参考视频:跟着孙兴华学习Pandas 大数据分析入门课(B站)
参考资料:https://pan.baidu.com/s/162dV7YSt3KkRFIGnrLGmUg
提取码:2545
pandas中文官网:Pandas: 强大的 Python 数据分析支持库 | Pandas 中文 (pypandas.cn)
注:内容来自孙老师的笔记。
一、环境配置
pip install numpy
pip install pandas
pip install xlrd
pip install openpyxl
二、pandas基础知识
1、 文件类型与新建文件
| 文件类型 |
说明 |
新建方法 |
| csv、tsv、txt |
用逗号分隔、tab分割的纯文本文件 |
pd.to_csv |
| excel |
xls或xlsx |
pd.to_excel |
| mysql |
关系数据库表 |
pd.to_sql |
代码示例:
import pandas as pd
'''
01.数据类型与新建文件
数据类型 说明 新建方法
csv、tsv、txt 用逗号分隔、tab分割的纯文本文件 pd.to_csv
excel xls或xlsx pd.to_excel
mysql 关系数据库表 pd.to_sql
'''
# 创建xlsx文件,并且将数据录入表格。
file_path = './test.xlsx' # 创建的文件路径,以及文件名称。
data = pd.DataFrame({'id': [1, 2, 3], '姓名': ['叶问', '李小龙', '孙兴华']}) # 录入表格的数据
data = data.set_index('id') # 将id设置为索引
data.to_excel(file_path) # 将数据写入Excel文件
print('新建空白文件.xlsx成功')
# 创建txt文件,并且将数据录入表格。
file_path = './test.txt' # 创建的文件路径,以及文件名称。
data = pd.Series("好好学习,天天向上") # 录入文本的数据
data.to_csv(file_path) # 将数据写入txt文件
print('新建空白文件.txt成功')
结果:

文件夹:

2 读取文件数据
| 文件类型 |
说明 |
读取方法 |
| csv、tsv、txt |
默认逗号分隔 |
pd.read_csv |
| csv、tsv、txt |
默认\t分隔 |
pd.read_table |
| excel |
xls或xlsx |
pd.read_excel |
| mysql |
关系数据库表 |
pd.read_sql |
2.1读取txt(cvs)文件
| 文件类型 |
说明 |
读取方法su |
| csv、tsv、txt |
默认逗号分隔 |
pd.read_csv |
| csv、tsv、txt |
默认\t分隔 |
pd.read_table |
切记:如果分隔符不止一种,使用正则表达式sep='\s+'
2.1.1 读取txt文件-cvs相似
"""
读取数据
文件类型 说明 读取方法
csv、tsv、txt 默认逗号分隔 pd.read_csv
csv、tsv、txt 默认\t分隔 pd.read_table
