innodb为什么选择B+ Tree而不是跳表,Redis为什么选择跳表而不是B+ Tree
跳表

链表和数组相比,数组可以通过下标快速定位,或者通过二分查找,查询复杂度为O(logn),而链表只能按照顺序挨个查找,复杂度为O(n)。
为了让链表也能支持二分查找,我们可以在链表的基础上加上一层目录,即一层索引链表:
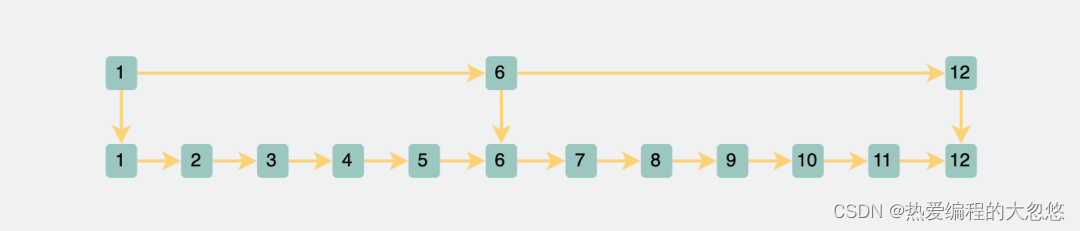
当我们访问某个节点时,先访问索引链表,通过索引链表进行二分过滤,在索引链表找到结点后,顺着索引链表的结点向下,找到原始链表的结点:
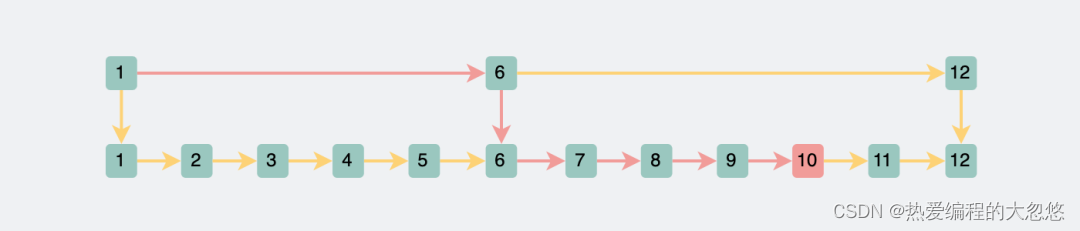
当数据量很大的情况下,一层索引查询复杂度无法满足O(logn)时,可以基于原始链表的第1层索引,抽出第二层/第三层更为稀疏的索引,结点数量是上一层的一半:
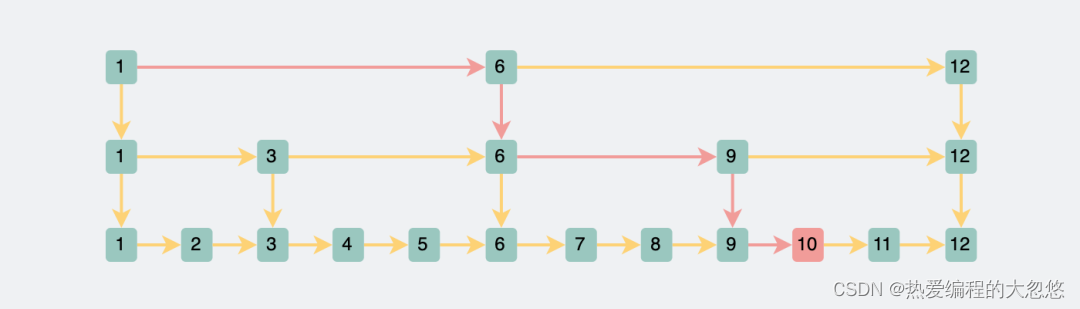
跳表: 通过对链表抽出索引层,以实现二分查找,从而可以快速定位节点位置,提示查找效率:
- 当原始链表有n个结点,则索引的层数为log(n)-1,在每一层的访问次数是常量,因此查找结点的平均时间复杂度为O(logn)。
- 增加了索引层,空间开销变大,相当于是以空间换时间
B+ Tree
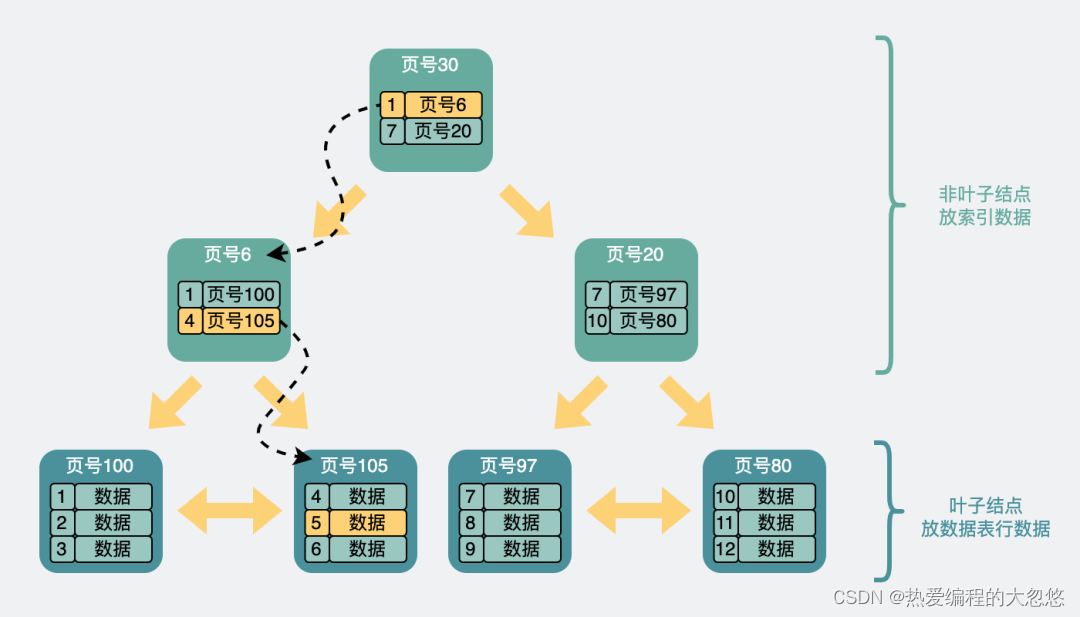
