1 安装Flink

使用Flink 1.12版本,部署Flink Standalone集群模式,启动服务,步骤如下:
step1、下载安装包
https://archive.apache.org/dist/flink/flink-1.12.2/
step2、上传软件包
flink-1.12.2-bin-scala_2.12.tgz 到node1的指定目录
step3、解压
tar -zxvf flink-1.12.2-bin-scala_2.12.tgz -C /export/server/ chown -R
root:root /export/server/flink-1.12.2/
step4、创建软连接
ln -s flink-1.12.2 flink
step5、添加hadoop依赖jar包
cd /export/server/flink/lib
使用rz上传jar包:flink-shaded-hadoop-2-uber-2.7.5-10.0.jar
step6、启动HDFS集群
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
step7、启动Flink本地集群
/export/server/flink/bin/start-cluster.sh
使用jps可以查看到下面两个进程

停止Flink
/export/server/flink/bin/stop-cluster.sh
step8、访问Flink的Web UI
网址:node1:8081/#/overview
step9、执行官方示例
读取文本文件数据,进行词频统计WordCount,将结果打印控制台。
/export/server/flink/bin/flink run
/export/server/flink/examples/batch/WordCount.jar
2 快速入门
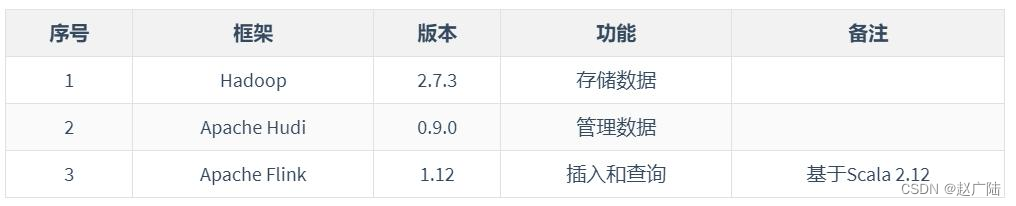
基于Flink操作Hudi表数据,进行查询分析,软件版本说明如下:
2.1 集成Flink概述
Flink集成Hudi时,本质将集成jar包:hudi-flink-bundle_2.12-0.9.0.jar,放入Flink 应用CLASSPATH下即可。Flink SQLConnector支持Hudi作为Source和Sink时,两种方式将jar包放入CLASSPATH路径:
● 方式一:运行Flink SQL Client命令行时,通过参数【-j xx.jar】指定jar包

● 方式二:将jar包直接放入Flink软件安装包lib目录下【$FLINK_HOME/lib】

接下来使用Flink SQL Client提供SQL命令行与Hudi集成,需要启动Flink Standalone集群,其中需要修改配置文件【$FLINK_HOME/conf/flink-conf.yaml】,TaskManager分配Slots数目为4。

2.2 环境准备
首先启动各个框架服务,然后编写DDL语句创建表,最后DML语句进行插入数据和查询分析。按照如下步骤启动环境,总共分为三步:
● 第一步、启动HDFS集群
[root@node1 ~]# hadoop-daemon.sh start namenode
[root@node1 ~]# hadoop-daemon.sh start datanode
● 第二步、启动Flink 集群
由于Flink需要连接HDFS文件系统,所以先设置HADOOP_CLASSPATH变量,再启动Standalone集群服务。
[root@node1 ~]# export HADOOP_CLASSPATH=
$HADOOP_HOME/bin/hadoop classpath[root@node1 ~]# /export/server/flink/bin/start-cluster.sh
● 第三步、启动Flink SQL Cli命令行
[root@node1 ~]# /export/server/flink/bin/sql-client.sh embedded shell
采用指定参数【-j xx.jar】方式加载hudi-flink集成包,命令如下。
[root@node1 ~]# /export/server/flink/bin/sql-client.sh embedded -j
/root/hudi-flink-bundle_2.11-0.9.0.jar shell
在SQL Cli设置分析结果展示模式为:set execution.result-mode=tableau;。
2.3 创建表
创建表:t1,数据存储到Hudi表中,底层HDFS存储,表的类型:MOR,语句如下:
CREATE TABLE t1(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://node1.oldlu.cn:8020/ehualu/hudi-warehouse/hudi-t1',
'write.tasks' = '1',
'compaction.tasks' = '1',
'table.type' = 'MERGE_ON_READ'
);
在Flink SQL CLI命令行执行DDL语句,截图如下所示:
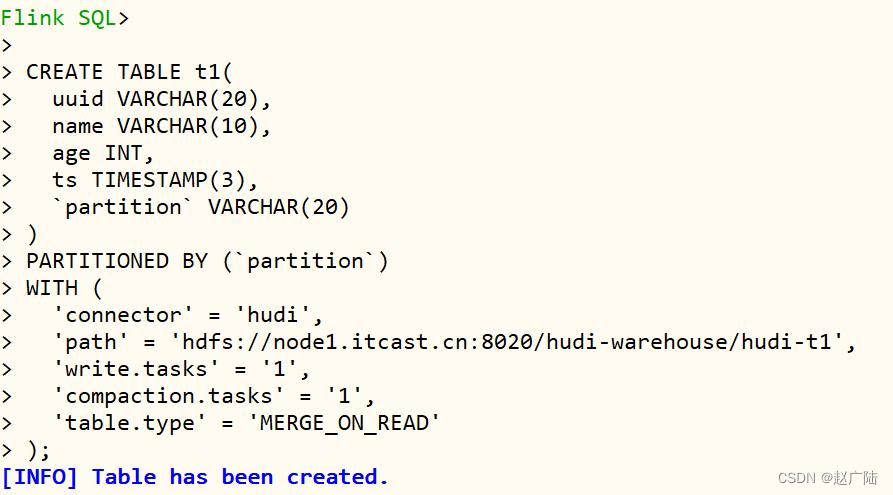
查看表及结构,命令如下:
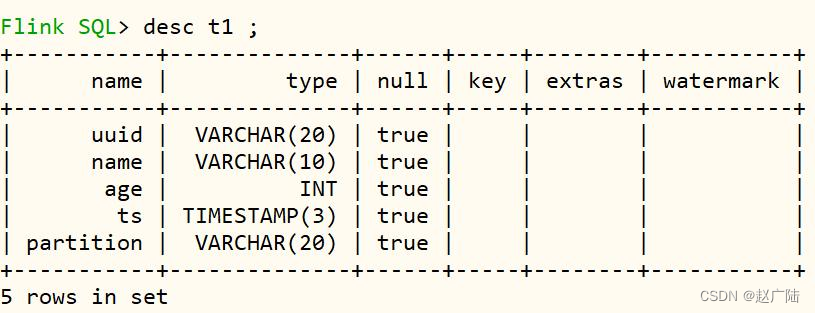
接下来,编写INSERT语句,向Hudi表中插入数据。
2.4 插入数据
向上述创建表:t1中插入数据,其中t1表为分区表,字段名称:partition,插入数据时字段值有:【part1、part2、part3和part4】,语句如下:
INSERT INTO t1 VALUES
('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1');
INSERT INTO t1 VALUES
('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),
('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),
('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),
('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),
('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),
('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),
('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');
在Flink SQL CLI中执行截图如下:
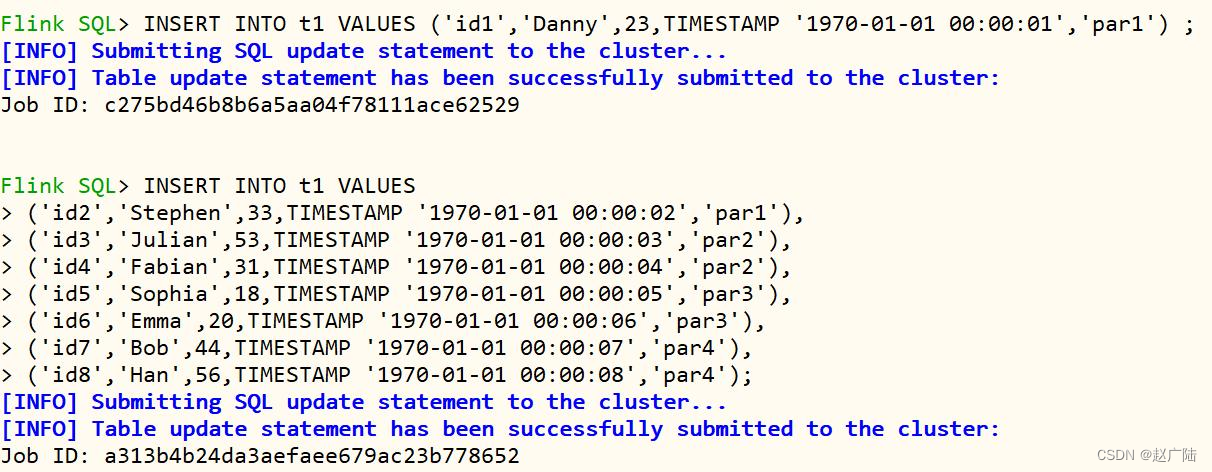
日志信息可知,将SQL语句提交至Flink Standalone集群执行,并且insert语句执行成功。
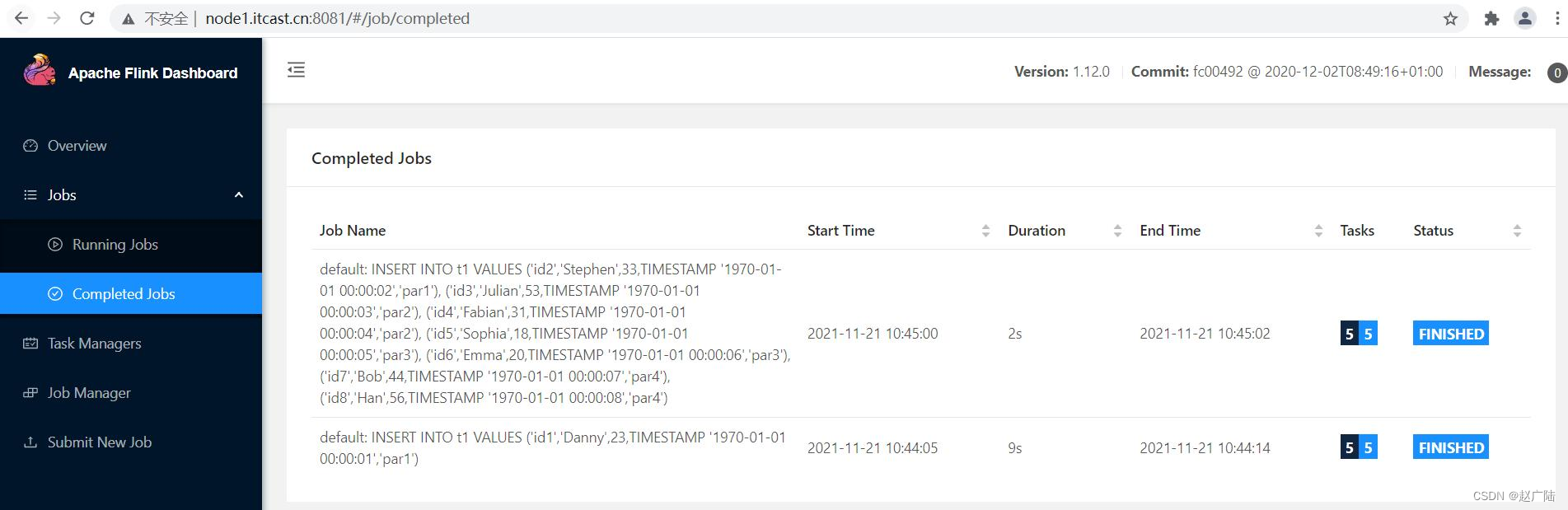
查询HDFS上数据存储目录:
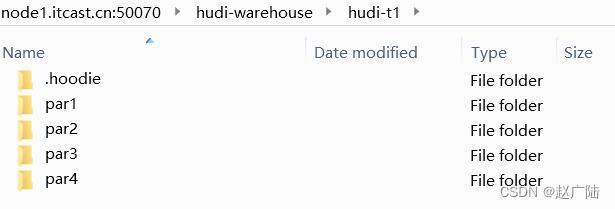
2.5 查询数据
数据通过Flink SQL CLi插入Hudi表后,编写SQL语句查询数据,语句如下:
select * from t1;
与插入数据一样,向Standalone集群提交SQL,生成Job查询数据。

