Kafka基础篇学习笔记整理
该文为Kafka基础篇学习笔记整理:
-
参考视频: kafka一小时入门精讲课程
-
参考文档: 极客时间: Kafka核心技术与实战 和 Kafka权威指南
本文作为Kafka基础篇学习笔记整理,主要包含kafka进阶知识点和SpringBoot整合kafka部分。
本文大部分图为个人手绘补充,绘图软件采用: draw.io
完整代码Demo工程仓库链接: https://gitee.com/DaHuYuXiXi/kafak-demo
本文前置知识参考kafka入门篇: Kafka入门篇学习笔记整理
生产者
数据发送流程
kafka生产者客户端的数据发送流程分为三个阶段:
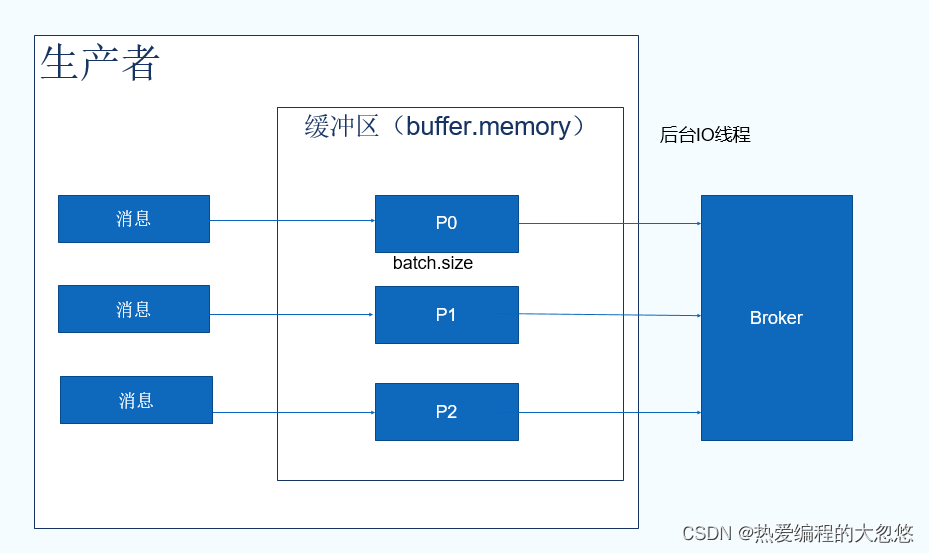
- 主线程调用KafkaProducer发送数据,数据不是之间发送给kafka broker服务端,而是先缓冲起来
- 异步线程sender负责将缓冲数据发往kafka broker服务端
- 使用缓冲可以避免高并发请求造成服务端压力,并且还可以利用缓冲实现数据批量发送。
- 异步sender线程负责数据发送,避免了主线程发送数据阻塞,造成核心业务响应延迟。
下面我们从源码角度来看一下这个过程:
- 先来看一下KafkaProducer的构造函数,只保留与数据发送有关的部分
KafkaProducer(ProducerConfig config,
Serializer<K> keySerializer,
Serializer<V> valueSerializer,
ProducerMetadata metadata,
KafkaClient kafkaClient,
ProducerInterceptors<K, V> interceptors,
Time time) {
...
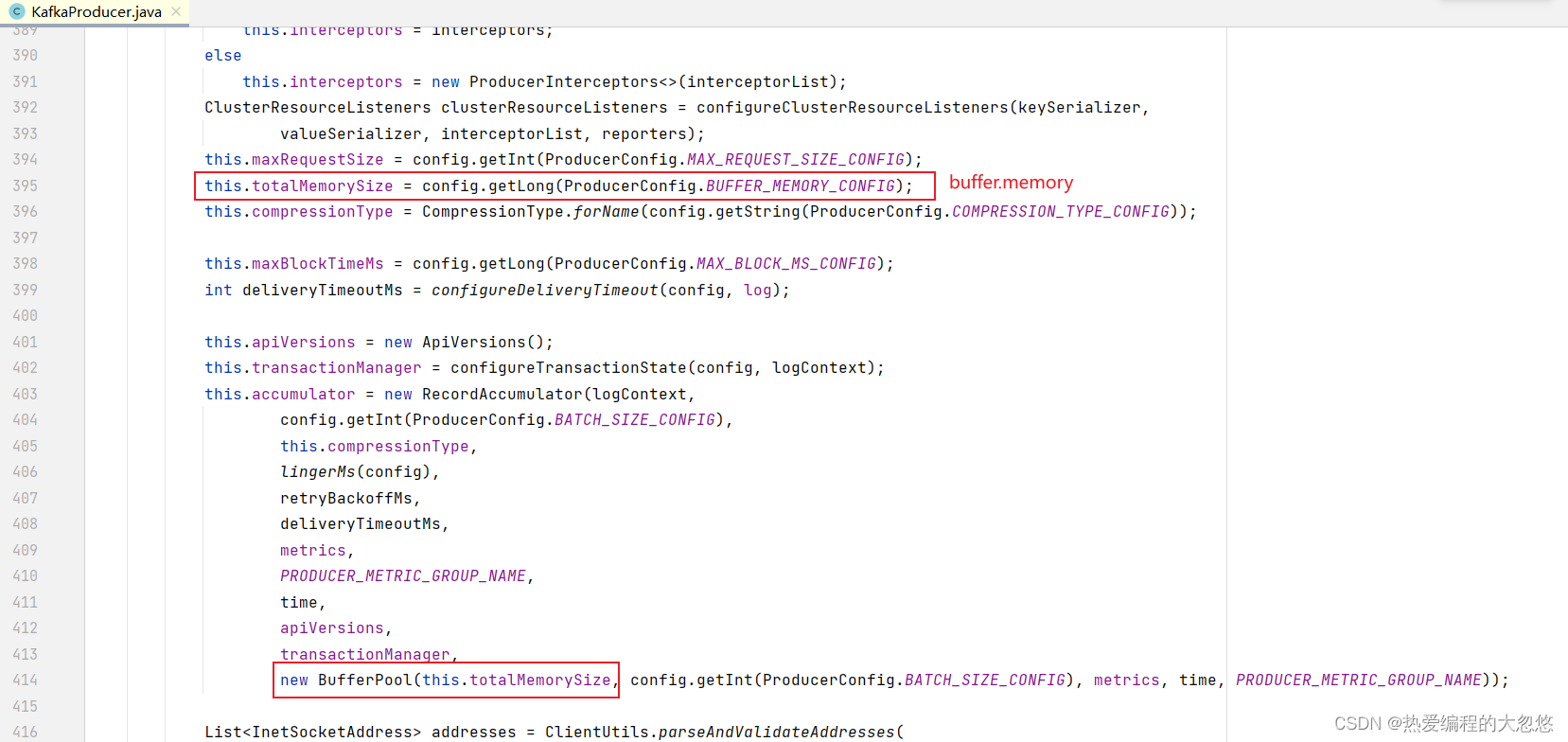
//记录累加器
this.accumulator = new RecordAccumulator(logContext,
config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
this.compressionType,
lingerMs(config),
retryBackoffMs,
deliveryTimeoutMs,
metrics,
PRODUCER_METRIC_GROUP_NAME,
time,
apiVersions,
transactionManager,
new BufferPool(this.totalMemorySize, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), metrics, time, PRODUCER_METRIC_GROUP_NAME));
....
//数据发送线程
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
....
}
- 记录累加器RecordAccumulator,也就是生产者KafkaProducer生产的数据不是直接发送给kafka broker,而是批量累加先放入RecordAccumulator,然后分批次发送给kafka broker。
- 数据发送有一个单独的sender线程来完成,一个KafkaProducer对应一个Sender线程。
- 记录累加器作为KafkaProducer的数据缓冲区,具体构造如下
public class RecordAccumulator {
...
private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;
- batches为数据缓冲区,针对TopicPartition(一个主题的一个分区),维护了一个Deque双端队列。
- 这个双端队列里面存放的数据类型为ProducerBatch,代表生产者生产的一批数据。
- RecordAccumulator类的append方法用于向数据缓冲区中添加数据
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock,
boolean abortOnNewBatch,
long nowMs) throws InterruptedException {
...
try {
//获取已有的缓冲区,或者创建新的缓冲区(Deque)
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
//锁住该缓冲区,避免用户异步编程操作导致数据发送数据顺序错乱的问题
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
//tryAppend方法将一条消息数据的时间戳、key、value、
//header等信息追加到缓冲区中(Deque<ProducerBatch> )
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq, nowMs);
if (appendResult != null)
return appendResult;
}
...
synchronized (dq) {
...
//再次尝试,查看是否能将消息成功追加到Deque的某个批次中
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq, nowMs);
if (appendResult != null) {
return appendResult;
}
//如果追加失败,那么创建一个新的批次,加入Deque尾部
...
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, nowMs);
...
dq.addLast(batch);
...
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true, false);
}
}
tryAppend方法详细分析:
- 当调用该方法时,它将检查给定的消息是否可以添加到当前Deque的最后一个ProducerBatch中,如果可以,则将该消息添加到批次中,并返回一个FutureRecordMetadata对象表示该消息的元数据;
添加失败有两种情况: 当前Deque为空,或者当前批次已满- 否则,它会关闭上一个ProducerBatch并返回null,后面会创建一个新批次,塞入Deque尾部。
- 正常情况下,该方法返回一个RecordAppendResult对象,该对象包含有关记录是否已写入磁盘、分区分配以及是否需要进行重新分区的信息。
在Kafka Producer中,每个ProducerBatch都对应一个Broker分区,该方法的作用是向ProducerBatch批次中尝试添加一条消息,如果该批次已满或无法再分配分区,则会创建一个新的ProducerBatch,并将消息添加到其中。通过使用一个生产者批次来批量发送多条消息,可以提高消息发送的效率和吞吐量,并减少网络IO的消耗。
- 生产者生产的一条消息数据包含哪些方面的信息
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers){
...
//消息属于哪个主题
this.topic = topic;
//消息属于哪个分区
this.partition = partition;
//消息的key
this.key = key;
//消息的value
this.value = value;
//消息的时间戳
this.timestamp = timestamp;
//消息的消息头
this.headers = new RecordHeaders(headers);
}
- 对上面内容做个小结,如下图所示:
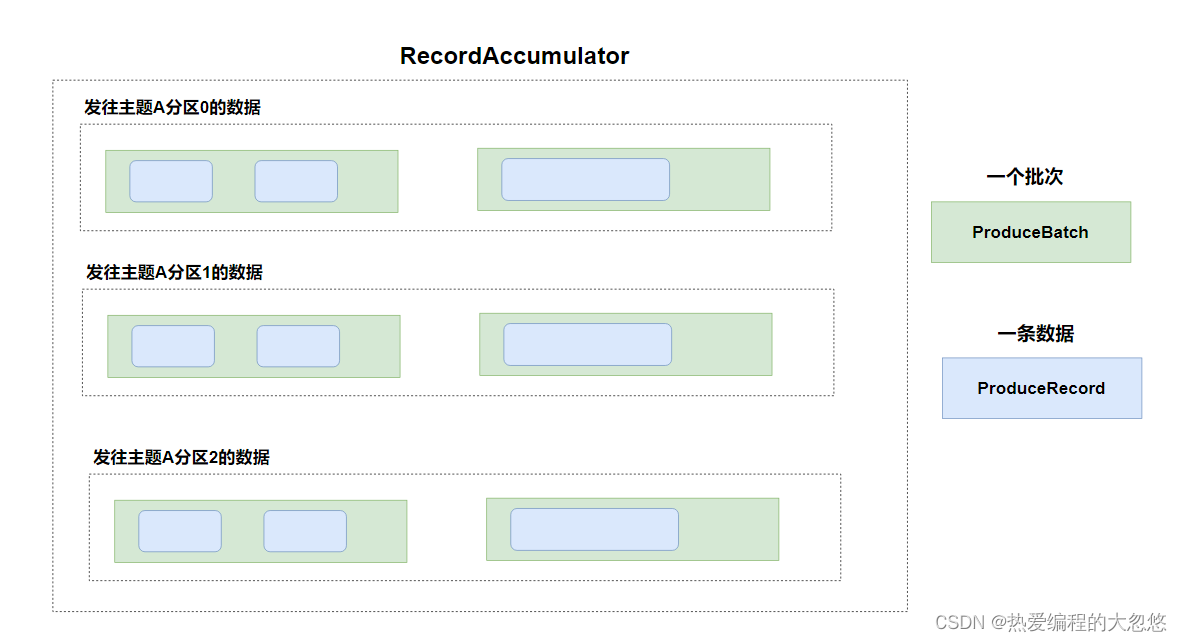
- RecordAccumulator作为数据缓冲区,包含若干Deque双端队列
- 针对一个主题的一个分区,在kafka生产者客户端维护一个Deque双端队列
- 每个队列Deque里面放入若干个批次ProducerBatch的数据
- 每一个批次ProducerBatch包含若干条数据记录ProducerRecord
- 具有相同的key的数据会被发往主题的同一个分区。
注意:
- KafkaProducer在数据发送给服务端之前,会将数据进行分类,分批次的缓冲好,然后由单独的线程将数据异步发送到Kafka服务端,从而提升数据的发送效率。
- 消息的value是按照topic,partition,key进行分类的,按照timestamp的顺序进行投递的
批量与定时发送
KafkaProducer会将消息先放入缓冲区中,然后由单独的sender线程异步发送到broker服务端,那么既然消息是批量发送的,那么触发批量发送的条件是什么呢?