一般来说B+树是由多个页组成的多级层级结构,每个页16Kb,对于主键索引来说,叶子节点存放用户完整行数据,非叶子节点存放索引信息(索引列和页号)。每个数据页内部,通过页目录实现二分查找
B+ tree也是利用了空间换时间的方式,同时利用索引层可以存放大量索引这一特点,使得B+ tree整体看上去更矮更胖,即定位记录需要的IO次数更少,每一层存放的数据量更多。
跳表和B+ tree相同之处
相同:
- B+树和跳表都是在最底层包含所有用户数据,并且都是按顺序排列,时候范围查询
- B+树和跳表利用索引层实现二叉查看,从而提高性能
不同之处也就是二者使用场景的区别了。
跳表和B+ tree在数据插入方面的性能
B+ tree插入性能分析
B+ Tree本质是一种多路平衡树,关键在于"平衡"二字,它的含义是子树们的高度层级尽量一致(最多差一个层级),这样在搜索的时候,不管是到哪个子树分支,搜索次数都差不太多。
当我们向数据库表不断插入记录时,为了维持B+树的平衡,B+树会不断分裂调整数据页。
插入主要分为以下三种情况:
- 叶子结点和索引结点都没满的情况,直接将数据插入叶子结点即可
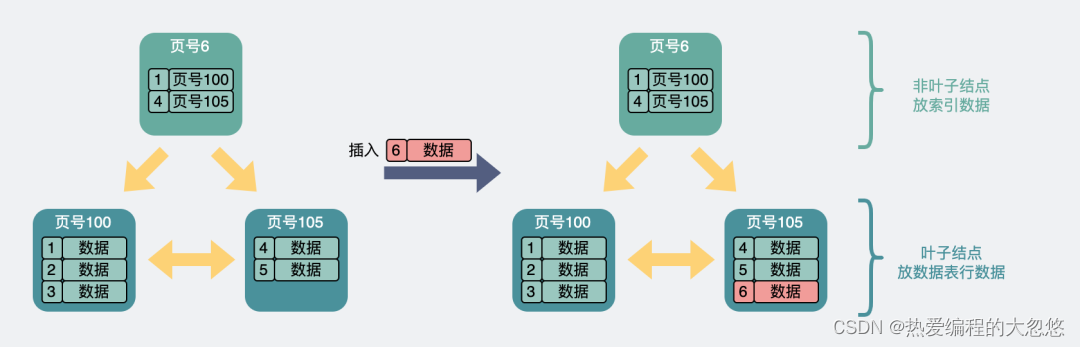
- 叶子结点满了,索引结点没满的情况,拆分叶子结点,索引结点中需要增加新的索引项