通过在 WHERE 子句中添加 partition 路径来裁剪 partition,如下所示:
select * from t1 where
partition= ‘par1’ ;

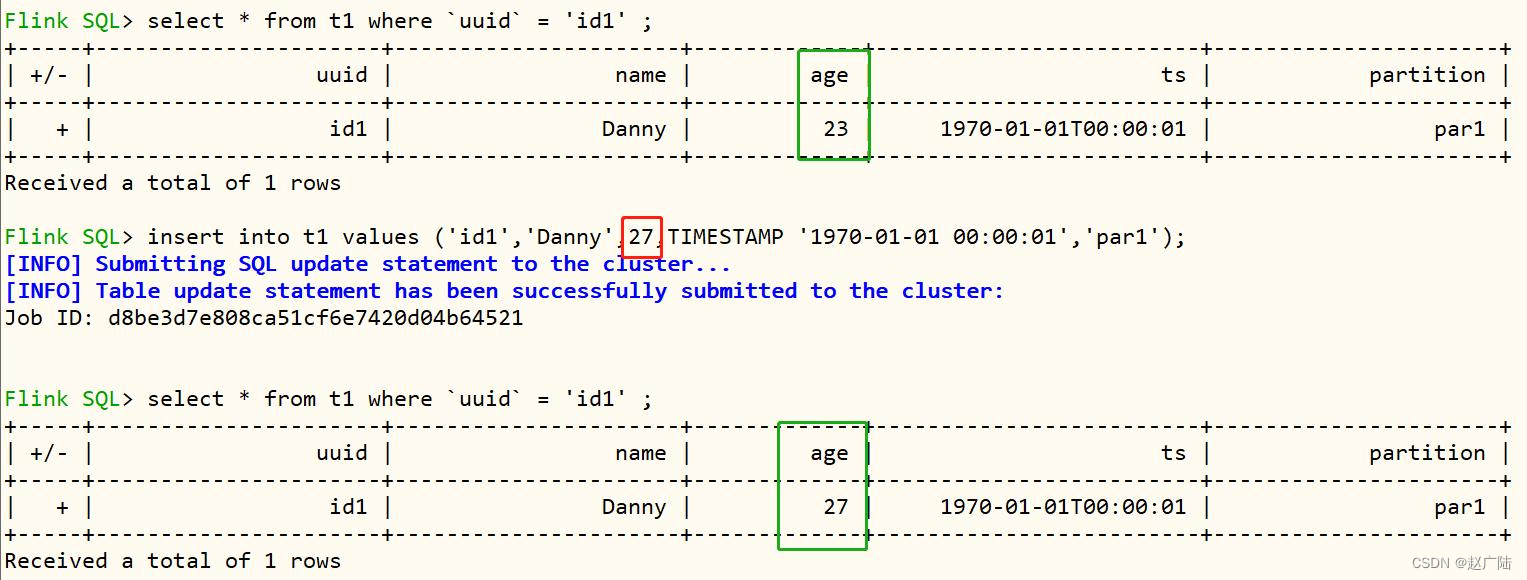
2.6 更新数据
将id1的数据age由23变为了27,执行SQL语句如下:
insert into t1 values (‘id1’,‘Danny’,27,TIMESTAMP ‘1970-01-01
00:00:01’,‘par1’);
再次查询表的数据,结果如下:
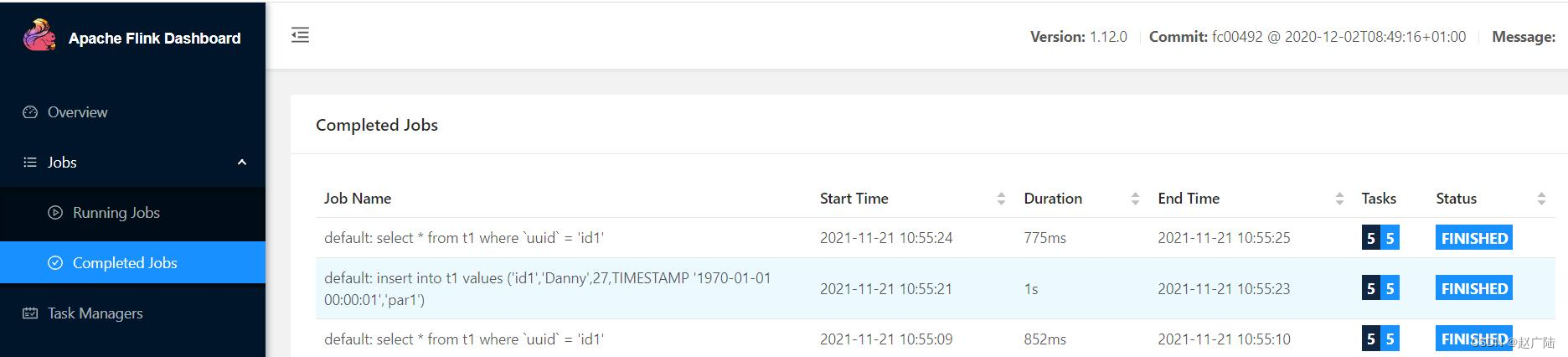
插入Flink Standalone监控页面8081,可以看到执行3个job。
3 Streaming query
Flink插入Hudi表数据时,支持以流的方式加载数据,增量查询分析。
3.1 创建表
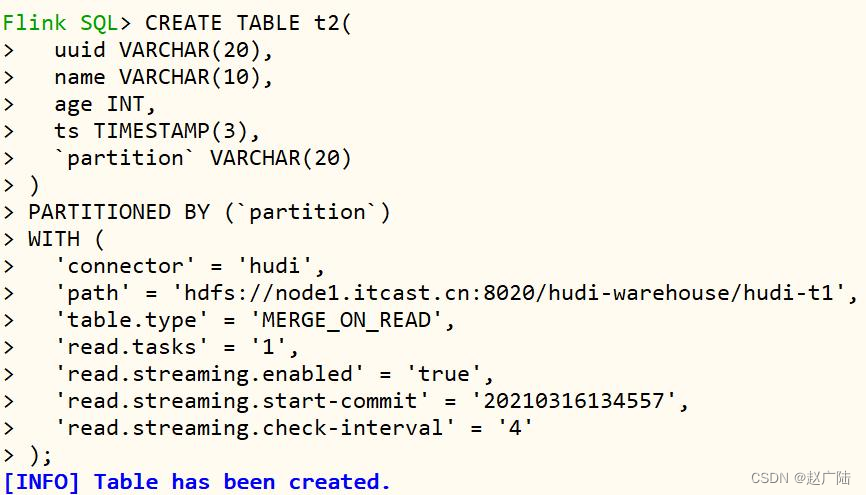
首先创建表:t2,设置相关属性,以流的方式查询读取,映射到前面表:t1,语句如下。
CREATE TABLE t2(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://node1.oldlu.cn:8020/hudi-warehouse/hudi-t1',
'table.type' = 'MERGE_ON_READ',
'read.tasks' = '1',
'read.streaming.enabled' = 'true',
'read.streaming.start-commit' = '20210316134557',
'read.streaming.check-interval' = '4'
);
核心参数选项说明:
● read.streaming.enabled 设置为 true,表明通过 streaming 的方式读取表数据;
● read.streaming.check-interval 指定了 source 监控新的 commits 的间隔为 4s;
● table.type 设置表类型为 MERGE_ON_READ;
接下来编写SQL插入数据,流式方式插入表:t2数据。
3.2 查询数据
创建表:t2 以后,此时表的数据就是前面批Batch模式写入的数据。
select * from t2 ;
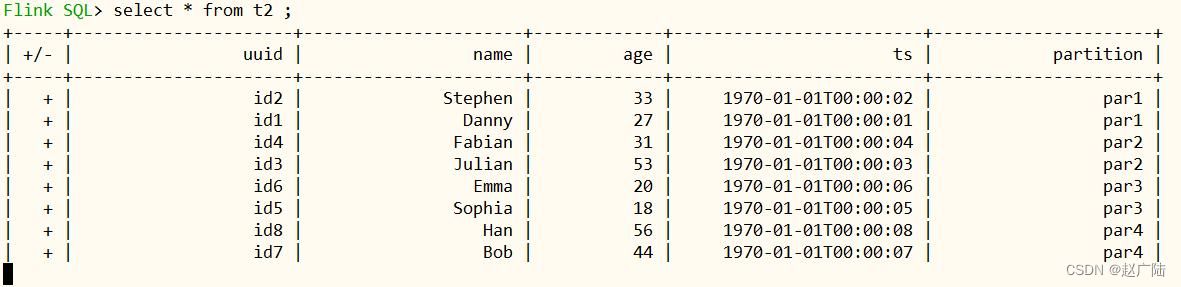
插入显示表中所有数据,光标在一直闪动,每隔4秒,再依据commit timestamp增量查询。
3.3 插入数据
重新开启Terminal启动Flink SQL CLI,重新创建表:t1,采用批Batch模式插入1条数据。
CREATE TABLE t1(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://node1.oldlu.cn:8020/hudi-warehouse/hudi-t1',
'write.tasks' = '1',
'compaction.tasks' = '1',
'table.type' = 'MERGE_ON_READ'
);
insert into t1 values ('id9','test',27,TIMESTAMP '1970-01-01 00:00:01','par5');
几秒后在流表中可以读取到一条新增的数据(前面插入的一条数据)。
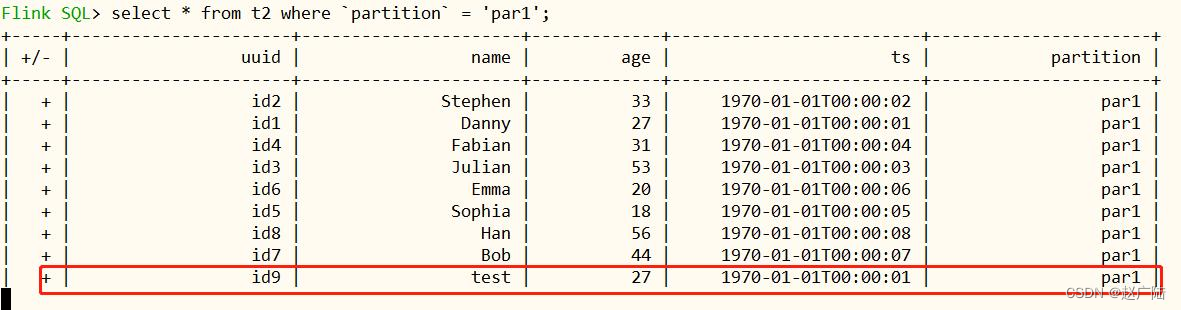
通过一些简单的演示,发现 HUDI Flink 的集成已经相对完善,读写数据均已覆盖。
4 Flink SQL Writer
在hudi-flink模块中提供Flink SQL Connector连接器,支持从Hudi表读写数据。