- batch.size:当准备发送到一个分区的缓冲数据量超过batch.size设置的阈值时,就会触发一次批量发送,将该Deque队列中所有数据一次性发送到Broker服务端,batch.size的默认值为16KB。
- linger.ms:如果缓冲区一直达不到发送标准,当时间超过linger.ms设置的值的时候,也会进行数据的发送,这主要考虑到如果batch.size设置的比较大,在某些非活跃时间产生的数据量又比较小,一直达不到batch.size的阈值,那么消息便会一直滞留在缓冲区中。
注意:
- 只要满足上面两个条件其中之一,数据就会被发往服务端
- linger.ms的默认值为0,也就是有数据就发送,但是由于sender是单线程的,生产者有很多缓冲队列Deque,所以缓冲区里面的数据需要等待sender线程空闲后才能被发送。
- linger.ms的默认值是0,在数据量很大的时候,sender线程很忙,缓冲区机制可以保证吞吐量;数据量小的时候,sender线程处理速度很快,可以保证消息的低延迟。
缓冲区大小
buffer.memory: 用来约束Kafka Producer能够使用的内存缓冲的大小的,默认为32MB。
注意:
- 这个buffer.memory参数非常重要,特别是当你的kafka集群主题与分区非常多的时候,对应的生产者分区缓冲队列也就非常多。
- 如果buffer.memory设置的太小,可能导致消息快速的写入内存缓冲里,但Sender线程来不及把消息发送到Kafka服务器。会造成内存缓冲很快就被写满,而一旦被写满,就会阻塞用户线程,不让继续往Kafka写消息。
- buffer.memory要大于batch.size,否则会报申请内存不足的错误,不要超过物理内存,根据实际情况调整。
send发送消息
生产者数据发送流程如下:

- send方法作为发送消息入口
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
//调用拦截器对record进行预处理,该方法不会抛出异常
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
//发送消息
return doSend(interceptedRecord, callback);
}
- doSend以do开头,可知是消息发送的真正入口
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
//1.检测生产者是否已经关闭
throwIfProducerClosed();
//2、检查正要将数据发往的主题在kafka集群中的包含哪些分区
//获取集群中一些元数据信息
long nowMs = time.milliseconds();
ClusterAndWaitTime clusterAndWaitTime;
try {
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
...
}
nowMs += clusterAndWaitTime.waitedOnMetadataMs;
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
byte[] serializedKey;
try {
//3.对消息的key进行序列化
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
...
}
byte[] serializedValue;
try {
//4.对消息的value进行序列化
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
...
}
//5.分区器进行计算,决定此条消息发送到哪个分区
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
...
//6.预估消息发送消息的大小,内容包括key,value以及消息头
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
//7.检查发送消息的大小是否超过阈值
ensureValidRecordSize(serializedSize);
...
// 拦截器回调函数
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
//8.将消息添加到消息累加器(缓冲区)
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
...
//9.如果添加进缓冲队列已经满了,或者是首次创建的,那么幻想sender线程进行数据发送
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
//10.返回future对象
return result.future;
}
...
}
dosend方法总结(上面源码省略了很多内容,大家结合具体源码来查看):
- dosend方法内部,首先检查是否关闭了Producer,然后调用waitOnMetadata方法等待元数据可用。
- 接下来,根据记录的键值对以及集群信息计算出分区,并使用RecordAccumulator类将消息添加到缓冲区中。
- 如果缓冲区已满或需要创建新的分区批次,则会唤醒Sender线程,将积压的消息批次发送到Kafka Broker。
- 如果发送过程中发生异常,将会调用相应的拦截器并返回一个FutureFailure对象表示失败的结果。
- 否则,返回一个Future< RecordMetadata >对象表示成功的结果。
- 目前,这个方法还包含处理API异常和记录错误的逻辑。
总的来说,该方法实现了Kafka Producer发送消息的核心逻辑,包括获取元数据、计算分区、将消息添加到缓冲区、处理异常和记录错误等。同时,它也支持拦截器机制,允许开发人员自定义消息的处理行为。
消息可靠性
kafka要保证消息的生产和消费过程的可靠性,需要从Broker服务端,生产者客户端,消费者客户端三管其下,只有这三个方面都保证可靠性,才能实现消息不重复,不丢失。
本节站在生产者客户端来谈谈如何保证消息的可靠性,kafka提供了一些生产者配置参数来保证:
- 消息不丢失
- 消息不重复发送
发布确认机制
- 相关参数如下:
#新版本中
acks=all
#在一些比较旧的apache kafka老版本中,参数名称如下
request.required.acks=all
ack参数决定了生产者发送完消息后,如何消息进行确认的机制:
- acks=0: 生产者将消息写入缓冲区后,就认为消息发送成功
- acks=1: 只要消息被对应分区的Leader副本端接收成功,就认为消息发送成功。
由于kafka生产者只和Leader分区副本进行通信,Follower副本负责从Leader分区进行副本的同步。所以,如果由于某些原因导致当前主题的分区副本进行Leader重新选举,如果选举完成后,前任Leader宕机,导致消息没有被复制到现任Leader那里,就会导致数据丢失。
- acks=all 或者 acks= -1 : ISR 中所有的副本都写入成功才算成功 , Leader在向生产者进行消息确认之前,需要等待ISR集合中所有副本完成消息同步,该方式最为可靠,同时效率也是最低的。
重试机制
- 相关参数如下:
retries=Integer.MAX_VALUE
retry.backoff.ms=100
delivery.timeout.ms=120000
注意:
- 当生产者发送消息时出现
RetriableException会进行重试,也就是重新发送消息。retries配置了允许重试的最大次数;retry.backoff.ms配置了2次重试之间的时间间隔,单位ms毫秒;delivery.timeout.ms配置了消息完成发送的超时时间,超过这个时间将不再重试,retries参数失效。
注意:
delivery.timeout.ms是Kafka生产者配置中的一个参数,用于指定发送消息的最大等待时间。具体来说,它定义了发送消息时,客户端等待服务器应答的时间上限。如果在规定的时间内未收到服务器的确认,则会抛出一个DeliveryException异常。
默认情况下,delivery.timeout.ms的值为2分钟(120000毫秒),这通常足以覆盖绝大多数情况。但是,在某些情况下,例如网络延迟较高或服务器繁忙等情况下,可能需要增加这个值,以便更充分地利用Kafka集群的容错性和可用性。
需要注意的是,delivery.timeout.ms只适用于异步发送模式(即使用send方法而不是sendSync方法)。在同步发送模式下,由于每个请求都会阻塞,所以不存在超时问题。
总的来说,delivery.timeout.ms是一个重要的Kafka生产者配置参数,可以帮助控制发送消息的最大等待时间,从而提高消息传递的可靠性和稳定性。但是,需要根据实际情况进行合理的调整,以免出现过度等待或消息丢失的问题。
注意:
retry.backoff.ms是Kafka生产者配置中的一个参数,用于控制在重试发送消息时等待的时间。具体来说,它定义了在第一次发送消息失败后,客户端等待下一次尝试之前的等待时间。
默认情况下,retry.backoff.ms的值为100毫秒,这通常足以应对大多数网络故障和其他异常情况。但是,在某些情况下,例如网络延迟较高或服务器繁忙等情况下,可能需要增加这个值,以便更稳定地处理消息传递失败的情况。
需要注意的是,retry.backoff.ms只适用于异步发送模式(即使用send方法而不是sendSync方法)。在同步发送模式下,由于每个请求都会阻塞,所以不存在重试问题。
总的来说,retry.backoff.ms是一个重要的Kafka生产者配置参数,可以帮助控制在重试发送消息时等待的时间,并提高消息传递的可靠性和稳定性。但是,需要根据实际情况进行合理的调整,以免过度等待或消息丢失的问题。
-
什么时候会抛出RetriableException异常呢?
- 对于分区Leader正在重新选举造成的异常等属于RetriableException,针对这类的异常生产者会进行重试。因为Leader选举完成之后,重新发送消息是会成功的。
- 对于配置信息错误导致的异常,生产者是不会进行重试的,因为尝试再多次程序也不能自动修改配置,还是需要人为干预才行。对于这类的异常进行消息发送的重试是没有意义的。
-
重试多次仍然失败的情况如何处理呢?
- 这种情况是可能出现的,在达到了
retries上限或delivery.timeout.ms上限之后,消息发送重试了多次,仍然没有发送成功。对于这种情况,我们还是要区别对待- 如果是用户的订单数据、用户的支付数据等,这类数据是绝对不能丢的。当出现异常的时候,就需要开发者catch异常并做好异常处理。或是将未能成功发送的数据入库、或是写文件先保存起来。等待异常通过人为干预的方式解除之后,再重新发往kafka。
- 如果消息数据是用户网页点击量、商品阅读量这类的数据,数据量大、对于数据处理延时也没有太多的要求,甚至在异常情况下出现数据丢失也不是不能容忍。对于这类情况,其实也就没有必要做太多的异常处理。做好告警及日志记录,发现问题、解决问题,从程序及kafka服务端、网络性能等角度优化。
- 这种情况是可能出现的,在达到了
-
重试可能会产生消息重复消费问题,这个问题如何解决呢?
- 生产者第一次发送数据至broker,可能由于网络原因,生产者没有能够得到服务端写入成功的消息的确认,
即:实际上消息数据已经在服务端写入成功,但是生产者没有接收到服务端的ack响应。 - 由于生产者没有收到消息确认成功写入,它就认为消息发送失败了。所以重新发送了该消息,结果这个消息就有可能被写入多次。
- 在kafka0.11.0.0版本之前是无法实现exactly once,也就是无法实现消息被发送一次,并且只被发送一次。从0.11.0.0版本开始引入了
EOS(exactly once semantics,精确一次处理语义),通过实现消息数据的幂等性和事务处理,来实现消息数据被精确的发送一次。
- 生产者第一次发送数据至broker,可能由于网络原因,生产者没有能够得到服务端写入成功的消息的确认,
消息顺序性问题
本节我们讨论的是kafka生产端如何确保消息发送有序性呢? 有几种常见的手段呢?