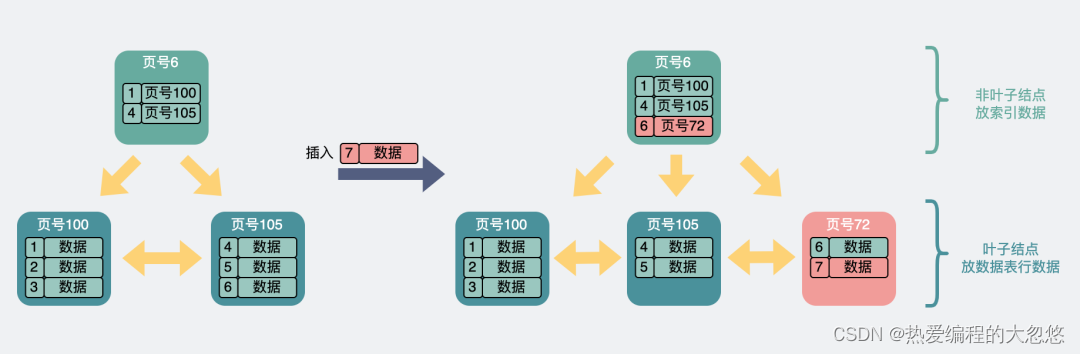
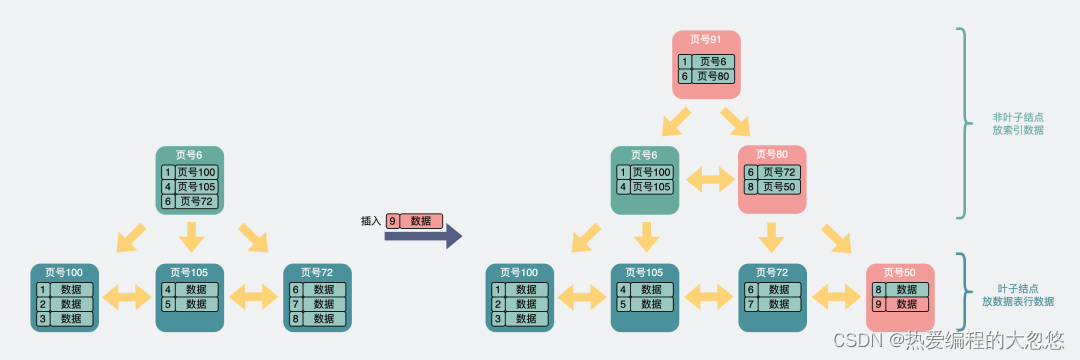
- 叶子结点满了,且索引结点也满了。叶子和索引结点都要拆分,同时往上还要再加一层索引。
跳表插入性能分析
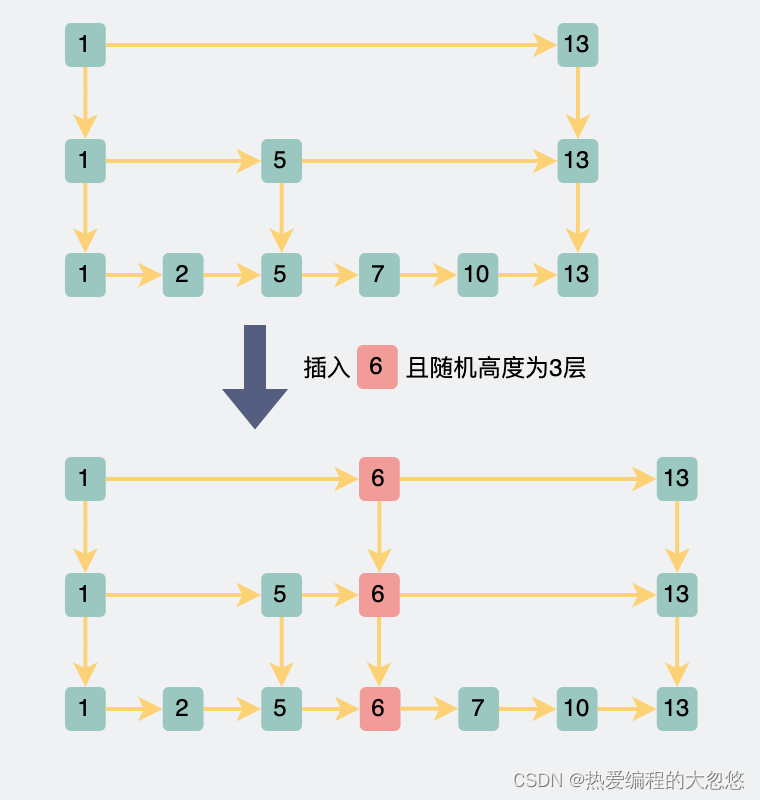
当我们需要往跳表中插入数据时,是通过随机函数产生当前节点的层数,然后更新每一层索引,往其中加入一个节点,如果当前层数不足,就新添加一个索引层。
理论上为了达到二分效果,每一层的节点数需要是下一层节点数的二分之一。
为什么Innodb选择B+ tree而不是跳表
- B+ tree是多叉树结构,每个结点都是一个16k的数据页,能存放较多的索引信息,所以扇出很高。三层左右就可以存储2kw左右的数据。也就是说查询一次数据,如果这些数据页都在磁盘里,那么最多需要查询三次磁盘IO。
- 跳表是链表结构,一个结点存放一条数据,如果底层需要存储2kw数据,且每次查询都能达到二分效果,2kw大概需要2的24次方左右,也就是说跳表高度大概在24层左右。最坏情况下,这24层数据会分散在不同的数据页里,也就是说查询一次数据需要24次磁盘IO。
因此,存放同样量级的数据,B+ tree的高度会比跳表的要少,对于数据库系统而言,意味着一次查询需要的磁盘IO次数更少,因此查询效率更高。
