1.论文
这些开发由两个关键组件提供动力:大型预训练语言模型(LM)和人工编写的指令数据。
1.1 背景
- 目前的训练太吃数据了,需要使用一些替代方法减少对数据的依赖
- 有
微调过的数据集效果远好于没有微调
用什么数据集微调呢?
基于人类指令性命令及其期望结果的数据集 - data越大,潜在可完成的任务就越多
这篇论文旨在通过减少对人工注释的依赖来解决这个瓶颈。
1.2
基本上一张图可以涵盖这篇论文的内容
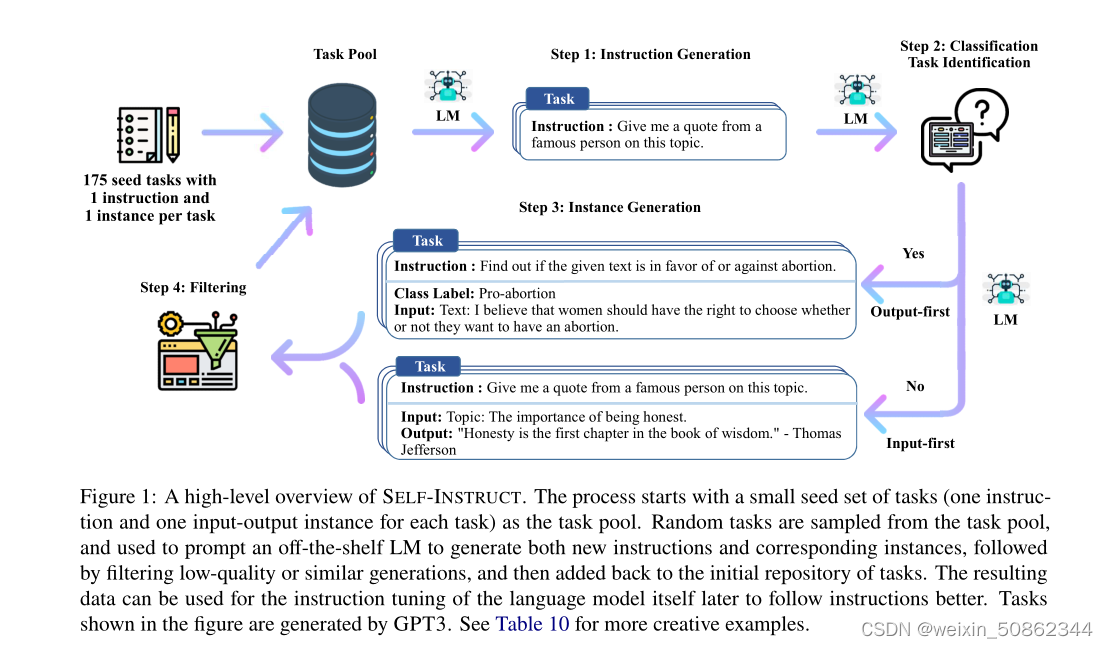
2. fintune
【网址】alpaca-lora
我12G4070显卡非常极限的完成了训练
参数如下:
python finetune.py --base_model 'decapoda-research/llama-7b-hf' \
--data_path 'yahma/alpaca-cleaned' --output_dir './lora-alpaca' \
--batch_size 16 --micro_batch_size 1 --num_epochs 2 \
--learning_rate 3e-4 --cutoff_len 256 --val_set_size 2000 \
--lora_r 8 --lora_alpha 16 --lora_dropout 0.05 --lora_target_modules '[q_proj,v_proj]' \
--train_on_inputs --group_by_length
2.1 out of memory 问题
在保存权重的时候出现oom,bitsandbytes版本问题
建议版本:
pip install bitsandbytes==0.37.2
2.2 transform 版本
某些transform版本会出现AutoModelForCausalLM等的错误