小白记录帖嘛,全程一些或对或错的碎碎念orz。。。
分类器用resnet50作为backbone,在此基础上将2048维输出先映射为512维,然后512维变为40分类的32维embedding,再变为40个1维分数,concat成Bx40x32的embedding以及Bx40的logits;用celebahq的数据集来跑:27000张作为training set,3000张作为validation set;训100个epoch。
Round 1
超参:learning_rate=0.001,batch_size=4,test_batch_size=2
* 因为不知道test_batch_size是单独出来的,所以前面几次实验都只改了batch_size(也就是train_batch_size)
q实验结果:如图,train loss非常震荡,test loss从epoch30起又抬回去了,我就在想,test loss一直没有train loss低,并且开始回升得比train loss早,这是不是过拟合了呀?

过拟合的话,难道是我在backbone之后添加的几层参数量大?我修改了网络模型,然后在logits那儿加了层BN。因为上课的时候说,Normalization是防过拟合的操作之一嘛。改完进行了第二轮实验:
Round 2
超参:learning_rate=0.001,batch_size=4,test_batch_size=2
* 没变超参
实验结果:OMG怎么train loss怎么不降啊,还不如第一次实验低了?难不成我一点小改动让它从过拟合变欠拟合了不成?

痛定思痛,然鹅我不愿再面对网络模型的改,所以先来动一动超参看看。首先,尝试了降低学习率和batch_size:
Round 3
超参:learning_rate=0.0007,batch_size=2,test_batch_size=2
实验结果:这次我没等它跑完100个epoch就kill了程序.....怎么一次不如一次了。

我去求助了师姐,师姐让调大batch_size试试,因为她训分类器从来不用这么小的batch_size,她用的32......她让我调大batch_size直至显卡跑满,我想先用32试试,显卡占用率67%:
Round 4
超参:learning_rate=0.001,batch_size=32,test_batch_size=2
* 是的,这一次也漏掉了test_batch_size
实验结果:又回到最初的曲线,呆呆地站在电脑前......anyway,train loss随batch_size增大变平滑了。

这时候我发现了test_batch_size一直没改,所以试了一下改动它,和batch_size保持一致:
Round 5
超参:learning_rate=0.001,batch_size=32,test_batch_size=32
实验结果:然并卵,和前次没区别。。。

单独调学习率试试:
Round 6
超参:learning_rate=0.0005,batch_size=32,test_batch_size=32

test loss曲线抬高没那么明显了但是!俩loss曲线也不怎么下降啊?好奇怪!试一试大一点的学习率:
Round 7
超参:learning_rate=0.0015,batch_size=32,test_batch_size=32

没跑完就kill掉了,因为这个test loss的上升趋势令我感到害怕...这样看起来,还是调小学习率吧。上次调小到了0.0005现在再小一点到0.0001试试:
Round 8
超参:learning_rate=0.0001,batch_size=32,test_batch_size=32

曲线上比较像学习率等于0.0005的那次,但是test loss在数值上优于round 6。再去log文件里看一眼准确率,其实以上实验大多epoch中的test准确率都在89左右,并没有怎么大幅度变化,round 8第一次在epoch 100还保持了90分的准确率,那我就选round 8作为best model好了..
⬆0401初记录
⬇0407更新
汇报给了导师,导师无语住了,说我train loss抬升或者不动了的时候就应该kill掉程序,而不是继续跑完浪费电,泪目.....
导师云:在如round 4的情况中,epoch14左右就可以保存模型停下来,然后load这个模型继续用更小的学习率训练。
我就去试了,用上述方法,换了个0.0001的学习率训练:
Round 9

