二叉树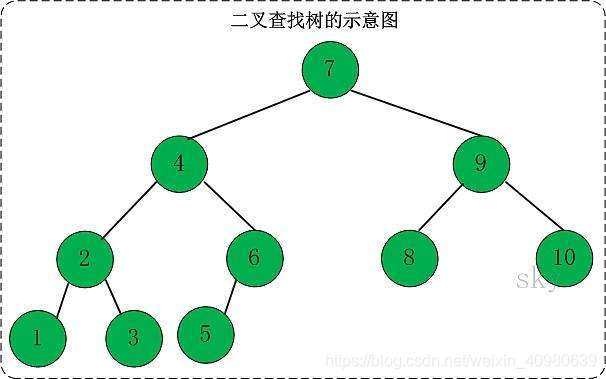
二叉树这种数据结构不太稳定,当插入的数据总是比上一个插入的数据大或者小,这时候的数据结构就像一个链表,当检索底层叶子节点的数据时,要检索整颗树。
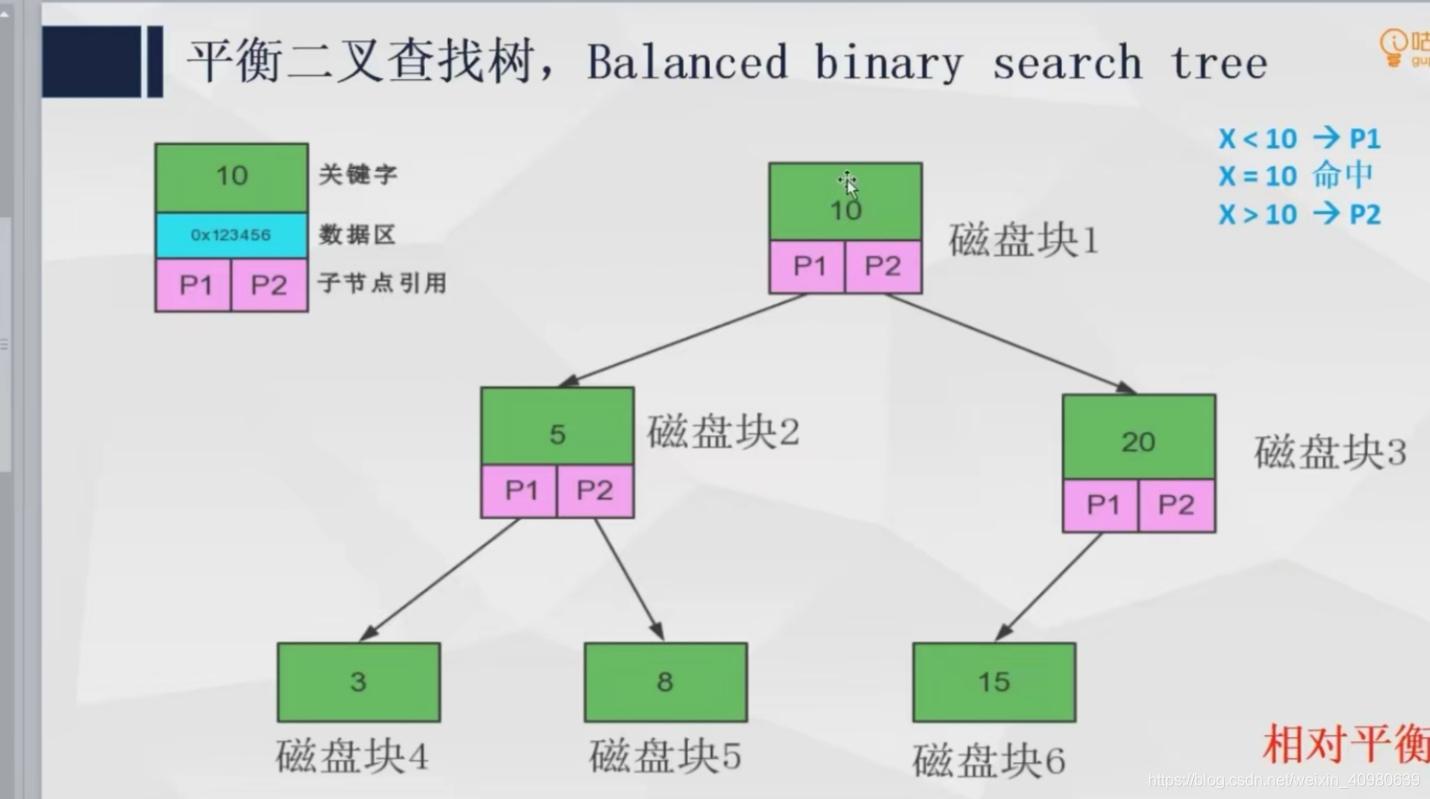
二叉树和平衡二叉树的磁盘块主要有三部分组成,关键字,数据区,子节点引用
关键字:索引列的值,当是主健id索引时,关键字就是id值
数据区: 当时主健索引时,存放的是当前行的数据,当是一般索引时,存放的是当前行的id值
