1 前言
Apache Hudi是大数据领域中新一代的基于流式计算的数据存储平台,又称之为数据湖平台(Data Lake Platform),其综合传统的数据库与数据仓库的核心功能,提供多样化的数据集成、数据处理以及数据存储的平台能力。Hudi提供的核心功能包括数据表管理服务、事务管理服务、高效的增删改查操作服务、先进的索引系统服务、流式数据采集服务、数据集群与压缩优化服务、高性能的并发控制服务,Hudi数据湖中的数据组织存储格式是使用开源的文件格式。
Apache Hudi能支持大规模的流式处理的工作负载,同时,也提供可创建高效的、增量式的、批量处理的数据管道。
Apache Hudi能轻易地部署在任何的云存储平台上,与目前流行的Apache Spark、Flink、Presto、Trino、Hive数据分析与查询引擎相结合能提供性能更加优越的数据分析能力。
2 架构描述
Apache Hudi数据湖平台的整体应用架构如下所示:
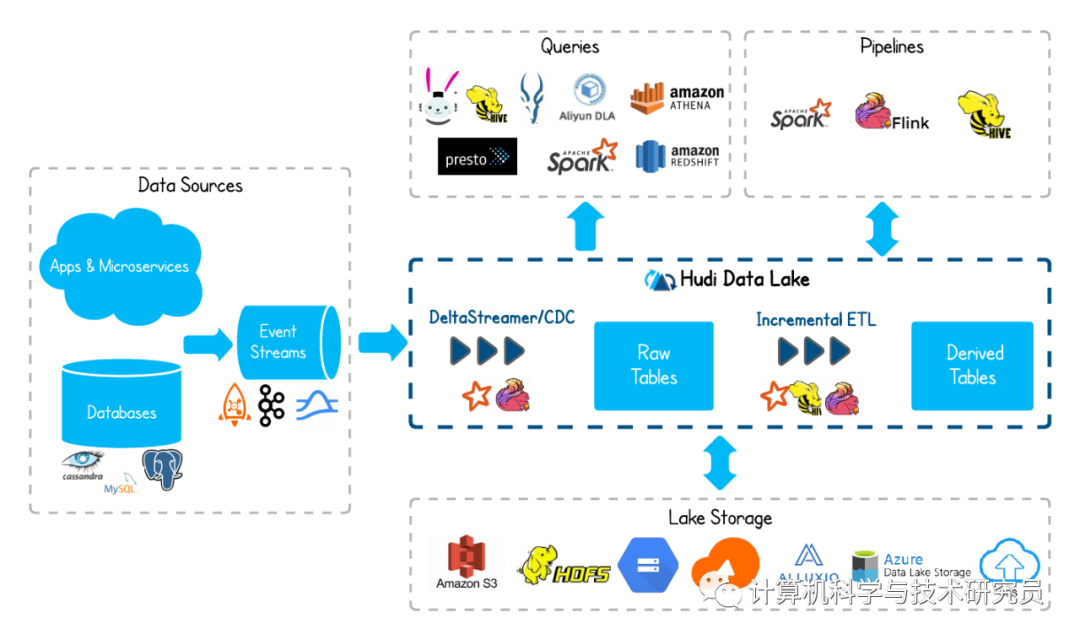
| Data Sources 数据源,提供数据的输入 |
| Apps & Microservices 应用与微服务类型的数据源,提供事件的输入 |
| Databases SQL数据库或者NoSQL数据库类型的数据源,提供事件的输入 |
| Event Streams 消息或者事件中间件,接受来自其他数据源的事件的输入,汇聚成事件流 |
| Hudi Data Lake Hudi数据湖平台,运用流式计算的技术提供大规模的、结构化或者非结构化类型数据的处理与存储服务 |
| DeltaStreamer/CDC 流式计算事件处理器/捕获数据变化,用于对事件流的处理以及处理事件的变化 |
| Row Tables 行式存储的数据表,用于存储上一步骤已经处理的事件 |
| Incremental ETL 数据仓库的标准处理步骤,使用增量式、流式、管道式计算事件处理器,汇聚成下一事件流的输入 |
| Derived Tables 存储上一步骤的输入流事件,或者是最终待分析的数据 |
| Lake Storage Hudi数据表的数据组织存储,支持HDFS或者公有云环境中的对象存储 |
| Queries 查询引擎,提供Hudi数据湖的查询与检索服务 |
| Pipelines 分析引擎,提供Hudi数据湖的查询与分析服务 |
(未完待续)