excel xls或xlsx pd.read_excel
mysql 关系数据库表 pd.read_sql
"""
import pandas as pd
# 一、读取数据
file_path = 'E:\python_project\python-DataAnalysis\python-pandas\Pandas课件\课件\pandas教程\课件001-005\读取文件.txt'
'''
读取txt文件
'''
data = pd.read_csv(file_path)
# pd.read_csv 按照逗号划分
# pd.read_table 按照制表符划分
print(data)
'''
(1)通过names=['a','b','c']可以自己设置列标题。
(2)sep=',':英文逗号或"\t",从文件、url、文件型对象中加载带分隔符的数据,默认为'\t'。(read_csv默认分隔符是逗号),可以通过制定sep 参数来修改默认分隔符
(3)header=None:读取没有标题的文件时,默认为第一行作为列标题,设置header=None,意思就是没有表头,后面你自己写表头
(4)index_col='入职日期':设置索引属性
'''
print('\n')
# 二、查看前几行数据
print(data.head()) # 默认是5行,指定行数写小括号里
print('\n')
# 三、查看数据的形状,返回(行数、列数)
print(data.shape)
print('\n')
# 四、 查看列名列表
print(data.columns)
print('\n')
# 五、查看索引列
print(data.index)
print('\n')
# 六、查看每一列数据类型
print(data.dtypes)
结果:文件中没有表头,所以将数据第一行是为表头,所以出现如下的结果。
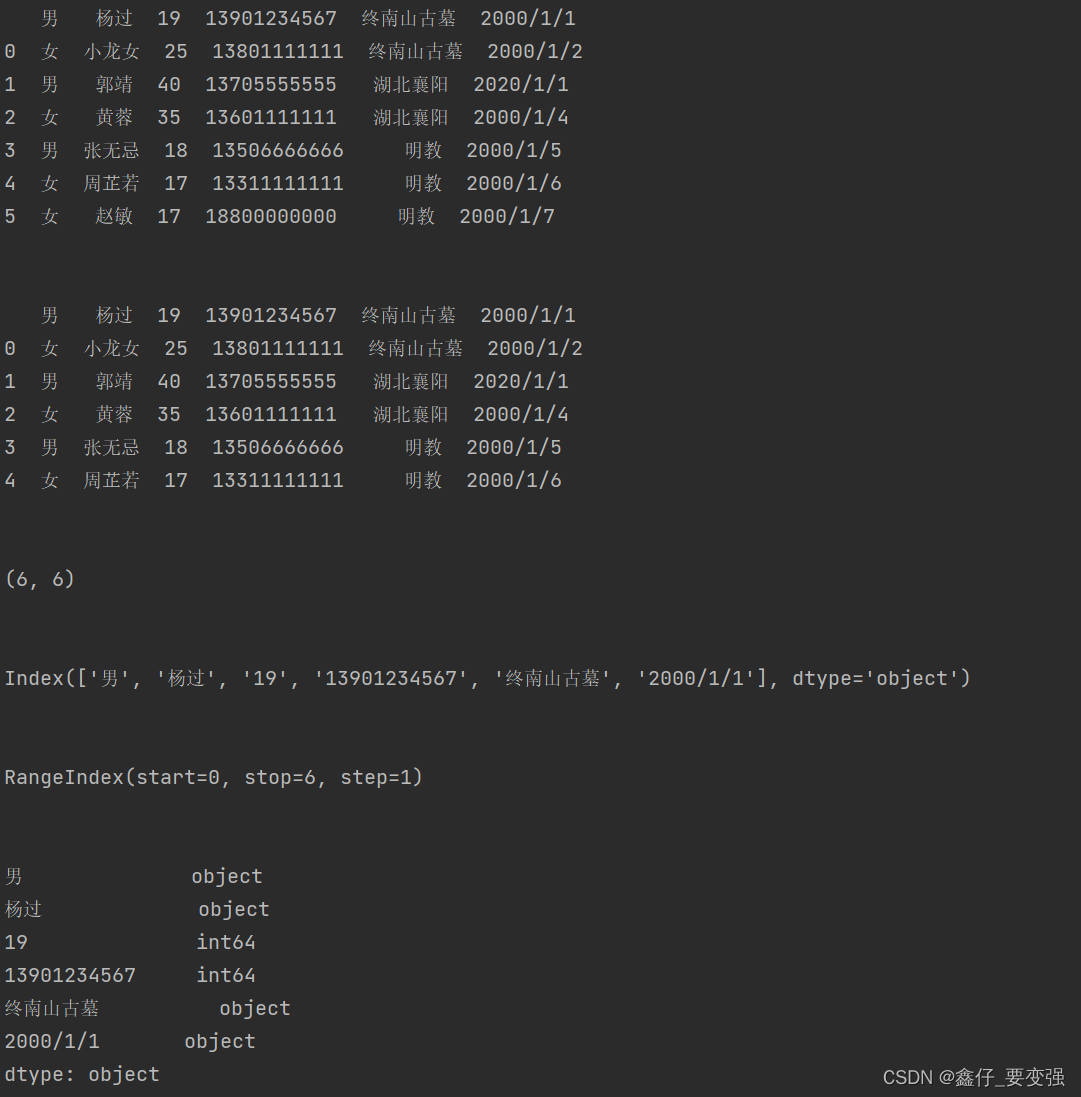
2.1.2 读取txt文件-进阶
示例:
import pandas as pd
'''
自己制定分隔符、列名
参数 描述
sep 分隔符或正则表达式 sep='\s+'
header 列名的行号,默认0(第一行),如果没有列名应该为None
names 列名,与header=None一起使用
index_col 索引的列号或列名,可以是一个单一的名称或数字,也可以是一个分层索引
skiprows 从文件开始处,需要跳过的行数或行号列表
encoding 文本编码,例如utf-8
nrows 从文件开头处读入的行数 nrows=3
'''
# 一、读取数据
path = 'E:\python_project\python-DataAnalysis\python-pandas\Pandas课件\课件\pandas教程\课件001-005\读取文件.txt'
'''
读取txt文件
'''
data = pd.read_csv(path, sep=',', header=None, names=['性别', '姓名', '年龄', '电话', '地址', '入职日期'], encoding='utf-8',
index_col='入职日期')
print(data)
'''