对于写操作而言,B+树需要拆分合并数据页,跳表则是独立插入,并且根据随机函数确定层数,没有旋转和维持平衡带来的开销,因此跳表的写入性能会比B+ tree树要好。
为什么Redis有序集合底层选择跳表而非B+ tree
redis是基于内存的数据库,因此不需要考虑磁盘IO,所以索引层数在redis看了就不再是跳表的劣势了
- B+树在数据写入时,存在拆分和合并数据页的开销,目的是为了保持树的平衡。
- 跳表在数据写入时,只需要通过随机函数生成当前节点的层数即可,然后更新每一层索引,往其中加入一个节点,相比于B+ tree而言,少了旋转平衡带来的开销。
因此,redis最终选择的是跳表,而不是B+ tree。
由于跳表的查询复杂度在O(logn),因此redis中zset数据类型底层结合使用skiplist和hash,用空间换时间,利用跳表支持范围查询和有序查询,利用hash支持精确查询。
小结
- B+ 树是多路平衡搜索树,扇出高,三层高度即可容纳2kw左右的数据,相同情况下,跳表则需要大约24层,假设层高对应磁盘IO,那么B+树的读性能会比跳表要好,因此Innodb选择了B+树做索引
- redis读写全在内存中,不涉及磁盘IO,无需考虑索引层高度,同时由于跳表实现起来更加简单,相比B+ tree而言,少了选择树结构的开销,因此redis使用跳表来实现zset,而不是B+ tree。