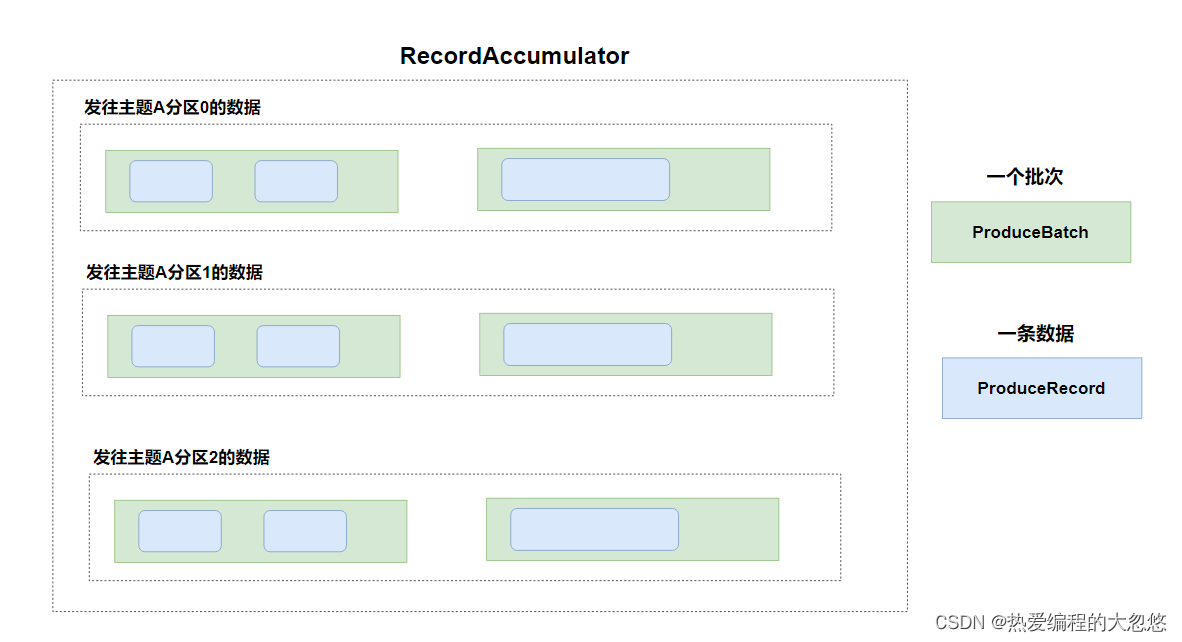
- kafka生产者缓冲区包含若干个缓冲队列,每一个缓冲队列对应kafka服务端的一个主题的一个分区。
- 缓冲队列的数据结构是Deque,是一个双端队列,一端放入数据,一端取出数据。
结合上图,可知:
- 在生产者中的双端缓冲队列中,消息是可以保证顺序的,一端进一端出。
- 每一个双端队列对应kafka服务端的一个主题的分区,所以kafka可以保证消息数据在一个分区内的有序性。
因此,要实现消息的有序性,有以下几个思路:
- 对应主题下只创建一个分区,那么这个主题下所有数据的发送和消费就都是有序的 —> 数据量比较小的主题可以这样干
- 通过自定义分区器,将需要实现有序的消息发送到同一个分区
- 发送消息时,指定key值,具有相同key的消息会被发送到同一个分区
如何避免重试导致消息顺序错乱
kafka生产者提供了消息发送的重试机制,也就是说消息发送失败后,kafka生产者会重新发送消息,那么就会出现下面这种情况:
- 第一个批次的消息发送后,因为某种特殊原因(如主题分区正在重新选举Leader)导致数据发送失败了
- 第二个批次的消息发送,服务端数据保存成功了。
- 因为第一个批次消息发送失败,kafka重新尝试发送第一个批次的数据,这次成功了
这就会导致了发往kafka分区的数据出现了顺序上的错乱,如果要避免这个问题,我们需要设置一下生产端相关参数,如下所示:
max.in.flight.requests.per.connection=1
这个参数的作用是:对于一个kafka客户端请求连接(可以认为是一个生产者),一旦出现1个批次的消息发送失败,在该批次的数据重试(重新发送)成功之前,下一个批次的消息数据发送处于阻塞状态。上一个批次不成功,下一个批次就永远发不出去。
注意:
- max.in.flight.requests.per.connection是Kafka生产者配置中的一个参数,用于控制每个连接可以发送到服务器的未确认请求数量。
- 具体来说,它定义了在一个TCP连接上没有收到服务器响应之前可以向该连接发送的最大请求次数。
- 例如,如果将max.in.flight.requests.per.connection设置为1,则客户端必须在收到对之前发送的请求的响应之后才能发送下一个请求。
- 这个参数的默认值是5,这意味着在一个TCP连接上最多可以有5个未确认的请求。
- 通过增加这个参数的值,可以提高Kafka客户端的性能,因为它允许更多的请求同时被发送和处理。
- 但是,如果设置过高,这可能会导致Kafka Broker过载或网络拥塞,从而影响整个系统的可用性和性能。
需要注意的是,max.in.flight.requests.per.connection只适用于异步发送模式(即使用send方法而不是sendSync方法)。在同步发送模式下,由于每个请求都会阻塞,所以不存在未确认的请求问题。总的来说,max.in.flight.requests.per.connection是一个重要的Kafka生产者配置参数,可以帮助优化生产者的性能和吞吐量,但需要根据实际情况进行合理的调整。
自定义拦截器
- 通过实现kafka提供的拦截器接口类ProducerInterceptor,可以实现消息拦截器的效果,具体如下:
public interface ProducerInterceptor<K, V> extends Configurable {
/**
* 该方法封装于KafkaProducer.send()方法中,运行在用户主线程
* Producer确保在消息序列化前调用该方法,可以对消息进行任意操作,但慎重修改消息的topic、key和partition,会影响分区以及日志压缩
*/
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);
/**
* 该方法在消息发送结果应答或者发送失败时调用,并且通常都是在callback()触发之前执行,运行在IO线程中
。实现该方法的代码逻辑尽量简单,否则影响消息发送效率
*/
public void onAcknowledgement(RecordMetadata metadata, Exception exception);
/**
* 生产者的producer.close触发
*/
public void close();
}
- 例如: 消息发送成功或者失败的次数统计
public class RequestStatCalInterceptor implements ProducerInterceptor<String,String> {
private static final String MSG_PREFIX="dhy:";
private final AtomicInteger successCnt = new AtomicInteger(0);
private final AtomicInteger errorCnt = new AtomicInteger(0);
@Override
public ProducerRecord<String,String> onSend(ProducerRecord<String,String> msg) {
return new ProducerRecord<>(msg.topic(),msg.partition(),msg.timestamp(),msg.key(),MSG_PREFIX+msg.value());
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if (metadata == null) {
errorCnt.getAndIncrement();
}else {
successCnt.getAndIncrement();
}
}
@Override
public void close() {
double successRate = (double) successCnt.get() / (successCnt.get() + errorCnt.get());
System.out.println("消息发送成功率:" + successRate*100 +"%");
}
@Override
public void configure(Map<String, ?> configs) {
}
}
- 应用拦截器
注意:
- 生产者拦截器可做消息发送前以及producer回调前的定制化需求,允许用户指定多个Interceptor按照配置顺序作用于一条消息从而形成一个拦截链
//拦截器的配置
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, Collections.singletonList("interceptor.RequestStatCalInterceptor"));
也可以单独指定配置一个拦截器:
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, RequestStatCalInterceptor.class.getName());
- 测试

自定义序列化器
kafka客户端生产者序列化接口如下,如果我们需要实现自定义数据格式的序列化,需要定义一个类实现该接口。
什么是序列化和反序列化:
- 把对象转成可传输、可存储的格式(json、xml、二进制、甚至自定义格式)叫做序列化。
- 反序列化就是将可传输、可存储的格式转换成对象。
- kafak提供的序列化器接口
/**
* 将对象转成二进制数组的接口序列化实现类
*/
public interface Serializer<T> extends Closeable {
/**
* 参数configs会传入生产者配置参数,
* 序列化器实现类可以根据生产者参数配置影响序列化逻辑
* isKey布尔型,表示当前序列化的对象是不是消息的key,如果不是key就是value
*/
default void configure(Map<String, ?> configs, boolean isKey) {
// intentionally left blank
}
/**
* 重要方法将对象data转换为二进制数组
*/
byte[] serialize(String topic, T data);
default byte[] serialize(String topic, Headers headers, T data) {
return serialize(topic, data);
}
/**
* 关闭序列化器
* 此方法的实现必须是幂等的,因为可能被调多次
*/
@Override
default void close() {
// intentionally left blank
}
}
- 使用JackSon进行序列化的例子,Jackson是SpringBoot默认的JSON处理框架
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.7</version>
</dependency>
- 定义一个类,作为我们的对象序列化的目标类。
public class Peo {
private String name;
private Integer age;
...
}
- 自定义序列化器
public class JacksonSerializer implements Serializer<Peo> {
private static final ObjectMapper objectMapper = new ObjectMapper();
@Override
public byte[] serialize(String topic, Peo data) {
byte[] result=null;
try {
result=objectMapper.writeValueAsBytes(data);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
return result;
}
}
注意: ObjectMapper是线程安全的,可以在多个线程之间共享和重用。它的线程安全性主要来自于以下两个方面:
- ObjectMapper本身是不可变的
- ObjectMapper对象在创建后不会被修改,因此可以被视为不可变对象。这意味着多个线程可以同时访问同一个ObjectMapper实例,而不需要担心并发修改和竞态条件等问题。
- ObjectMapper使用了线程安全的数据结构
- ObjectMapper使用了一些线程安全的数据结构,例如ThreadLocal、ConcurrentHashMap和CopyOnWriteArrayList等。这些数据结构是专门设计用于多线程环境的,并且能够提供高效的并发访问和修改。
- 需要注意的是,虽然ObjectMapper本身是线程安全的,但是它所使用的类(例如序列化和反序列化的POJO类)可能不是线程安全的。因此,在处理复杂的数据类型时,需要考虑到这些类的线程安全性,并在必要时进行额外的同步或复制等操作,以避免出现竞态条件和线程安全问题。
- 应用序列化器
注意:
- kafka生产者消息只能选择一种格式,不能上一条数据是JSON,下一条数据是XML。所以序列化器也只能配置一个。
//序列化器的配置
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JacksonSerializer.class.getName());
- 编写测试用例,配合断点查看序列化器是否生效
@Test
void testJacksonSerializer() throws ExecutionException, InterruptedException {
Peo peo = new Peo();
peo.setName("dhy");
peo.setAge(18);
KafkaProducer<String, Peo> producer = new KafkaProducer<>(props);
RecordMetadata metadata = producer.send(new ProducerRecord<>(TEST_TOPIC, peo)).get();
System.out.println("消息偏移量为:"+metadata.offset());
}
自定义分区器
KafkaProducer的默认分区策略为:
- 默认策略一:如果生产者指定了partition分区,就直接发送到该partition分区
- 默认策略二:如果没有指定分区但是指定了key,就按照key的hash值选择分区,具有相同key值的消息将被发往同一个分区。
- 默认策略三:如果partition和key都没有指定就使用轮询策略,能保证消息相对均衡的分配给同一个主题下的多个分区。
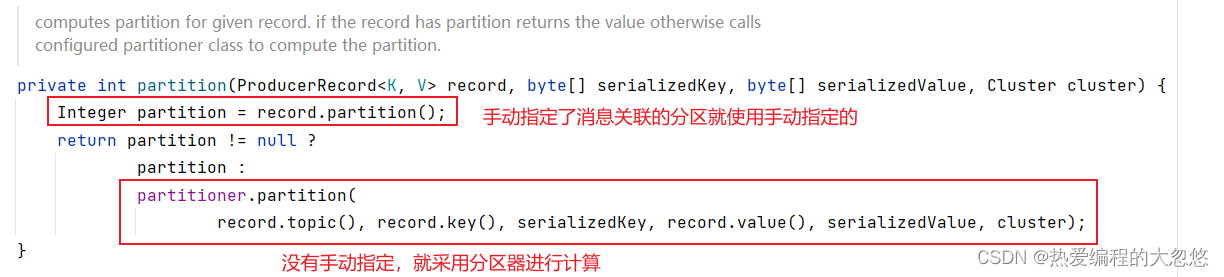
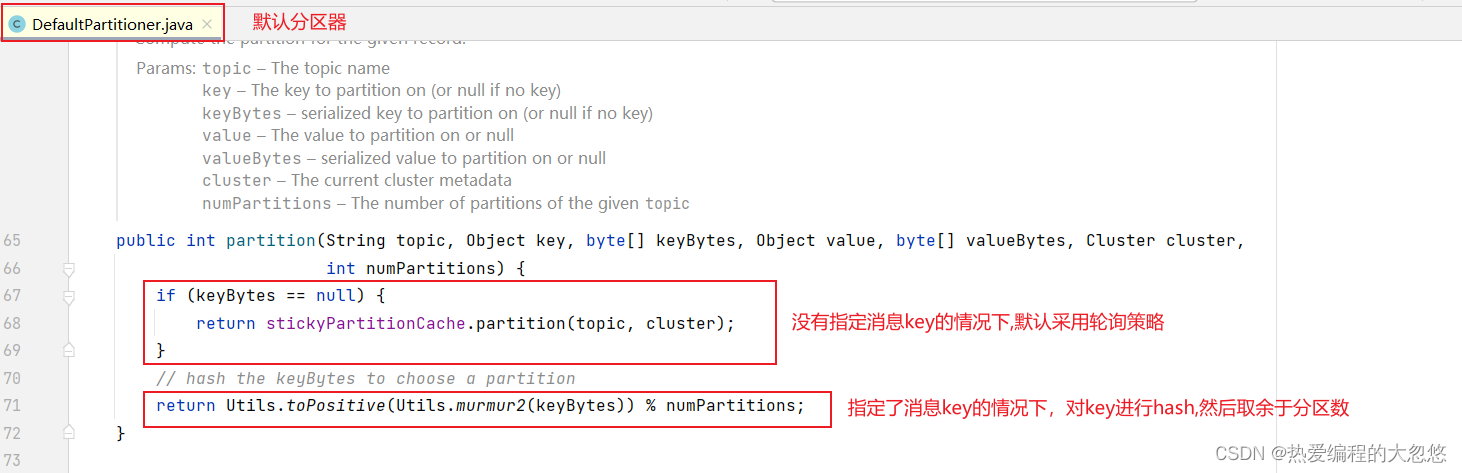
- 为了保证生产者消息发送的有序性和消费者消费数据的有序性,就必须将这些消息发送到同一个分区
- 如果要将消息发送到同一个分区,有三种方法:
- 生产者手动指定partition
- 需要发送到同一个分区的消息,指定相同的key