文档:https://hudi.apache.org/docs/writing_data#flink-sql-writer
4.1 Flink SQL集成Kafka
首先配置Flink SQL 集成Kafka,实时消费Kafka Topic数据,具体操作如下步骤:
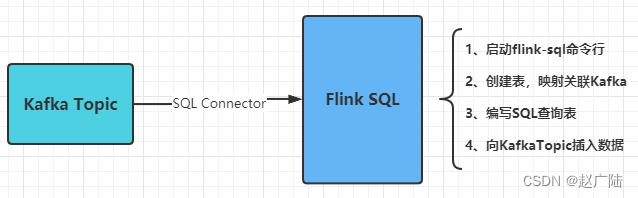
● 第一步、创建Topic
启动Zookeeper和Kafka服务组件,案例演示FlinkSQL与Kafka集成,实时加载数据。使用KafkaTool工具,连接启动Kafka服务,创建topic:flink-topic。
可以使用命令行创建Topic,具体命令如下:
– 创建topic:flink-topic
kafka-topics.sh --create --bootstrap-server node1.oldlu.cn:9092
–replication-factor 1 --partitions 1 --topic flink-topic
启动Flink Standalone集群服务,运行flink-sql命令行,创建表映射到Kafka中。
■第二步、启动HDFS集群
[root@node1 ~]# hadoop-daemon.sh start namenode [root@node1 ~]#
hadoop-daemon.sh start datanode
■第三步、启动Flink 集群
由于Flink需要连接HDFS文件系统,所以先设置HADOOP_CLASSPATH变量,再启动Standalone集群服务。
[root@node1 ~]# export HADOOP_CLASSPATH=
$HADOOP_HOME/bin/hadoop classpath[root@node1 ~]# /export/server/flink/bin/start-cluster.sh
■第四步、启动Flink SQL Cli命令行
采用指定参数【-j xx.jar】方式加载hudi-flink集成包,命令如下。
[root@node1 ~]# cd /export/server/flink [root@node1 ~]#
bin/sql-client.sh embedded -j
/root/flink-sql-connector-kafka_2.11-1.12.0.jar shell
在SQL Cli设置分析结果展示模式为:tableau。
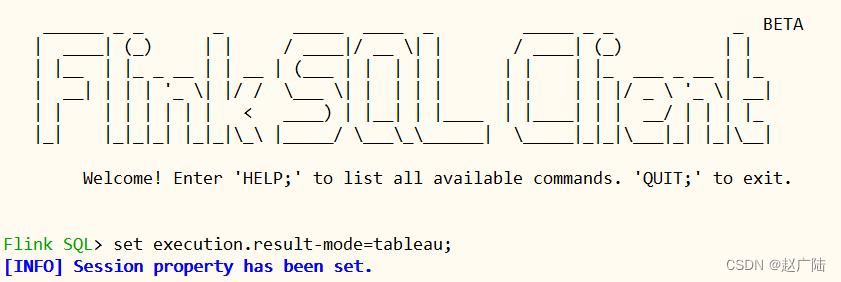
■第五步、创建表,映射到Kafka Topic
其中Kafka Topic中数据是CSV文件格式,有三个字段:user_id、item_id、behavior,从Kafka消费数据时,设置从最新偏移量开始,创建表语句如下:set execution.result-mode=tableau;
CREATE TABLE tbl_kafka (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'flink-topic',
'properties.bootstrap.servers' = 'node1.oldlu.cn:9092',
'properties.group.id' = 'test-group-10001',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv'
);
执行命令后,查看表,截图如下:

■第六步、实时向Topic发送数据,并在FlinkSQL查询
首先,在FlinkSQL页面,执行SELECT查询语句,截图如下:

其次,通过Kafka Console Producer向Topic发送数据,命令和数据如下:
– 生产者发送数据
kafka-console-producer.sh --broker-list node1.oldlu.cn:9092 --topic flink-topic
/*
1001,90001,click
1001,90001,browser
1001,90001,click
1002,90002,click
1002,90003,click
1003,90001,order
1004,90001,order
*/
插入数据,观察FlinkSQL界面,可以发现数据实时查询处理,截图如下所示:
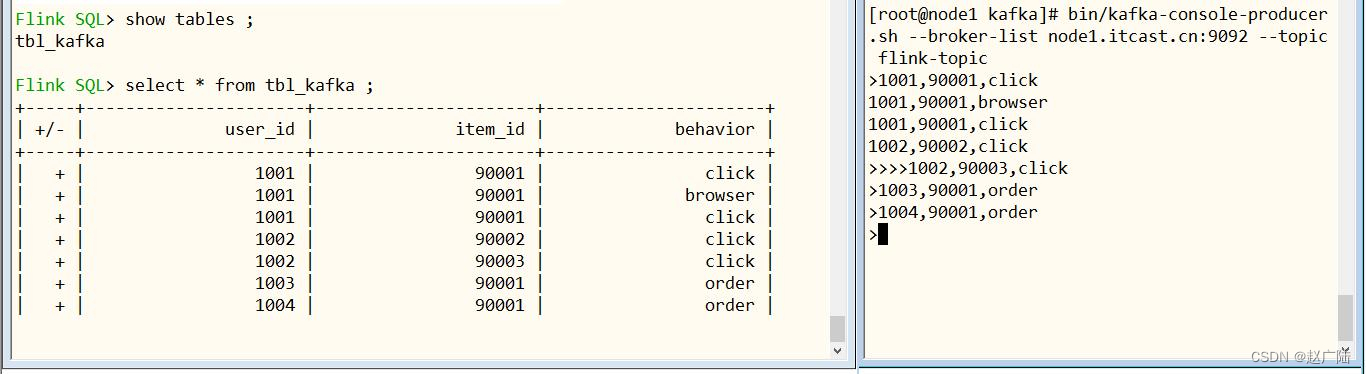
至此FlinkSQL集成Kafka,采用表的方式关联Topic数据,接下来编写Flink SQL 程序实时将Kafka数据同步到Hudi表中。
4.2 Flink SQL写入Hudi
将上述编写StructuredStreaming流式程序改为Flink SQL程序:实时从Kafka消费Topic数据,解析转换后,存储至Hudi表中,示意图如下所示。