平衡二叉树相对于二叉树虽然保证了数据的平衡,但是随着数据的上升,树的深度也会越来越大。
小结:1.以上2种数据结构树的的高度都太深了。数据处的深度决定了 io的次数。2.每个磁盘块保存的数据量太小了。没有很好的利用磁盘io的数据交换特性,每读取一页的数据是最好。每页16k,大小可以设置。也没有利用好磁盘的预读能力,从而带来频繁的io操作。
b tree
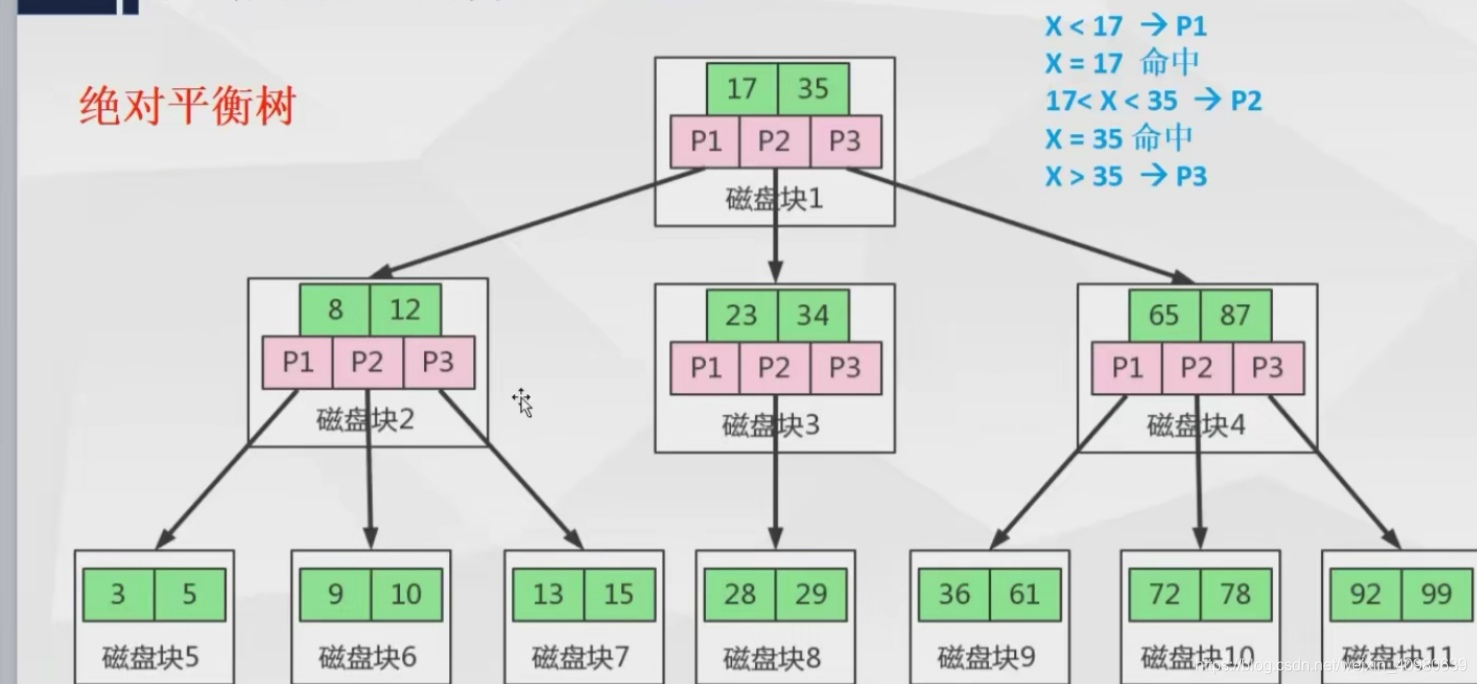
b tree解决以上的问题,可以保存很多的关键字,路数也不在是局限的二路,而是关键字+1路。
b+tree