- 自定义分区器实现分区逻辑
- 分区器接口
/**
* 分区器接口
*/
public interface Partitioner extends Configurable, Closeable {
/**
* 根据消息record信息对其进行重新分区
*
* @param topic 主题名称
* @param key 用于分区的key对象
* @param keyBytes 用于分区的key的二进制数组
* @param value 生产者消息对象
* @param valueBytes 生产者消息对象的二进制数组
* @param cluster 当前kafka集群的metadata信息
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
/**
* 当分区器执行完成时被调用
*/
public void close();
default public void onNewBatch(String topic, Cluster cluster, int prevPartition) {
}
}
- 自定义分区器
/**
* 通过对消息value进行hash,然后取余于分区数计算出消息要被路由到的分区
*/
public class ValuePartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return partition(valueBytes, cluster.partitionsForTopic(topic).size());
}
private int partition(byte[] valueBytes, int numPartitions) {
return Utils.toPositive(Utils.murmur2(valueBytes)) % numPartitions;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
- 应用自定义分区器: 为生产者指定自定义分区器,这样配置完成之后,生产者再次发送消息时,会遵守分区器中partition方法中定义的分区规则,将数据发往指定的分区。
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, ValuePartitioner.class.getName());
幂等与事务
在生产者消息可靠性的重试机制一节,我们讲过kafka生产者发送数据失败后的重试机制,同时也介绍过一种可能产生的异常情况:
- 生产者发送数据至broker,由于网络原因生产者可能会没有能够得到服务端的确认(确认消息发送的成功),实际上消息数据已经成功发送,kafka服务端broker已经成功写入。
- 由于生产者没有收到消息确认成功写入,它就认为消息发送失败了。所以重新发送了该消息,结果这个消息就有可能在kafka broker服务端被写入第二次。
通常情况下我们不能接受这种情况的发生,我们期望的效果是exactly once(一批数据发送成功一次,并且只成功一次)。在0.11.0.0版本之前这是做不到的,在0.11.0.0版本之后kafka引入了幂等和事务机制,从而可以支持exactly once语义。
概念介绍:
- 幂等:简单地说就是对接口的多次调用所产生的结果和调用一次产生的结果是一致的。对于kafka而言就是消息发送一次与消息被发送多次产生的结果是一样的,消息不会被消费者重复处理。
- 事务:事务这个词对于开发者可能就比较熟悉了,通常是指一系列操作行为要么都成功,要么都失败(回滚)。对于kafka而言,事务是用来保证多条消息要么都发送成功(都写入kafka broker数据日志),要么就都不写入kafka数据日志。
kafka实现幂等
- kafka实现幂等性十分Easy,只需要将生产者客户端参数enable.idempotence设置为true即可(这个参数的默认值为false)
问题: Kafka是如何做到发送重复消息(重试),仍然可以保证幂等性的呢?
- 为此Kafka生产者引入了producer id(以下简称PID)和序列号(sequence number)这两个概念。
- 每个kafka生产者客户端在初始化的时候都会被分配一个PID
- PID + 序列号可以代表唯一的一条消息数据,生产者每一条消息对应唯一的序列号。即使同一个消息被多次发送,该消息对应的序列号也是不会变的。
- 同时kafka broker服务端会为每一个生产者(PID)保存已经成功发送的数据批次的起始序列号(start_seq)和终止序列号(end_seq)。
- 所以当新的批次消息被发送到服务端的时候,会首先进行序列号区间比对,一旦发生重叠就意味着序号重叠的消息已经在服务端被成功写入过,就可以将重复的消息数据抛弃掉,从而避免消费端重复消费。
注意;
- 我们上面所讲的幂等性都是基于某一个分区而言的,也就是说Kafka的幂等只能保证某个主题的单个分区的幂等性。
- 所以发生重试的消息与第一次被发送的同一个消息如果被发往不同的分区,幂等性是不生效的。
- 但是这种情况通常不会出现,因为即使消息发送失败后进行重试,但是消息的key、value、topic信息本身没变化、消息分区算法没有变化、分区数量没有变化。在这些前提下,同一个消息即使被重复发送,也会发往同一个分区。
- Kafka的幂等机制只能保证某个主题的单个分区的幂等性,因为幂等性是基于分区ID实现的。每个分区都有自己的唯一标识符,而消息的幂等性检查是基于该标识符进行的。因此,如果消息在多个分区中具有相同的键,那么它们在每个分区中都将被视为不同的消息,无法实现全局的幂等性。
kafka实现事务
kafka幂等性解决的是同一个消息被发送多次,发送至同一个分区。那么如果多个不同的消息发送至不同的分区,我们该如何保证多条消息要么都发送成功(都写入kafka broker数据日志),要么就都不写入kafka数据日志?
这就需要依赖kafka事务来实现:
- kafka生产者需要设置transactional.id参数,可以认为该参数就是事务管理器的id
- kafka事务生产者开启幂等,即:enable.idempotence设置为true(如果未显式设置,则KafkaProducer默认会将它的值设置为true)。如果用户显式地将enable.idempotence设置为false,则会报出ConfigException的异常。
KafkaProducer提供了5个与事务相关的方法,详细如下:
//初始化事务
void initTransactions();
//开启事务
void beginTransaction() throws ProducerFencedException;
//为消费者提供在事务内的位移提交的操作
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets, String consumerGroupId)throws ProducerFencedException;
//提交事务
void commitTransaction() throws ProducerFencedException;
//中止事务,类比事务的回滚
void abortTransaction() throws ProducerFencedException;
事务的隔离级别
在kafka消费客户端有一个参数isolation.level,这个参数的默认值为“read_uncommitted”,意思是说消费端应用可以看到(消费到)未提交的事务,当然对于已提交的事务也是可见的。
这个参数还可以设置为“read_committed”,表示消费端应用不可以看到尚未提交的事务内的消息。
举个例子:
- 如果生产者开启事务并向某个分区值发送3条消息msg1、msg2和msg3,在执行commitTransaction()或abortTransaction()方法前,设置为“read_committed”的消费端应用是消费不到这些消息的,不过在KafkaConsumer内部会缓存这些消息,直到生产者执行commitTransaction()方法之后它才能将这些消息推送给消费端应用。
- 反之,如果生产者执行了abortTransaction()方法,那么KafkaConsumer会将这些缓存的消息丢弃。
使用演示
/**
* 生产者使用demo
*/
public class KafkaProducerTest {
private static final String TEST_TOPIC = "test1";
private Properties props;
@BeforeEach
public void prepareTest() {
props = new Properties();
//kafka broker列表
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 5000);
//可靠性确认应答参数
props.put(ProducerConfig.ACKS_CONFIG, "1");
//发送失败,重新尝试的次数
props.put(ProducerConfig.RETRIES_CONFIG, "3");
//生产者数据key序列化方式
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//序列化器的配置
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//生产者端开启幂等
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, Boolean.TRUE);
//生产者端开启事务
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "test-transaction");
}
@Test
void testTransaction() throws ExecutionException, InterruptedException {
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
//0.初始化事务管理器
producer.initTransactions();
//1.开启事务
producer.beginTransaction();
try {
//2.发送消息
producer.send(new ProducerRecord<>(TEST_TOPIC, Integer.toString(1), "test1"));
producer.send(new ProducerRecord<>(TEST_TOPIC, Integer.toString(2), "test2"));
producer.send(new ProducerRecord<>(TEST_TOPIC, Integer.toString(3), "test3"));
//3.提交事务
producer.commitTransaction();
} catch (ProducerFencedException e) {
e.printStackTrace();
//4.1 事务回滚
producer.abortTransaction();
} catch (KafkaException e) {
e.printStackTrace();
//4.2 事务回滚
producer.abortTransaction();
} finally {
producer.close();
}
}
}
消费者
重平衡
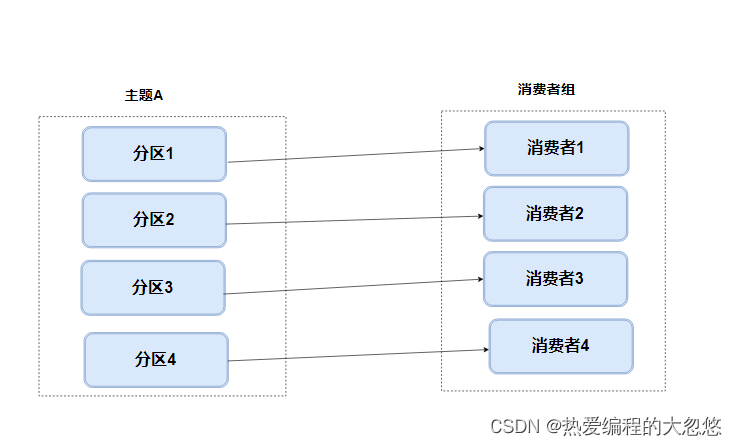
- 什么是分区重平衡呢?
- 我们知道一个主题分区由消费者组内的一个消费者进行消费。
- 所谓分区再平衡(重平衡),就是相对于第一次平衡状态而言,重新进行分区与消费者的关系建立
- 在启动消费者组所在服务的时候,就会为消费者分配它可以访问数据的主题分区,这是第一次消费者与分区之间建立关系,是第一次分区平衡
- 所谓分区再平衡,接收在数据消费进行时,由于某些外部条件发生变化,发生的消费者与分区之间重新建立关系的动作。
-
什么时候会发生分区重平衡呢?
- 消费者组消费主题的分区数量发生变化(增加分区),kafka目前只支持为某个主题增加分区
- 消费者数量增加,在原有消费者组内消费者应用程序正常运行的情况下,新启动了一个服务,该服务内包含与原有消费者groupId一致的消费者,导致消费者组内消费者增加。
- 当消费者组以正则表达式的方式订阅主题,当新建了一个主题,并且该主题名称匹配到消费者组的订阅正则表达式。也会触发分区再平衡。
- 消费某主题的消费者数量的减少。常见情况:当消费者拉取数据之后长时间无法完成数据处理(不执行下一次的数据拉取动作),kafka服务端就认为这个消费者挂掉了(即kafka服务端认为消费者组内消费者数量变少了)。
-
重平衡会产生哪些影响呢?
- Rebalance会影响消费者的处理性能,当发生Reabalance的期间,消费者失去与分区之间的连接,无法poll拉取数据,也无法提交消费偏移量。
- Rebalance的速度很慢,当你的主题分区很多,消费者组消费者数量也很多的情况下,这个过程有可能持续几十分钟。
-
如何避免重平衡的发生呢?