4.2.1 创建Maven Module

创建Maven Module模块,添加依赖,此处Flink:1.12.2和Hudi:0.9.0版本。
<repositories>
<repository>
<id>nexus-aliyun</id>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</repository>
<repository>
<id>central_maven</id>
<name>central maven</name>
<url>https://repo1.maven.org/maven2</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>apache.snapshots</id>
<name>Apache Development Snapshot Repository</name>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<flink.version>1.12.2</flink.version>
<hadoop.version>2.7.3</hadoop.version>
<mysql.version>8.0.16</mysql.version>
</properties>
<dependencies>
<!-- Flink Client -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Flink Table API & SQL -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink-bundle_${scala.binary.version}</artifactId>
<version>0.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2-uber</artifactId>
<version>2.7.5-10.0</version>
</dependency>
<!-- MySQL/FastJson/lombok -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.68</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
<!-- slf4j及log4j -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/test/java</testSourceDirectory>
<plugins>
<!-- 编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<!--<encoding>${project.build.sourceEncoding}</encoding>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<!-- 打jar包插件(会包含所有依赖) -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- <mainClass>com.oldlu.flink.batch.FlinkBatchWordCount</mainClass> -->
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
4.2.2 消费Kafka数据
创建类:FlinkSQLKafakDemo,基于Flink Table API,从Kafka消费数据,提取字段值(方便后续存储Hudi表中)。
package cn.oldlu.hudi;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import static org.apache.flink.table.api.Expressions.$;
/**
* 基于Flink SQL Connector实现:实时消费Topic中数据,转换处理后,实时存储Hudi表中
*/
public class FlinkSQLKafakDemo {
public static void main(String[] args) {
// 1-获取表执行环境
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings) ;
// 2-创建输入表, TODO: 从Kafka消费数据
tableEnv.executeSql(
"CREATE TABLE order_kafka_source (\n" +
" orderId STRING,\n" +
" userId STRING,\n" +
" orderTime STRING,\n" +
" ip STRING,\n" +
" orderMoney DOUBLE,\n" +
" orderStatus INT\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'order-topic',\n" +
" 'properties.bootstrap.servers' = 'node1.oldlu.cn:9092',\n" +
" 'properties.group.id' = 'gid-1001',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'json',\n" +
" 'json.fail-on-missing-field' = 'false',\n" +
" 'json.ignore-parse-errors' = 'true'\n" +
")"
);
// 3-数据转换:提取订单时间中订单日期,作为Hudi表分区字段值
Table etlTable = tableEnv
.from("order_kafka_source")
.addColumns(
$("orderTime").substring(0, 10).as("partition_day")
)
.addColumns(
$("orderId").substring(0, 17).as("ts")
);
tableEnv.createTemporaryView("view_order", etlTable);
// 4-查询数据
tableEnv.executeSql("SELECT * FROM view_order").print();
}
}
运行流式应用程序和模拟数据程序,查看控制台。
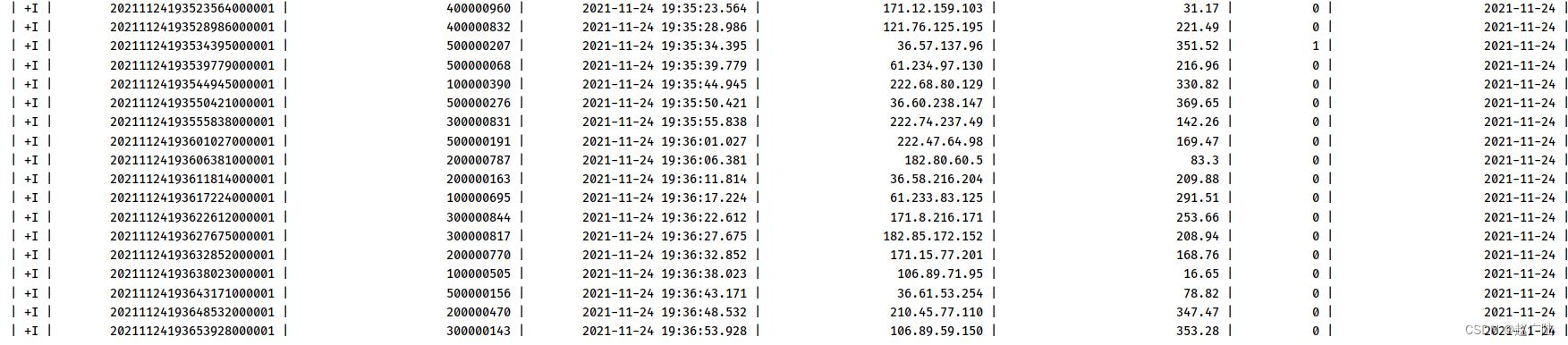
4.2.3 保存数据至Hudi
编写创建表DDL语句,映射到Hudi表中,指定相关属性:主键字段、表类型等等。
CREATE TABLE order_hudi_sink (
orderId STRING PRIMARY KEY NOT ENFORCED,
userId STRING,
orderTime STRING,
ip STRING,
orderMoney DOUBLE,
orderStatus INT,
ts STRING,
partition_day STRING
)
PARTITIONED BY (partition_day)
WITH (
'connector' = 'hudi',
'path' = 'file:///D:/flink_hudi_order',
'table.type' = 'MERGE_ON_READ',
'write.operation' = 'upsert',
'hoodie.datasource.write.recordkey.field'= 'orderId',
'write.precombine.field' = 'ts',
'write.tasks'= '1'
);
将Hudi表数据保存在本地文件系统LocalFS目录中,此外,向Hudi表写入数据时,采用INSERT INTO插入方式写入数据,具体DDL语句如下:
– 子查询插入INSERT … SELECT …
INSERT INTO order_hudi_sink
SELECT
orderId, userId, orderTime, ip, orderMoney, orderStatus,
substring(orderId, 0, 17) AS ts, substring(orderTime, 0, 10) AS partition_day
FROM order_kafka_source ;
12345
创建类:FlinkSQLHudiDemo,编写代码:从Kafka消费数据,转换后,保存到Hudi表。
package cn.oldlu.hudi;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import static org.apache.flink.table.api.Expressions.$;
/**
* 基于Flink SQL Connector实现:实时消费Topic中数据,转换处理后,实时存储Hudi表中
*/
public class FlinkSQLHudiDemo {
public static void main(String[] args) {
System.setProperty("HADOOP_USER_NAME","root");
// 1-获取表执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.enableCheckpointing(5000);
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings) ;
// 2-创建输入表, TODO: 从Kafka消费数据
tableEnv.executeSql(
"CREATE TABLE order_kafka_source (\n" +
" orderId STRING,\n" +
" userId STRING,\n" +
" orderTime STRING,\n" +
" ip STRING,\n" +
" orderMoney DOUBLE,\n" +
" orderStatus INT\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'order-topic',\n" +
" 'properties.bootstrap.servers' = 'node1.oldlu.cn:9092',\n" +
" 'properties.group.id' = 'gid-1001',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'json',\n" +
" 'json.fail-on-missing-field' = 'false',\n" +
" 'json.ignore-parse-errors' = 'true'\n" +
")"
);
// 3-数据转换:提取订单时间中订单日期,作为Hudi表分区字段值
Table etlTable = tableEnv
.from("order_kafka_source")
.addColumns(
$("orderId").substring(0, 17).as("ts")
)
.addColumns(
$("orderTime").substring(0, 10).as("partition_day")
);
tableEnv.createTemporaryView("view_order", etlTable);
// 4-定义输出表,TODO:数据保存到Hudi表中
tableEnv.executeSql(
"CREATE TABLE order_hudi_sink (\n" +
" orderId STRING PRIMARY KEY NOT ENFORCED,\n" +
" userId STRING,\n" +
" orderTime STRING,\n" +
" ip STRING,\n" +
" orderMoney DOUBLE,\n" +
" orderStatus INT,\n" +
" ts STRING,\n" +
" partition_day STRING\n" +
")\n" +
"PARTITIONED BY (partition_day) \n" +
"WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'path' = 'file:///D:/flink_hudi_order',\n" +
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'write.operation' = 'upsert',\n" +
" 'hoodie.datasource.write.recordkey.field' = 'orderId'," +
" 'write.precombine.field' = 'ts'" +
" 'write.tasks'= '1'" +
")"
);
// 5-通过子查询方式,将数据写入输出表
tableEnv.executeSql(
"INSERT INTO order_hudi_sink\n" +
"SELECT\n" +
" orderId, userId, orderTime, ip, orderMoney, orderStatus, ts, partition_day\n" +
"FROM view_order"
);
}
}
运行上述编写流式程序,查看本地文件系统目录,保存Hudi表数据结构信息:
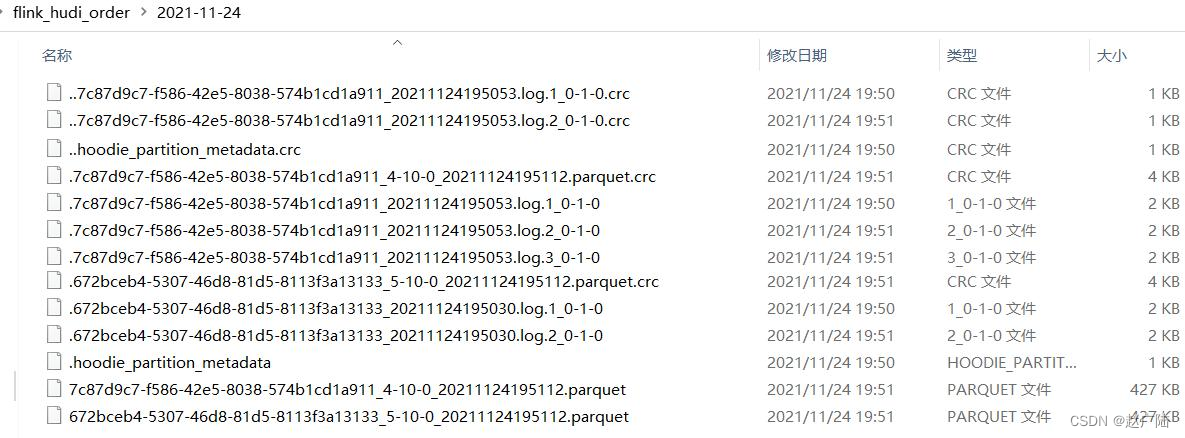
4.2.4 加载Hudi表数据
创建类:FlinkSQLReadDemo,加载Hudi表中数据,采用流式方式读取,同样创建表,映射关联到Hudi表数据存储目录中,创建表DDL语句如下:
CREATE TABLE order_hudi(
orderId STRING PRIMARY KEY NOT ENFORCED,
userId STRING,
orderTime STRING,
ip STRING,
orderMoney DOUBLE,
orderStatus INT,
ts STRING,
partition_day STRING
)
PARTITIONED BY (partition_day)
WITH (
'connector' = 'hudi',
'path' = 'file:///D:/flink_hudi_order',
'table.type' = 'MERGE_ON_READ',
'read.streaming.enabled' = 'true',
'read.streaming.check-interval' = '4'
);
完整Flink SQL流式程序代码如下:
package cn.oldlu.hudi;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
/**
* 基于Flink SQL Connector实现:从Hudi表中加载数据,编写SQL查询
*/
public class FlinkSQLReadDemo {
public static void main(String[] args) {
System.setProperty("HADOOP_USER_NAME","root");
// 1-获取表执行环境
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings) ;
// 2-创建输入表, TODO: 加载Hudi表查询数据
tableEnv.executeSql(
"CREATE TABLE order_hudi(\n" +
" orderId STRING PRIMARY KEY NOT ENFORCED,\n" +
" userId STRING,\n" +
" orderTime STRING,\n" +
" ip STRING,\n" +
" orderMoney DOUBLE,\n" +
" orderStatus INT,\n" +
" ts STRING,\n" +
" partition_day STRING\n" +
")\n" +
"PARTITIONED BY (partition_day)\n" +
"WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'path' = 'file:///D:/flink_hudi_order',\n" +
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'read.streaming.enabled' = 'true',\n" +
" 'read.streaming.check-interval' = '4'\n" +
")"
);
// 3-通过子查询方式,将数据写入输出表
tableEnv.executeSql(
"SELECT \n" +
" orderId, userId, orderTime, ip, orderMoney, orderStatus, ts ,partition_day \n" +
"FROM order_hudi"
).print();
}
}
运行流式程序,加载Hudi表数据,结果如下所示:

4.3 Flink SQL Client 写入Hudi
启动Flink Standalone集群,运行SQL Client命令行客户端,执行DDL和DML语句,操作数据。
4.3.1 集成环境
■配置Flink 集群
修改$FLINK_HOME/conf/flink-conf.yaml文件
jobmanager.rpc.address: node1.oldlu.cn
jobmanager.memory.process.size: 1024m
taskmanager.memory.process.size: 2048m
taskmanager.numberOfTaskSlots: 4
classloader.check-leaked-classloader: false
classloader.resolve-order: parent-first
execution.checkpointing.interval: 3000
state.backend: rocksdb
state.checkpoints.dir: hdfs://node1.oldlu.cn:8020/flink/flink-checkpoints
state.savepoints.dir: hdfs://node1.oldlu.cn:8020/flink/flink-savepoints
state.backend.incremental: true
● 将Hudi与Flink集成jar包及其他相关jar包,放置到$FLINK_HOME/lib目录