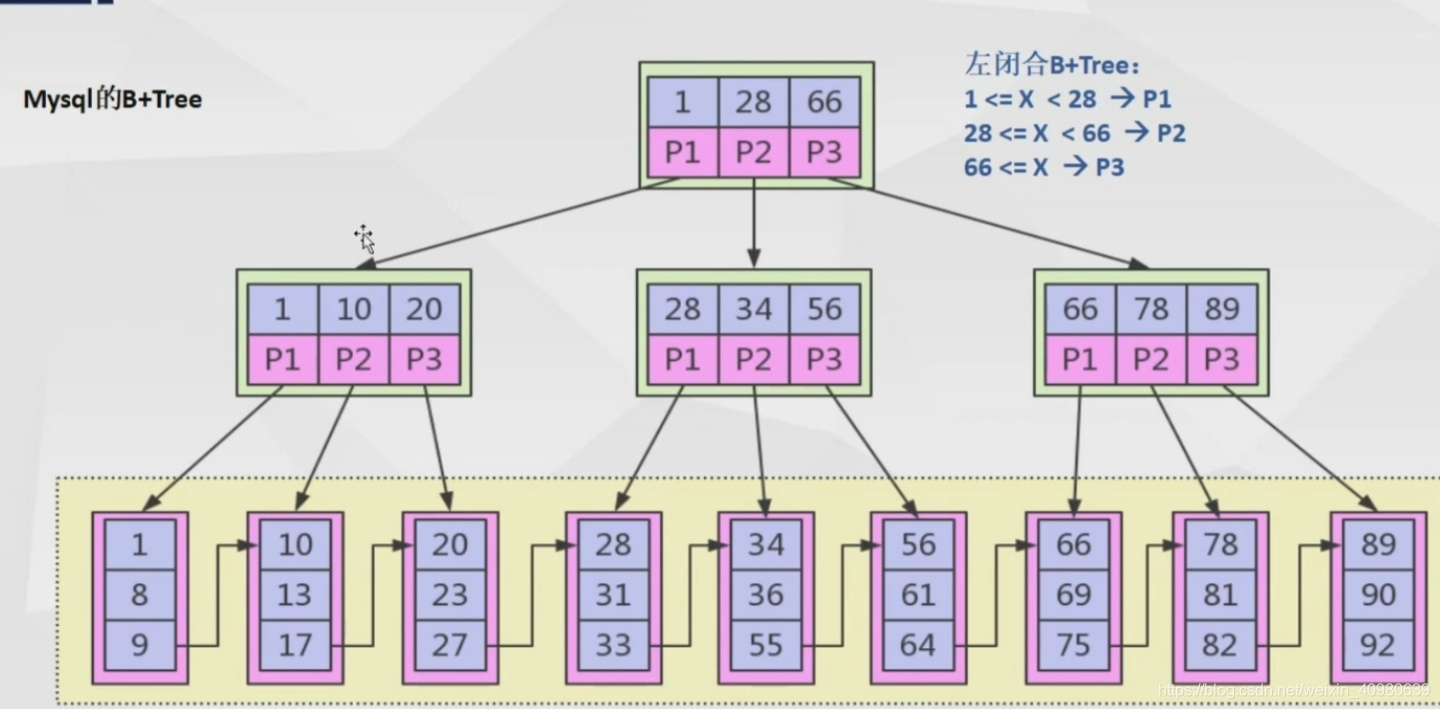
b+tree是btree的加强版
b+tree和btree的区别
1.b+节点关键字采用闭合区间
2.b+非叶节点不保存数据相关信息,只保存关键字和子节点的引用
3.b+关键字对应的数据保存在叶子节点中
4.b+叶子节点是顺序排序的,并且相邻节点具有顺序引用的关系表
为什么选用b+tree
1.b+树拥有b树的优势
2.扫库表能力更强
3.树的操盘读写能力更强
4.排序能力更强
5.查的效率更加稳定,b树查询第二层和最底层时间是偏差的,设计角度不太稳定