- 导致重平衡行为的前三点是我们的主动行为,可以避免在繁忙时,进行增减消费者,增加分区的操作
- 对于第四点,消费者组内消费者数量发生变化,如: 消费者数量减少。当消费者拉取一批数据之后长时间无法完成这批数据的处理(不提交偏移量),kafak服务端就认为这个消费者挂掉了(即消费者组内消费者数量变少了),从而会触发Rebalance,这种情况下,我们可以通过设置以下参数避免:
session.timout.ms=10000
heartbeat.interval.ms=2000
max.poll.interval.ms=配置该值大于消费者批处理消息最长耗时(默认5分钟)
max.poll.records=500(默认值是500)
- 消费者与kafka服务端维持着心跳,一旦服务端在超过
session.timout.ms设置的时间没有接收到消费者的心跳,就认为该消费者挂掉了。所以这个值可以相对大一些,比如10s。 heartbeat.interval.ms是消费者向kafka服务端发送心跳的时间间隔,这个值越小频率就越高,发生心跳失联误判的概率就越低。- 当消费者拉取一批数据,在超过
max.poll.interval.ms时间后仍然不执行下一次数据拉取poll(因为数据处理超时),kafka服务端就认为这个消费者挂掉了。所以为了避免rebalance,我们应该让单批次(拉取一个批次默认是500条)数据处理的时长小于max.poll.interval.ms配置值。 - 上文是通过增加单批次处理超时时间的方式避免rebalance,我们还可以在保持
max.poll.interval.ms不变的情况下,减少max.poll.records配置值。一个批次拉取的数据越少,进行数据处理的时间就越短,从而避免因为超时导致的rebalance问题。
-
重平衡为什么会产生消息重复消费问题呢?
- 在消费者组内消费者发生rebalance的时间内,组内所有的消费者将停止拉取数据,与服务端处于暂时失联状态。
- 可能导致的问题,举例说明:上一批次拉取了500条数据,在这些数据没处理完成之前发生了rebalance,该批次消费偏移量也就无法提交。当rebalance完成之后,消费者再消费这个分区的时候,按照服务端记录的消费偏移量,拉下来的数据还是原来的那500条,导致重复消费的问题。
-
如何解决由重平衡导致的消息重复消费问题呢?
- 我们期望能有一种方式在rebalance之前完成偏移量的提交。通过实现ConsumerRebalanceListener接口可以满足这个需求,在监听到某个主题的分区发生再均衡事件时,进行该消费者的偏移量的提交,具体示例:
public class ConsumerBalance {
private static KafkaConsumer<String, String> consumer;
/**
* 存储一个主题多个分区的当前消费偏移量
*/
private static Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
/**
* 初始化消费者
*/
static {
Properties configs = initConfig();
consumer = new KafkaConsumer<>(configs);
//主题订阅
consumer.subscribe(Collections.singletonList("test1"), new RebalanceListener(consumer));
}
/**
* 初始化配置
*/
private static Properties initConfig() {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "dhy-group");
props.put("enable.auto.commit", true);
props.put("auto.commit.interval.ms", 1000);
props.put("session.timeout.ms", 30000);
props.put("max.poll.records", 1000);
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
return props;
}
public static void main(String[] args) {
while (true) {
// 这里的参数指的是轮询的时间间隔,也就是多长时间去拉一次数据
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(3000));
records.forEach((ConsumerRecord<String, String> record) -> {
System.out.println("topic:" + record.topic()
+ ",partition:" + record.partition()
+ ",offset:" + record.offset()
+ ",key:" + record.key()
+ ",value" + record.value());
// 每次消费记录消费偏移量,用于一旦发生rebalance时提交
currentOffsets.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1, "no matadata"));
});
consumer.commitAsync();
}
}
static class RebalanceListener implements ConsumerRebalanceListener {
KafkaConsumer<String, String> consumer;
public RebalanceListener(KafkaConsumer<String,String> consumer) {
this.consumer = consumer;
}
/**
* 在rebalance发生之前和消费者停止读取消息之后被调用
*/
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
consumer.commitSync(currentOffsets);
}
/**
* 在rebalance完成之后(重新分配了消费者对应的分区),消费者开始读取消息之前被调用。
*/
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
consumer.commitSync(currentOffsets);
}
}
}
消费者组与线程池的正确实践
- 错误示例一: 多线程使用一个消费者
- 创建多个线程用来消费kafka数据
- 多线程使用同一个KafkaConsumer对象
- 在单线程中使用这个KafkaConsumer对象,完成数据拉取、处理、提交偏移量。
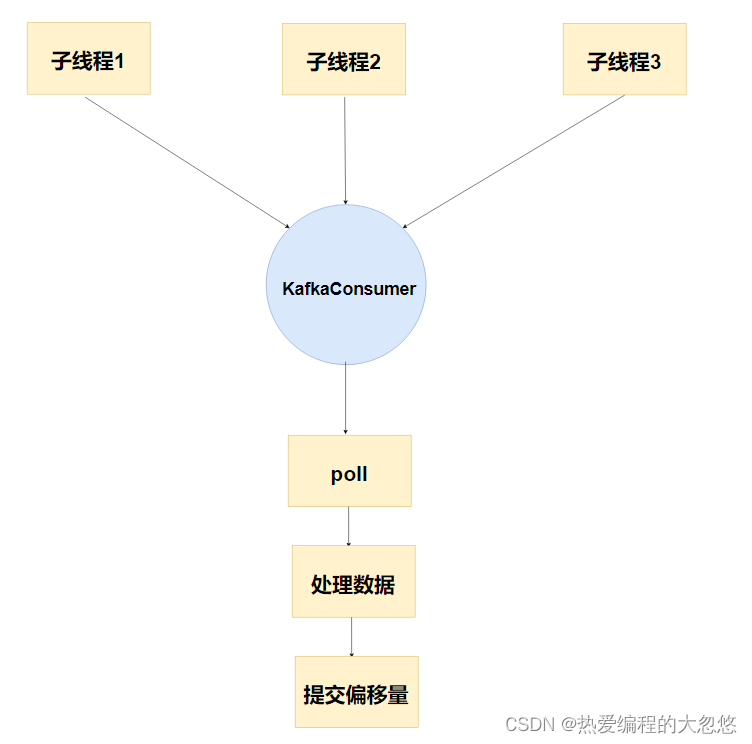
错误原因:
KafkaConsumer是线程不安全的,因为它的设计中包含了非线性的状态,而且在多线程情况下可能导致意外的结果。具体来说,以下是一些可能产生线程安全问题的因素:
调用poll()方法时,KafkaConsumer会有许多内部状态的变化,如当前分区、消费位移等。这些内部状态被多个线程共享时,就会存在竞争条件,导致消费位移错误或者消息被重复消费。
KafkaConsumer会自动提交消费位移,如果多个线程同时调用commitSync()或commitAsync()方法,就会发生竞争条件,导致消费位移提交出现错误。
KafkaConsumer在处理消息时,需要使用缓存(例如offsetsForTimes缓存)以提高效率。如果多个线程同时修改缓存,就会导致数据不一致,甚至出现NullPointerException等异常。
- 错误示例二: 拉取消息然后交给线程池分批处理
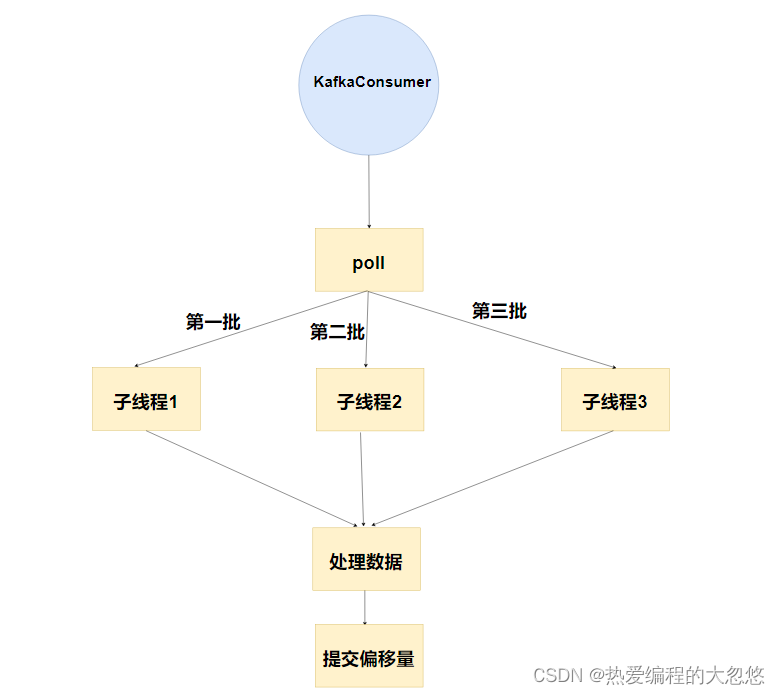
不推荐使用原因:
- 这个处理方式不是错误,但是他只是一个消费者在消费kafka消息队列中的数据,不是消费者组的方式消费数据。无法充分利用kafka分区提升消息处理的吞吐量。
- 正确做法:使用线程池实现消费者组
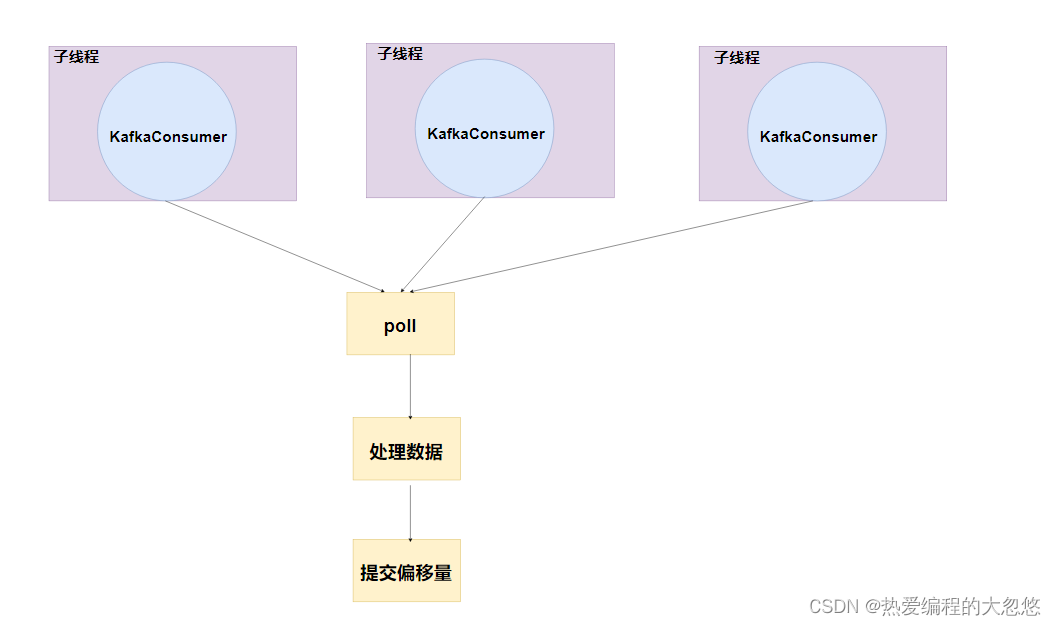
- 因为KafkaConsumer是线程不安全的,所以不能跨线程使用KafkaConsumer
- 每个线程持有一个KafkaConsumer对象
- 多个线程的实现可以使用线程池,线程池的线程数量等于消费者组内消费者的数量
class ConsumerGroupThreadPoolTest {
@Test
void test(){
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 3; i++) {
executorService.execute(new MyConsumer());
}
}
}
- MyConsumer在run方法中调用KafkaConsumer相关拉取消费数据方法
class MyConsumer implements Runnable {
private static final String TEST_TOPIC = "test1";
private final KafkaConsumer<String, String> consumer;
public MyConsumer() {
Properties props = new Properties();
//kafka集群信息
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
//消费者组名称
props.put(ConsumerConfig.GROUP_ID_CONFIG, "dhy_group");
//key的反序列化器
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//value的反序列化器
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//初始化消费者
consumer = new KafkaConsumer<>(props);
}
@Override
public void run() {
consumeTemplate(MyConsumer::printRecord, null);
}
/**
* recordConsumer针对单条数据进行处理,此方法中应该做好异常处理,避免外围的while循环因为异常中断。
*/
public void consumeTemplate(Consumer<ConsumerRecord<String, String>> recordConsumer, Consumer<KafkaConsumer<String, String>> afterCurrentBatchHandle) {
consumer.subscribe(Collections.singletonList(TEST_TOPIC));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(100));
for (ConsumerRecord<String, String> record : records) {
recordConsumer.accept(record);
}
if (afterCurrentBatchHandle != null) {
afterCurrentBatchHandle.accept(consumer);
}
}
} finally {
consumer.close();
}
}
private static void printRecord(ConsumerRecord<String, String> record) {
System.out.println("topic:" + record.topic()
+ ",partition:" + record.partition()
+ ",offset:" + record.offset()
+ ",key:" + record.key()
+ ",value" + record.value());
record.headers().forEach(System.out::println);
}
}
拦截器
- Consumer消费者端拦截器接口
public interface ConsumerInterceptor<K, V> extends Configurable, AutoCloseable {
/**
* 发生的时机:在返回给客户端之前,也就是poll() 方法返回之前
* 这个方法允许你修改records(记录集合),然后信息的记录集合被返回
* 没有返回记录条数上的限制,你可以在这里可以可以过滤或者是生成新的记录
*/
public ConsumerRecords<K, V> onConsume(ConsumerRecords<K, V> records);
//当offset 被提交之后调用
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets);
//当拦截器关闭的时候被调用
public void close();
}
- 消费者端拦截器应用场景: 客户端监控、端到端系统性能检测、消息审计等场景
- 使用案例: 实现计算一个批次数据发送到接受的平均延时。
- 一个批次数据发送时间会保存在ConsumerRecords的timestamp的时间戳,是在生产者构建消息的时候添加的。
- 一个批次数据接收到的时间可以认为是当前时间System.currentTimeMillis()
- 我们把接收到的批次延时保存到totalLatency,结束到的消息批次数量保存到msgCountLong,二者相除就得到“批次消息”从生产者发送到消费者接收的平均延时。
package interceptor;
import org.apache.kafka.clients.consumer.ConsumerInterceptor;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import java.util.Map;
import java.util.concurrent.atomic.AtomicLong;
public class LatencyCalConsumerInterceptor implements ConsumerInterceptor<String, String> {
/**
* 数据处理总耗时
*/
private static final AtomicLong totalLatency = new AtomicLong();
/**
* 消息的总数量
*/
private static final AtomicLong msgCount = new AtomicLong();
/**
* 在消费者进行数据处理之前被调用
*/
@Override
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {
long lantency = 0L;
//累加每条消息处理耗时
for (ConsumerRecord<String, String> msg : records) {
lantency += (System.currentTimeMillis() - msg.timestamp());
}
//获取当前消息发送处理的总耗时
long totalLatencyLong = totalLatency.addAndGet(lantency);
//获取消息总数
long msgCountLong = msgCount.incrementAndGet();
System.out.println("该批次消息发出到消费处理的平均延时:" + (totalLatencyLong / msgCountLong));
return records;
}
@Override
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
- 应用自定义拦截器
props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, LatencyCalConsumerInterceptor.class.getName());
反序列化器
- 序列化过程: kafka生产者将Peo对象序列化为JSON格式,再讲JSON格式转成byte[]字节流用于网络传输
- 反序列化过程: kafka消费者得到byte[]字节流数组,反序列化为JSON,进而通过JSON得到Peo对象
消费者反序列化接口:
public interface Deserializer<T> extends Closeable {
/**
* 参数configs会传入消费者配置参数,
* 反序列化器实现类可以根据消费者参数配置影响序列化逻辑
* isKey布尔型,表示当前反序列化的对象是不是消息的key,如果不是key就是value
*/
default void configure(Map<String, ?> configs, boolean isKey) {
}
//核心反序列化函数,将二进制数组转成T类对象
T deserialize(String topic, byte[] var2);
default T deserialize(String topic, Headers headers, byte[] data) {
return this.deserialize(topic, data);
}
default void close() {
}
}
- 举例: 使用JackSon反序列化对象