● 启动Standalone集群
export HADOOP_CLASSPATH=
/export/server/hadoop/bin/hadoop classpath
/export/server/flink/bin/start-cluster.sh
● 启动SQL Client,最好再次指定Hudi集成jar包
/export/server/flink/bin/sql-client.sh embedded -j
/export/server/flink/lib/hudi-flink-bundle_2.12-0.9.0.jar shell
● 设置属性
set execution.result-mode=tableau; set
execution.checkpointing.interval=3sec;
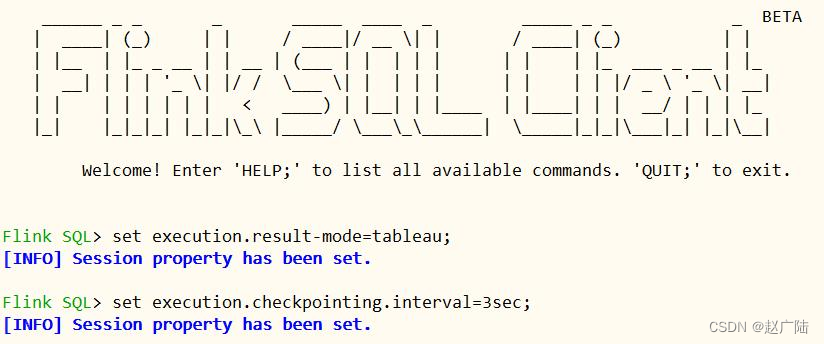
4.3.2 执行SQL
首先创建输入表:从Kafka消费数据,其次编写SQL提取字段值,再创建输出表:将数据保存值Hudi表中,最后编写SQL查询Hudi表数据。
● 第1步、创建输入表,关联Kafka Topic
– 输入表:Kafka Source
CREATE TABLE order_kafka_source (
orderId STRING,
userId STRING,
orderTime STRING,
ip STRING,
orderMoney DOUBLE,
orderStatus INT
) WITH (
'connector' = 'kafka',
'topic' = 'order-topic',
'properties.bootstrap.servers' = 'node1.oldlu.cn:9092',
'properties.group.id' = 'gid-1001',
'scan.startup.mode' = 'latest-offset',
'format' = 'json',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true'
);
SELECT orderId, userId, orderTime, ip, orderMoney, orderStatus FROM order_kafka_source ;
● 第2步、处理获取Kafka消息数据,提取字段值
SELECT
orderId, userId, orderTime, ip, orderMoney, orderStatus,
substring(orderId, 0, 17) AS ts, substring(orderTime, 0, 10) AS partition_day
FROM order_kafka_source ;
● 第3步、创建输出表,保存数据至Hudi表,设置相关属性
– 输出表:Hudi Sink
CREATE TABLE order_hudi_sink (
orderId STRING PRIMARY KEY NOT ENFORCED,
userId STRING,
orderTime STRING,
ip STRING,
orderMoney DOUBLE,
orderStatus INT,
ts STRING,
partition_day STRING
)
PARTITIONED BY (partition_day)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://node1.oldlu.cn:8020/hudi-warehouse/order_hudi_sink',
'table.type' = 'MERGE_ON_READ',
'write.operation' = 'upsert',
'hoodie.datasource.write.recordkey.field'= 'orderId',
'write.precombine.field' = 'ts',
'write.tasks'= '1',
'compaction.tasks' = '1',
'compaction.async.enabled' = 'true',
'compaction.trigger.strategy' = 'num_commits',
'compaction.delta_commits' = '1'
);
● 第4步、使用INSERT INTO语句,将数据保存Hudi表
– 子查询插入INSERT … SELECT …
INSERT INTO order_hudi_sink
SELECT
orderId, userId, orderTime, ip, orderMoney, orderStatus,
substring(orderId, 0, 17) AS ts, substring(orderTime, 0, 10) AS partition_day
FROM order_kafka_source ;
12345
此时,提交Flink Job运行在FlinkStandalone集群上,示意图如下:
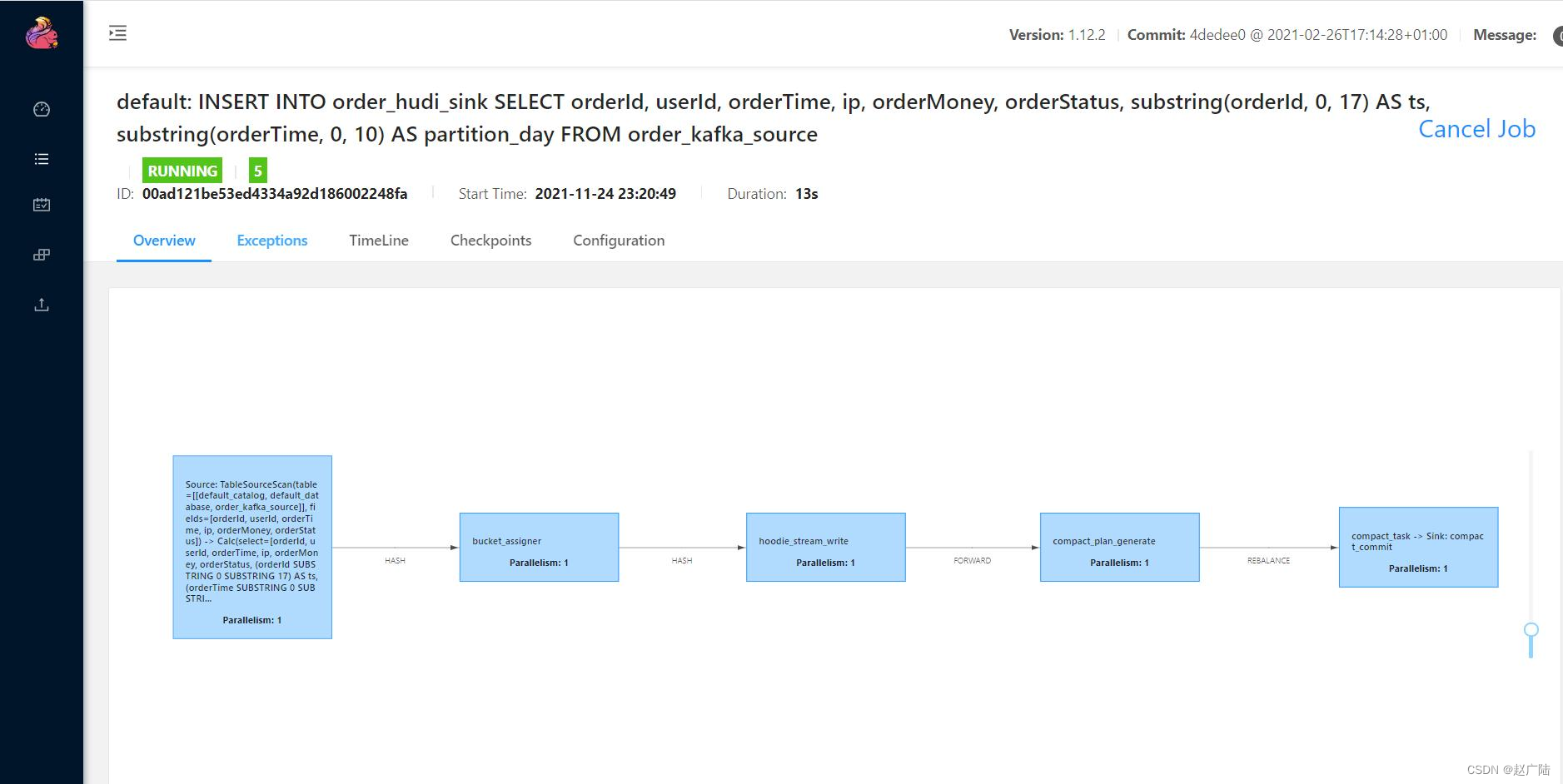
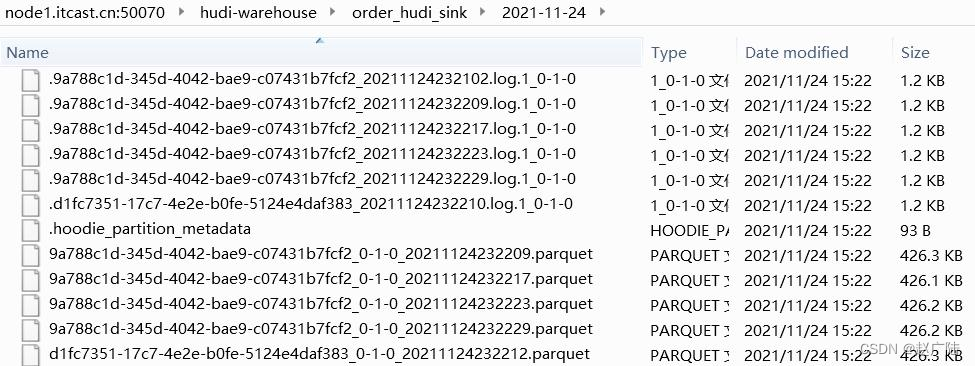
只要运行模拟交易订单数据程序,就会将数据发送到Kafka,最后转换保存至Hudi表,截图如下:
■第5步、编写SELECT语句,查询Hudi表交易订单数据
– 查询Hudi表数据
SELECT * FROM order_hudi_sink ;

