个超参数。
通过从鉴别器的编码器和解码器的每个下采样块和上采样块中提取特征来计算。我们连续插入真实的和合成的分割图。N 表示特征的数量。这里,λenc 和 λdec 是每个提取的特征图的内部权重乘数。权重值在[0,1]之间,并且权重的总和是 1,并且我们对解码器特征映射使用比编码器特征映 射更高的权重值。
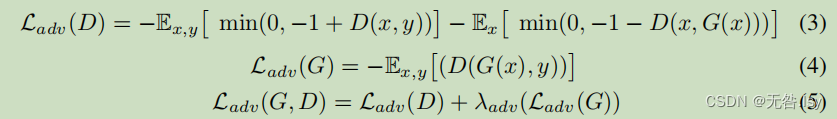
对于(3),使鉴别器生成的特征图中各个像素点大于1或者小于-1的部分,loss等于0,也就是说这部分是确定的结果。而对于在-1到1之间是像素点,loss不为0,也就是说是不确定的结果,这个时候就需要通过不断修正loss,使它达到最小值来训练我们这个网络。
对于(4),我们可以看到在鉴别器中通过输入生成器的生成的图片和标签,然后它的一个结果是一个特征图。(4)的意思是让特征图内每一个值求平均。
对于(5),就是将(3)和(4)这两部分加起来。
我们首先在真实眼底 x 和真实分割图 y 上训练鉴别器。之后,我们用真实眼底 x 和合成分割图 G(x)进行训练。我们开始分批训练鉴别器 Df 和 Dc,对训练数据进行几次迭代。接下来,我们训练 Gc,同 时保持鉴别器的权重不变。以类似的方式,我们训练 Gf批量训练图像,同时保持所有鉴别器的权重不变。
生成器还包含重建损失(均方误差),如等式(6)所示。 通过利用损失,我们确保合成图像包含更真实的微血管、动脉和血管结构
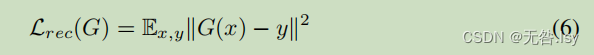
通过加入等式2, 5 和 6, 我们可以将我们的最终目标函数公式化为等式(7)

3.数据集
我们使用的是三个公开视网膜数据集:DRIVE ,CHASE-DB1 , STARE,格式分别是:tif(565 × 584),.jpg(999 × 960), and .ppm(700 × 605)
3.1数据集介绍
DRIVE数据集,视网膜图像中对血管分割进行比较研究,数据来源与糖尿病视网膜病变筛查项目,40张视网膜图片,20张样本用作训练,20张样本用做测试,图像的原始大小为565x584
CHASE-DB1训练20张,测试8张,图片的原始大小是999×960
STARE数据集 是 1975 年由 Michael Goldbaum 发起的项目, 它在 2000 年由 Hoover 等首次在论文中引用并公开,是用来进行视网膜血管分割的彩色眼底图数据库, 包括 20 幅眼底图像, 其中 10 幅有病变, 10 幅没有病变, 图像分辨率为 605×700, 每幅图像对应 2 个专家手动分割的结果, 是最常用的眼底图标准库之一.。但是其自身的数据库中没有掩膜,需要自己手动设置掩膜。目前它已扩展到 40 幅血管分割手工标注结果和 80 幅视神经检测手工标注结果。训练16张,4张用于测试。
3.2数据预处理
我们训练三种不同的 RV-GAN 网络其中每个数据集使用 5 重交叉验证。我们使用跨度为 32、图像大小为 128×128的重叠图像补片进行训练和验证。因此,我们最终有 4320 个用于STARE,15120个用于CHASE-DB1,4200 个用于DRIVE。重叠补丁对数据进行扩充.
DRIVE数据集带有测试图像的官方 FoV 遮罩。对于CHASE 和 STARE 数据集,我们也生成类似于李等人的 FoV 掩模[16]. 为了测试,
通过从 DRIVE、CHASE-DB1 和 STARE 拍摄 20、8 和 4 幅图像,提取步幅为 3 的重叠图像补片并进行平均。
3.3参数初始化
对于对抗性训练,我们使用铰链损失. 我们选择 λenc = 0.4(等式。1),λdec = 0.6(等式 2), λadv = 10(等式。5), λrec = 10(等式 6) 并且 λwfm = 10(等式。7). 我们使用了Adam, 学习率 α =0.0002,β1 = 0.5,β2 = 0.999。我们使用 Tensorflow 分三个阶段用批量大 小为 b = 24 的小批量训练 100 个时期。在英伟达 P100 GPU 上训练我们的模型花费了 24-48 小时取决于数据集。因为与CHASE-DB1 相比,DRIVE和STARE的补丁数量较少,所以训练量较少。推断时间是每幅图像 0.025 秒。
4.实验结果

在 AUC-ROC、Mean-IOU 和 SSIM(该任务的三个主要指标)方面,我们的模型优于 UNet 衍生的架构和最近基于 GAN 的模型。M-GAN 在CHASE-DB1 和 STARE 中实现了更好的特异性和准确性
5.结论
本文提出了一种新的多尺度生成架构 RV-GAN。通过结合我们以匹配损失为特征的新颖方法,该体系结构综合了精确的小静脉结构分割和两个相关度量的高置信度得分。因此,我们可以在眼科的各种应用中有效地采用这种架构。该模型最适合于分析视网膜变性疾病和监测未来预后。我们希望将这项工作扩展到其他数据模式。