/**
* 反序列化器
*/
public class JacksonDeserializer implements Deserializer<Peo> {
private static final ObjectMapper objectMapper = new ObjectMapper();
@Override
public Peo deserialize(String topic, byte[] data) {
try {
return objectMapper.readValue(data,Peo.class);
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
}
- 应用反序列化器
//value的反序列化器
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JacksonDeserializer.class.getName());
- 测试
@Test
void testDeserializer(){
//1.创建消费者
KafkaConsumer<String, Peo> consumer = new KafkaConsumer<>(props);
//2.订阅Topic
consumer.subscribe(Collections.singletonList(TEST_TOPIC));
try {
while (true) {
//循环拉取数据,
//Duration超时时间,如果有数据可消费,立即返回数据
// 如果没有数据可消费,超过Duration超时时间也会返回,但是返回结果数据量为0
ConsumerRecords<String, Peo> records = consumer.poll(Duration.ofSeconds(100));
for (ConsumerRecord<String, Peo> record : records) {
System.out.println(record.value());
}
}
} finally {
//退出应用程序前使用close方法关闭消费者,
// 网络连接和socket也会随之关闭,并立即触发一次再均衡(再均衡概念后续章节介绍)
consumer.close();
}
}
整合SpringBoot
快速入门
- SpringBoot与Kafka对应版本: 详情查看官网链接
- 引入依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
- 参数配置
spring:
kafka:
bootstrap-servers: localhost:9092
producer: # 生产者
retries: 3 #发送失败重试次数
acks: all #所有分区副本确认后,才算消息发送成功
# 指定消息key和消息体的序列化编码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
consumer: #消费者
# 指定消息key和消息体的反序列化解码方式,与生产者序列化方式一一对应
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
# 该参数作用见下文注释
properties:
spring:
json:
trusted:
packages: '*'
注意:
生产者的序列化器和消费者的反序列化器是成对出现的,也就是说生产者序列化value采用JSON的方式,消费者反序列化的时候也应该采用JSON的方式
spring.kafka.consumer.properties.spring.json.trusted.packages是一个Kafka 消费者属性,用于指定 Spring Kafka 应该信任哪些 Java 包来反序列化 JSON 消息。在 Kafka 中,消息通常是序列化的,而 Spring Kafka 默认使用 JSON 序列化器/反序列化器来处理 JSON格式的消息。然而,为了防止反序列化漏洞,Spring Kafka 默认只信任一些基本的 Java 类型,例如
java.lang包下的类。如果你的 JSON 消息包含其他类型的对象,例如自定义的 POJO 类,那么 Spring Kafka 将会拒绝反序列化这些消息。为了解决这个问题,你可以使用
spring.kafka.consumer.properties.spring.json.trusted.packages属性来指定
Spring Kafka 应该信任哪些 Java 包。你可以将你的自定义类所在的包添加到这个属性中,以便 Spring Kafka在反序列化 JSON 消息时可以正确地处理你的自定义类。例如:
spring.kafka.consumer.properties.spring.json.trusted.packages=com.example.myapp.pojo
- 这将会告诉 Spring Kafka 在反序列化 JSON 消息时信任
com.example.myapp.pojo包下的类。- 注意,这个属性只对使用 JSON 序列化器/反序列化器的情况下生效。如果你使用其他类型的序列化器/反序列化器,那么这个属性将不起作用。
- 如果想自定义日志级别,使用下面的配置。
logging:
level:
org:
springframework:
kafka: ERROR # spring-kafka
apache:
kafka: ERROR # kafka
生产者环境搭建:
- 目标对象
@Data
public class User {
private String name;
private Integer age;
}
- 生产者测试用例
@SpringBootTest(classes = KafkaSpringBootDemo.class)
class SpringKafkaTest {
@Resource
KafkaTemplate<String, User> kafkaTemplate;
@Test
void testProducer() {
User user = new User();
user.setAge(21);
user.setName("大忽悠");
kafkaTemplate.send(TEST_KAFKA_TOPIC, user);
//阻塞等待观察结果
System.in.read();
}
}
注意:
- KafkaTemplate是Spring针对kafka生产者封装的模板操作类,可以使用泛型,上文中的
<String,User>表示发送的数据消息的key的数据类型是String,数据体value的数据类型是User。- 因为配置了
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer,所以User对象会被序列化为JSON对象之后发往kafka服务端。- 需要注意的是:在进行数据发送之前我并没有在服务端新建一个主题“test3”,但是数据却发送成功了。这是因为,默认情况下当生产者发送数据的主题不存在的时候,会新建一个主题(该主题只有一个分区)。
消费者环境搭建:
@Component
@Slf4j
public class KafkaConsumer {
@KafkaListener(topics = TEST_KAFKA_TOPIC , groupId = TEST_CONSUMER_GROUP)
public void dealUser(User user) {
log.info("kafka consumer msg: {}",user);
}
}
注意:
- 核心注解是KafkaListener,topics指定了消费哪个主题的数据,gourpId指定了消费者组的名称
- 这里使用User作为方法参数,是因为kafka消费者会调用反序列化器
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer将生产者发送的User对象反序列化。- 注意这里的消费者组只有一个消费者,如果希望启动多个消费者线程,可以设置
@KafkaListener(concurrency=n)。(用法:消费者线程数=主题分区数)
运行生产者测试用例,查看输出:
如果测试过程中出现下面这个错误:
Caused by: java.lang.IllegalArgumentException: The class 'springboot.pojo.User' is not in the trusted packages
- 因为springboot.pojo这个包路径在消费者这一端不被信任。
- 如果需要被信任,需要配置spring.kafka.consumer.properties.spring.json.trusted.packages: springboot.pojo;
- 如果配置成’*'表示所有的路径都将被信任。
生产者
KafkaTemplate的send方法所支持参数列表如下:
- topic:Topic主题的的名称
- partition:主题的分区编号,编号从0开始。表示消息数据指定发送到该分区中
- timestamp:时间戳,一般默认当前时间戳
- key:消息的键,可以是不同数据类型,但是通常是String。具有相同key的消息被发往同一个分区,也就是说具有相同key的消息可以保证数据有序性。
- data:消息的数据,可以是不同数据类型
- ProducerRecord:消息对应的封装类,包含上述字段,较少使用
- Message:Spring自带的Message封装类,包含消息及消息头,较少使用
异步发送
send方法默认为异步,即发送之后就不再等待服务端对该消息的确认,如果出现异常生产者客户端不会有任何的感知。
为了能够使生产者能够感知到消息是否真的发送成功了,有两种方式:
- 同步发送
- 异步发送 + 回调函数
添加回调函数写法如下:
@Test
void testAsyncWithCallBack() throws IOException {
User user = new User();
user.setAge(21);
user.setName("大忽悠");
kafkaTemplate.send(TEST_KAFKA_TOPIC, user).addCallback(new ListenableFutureCallback<SendResult<String, User>>() {
@Override
public void onFailure(Throwable ex) {
log.error("msg send err: ",ex);
}
@Override
public void onSuccess(SendResult<String, User> result) {
// 消息发送到的topic
String topic = result.getRecordMetadata().topic();
// 消息发送到的分区
int partition = result.getRecordMetadata().partition();
// 消息在分区内的offset
long offset = result.getRecordMetadata().offset();
log.info("msg send success,topic: {},partition: {},offset: {}",topic,partition,offset);
}
});
System.in.read();
}

同步发送
默认情况下send()方法就是异步调用的方法,如果想实现同步阻塞的方法,需要在send方法的基础上调用get()方法。
get()无参方法有一个重载方法get(long timeout, TimeUnit unit),当超过一定的时长服务端仍无消息写入成功确认,则抛出TimeoutException异常。
@Test
void testSync() throws IOException {
User user = new User();
user.setAge(21);
user.setName("大忽悠");
try {
SendResult<String, User> result = kafkaTemplate.send(TEST_KAFKA_TOPIC, user).get();
// 消息发送到的topic
String topic = result.getRecordMetadata().topic();
// 消息发送到的分区
int partition = result.getRecordMetadata().partition();
// 消息在分区内的offset
long offset = result.getRecordMetadata().offset();
log.info("msg send success,topic: {},partition: {},offset: {}",topic,partition,offset);
} catch (InterruptedException | ExecutionException e) {
log.error("send msg sync occurs err: ",e);
}
System.in.read();
}

拦截器和分区器配置
注意拦截器和分区器在Spring看来属于不常用的配置属性,对于不常用的原生配置属性,spring全都放在properties下面进行配置。也就是说原生API中,通过Properties传递给生产者的属性,在这里全部都支持。
spring:
kafka:
producer:
properties:
interceptor.classes: springboot.producer.interceptor.RequestStatCalInterceptor
partitioner.class: springboot.producer.partitioner.ValuePartitioner
注意:
- 注意一个是classes、一个是class,分区器只能配置一个,拦截器可以配置多个。
事务
幂等性的设置仍然很简单,只需要将生产者客户端参数enable.idempotence设置为true即可。
spring:
kafka:
producer:
properties:
enable.idempotence: true
kakfa的事务处理和spring结合后,有两种使用方式,分别为手动挡(模板方法)和自动挡(注解),这里以订单支付场景为例:
- 用户订单支付,向kafka发送数据,为用户增加积分
- 然后把用户的订单支付结果存入数据库
- 如果订单支付失败,抛出异常,但是kafka消息已经发送出去了,此时我们希望订单支付成功和用户积分增加成功,要么都成功,要么都失败
介绍完kafak事务的应用场景后,下面来演示一下事务的手动挡使用方式:
@Test
void testTransaction() {
User user = new User();
user.setAge(21);
user.setName("大忽悠");
//调用事务模板方法
kafkaTemplate.executeInTransaction(operations -> {
operations.send(TEST_KAFKA_TOPIC, user);
//业务处理发生异常,事务回滚
throw new RuntimeException("fail");
});
}
自动挡的方式就是使用@Transactional注解,同时需要针对kafka做额外的配置管理,但是不推荐使用这种方式,因为容易与数据库事务混淆。
消费者
使用@KafkaListener注解标注某个消费者,该注解中有若干属性,作用分别为:
public @interface KafkaListener {
/**
* 消费者的id,如果没有配置或默认生成一个。如果配置了会覆盖groupId,笔者的经验这个配置不需要配
*/
String id() default "";
/**
* 配置一个bean,类型为:org.springframework.kafka.config.KafkaListenerContainerFactory
*/
String containerFactory() default "";
/**
* 三选一:该消费者组监听的Topic名称
*/
String[] topics() default {
};
/**
* 三选一:通过为消费者组指定表达式匹配监听多个Topic(笔者从来没用过,也不建议使用)
*/
String topicPattern() default "";
/**
* 三选一:消费组指定监听Topic的若干分区。
*/
TopicPartition[] topicPartitions() default {
};
/**
* 没用过,不知道作用
*/
String containerGroup() default "";
/**
* Listener的异常处理器,后续会介绍
* @since 1.3
*/
String errorHandler() default "";
/**
* 消费者组的分组id
* @since 1.3
*/
String groupId() default "";
/**
* 设否设置id属性为消费组组id
* @since 1.3
*/
boolean idIsGroup() default true;
/**
* 消费者组所在客户端的客户端id的前缀,用于kafka客户端分类
* @since 2.1.1
*/
String clientIdPrefix() default "";
/**
* 用于SpEL表达式,获取当前Listener的配置信息
* 如获取监听Topic列表的SpEL表达式为 : "#{__listener.topicList}"
* @return the pseudo bean name.