5 Hudi CDC
CDC的全称是Change data Capture,即变更数据捕获,主要面向数据库的变更,是是数据库领域非常常见的技术,主要用于捕获数据库的一些变更,然后可以把变更数据发送到下游。
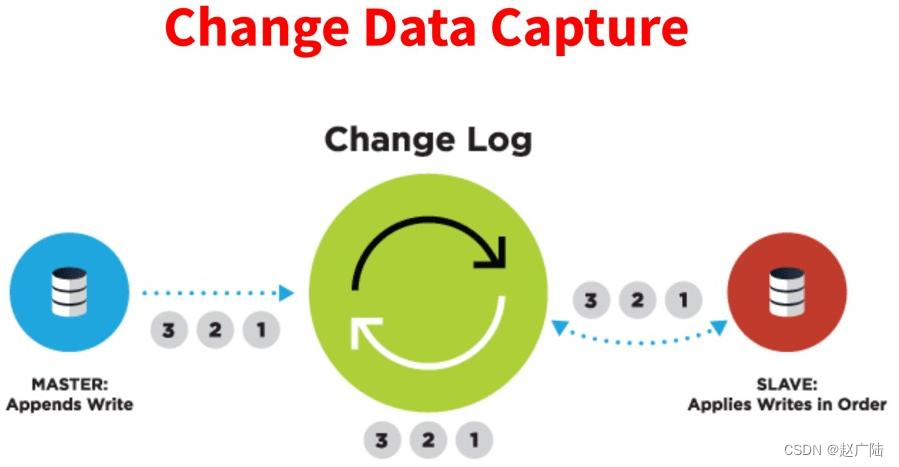
对于CDC,业界主要有两种类型:一是基于查询的,客户端会通过SQL方式查询源库表变更数据,然后对外发送。二是基于日志,这也是业界广泛使用的一种方式,一般是通过binlog方式,变更的记录会写入binlog,解析binlog后会写入消息系统,或直接基于Flink CDC进行处理。
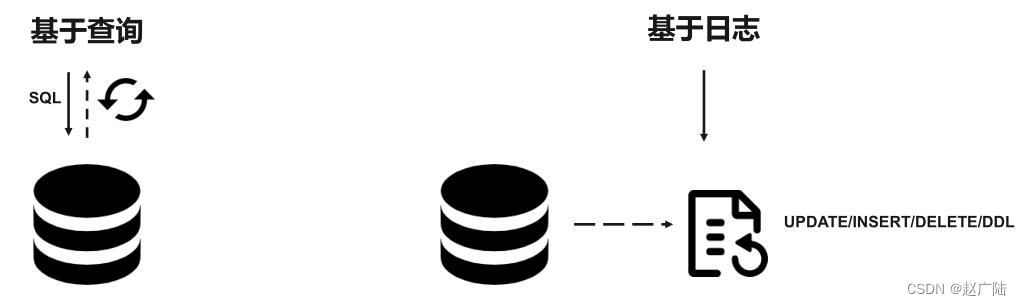
■基于查询:这种 CDC 技术是入侵式的,需要在数据源执行 SQL 语句。使用这种技术实现CDC 会影响数据源的性能。通常需要扫描包含大量记录的整个表。
■基于日志:这种 CDC 技术是非侵入性的,不需要在数据源执行 SQL 语句。通过读取源数据库的日志文件以识别对源库表的创建、修改或删除数据。
5.1 CDC 数据入湖
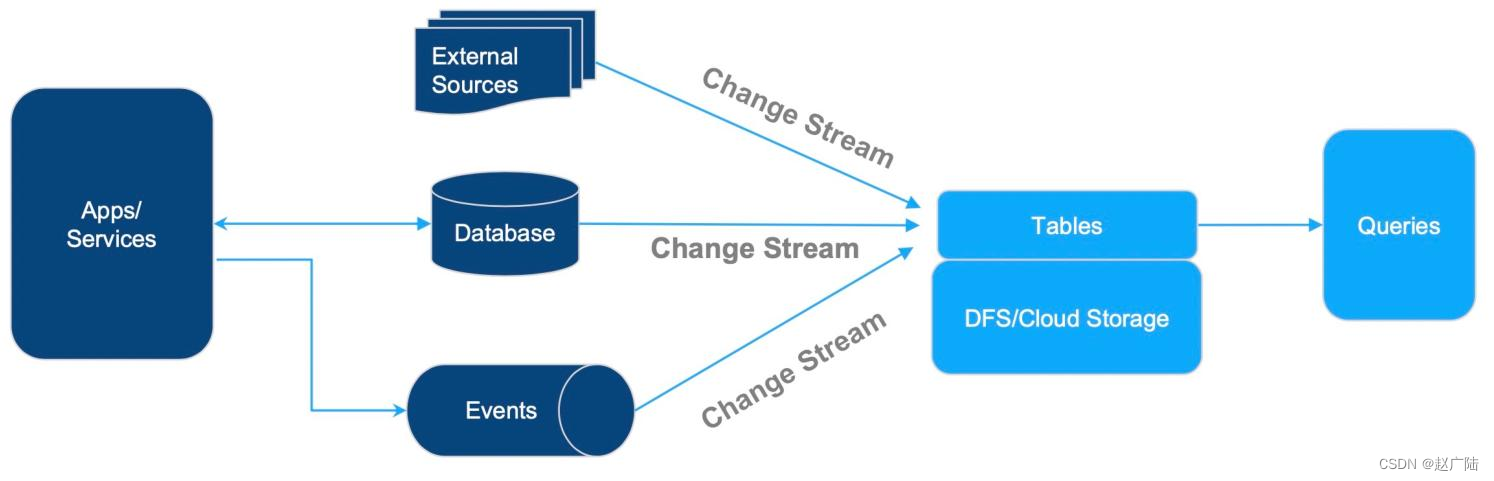
基于CDC数据的入湖,这个架构非常简单:上游各种各样的数据源,比如DB的变更数据、事件流,以及各种外部数据源,都可以通过变更流的方式写入表中,再进行外部的查询分析。
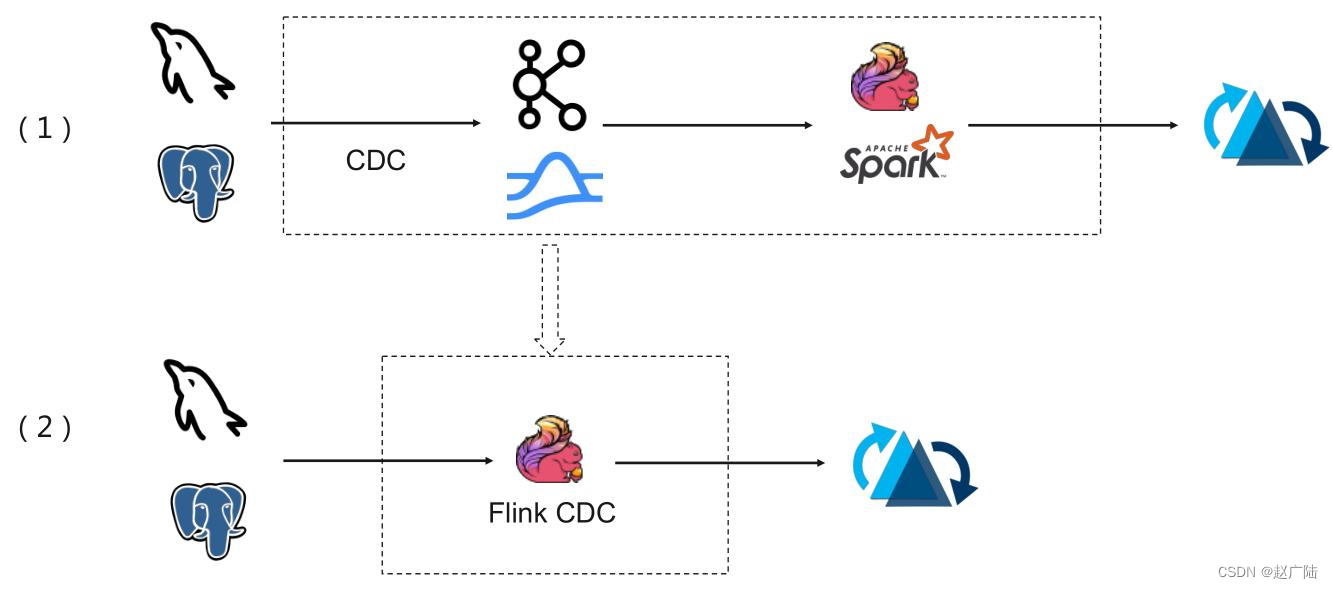
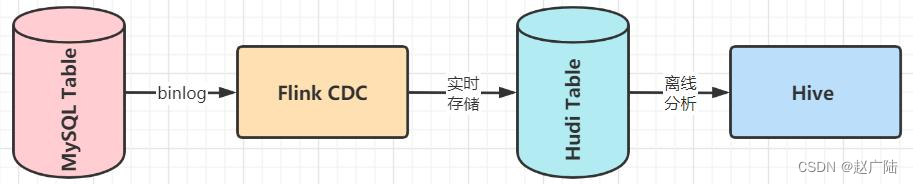
典型CDC入湖的链路:上面的链路是大部分公司采取的链路,前面CDC的数据先通过CDC工具导入Kafka或者Pulsar,再通过Flink或者是Spark流式消费写到Hudi里。第二个架构是通过Flink CDC直联到MySQL上游数据源,直接写到下游Hudi表。
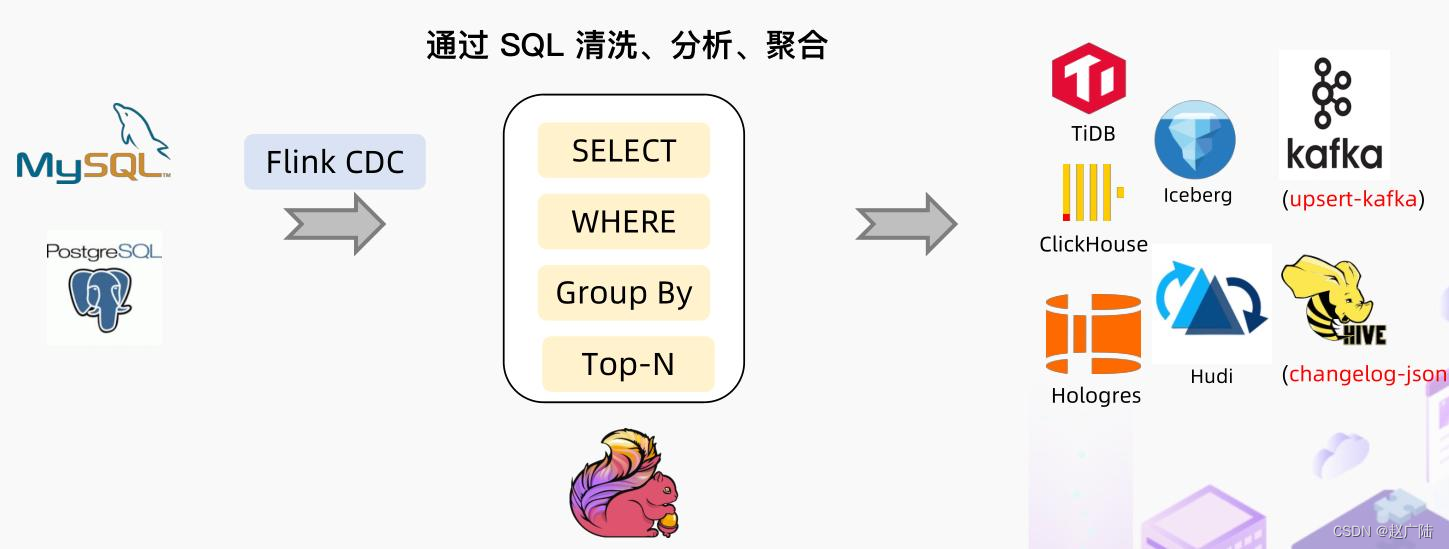
5.2 Flink CDC Hudi
基于Flink CDC技术,实时采集MySQL数据库表数据,进行过ETL转换处理,最终存储Hudi表。
5.2.1 业务需求
MySQL数据库创建表,实时添加数据,通过Flink CDC将数据写入Hudi表,并且Hudi与Hive集成,自动在Hive中创建表与添加分区信息,最后Hive终端Beeline查询分析数据。
Hudi 表与Hive表,自动关联集成,需要重新编译Hudi源码,指定Hive版本及编译时包含Hive依赖jar包,具体步骤如下。
● 修改Hudi集成flink和Hive编译依赖版本配置
原因:现在版本Hudi,在编译的时候本身默认已经集成的flink-SQL-connector-hive的包,会和Flink lib包下的flink-SQL-connector-hive冲突。所以,编译的过程中只修改hive编译版本。
文件:hudi-0.9.0/packaging/hudi-flink-bundle/pom.xml

