在多因子选股的框架下,因子的产生通常有两条途径:
- 先有逻辑,后有公式:根据经济学逻辑、历史经验、直觉进行人工构造一些因子;
- 例如:动量(Momentum)因子:当最近的股价呈现连续上升时,认为股价产生了 “动量”,这样的动量会持续一段时间,因此当期股价
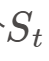 相对于前期股价
相对于前期股价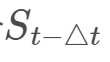 的涨幅
的涨幅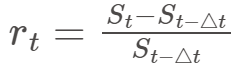 可能决定了一期股价
可能决定了一期股价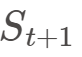 的走势,那么
的走势,那么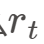 可以作为一个简单的动量因子,认为它潜在地与未来收益率
可以作为一个简单的动量因子,认为它潜在地与未来收益率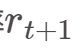 相关
相关
- 例如:动量(Momentum)因子:当最近的股价呈现连续上升时,认为股价产生了 “动量”,这样的动量会持续一段时间,因此当期股价
- 先有公式,后有逻辑:使用大量的历史数据与收益率数据,通过机器学习的方法进行拟合,大批量的生成因子;
- 例如:利用遗传规划(������� �����������)进行符号回归(�������� ����������)
- 这就是本文要引入的第一个话题
符号回归 (Symbolic Regression)
从参数估计讲起
有统计学基础的伙伴都知道,许多较为简单的机器学习模型本质是在做参数估计。比如我们想要对X 与Y 之间的关系进行挖掘,我们首先假设他们有如下的关系:
�=�(�)
其中,� 是我们已经假设好,或者挑选好的形式,比如:�(�)=�0+�1�+�2�2
那么我们传统的机器学习,或者说统计回归,都是对参数θ0,�1,�2 进行估算,使得我们根据Y=�(�) 算出的预测值Y^ 与真实值Y 之间的差距尽可能的小,即我们需要:
��� ||�−�^||2
总结之,我们的有如下的流程:
- 获取已有的样本特征(�������)� 与样本标签(�����)� 数据
- 人工挑选或构建Y 与X 之间的关系,即模型的显示形式f(�^|�)
- 通过调整参数θ^,使得预测值与真实值尽可能接近(过拟合的问题不是这里的重点)
- 完成模型的学习,模型f(�|�) 用于未来的预测等功能
看起来很完美了,那为什么还需要符号回归呢?问题在于f 形式的选取。结合前言的叙述,很容易想到:
- 传统的参数估计思想→给定公式的形式,优化公式的内部(基于参数的优化)
- 所围的符号回归思想→不给定公式的形式,从公式里面挑选(基于公式的优化)
这样,符号回归的意思就很明显了:用各种变量与算子(符号)构造许多公式,用不同的公式去逼近数据的真实分布,达到回归的效果。
符号回归的实现
符号回归听起来很不错,但是怎么实现呢?参数回归本质是在高维空间对参数进行有规律的搜索,从而达到优化目的。符号回归也要在 “符号空间” 里进行搜索吗?实际上是的。
我们假设两个变量 � 和 � 的真实关系就是下面这样:
�=1+�+�2+�3
现在我们有来自这个关系的数据样本:(−1,0),(0,1),(1,4),(2,15)
假设我们随便进行两个猜测:
�����1:�=�+�2; �����2:�=1+�+�2
很明显,�����2 更好,所以我们抛弃了G����1,走向了G����2。
那如果再来一个呢?