* @since 2.1.2
*/
String beanRef() default "__listener";
/**
* 当前消费者组启动多少了消费者线程,并行执行消费动作
* @since 2.2
*/
String concurrency() default "";
/**
* 是否自动启动,true or false
* @since 2.2
*/
String autoStartup() default "";
/**
* Kafka consumer 属性配置,支持所有的apache kafka 消费者属性配置
* 但不包括group.id 和 client.id 配置属性
* @since 2.2.4
*/
String[] properties() default {
};
/**
* 笔者从来没用过,自己理解下面的这段英文吧
* When false and the return type is an {@link Iterable} return the result as the
* value of a single reply record instead of individual records for each element.
* Default true. Ignored if the reply is of type {@code Iterable<Message<?>>}.
* @return false to create a single reply record.
* @since 2.3.5
*/
boolean splitIterables() default true;
/**
* 笔者从来没用过,自己理解下面的这段英文吧
* Set the bean name of a
* {@link org.springframework.messaging.converter.SmartMessageConverter} (such as the
* {@link org.springframework.messaging.converter.CompositeMessageConverter}) to use
* in conjunction with the
* {@link org.springframework.messaging.MessageHeaders#CONTENT_TYPE} header to perform
* the conversion to the required type. If a SpEL expression is provided
* ({@code #{...}}), the expression can either evaluate to a
* {@link org.springframework.messaging.converter.SmartMessageConverter} instance or a
* bean name.
* @return the bean name.
* @since 2.7.1
*/
String contentTypeConverter() default "";
}
最佳实践
把消费者监听的主题,消费者组名称,消费者组中消费者数量等常用信息做成自定义配置(而不是在代码中写死),如下所示:
dhyconsumer:
topic: topic1,topic2
group-id: dhy-group
concurrency: 5
注解属性支持使用SPEL表达式,所以我们可以读取配置作为属性值:
@KafkaListener(topics = "#{'${dhyconsumer.topic}'.split(',')}",
groupId = "${dhyconsumer.group-id}",
concurrency="${dhyconsumer.concurrency}")
public void readMsg(ConsumerRecord consumerRecord) {
//监听到数据之后,进行处理操作
}
指定消费位置
在某些特殊场景下,希望消费Topic主题中的某几个分区(不是全部分区消费)。或者是针对某个分区从指定的偏移量开始消费。
@KafkaListener(topicPartitions =
{
@TopicPartition(topic = "topic1", partitions = {
"0", "1" }),
@TopicPartition(topic = "topic2", partitions = {
"0","4"},partitionOffsets = @PartitionOffset(partition = "0", initialOffset = "300"))
})
public void readMsg(ConsumerRecord<?, ?> record) {
}
上面例子中消费者监听topic1的0,1分区(可能包含不只2个分区);监听topic2的第0和4分区 ,并且第0分区从offset为300的开始消费;
监听器工厂
@Configuration
public class KafkaInitialConfiguration {
/**
* 监听器工厂
*/
@Autowired
private ConsumerFactory<String,String> consumerFactory;
/**
* @return 配置一个消息过滤策略
*/
@Bean
public ConcurrentKafkaListenerContainerFactory<String,String> myFilterContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String,String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
// 被过滤的消息将被丢弃
factory.setAckDiscarded(true);
//设置消息过滤策略
factory.setRecordFilterStrategy(new RecordFilterStrategy() {
@Override
public boolean filter(ConsumerRecord consumerRecord) {
//这里做逻辑判断
//返回true的消息将会被丢弃
return true;
}
});
return factory;
}
}
使用方法,myFilterContainerFactory是上文中bean方法的名称:
@KafkaListener(containerFactory ="myFilterContainerFactory")
注意:
- ConsumerFactory用于创建消费者实例。它的作用是为了简化消费者的创建过程,尤其是在使用自定义配置时,可以为消费者提供更多的灵活性。
- ConcurrentKafkaListenerContainerFactory是Spring Kafka提供的一个工厂类,用于创建并配置Kafka消息监听器容器,它可以创建多个并发的监听器容器,从而实现多线程处理Kafka消息的能力。
注意:
ConcurrentMessageListenerContainer是Spring框架中的一个组件,它的作用是在消息队列中监听并发处理消息。它可以在多个线程中同时处理消息,从而提高消息处理的效率。
具体来说,ConcurrentMessageListenerContainer可以配置多个MessageListener实例,并将它们分配到不同的线程中处理消息。这样可以避免消息处理的瓶颈,提高系统的吞吐量。同时,ConcurrentMessageListenerContainer还支持消息的批量处理,可以在一次调用中处理多个消息,进一步提高处理效率。
除此之外,ConcurrentMessageListenerContainer还提供了一些其他的功能,比如:
- 支持动态调整并发消费者数量,可以根据消息队列的负载情况自动调整并发消费者的数量。
- 支持消息的事务处理,可以保证消息的原子性和一致性。
- 支持消息的重试和死信处理,可以处理因为各种原因导致消息处理失败的情况。
总之,ConcurrentMessageListenerContainer是一个非常实用的组件,可以帮助我们更加高效地处理消息队列中的消息。
注意:
KafkaMessageListenerContainer是一个Spring Kafka库中的组件,它的作用是作为Kafka消息监听器的容器,可以自动管理Kafka消费者的生命周期,并提供了一些方便的配置选项和处理逻辑。
具体来说,KafkaMessageListenerContainer可以通过订阅一个或多个Kafka主题来监听Kafka消息,并在消息到达时自动调用注册的消息监听器进行处理。它还支持一些高级特性,例如:
- 手动提交偏移量,以确保消息被完全处理后才提交偏移量。
- 支持批量处理消息,以提高处理效率。
- 提供了一些错误处理机制,例如重试和错误记录。
总之,KafkaMessageListenerContainer可以大大简化Kafka消息处理的开发工作,并提供了一些高级特性以提高消息处理的可靠性和效率。
其他属性配置
除了上面提到的一些配置属性,实际上apache kafka consumer支持的原生配置属性,要比Spring 提供的配置属性多得多。所有的apache kafka原生配置属性都可以通过properties配置来传递:
@KafkaListener(properties = {
"enable.auto.commit:false","max.poll.interval.ms:6000" })
消息头获取
我们可以通过注解方式获取消息头:
- @Payload:获取的是消息的消息体,也就是发送的数据内容
- @Header(KafkaHeaders.RECEIVED_MESSAGE_KEY):获取发送消息的key
- @Header(KafkaHeaders.RECEIVED_PARTITION_ID):获取当前消息是从哪个分区中监听到的
- @Header(KafkaHeaders.RECEIVED_TOPIC):获取监听的TopicName
- @Header(KafkaHeaders.RECEIVED_TIMESTAMP):获取到数据时间的时间戳
@KafkaListener(topics = "topic1")
public void readMsg(@Payload String data,
@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) Integer key,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(KafkaHeaders.RECEIVED_TIMESTAMP) long ts) {
}
消息转发
Spring-Kafka只需要通过一个@SendTo注解即可以实现消息的转发,被注解方法的return值即转发的消息内容:
@Component
public class KafkaConsumer {
@KafkaListener(topics = {
"topic2"})
@SendTo("topic1")
public String listen1(String data) {
System.out.println("业务A收到消息:" + data);
return data + "(已处理)";
}
@KafkaListener(topics = {
"topic1"})
public void listen2(String data) {
System.out.println("业务B收到消息:" + data);
}
}
手动提交和自动提交偏移量
Spring Kafka监听器模式(spring.kafka.listener.type配置属性)有两种:
- single: 监听器消息参数是一个对象
- batch: 监听器消息参数是一个集合
监听器消息参数为单个对象
@KafkaListener(topics = TEST_KAFKA_TOPIC , groupId = TEST_CONSUMER_GROUP)
public void dealUser(User user) {
log.info("kafka consumer msg: {}",user);
}
- 定时自动提交消费偏移量
# 开启自动提交消费offset(这个配置实际上专指按照周期自动提交)
spring.kafka.consumer.enable-auto-commit: true
# 进行自动提交操作的时间间隔
spring.kafka.consumer.auto-commit-interval: 10s
- 每处理完成一条消息数据,就自动提交消费者偏移量。这种方式是避免数据重复消费最可靠的方式,但是也是执行效率最低的方式。
# 禁用按周期自动提交消费者offset
spring.kafka.consumer.enable-auto-commit: false
# offset提交模式为record
spring.kafka.listener.ack-mode: record
注意: ack-mode一共有下面的几种配置模式
| ack-mode模式 | 说明 |
|---|---|
| RECORD | 每条记录提交一次偏移量 |
| BATCH(默认) | 每一次poll()下来的一个批次的数据处理完成之后提交偏移量 |
| TIME | 一批poll()下来的数据,处理时间超过spring.kafka.listener.ack-time就提交一次偏移量 |
| COUNT | 一批poll()下来的数据大于等于spring.kafka.listener.ack-count设置时就提交一次偏移量 |
| COUNT_TIME | 超时或超数量 TIME或COUNT ,有一个条件满足时提交偏移量 |
| MANUAL手动提交 | 手动调用Acknowledgment.acknowledge()进行消费offset提交,但是在一个批次数据处理完成之后才能提交。 |
| MANUAL_IMMEDIATE | 手动调用Acknowledgment.acknowledge()后立即提交偏移量,即使可能此时只处理了一个批次数据中的一条或几条数据,也要提交偏移量。 |
- 手动提交消费偏移量
# 禁用自动提交消费offset
spring.kafka.consumer.enable-auto-commit: false
# offset提交模式为manual_immediate
spring.kafka.listener.ack-mode: manual_immediate 或 manual
@KafkaListener(topics = TEST_KAFKA_TOPIC, groupId = TEST_CONSUMER_GROUP)
public void dealUser(User user, Acknowledgment ack) {
log.info("kafka consumer msg: {}", user);
ack.acknowledge();
}
注意:
- 如果此时
ack-mode=manual,我们看到dealUser方法是一条数据一条数据的接收参数,此时处理完成一条数据,然后调用ack.acknowledge();不意味着消费者偏移量会立即提交,而是“我要提交”,真正的提交时机是一个批次的消息都处理完成之后才会提交。- 如果此时
ack-mode=manual_immediate, 就意味着处理一条消息,立即提交一次消费者偏移量。
监听器消息参数为集合
监听器函数参数是List集合类型,需要设置spring.kafka.listener.type: batch,不是默认的:
@KafkaListener(topics = TEST_KAFKA_TOPIC, groupId = TEST_CONSUMER_GROUP)
public void dealUser(List<User> user) {
}
注意:
- 需要对消息数据进行批处理的情况下可以使用这种模式,比如直接将List集合数据入库.