● 编译Hudi源码
mvn clean install -DskipTests -Drat.skip=true -Dscala-2.12 -Dspark3
-Pflink-bundle-shade-hive2
编译完成以后,有2个jar包,至关重要:
hudi-flink-bundle_2.12-0.9.0.jar,位于
hudi-0.9.0/packaging/hudi-flink-bundle/target,flink 用来写入和读取数据,将其拷贝至
KaTeX parse error: Unexpected character: '' at position 39: …同名jar包,先删除再拷贝。 ̲ hudi-hadoop-mr…HIVE_HOME/lib目录中。
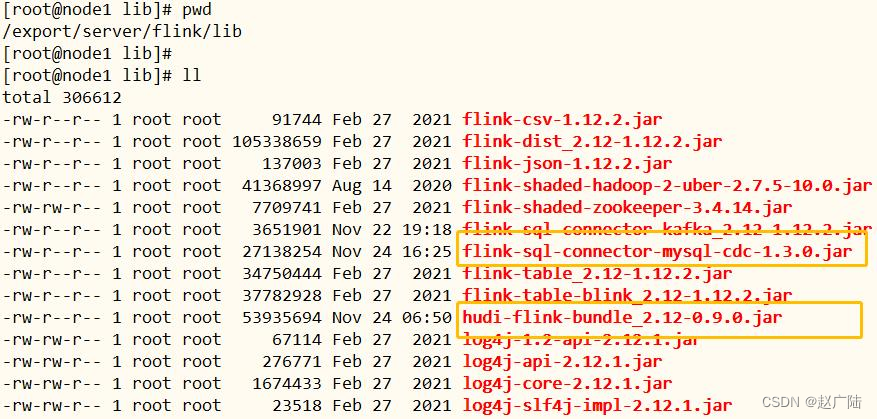
■ 将Flink CDC MySQL对应jar包,放到$FLINK_HOME/lib目录中
flink-sql-connector-mysql-cdc-1.3.0.jar
至此,$FLINK_HOME/lib目录中,有如下所需的jar包,缺一不可,注意版本号。
5.2.2 创建 MySQL 表
首先开启MySQL数据库binlog日志,再重启MySQL数据库服务,最后创建表。
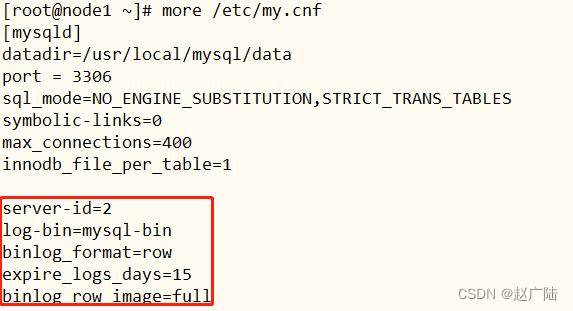
■第一步、开启MySQL binlog日志
[root@node1 ~]# vim /etc/my.cnf
在[mysqld]下面添加内容:
server-id=2
log-bin=mysql-bin
binlog_format=row
expire_logs_days=15
binlog_row_image=full
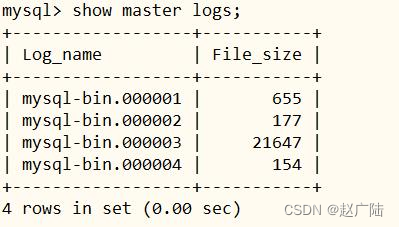
■第二步、重启MySQL Server
service mysqld restart
登录MySQL Client命令行,查看是否生效。
■第三步、在MySQL数据库,创建表
– MySQL 数据库创建表
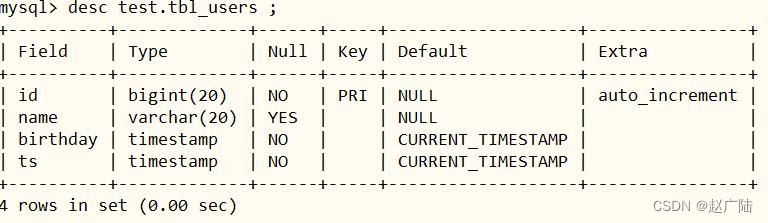
create database test ;
create table test.tbl_users(
id bigint auto_increment primary key,
name varchar(20) null,
birthday timestamp default CURRENT_TIMESTAMP not null,
ts timestamp default CURRENT_TIMESTAMP not null
);
5.2.3 创建 CDC 表
先启动HDFS服务、Hive MetaStore和HiveServer2服务和Flink Standalone集群,再运行SQL Client,最后创建表关联MySQL表,采用MySQL CDC方式。
● 启动HDFS服务,分别启动NameNode和DataNode
– 启动HDFS服务
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
● 启动Hive服务:元数据MetaStore和HiveServer2
– Hive服务
/export/server/hive/bin/start-metastore.sh
/export/server/hive/bin/start-hiveserver2.sh
■启动Flink Standalone集群
– 启动Flink Standalone集群
export HADOOP_CLASSPATH=
/export/server/hadoop/bin/hadoop classpath
/export/server/flink/bin/start-cluster.sh
■启动SQL Client客户端
/export/server/flink/bin/sql-client.sh embedded -j
/export/server/flink/lib/hudi-flink-bundle_2.12-0.9.0.jar shell
设置属性:
set execution.result-mode=tableau; set
execution.checkpointing.interval=3sec;
● 创建输入表,关联MySQL表,采用MySQL CDC 关联
– Flink SQL Client创建表
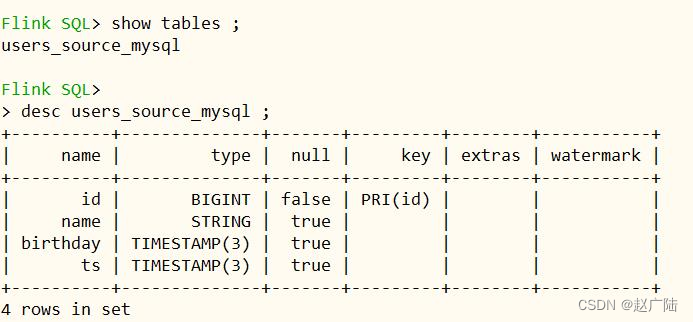
CREATE TABLE users_source_mysql (
id BIGINT PRIMARY KEY NOT ENFORCED,
name STRING,
birthday TIMESTAMP(3),
ts TIMESTAMP(3)
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'node1.oldlu.cn',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'server-time-zone' = 'Asia/Shanghai',
'debezium.snapshot.mode' = 'initial',
'database-name' = 'test',
'table-name' = 'tbl_users'
);
查询表的结构,其中id为主键,ts为数据合并字段。
● 查询CDC表数据
– 查询数据
select * from users_source_mysql;

● 开启MySQL Client客户端,执行DML语句,插入数据
insert into test.tbl_users (name) values (‘zhangsan’) insert into
test.tbl_users (name) values (‘lisi’); insert into test.tbl_users
(name) values (‘wangwu’); insert into test.tbl_users (name) values
(‘laoda’); insert into test.tbl_users (name) values (‘laoer’);
5.2.4 创建视图
创建一个临时视图,增加分区列part,方便后续同步hive分区表。
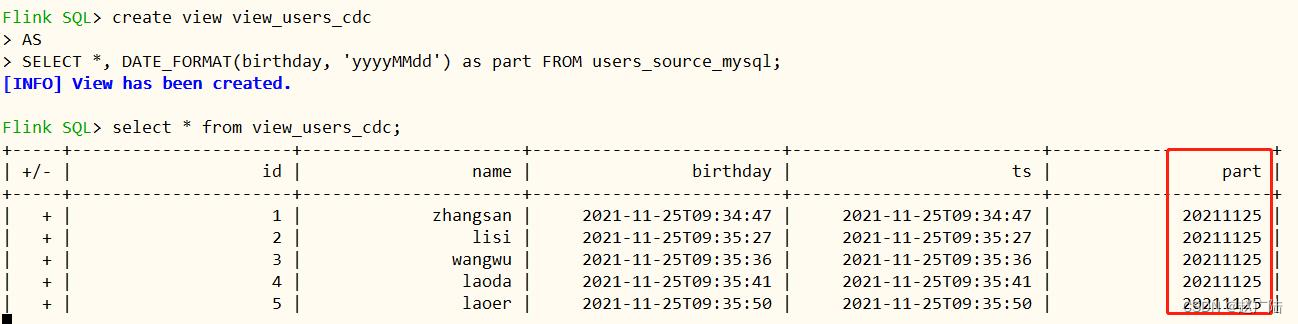
– 创建一个临时视图,增加分区列 方便后续同步hive分区表
create view view_users_cdc AS SELECT *, DATE_FORMAT(birthday,
‘yyyyMMdd’) as part FROM users_source_mysql;
查看视图view中数据
select * from view_users_cdc;
5.2.5 创建 Hudi 表
创建 CDC Hudi Sink表,并自动同步hive分区表,具体DDL语句。
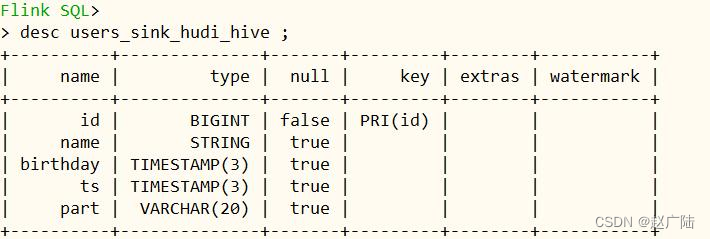
CREATE TABLE users_sink_hudi_hive(
id bigint ,
name string,
birthday TIMESTAMP(3),
ts TIMESTAMP(3),
part VARCHAR(20),
primary key(id) not enforced
)
PARTITIONED BY (part)
with(
'connector'='hudi',
'path'= 'hdfs://node1.oldlu.cn:8020/ehualu/hudi-warehouse/users_sink_hudi_hive',
'table.type'= 'MERGE_ON_READ',
'hoodie.datasource.write.recordkey.field'= 'id',
'write.precombine.field'= 'ts',
'write.tasks'= '1',
'write.rate.limit'= '2000',
'compaction.tasks'= '1',
'compaction.async.enabled'= 'true',
'compaction.trigger.strategy'= 'num_commits',
'compaction.delta_commits'= '1',
'changelog.enabled'= 'true',
'read.streaming.enabled'= 'true',
'read.streaming.check-interval'= '3',
'hive_sync.enable'= 'true',
'hive_sync.mode'= 'hms',
'hive_sync.metastore.uris'= 'thrift://node1.oldlu.cn:9083',
'hive_sync.jdbc_url'= 'jdbc:hive2://node1.oldlu.cn:10000',
'hive_sync.table'= 'users_sink_hudi_hive',
'hive_sync.db'= 'default',
'hive_sync.username'= 'root',
'hive_sync.password'= '123456',
'hive_sync.support_timestamp'= 'true'
);
此处Hudi表类型:MOR,Merge on Read (读时合并),快照查询+增量查询+读取优化查询(近实时)。使用列式存储(parquet)+行式文件(arvo)组合存储数据。更新记录到增量文件中,然后进行同步或异步压缩来生成新版本的列式文件。
5.2.6 数据写入Hudi表
编写INSERT语句,从视图中查询数据,再写入Hudi表中,语句如下:
insert into users_sink_hudi_hive select id, name, birthday, ts, part
from view_users_cdc;
Flink web UI DAG图:
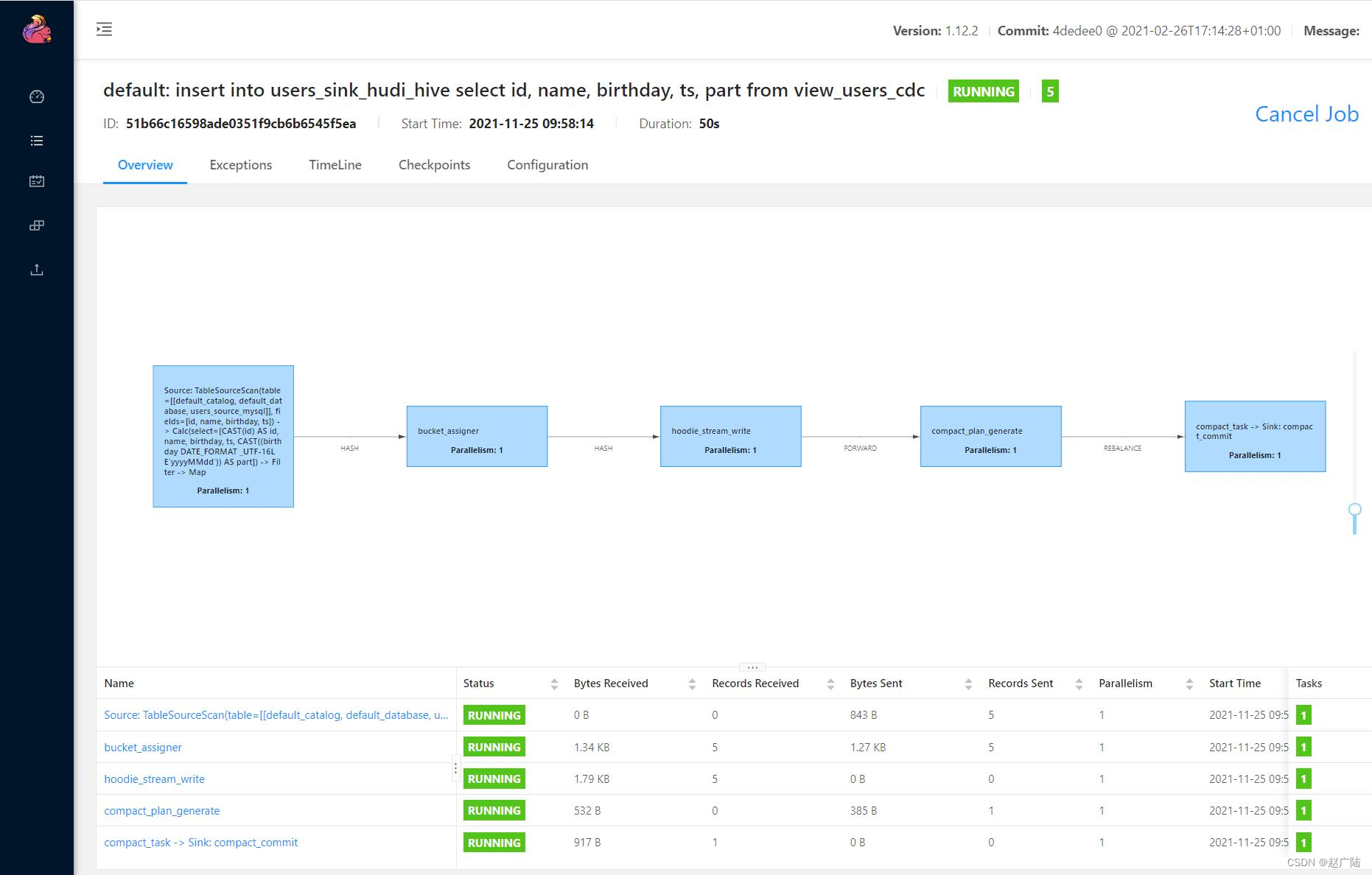
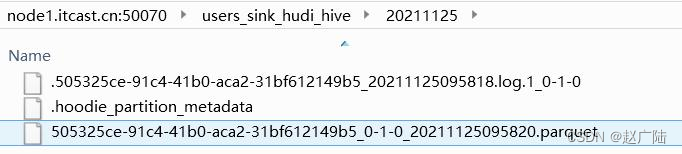
HDFS上Hudi文件目录情况:
查询Hudi表数据,SELECT语句如下:
select * from users_sink_hudi_hive;