这个妥妥的过拟合趋势....我懂了,这次及时kill掉,贯彻导师的环保主义理念。
是学习率太小了吗这次,换个大点的0.0004试一下子:
Round 10

怎么也逃不出...过拟合的命运。
⬇0501更新
本以为虽然曲线不好看,但验证集准确率89-90还不错可以拿来做我的主实验了,结果不行,用分类器embedding比较距离的loss非常小,根本起不到约束的作用了嘛!
之前的模型老过拟合,怀疑是网络太深参数太多之类的?
首先尝试修改我加的那几层,把2048-512-32-1的映射过程改为2048-64-16-1,然并卵,用0.001学习率先学仍在同样位置过拟合,且换0.0001的小分辨率test loss只升不降。
于是乎改掉resnet50,改用alexnet(导师说alexnet应该就够用了),然后alexnet最后三层FC改为9216-4096-4096-512,然后继续512-32-1造出40属性分类的embedding。
Round1
左:lr=0.001,bs=32
右:lr=0.0005,bs=32
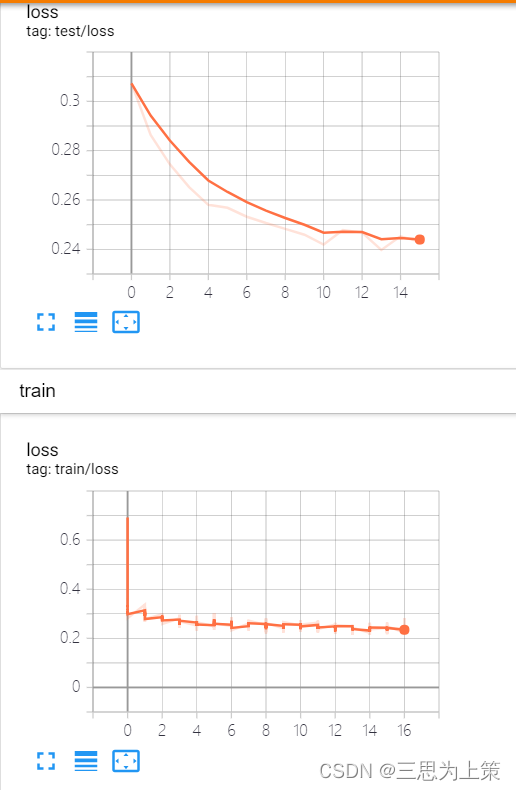

由于右边的曲线数值更低,我kill了左边,只跑lr0.0005的这个实验。
Round2
同时,我考虑是不是lr越低越好,然后还想动一下bs,所以设了一个lr0.0003,bs16的实验。
左:lr=0.0005,bs=32
右:lr=0.0003,bs=16
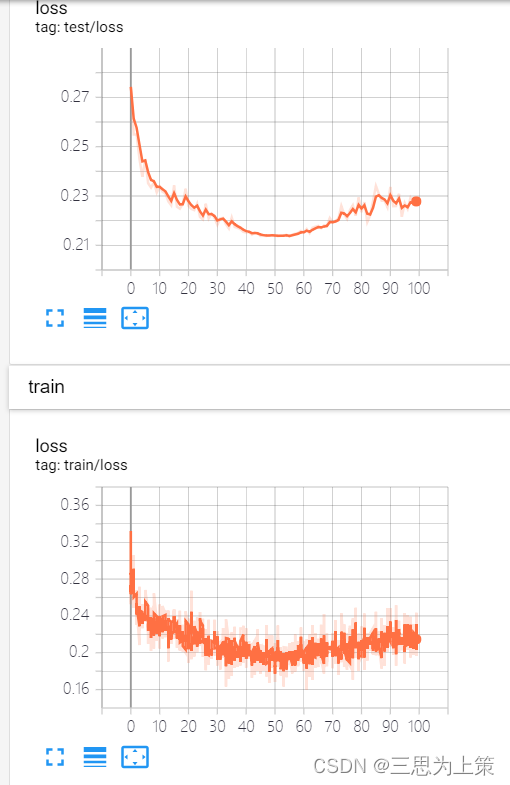
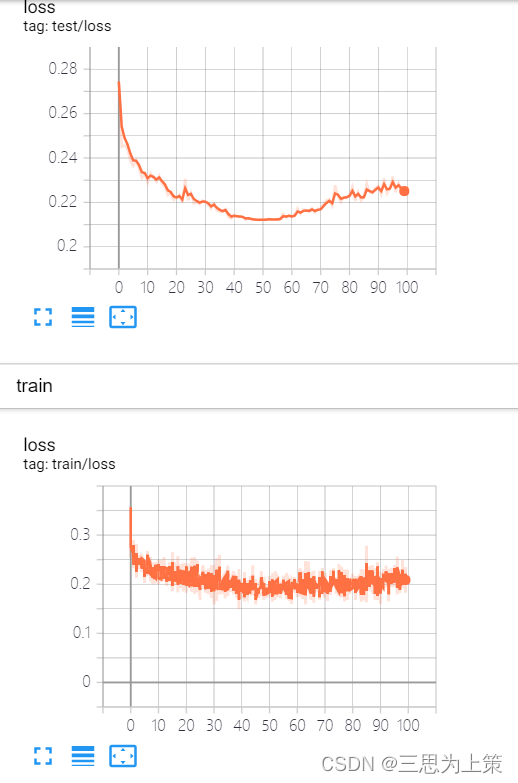
就..差不多,train loss和test loss同时在epoch50左右不降反升了?晕。。。
Round3
尝试取Round2右边训练epoch50的模型参数继续以0.0001学习率来训,bs32,曲线非常震荡,但是在下降,如左图。
同时考虑手动调整学习率太伤了,加入scheduler余弦退火试试,如右图。