- 按批次自动提交消费偏移量
# listener类型为批量batch类型(默认为single单条消费模式)
spring.kafka.listener.type: batch
# offset提交模式为batch(不可使用record - 启动报错)
spring.kafka.listener.ack-mode: batch
# 禁用自动按周期提交消费者offset
spring.kafka.consumer.enable-auto-commit: false
注意:
- 一个批次处理过程对应监听函数的一次调用,也就是说监听函数处理完当前批次数据后,自动提交本批次的消费偏移量
- 这种方式执行效率最高,但是一旦数据处理过程中发生异常,偏移量没有被提交。下一次消费者消费该分区,拉取下来的还是这500条数据,容易重复消费。
- 按批次手动提交offset
# listener类型为批量batch类型(默认为single单条消费模式)
spring.kafka.listener.type: batch
# offset提交模式为manual(不可使用record - 启动报错)
spring.kafka.listener.ack-mode: manual_immediate 或 manual
# 禁用自动按周期提交消费者offset
spring.kafka.consumer.enable-auto-commit: false
@KafkaListener(topics = TEST_KAFKA_TOPIC, groupId = TEST_CONSUMER_GROUP)
public void dealUser(List<User> user,Acknowledgment ack) {
user.forEach(System.out::println);
ack.acknowledge();
}
消费异常处理
序列化异常处理
毒丸消息(应用场景之一)
毒丸消息是一种特殊的消息,通常用于告诉消费者停止消费并退出队列。这种消息通常具有特殊的标识符,以便消费者可以轻松地识别它们并采取相应的行动。一旦消费者收到毒丸消息,它应该立即停止消费并退出队列。
使用毒丸消息的原因通常是因为在某些情况下,消费者可能无法正常处理队列中的消息,例如由于错误或异常。在这种情况下,毒丸消息可以用来告诉消费者停止消费并退出队列,以避免进一步的错误或问题。
如果你正在使用消息队列,那么我建议你考虑在设计时考虑毒丸消息的使用。确保你的消费者能够识别和正确处理毒丸消息,并在必要时能够停止消费并退出队列。此外,你还应该考虑如何处理毒丸消息之后的消息,以便你的应用程序可以继续正常工作。
-
什么情况下可能会造成毒丸(Poison Pill)问题呢?
- 主题A之前对应的数据结构一直是User对象(JSON序列化),某天由于程序修改错误,一不小心向该主题发送了若干条字符串消息
- 这些字符串消息无法被反序列化,出现毒丸(Poison Pill)现象,Consumer会卡在“反序列化失败-重试-反序列化失败”的死循环中,无法再处理后续消息。
-
如何处理毒丸问题呢?
- 使用ErrorHandlingDeserializer处理反序列化失败,在application.yaml 中配置ErrorHandlingDeserializer反序列化器。
spring:
kafka:
consumer:
auto-offset-reset: earliest
key-deserializer: org.springframework.kafka.support.serializer.ErrorHandlingDeserializer
value-deserializer: org.springframework.kafka.support.serializer.ErrorHandlingDeserializer
properties:
spring.json.trusted.packages: '*'
spring.deserializer.key.delegate.class: org.apache.kafka.common.serialization.StringDeserializer
spring.deserializer.value.delegate.class: org.springframework.kafka.support.serializer.JsonDeserializer
将Consumer的key-deserializer 和 value-deserializer 都配置为 org.springframework.kafka.support.serializer.ErrorHandlingDeserializer
并委任具体的Key和Value反序列化器:
spring.deserializer.key.delegate.class: org.apache.kafka.common.serialization.StringDeserializerspring.deserializer.value.delegate.class: org.springframework.kafka.support.serializer.JsonDeserializer
注意:
auto-offset-reset是一个Kafka消费者配置属性,它用于指定消费者在何时重置消费的偏移量(offset)。当一个消费者订阅一个Kafka主题时,它需要知道从哪个偏移量开始消费消息。如果消费者已经消费了一些消息,那么它需要知道下一次应该从哪个偏移量开始消费。
auto-offset-reset属性用于指定当消费者没有存储任何偏移量或存储的偏移量无效时应该如何处理。它有三个可选值:
earliest:从最早的可用偏移量开始消费。这意味着消费者将从主题的最早消息开始消费,无论消费者之前是否已经消费了一些消息。
latest:从最新的可用偏移量开始消费。这意味着消费者将从主题的最新消息开始消费,无论消费者之前是否已经消费了一些消息。
none:如果消费者没有存储任何偏移量,则抛出异常。这意味着消费者必须在启动时指定偏移量,否则将无法消费消息。
auto-offset-reset属性的作用是确保消费者始终能够消费到主题中的消息,即使它之前没有消费过或者存储的偏移量无效
默认情况下,auto-offset-reset的值为latest,这意味着消费者将从最新的可用消息开始消费。如果您想要从最早的可用消息开始消费,则可以将auto-offset-reset设置为earliest。这个选项非常重要,因为它可以确保消费者不会错过任何消息,从而保证数据的完整性和准确性。
在Key或Value反序列化失败时,先有delegate代理配置的反序列化器进行反序列化。
如果反序列化失败,ErrorHandlingDeserializer 可以确保毒丸(Poison Pill)消息被处理掉并记录日志,Consumer offeset可以向前移动,使得Consumer可以继续处理后续的消息。
ErrorHandlingDeserializer的反序列化源码如下:
@Override
public T deserialize(String topic, byte[] data) {
try {
return this.delegate.deserialize(topic, data);
}
catch (Exception e) {
return recoverFromSupplier(topic, null, data, e);
}
}
private T recoverFromSupplier(String topic, Headers headers, byte[] data, Exception exception) {
//如果我们指定了反序列失败的处理函数,这里会回调,否则返回null
if (this.failedDeserializationFunction != null) {
FailedDeserializationInfo failedDeserializationInfo =
new FailedDeserializationInfo(topic, headers, data, this.isForKey, exception);
return this.failedDeserializationFunction.apply(failedDeserializationInfo);
}
else {
return null;
}
}
- 配置key和value反序列化失败的配置参数,值为对应回调处理器的全类名
/**
* Supplier for a T when deserialization fails.
*/
public static final String KEY_FUNCTION = "spring.deserializer.key.function";
/**
* Supplier for a T when deserialization fails.
*/
public static final String VALUE_FUNCTION = "spring.deserializer.value.function";
消费异常处理
除了再反序列化过程中出现异常,还有可能我们的消费者程序处理数据过程中出现异常,同样有全局的异常处理机制可以使用。实现KafkaListenerErrorHandler接口对监听器出现的异常进行处理。
@Component
public class MyErrorHandler implements KafkaListenerErrorHandler {
@Override
public Object handleError(Message<?> message, ListenerExecutionFailedException exception) {
return null;
}
@Override
public Object handleError(Message<?> message, ListenerExecutionFailedException exception, Consumer<?, ?> consumer) {
return null;
}
}
配置使用方法如下
@KafkaListener(errorHandler="myErrorHandler")
public void userdeal(@Payload ConsumerRecord consumerRecord) {
//所有的异常全部对外抛出,不要处理,由myErrorHandler统一处理
}
补充
ObjectMapper日期序列化问题
ObjectMapper默认将日期类型序列化为Long类型的时间戳,而Spring中注入的ObjectMapper进行了配置修改,默认将日期类型序列化为字符串。
注意:
ObjectMapper默认将日期类型序列化为Long时间戳的原因是为了确保数据在不同的系统之间传输时的一致性和可靠性。长整型时间戳是一种通用的时间表示方式,可以在不同的编程语言和操作系统之间进行解释和转换,从而避免了日期格式不一致的问题。
此外,长整型时间戳还具有更高的精度和可读性,因为它们可以被直接转换为日期和时间,而无需进行进一步的解析和处理。这对于数据分析和处理非常有用,因为它可以让开发人员更轻松地对日期和时间进行操作和计算。
如果您想要将日期类型序列化为其他格式,例如ISO 8601日期格式或自定义格式,您可以使用ObjectMapper的日期格式化程序来实现。这将允许您根据需要定制日期格式,并确保数据在不同系统之间的传输和解析的一致性。
@SpringBootTest(classes = KafkaSpringBootDemo.class)
class JsonSerializerTest {
@Resource
private ObjectMapper objectMapper;
private ObjectMapper objectMapperNew=new ObjectMapper();
@Test
void dateSerializerTest() throws JsonProcessingException {
System.out.println("spring注入的ObjectMapper序列化结果: "+objectMapper.writeValueAsString(new Date()));
System.out.println("手动new的ObjectMapper序列化结果: "+objectMapperNew.writeValueAsString(new Date()));
}
}

在反序列化的时候,这个long类型数字将无法被自动识别为Date数据类型,而是被识别为Long类型,从而导致反序列化失败,而Spring kafka默认使用的日期序列化ObjectMapper ,也是手动new出来的。所以会将Date类型序列化为Long类型的时间戳。如果我们不希望出现这样的问题,可以进行如下的定义:
@Configuration
public class ConsumerKafkaConfig {
@Resource
private ObjectMapper objectMapper;
//反序列化器
@Bean
public DefaultKafkaConsumerFactory<?, ?> cf(KafkaProperties properties) {
Map<String, Object> props = properties.buildConsumerProperties();
return new DefaultKafkaConsumerFactory<>(props,
new StringDeserializer(), //指定key的反序列化方式是String
new JsonDeserializer<>(objectMapper)); //指定value的反序列化方式是JSON
}
//序列化器
@Bean
public DefaultKafkaProducerFactory<?, ?> pf(KafkaProperties properties) {
Map<String, Object> props = properties.buildProducerProperties();
return new DefaultKafkaProducerFactory<>(props,
new StringSerializer(), //指定key的序列化方式是String
new JsonSerializer<>(objectMapper)); //指定value的序列化方式是JSON
}
}
这样配置之后就不要在application.yml配置文件中写下面的参数了,配置也了也不会生效:
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
我们还可以使用ObjectMapper中的configure()方法来修改其配置,以便将日期类型序列化为字符串。具体代码如下:
@Test
void configureTest() throws JsonProcessingException {
objectMapperNew.configure(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS, false);
objectMapperNew.setDateFormat(new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSSZ"));
System.out.println("手动new的ObjectMapper序列化结果: "+objectMapperNew.writeValueAsString(new Date()));
}

这将禁用日期序列化为时间戳,并将日期格式设置为ISO 8601格式的字符串。您可以根据需要更改日期格式的格式字符串。