(1)通过names=['a','b','c']可以自己设置列标题。
(2)sep=',':英文逗号或"\t",从文件、url、文件型对象中加载带分隔符的数据,默认为'\t'。(read_csv默认分隔符是逗号),可以通过制定sep 参数来修改默认分隔符
(3)header=None:读取没有标题的文件时,默认为第一行作为列标题,设置header=None,意思就是没有表头,后面你自己写表头
(4)index_col='入职日期':设置索引属性
'''
print('\n')
# 二、查看前几行数据
print(data.head()) # 默认是5行,指定行数写小括号里
print('\n')
# 三、查看数据的形状,返回(行数、列数)
print(data.shape)
print('\n')
# 四、 查看列名列表
print(data.columns)
print('\n')
# 五、查看索引列
print(data.index)
print('\n')
# 六、查看每一列数据类型
print(data.dtypes)结果:
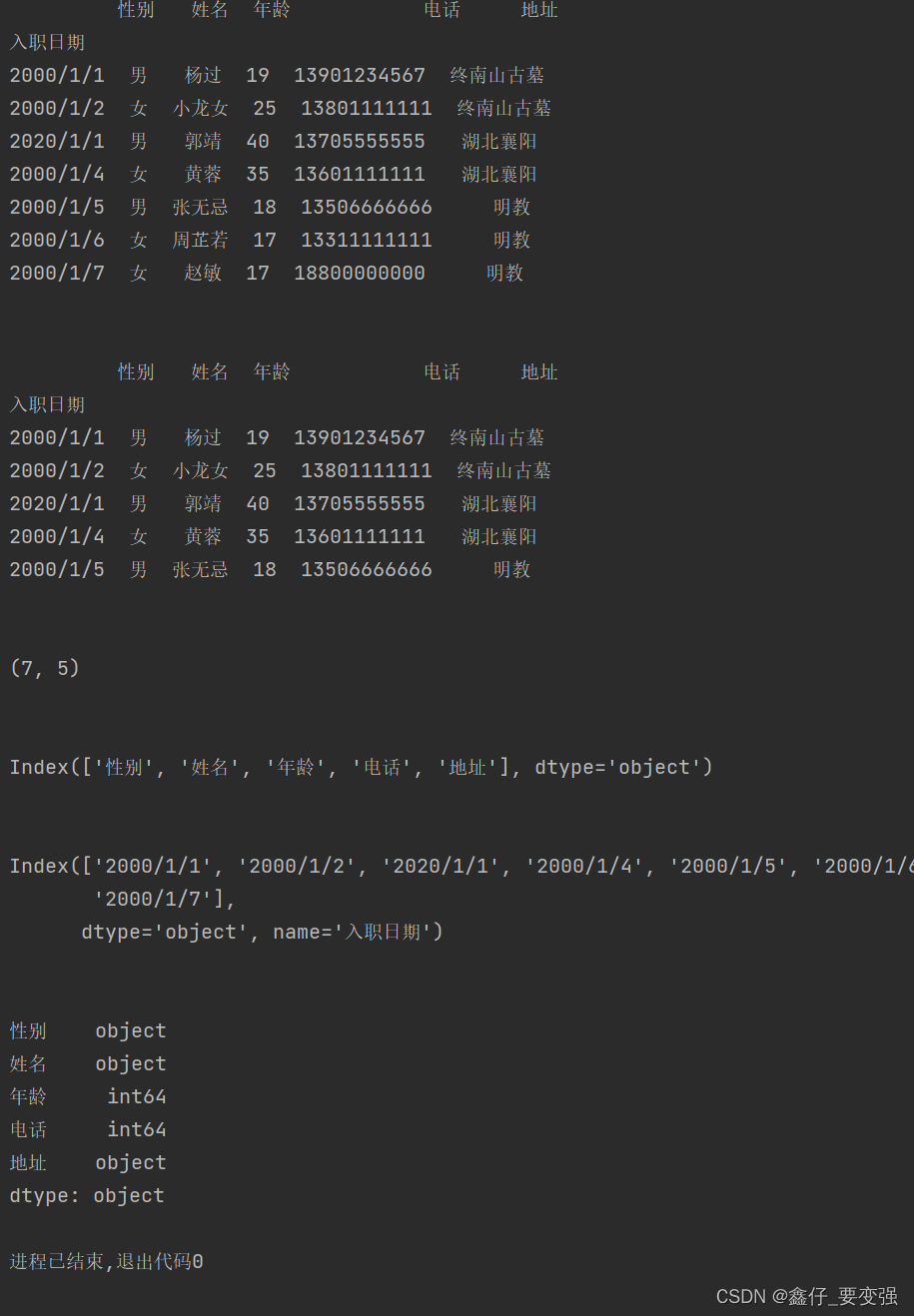
注意:你的txt文档必需另存为utf-8编码,如果是ASCII报错
| 参数 |
描述 |
| sep |
分隔符或正则表达式 sep='\s+' |
| header |
列名的行号,默认0(第一行),如果没有列名应该为None |
| names |
列名,与header=None一起使用 |
| index_col |
索引的列号或列名,可以是一个单一的名称或数字,也可以是一个分层索引 |
| skiprows |
从文件开始处,需要跳过的行数或行号列表 |
| encoding |
文本编码,例如utf-8 |
| nrows |
从文件开头处读入的行数 nrows=3 |
2.1.3txt文件转csv文件
import pandas as pd
# 读取txt文件的数据
data = pd.read_csv('E:\python_project\python-DataAnalysis\python-pandas\Pandas课件\课件\pandas教程\课件001-005\读取文件.txt')
# 创建cvs文件,并且将数据写入其中。
data.to_csv ('./读取文件.cvs')
print(data)结果:

文件夹:
2.2 读取MySQL数据库
示例:
import pandas as pd
import pymysql
连接对象 = pymysql.connect(host = 'localhost',user = 'root',password = '1234',database = 'test',charset = 'utf8')
读取文件 = pd.read_sql("select * from 1班",con=连接对象)
# 第1个参数是SQL查询语句,第2参数是数据库连接
print(读取文件)
2.3 读取Excel文件
import pandas as pd
# 文件的路径
path = "E:\python_project\python-DataAnalysis\python-pandas\Pandas课件\课件\pandas教程\课件001-005\读取文件.xlsx"