�����2:�=1+�+�2; �����3:�=1+�+�2+�3
无疑地,我们从G����2 走向了G����3,我们离 “正确” 答案越来越近了!(甚至已经完美达到了正确答案)
其实以上过程已经大体揭示了遗传规划进行符号回归的大体思路:产生很多公式,然后优中选优,然后再产生,再优中选优…. 总体上,我们会越来越接近。
遗传规划 (Genetic Programming)
基本概念
经过漫长的 General Sense 的讲解,相信可以明白:遗传规划是借鉴了生物种群的进化理论,认为优秀的 “基因”(����),也就是公式对数据的拟合能力,会在一次又一次的产生、挑选、变异、交叉中被保存、传递。
在开始遗传规划的具体步骤之前,我们需要知道几个基本概念:
-
公式树:任意一个合法的数学公式,都可以改写为一棵树(����)
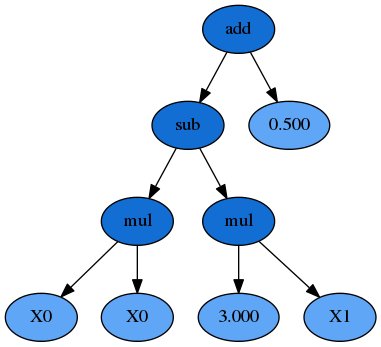
例如:�=�02−3�1+0.5 可以改写为:�=�0×�0−3×�0+0.5,转换为一个 S - 表达式(�−����������)即为:�=(+(−(×�0�0)(×3�1))0.5),那么他的公式树就长成这个样子:
-
变量 / 常数:公式树的叶子,含一个数值
-
算子:公式树的结点,是一个对变量 / 常数的运算函数
主要步骤
由以上基础,遗传规划的主要步骤如下:
定义算子库与变量 / 常数库:首先要清楚你有几个变量、叫什么名字,有哪些算子、算子的具体内容;
- 算子库例如:+、-、×、÷、平方根、相反数….
- 变量库例如:开盘价、收盘价、交易量…
生成公式种群:从因子库和变量库里获取元素,随机组成若干公式树,这是 “公式种群”;
定义适应度函数:“选优” 的标准是什么?需要定义一个函数评估公式的优劣,很明显,适应度函数通常(只是通常)衡量通过公式计算的结果与真实数据的差距;
- 例如:评价X 的一个适应度函数F(�)=||����(�)−(�2)||1,衡量根据公式树t���(·) 计算的结果t���(�) 和y=�2 之间的差的一范数
自然选择 / 选优:从公式种群中,挑选适应度最高(或最低)的一批公式,作为优种;
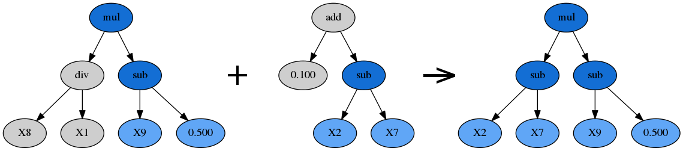
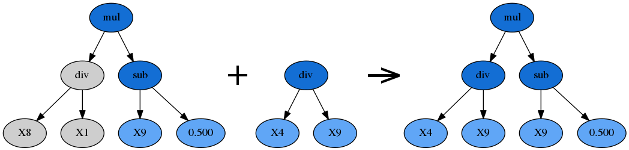
交叉组合与基因变异:
很明显,这都是从自然进化中启发而来的,主要是为了保持公式树的多样性,提升公式树种群的 “潜力”
具体来说,是在不同的公式树之间进行:
- 交叉 (���������):
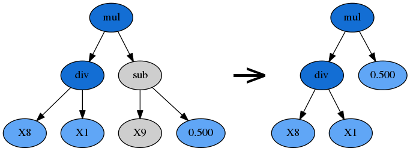
- 子树变异 (������� ��������)
- Hoist 变异 (����� ��������)
- 点变异 (����� ��������)
循环进行 4-5,直到达到设定的条件

因子挖掘
很明显,遗传规划算法可以用于因子挖掘,只需要将对应的基础概念代入即可:
- 公式树 → 用一些基础因子组合成的新因子
- 变量 / 常数 → 基础因子
- 例如:最基本的 “开高低收” 这样的行情属性)
- 算子 → 基础算子(+ - × ÷)或时序算子(MA)等
遗传迭代的过程,即代表因子挖掘的过程:
- 公式种群 → 一批挖出的因子
- 适应度函数 → 评估因子的一些指标
- 例如:因子暴露与一期收益的相关系数I�
- 自然选择 / 选优 → 选择评价最好的因子,传入下一代
反思:为什么要用 Genetic Programming?
用一个模型不是为了用而用。遗传规划之所以可以用于尝试因子挖掘的一个方向,笔者认为有如下几个原因:
- 生成海量新因子:在生成初代种群的时,可以快速生成海量的新因子;
- 遗传迭代的过程模拟了 “符号搜索” 的过程:通过每一代的选优,可以快速对符号结构进行筛选和优化;
- 保留符号的变异性、多样性,防止过拟合速度过快:在每一代的繁殖过程中,交叉和变易保证了新因子结构的潜力,从而可以防止过快的过拟合。