5.2.7 Hive 表查询
需要引入hudi-hadoop-mr-bundle-0.9.0.jar包,放到$HIVE_HOME/lib下。

启动Hive中beeline客户端,连接HiveServer2服务:
/export/server/hive/bin/beeline -u jdbc:hive2://node1.oldlu.cn:10000
-n root -p 123456
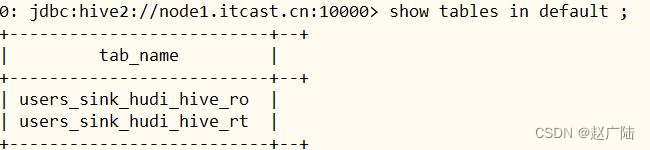
已自动生产hudi MOR模式的2张表:
■users_sink_hudi_hive_ro,ro 表全称 read oprimized table,对于 MOR 表同步的 xxx_ro 表,只暴露压缩后的 parquet。其查询方式和COW表类似。设置完 hiveInputFormat 之后 和普通的 Hive 表一样查询即可;
■users_sink_hudi_hive_rt,rt表示增量视图,主要针对增量查询的rt表;ro表只能查parquet文件数据, rt表 parquet文件数据和log文件数据都可查;
查看自动生成表users_sink_hudi_hive_ro结构:
CREATE EXTERNAL TABLE `users_sink_hudi_hive_ro`(
`_hoodie_commit_time` string COMMENT '',
`_hoodie_commit_seqno` string COMMENT '',
`_hoodie_record_key` string COMMENT '',
`_hoodie_partition_path` string COMMENT '',
`_hoodie_file_name` string COMMENT '',
`_hoodie_operation` string COMMENT '',
`id` bigint COMMENT '',
`name` string COMMENT '',
`birthday` bigint COMMENT '',
`ts` bigint COMMENT '')
PARTITIONED BY (
`part` string COMMENT '')
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES (
'hoodie.query.as.ro.table'='true',
'path'='hdfs://node1.oldlu.cn:8020/users_sink_hudi_hive')
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://node1.oldlu.cn:8020/users_sink_hudi_hive'
TBLPROPERTIES (
'last_commit_time_sync'='20211125095818',
'spark.sql.sources.provider'='hudi',
'spark.sql.sources.schema.numPartCols'='1',
'spark.sql.sources.schema.numParts'='1',
'spark.sql.sources.schema.part.0'='{\"type\":\"struct\",\"fields\":[{\"name\":\"_hoodie_commit_time\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"_hoodie_commit_seqno\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"_hoodie_record_key\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"_hoodie_partition_path\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"_hoodie_file_name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"_hoodie_operation\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"id\",\"type\":\"long\",\"nullable\":false,\"metadata\":{}},{\"name\":\"name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"birthday\",\"type\":\"timestamp\",\"nullable\":true,\"metadata\":{}},{\"name\":\"ts\",\"type\":\"timestamp\",\"nullable\":true,\"metadata\":{}},{\"name\":\"part\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}}]}',
'spark.sql.sources.schema.partCol.0'='partition',
'transient_lastDdlTime'='1637743860')
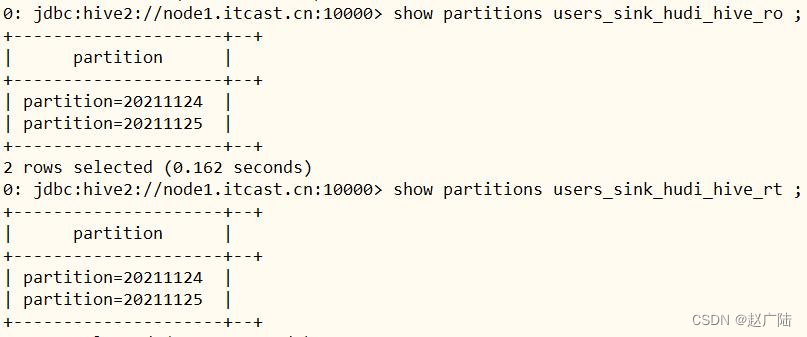
查看自动生成表的分区信息:
show partitions users_sink_hudi_hive_ro ; show partitions
users_sink_hudi_hive_rt ;
查询Hive 分区表数据
set hive.exec.mode.local.auto=true; set hive.input.format =
org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat; set
hive.mapred.mode=nonstrict ;select id, name, birthday, ts,
partfrom users_sink_hudi_hive_ro;
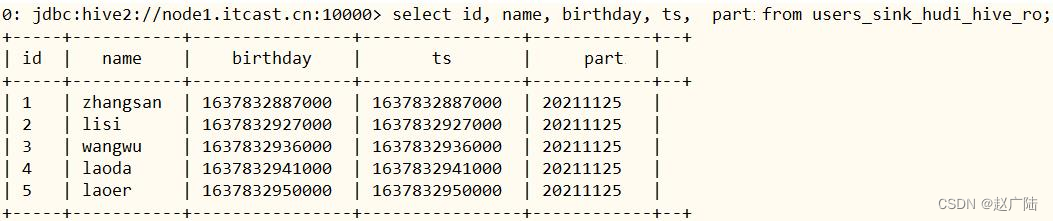
指定分区字段过滤,查询数据
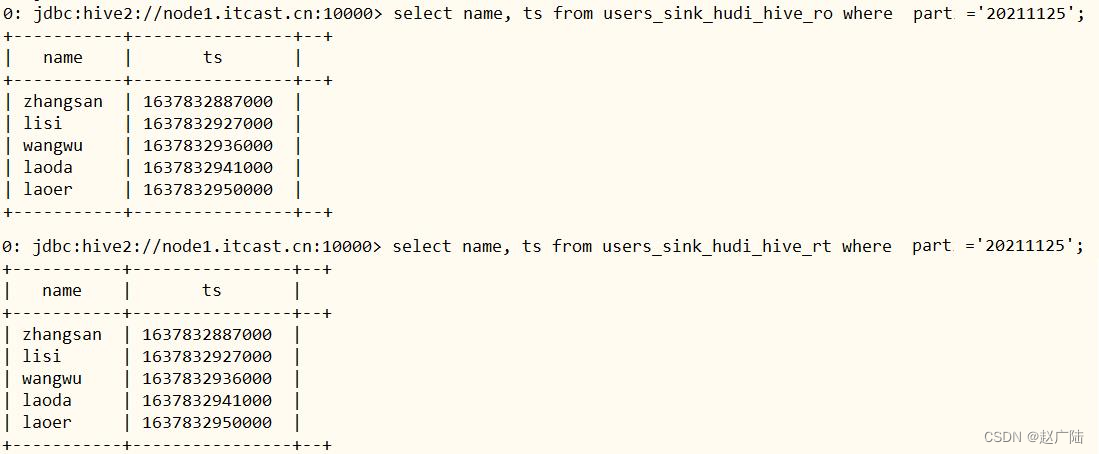
select name, ts from users_sink_hudi_hive_ro where part =‘20211125’;
select name, ts from users_sink_hudi_hive_rt where part =‘20211125’;
5.3 Hudi Client操作Hudi表
进入Hudi客户端命令行:hudi-0.9.0/hudi-cli/hudi-cli.sh
连接Hudi表,查看表信息
connect --path hdfs://node1.oldlu.cn:8020/users_sink_hudi_hive

查看Hudi commit信息
commits show --sortBy “CommitTime”

查看Hudi compactions 计划
compactions show all