# 设置数据的格式
data = pd.read_excel(path, header=None, names=['序号', '姓名', '年龄', '地址', '电话', '入职时间'], index_col='序号')
print(data)
# 将数据写入文件
data.to_excel('./读取文件.xlsx')表格内容:

结果:

3pandas数据结构
DataFrame:二维数据,整个表格,多行多列 【简称df】
df.index:索引列
df.columns:列名
Series:一维数据,一行或一列
3.1 pd.Series:一维数据
Series是一种类似于一维数组的对象,它由一组数据(不同数据类型)以及一组与之相关的数据标签(即索引)组成。
案例:
import pandas as pd
# 仅有数据列表即可产生最简单的Series
data = pd.Series([1234, '鑫', 467, '2000-02-30']) # 左侧是索引,右侧是数据
print('仅有数据列表即可产生最简单的Series:')
print(data)
print(data.index) # 获取索引,返回索引的(起始值,结束值,步长)
print(data.values) # 获取数据,返回值序列,打印元素值的列表
print('-' * 30)
# 我们指定Series的索引
data = pd.Series([1234, '鑫', 467, '2000-02-30'], index=['a', 'b', 'c', 'd']) # 指定索引
print('我们指定Series的索引:')
print(data)
print(data.index) # 返回指定的索引
print('-' * 30)
# 使用Python字典创建Series
dict1 = {'姓名': '赵匡义', '性别': '男', '年龄': '20', '地址': '宋代皇宫'}
data = pd.Series(dict1)
print('使用Python字典创建Series:')
print(data)
print(data.index) # 返回key
print('-' * 30)
# 根据标签索引查询数据
print('根据标签索引查询数据:')
print(data) # 查询整个字典
print(data['姓名']) # 通过key可以查对应的值
type(data['年龄']) # 通过key可以查对应值的类型
print(data[['姓名', '年龄']]) # 通过多个key查对应的值
type(data[['姓名', '年龄']]) # 注意:他不返回值的类型,而返回Series
print('-' * 30)
list1 = ['姓名', '性别', '年龄']
list2 = ['赵飞', '男', 20]
data = pd.Series(list2, index=list1) # 指定谁是索引
print('键和值存在两个列表中,创建Series:')
print(data)
结果:

备注:
Series只是一个序列,可能是一行,也可能是一列,现在无法确定用行的方法,把Series加入DataFrame,就是行,反之就是列。