第一范式
一个关系模式应当是一个五元组。
R ( U , D , D O M , F ) R(U,D,DOM,F) R(U,D,DOM,F)
这里:
- 关系名 R R R是符号化的元组语义
- U U U为一组属性
- D D D为属性组 U U U中的属性所来自的域
- D O M DOM DOM为属性到域的映射
- F F F为属性组 U U U上的一组数据依赖
由于 D , D O M D,DOM D,DOM与模式设计关系不大,因此在此把关系模式看作一个三元组: < U , F > <U,F> <U,F>
当且仅当 U U U上的一个关系 r r r满足 F F F时, r r r成为关系模式 R < U , F > R<U,F> R<U,F>的一个关系。
作为一个二维表,关系要符合一个最基本的条件:每一个分量必须是不可分的数据项
满足了这个条件的关系模式就属于第一范式(1NF)

数据依赖:
数据依赖是一个关系内部属性与属性之间的一种约束关系。
这种约束关系是通过属性间值的相等与否体现出来的数据间相关联系。
人们已经提出了许多种类型的数据依赖,其中最重要的是函数依赖和多值依赖
但是,这个关系模式存在以下问题:
数据冗余
每一个系的系主任姓名重复出现,重复次数与该系所有学生的课程成绩出现的次数相同。
这将浪费大量的存储空间。
更新异常
某系更换系主任后,必须修改与该系学生有关的每一个元组。
插入异常
如果一个系刚成立,尚无学生,则无法将这个系及其系主任的信息存入数据库。
删除异常
如果某个系的学生全部毕业了,则在删除该系学生信息的同时,这个系及其系主任的信息也丢掉了。
一个好的模式应当不会发生插入异常、删除异常和更新异常,数据冗余应尽可能少。
规范化
函数依赖
设 R ( U ) R(U) R(U)是属性集 U U U上的关系模式, X , Y X,Y X,Y是 U U U的子集。若对于 R ( U ) R(U) R(U)的任意一个可能的关系 r r r, r r r中不可能存在两个元组在 X X X上的属性值相等,而在 Y Y Y上的属性值不等,则称 X X X函数确定 Y Y Y或 Y Y Y函数依赖于 X X X。
记作 X → Y X \rightarrow Y X→Y。
函数依赖和别的数据依赖一样是语义范畴的概念,只能根据语义来确定一个函数依赖。
下面介绍一些术语和记号
-
X → Y X \rightarrow Y X→Y,但 Y ⊊ X Y \subsetneq X Y⊊X,则称 X → Y X \rightarrow Y X→Y是非平凡的函数依赖。
-
X → Y X \rightarrow Y X→Y,但 Y ⊆ X Y \subseteq X Y⊆X,则称 X → Y X \rightarrow Y X→Y是平凡的函数依赖。
对于任一关系模式,平凡函数依赖都是必然成立的,它不反映新的语义。若不特别声明,总是讨论平凡的函数依赖。 -
若 X → Y X \rightarrow Y X→Y,则 X X X称为这个函数依赖的决定属性组,也称为决定因素。
-
若 X → Y X \rightarrow Y X→Y, Y → X Y \rightarrow X Y→X,则记作 X ← → Y X \leftarrow \rightarrow Y X←→Y
-
若 Y Y Y函数不依赖于 X X X,则记作 X ↛ Y X \nrightarrow Y X↛Y
在 R ( U ) R(U) R(U)中,如果 X → Y X \rightarrow Y X→Y,并且对于 X X X的任何一个真子集 X ′ X^{'} X′,都有 X ′ ↛ Y X^{'}\nrightarrow Y X′↛Y,则称 Y Y Y对 X X X完全函数依赖,记作 X → F Y X{\rightarrow}^{F} Y X→FY
如果 X → Y X \rightarrow Y X→Y,但 Y Y Y不完全函数依赖于 X X X,则称 Y Y Y对 X X X部分函数依赖,记作 X → P Y X{\rightarrow}^{P} Y X→PY
码
码是关系模式中的一个重要概念。
设 K K K为 R < U , F > R<U,F> R<U,F>中的属性或属性组合,若 R → F U R{\rightarrow}^{F} U R→FU,则 K K K为 R R R的候选码。
注意 U U U是完全函数依赖于 K K K,而不是部分函数依赖于 K K K。一般地,如果 U U U函数依赖于 K K K,即 K → U K{\rightarrow} U K→U,则 K K K称为超码。
候选码是一类特殊的超码,即候选码的超集(如果存在)一定是超码,候选码的任何真子集一定不是超码。
若候选码多于一个,则选定其中的一个为主码。
包含在任何一个候选码中的属性称为主属性;不包含在任何候选码中的属性称为非主属性或非码属性。
最简单的情况,单个属性是码;
最极端的情况,整个属性组是码,称为全码。
范式
关系数据库中的关系是要满足一定要求的,满足不同程度要求的为不同范式。
一个低一级的范式的关系模式通过模式分解可以转换为若干高一级范式的关系模式的集合,这种过程就叫规范化。
第二范式
若 R ∈ 1 N F R\in 1NF R∈1NF,且每一个非主属性完全函数依赖于任何一个候选码,则 R ∈ 2 N F R\in 2NF R∈2NF。


第三范式
设关系模式 R < U , F > ∈ 1 N F R<U,F> \in1NF R<U,F>∈1NF,若 R R R中不存在这样的码 X X X,属性组 Y Y Y及非主属性 Z ( Z ⊊ Y ) Z(Z \subsetneq Y) Z(Z⊊Y)使得 X → Y X \rightarrow Y X→Y, Y → Z Y \rightarrow Z Y→Z, Y ↛ X Y\nrightarrow X Y↛X,则称 R < U , F > ∈ 3 N F R<U,F>\in3NF R<U,F>∈3NF。

扩充的第三范式
BCNF是修正的第三范式,有时也称为扩充的第三范式。
关系模式 R < U , F > ∈ 1 N F R<U,F>\in1NF R<U,F>∈1NF,若 X → Y X \rightarrow Y X→Y且 Y ⊊ X Y\subsetneq X Y⊊X时 X X X必含有码,则 R < U , F > ∈ B C N F R<U,F>\in BCNF R<U,F>∈BCNF
由 N C N F NCNF NCNF的定义可以得到结论,一个满足 B C N F BCNF BCNF的关系模式有:
- 所有非主属性对每一个码都是完全函数依赖。
- 所有主属性对每一个不包含它的码也是完全函数依赖。
- 没有任何属性完全函数依赖于非码的任何一组属性。
多值依赖
设 R ( U ) R(U) R(U)是属性集 U U U上的一个关系模式。 X , Y , Z X,Y,Z X,Y,Z是 U U U的子集,并且 Z = U − X − Y Z=U-X-Y Z=U−X−Y。关系模式 R ( U ) R(U) R(U)中多值依赖 X → → Y X\rightarrow\rightarrow Y X→→Y成立,当且仅当对 R ( U ) R(U) R(U)的任一关系 r r r,给定的一对 ( x , z ) (x,z) (x,z)值,有一组 Y Y Y的值,这组值仅仅决定于 x x x值而与 z z z值无关。
多值依赖具有以下性质:
- 对称性
- 传递性
- 函数依赖可以看作是多值依赖的特殊情况
与函数依赖相比,多值依赖有下面两个基本的区别:
- 多值依赖的有效性与属性集的范围有关
- 见P188
4NF
4 N F 4NF 4NF就是限制关系模式的属性之间不允许有非平凡且非函数依赖的多值依赖。
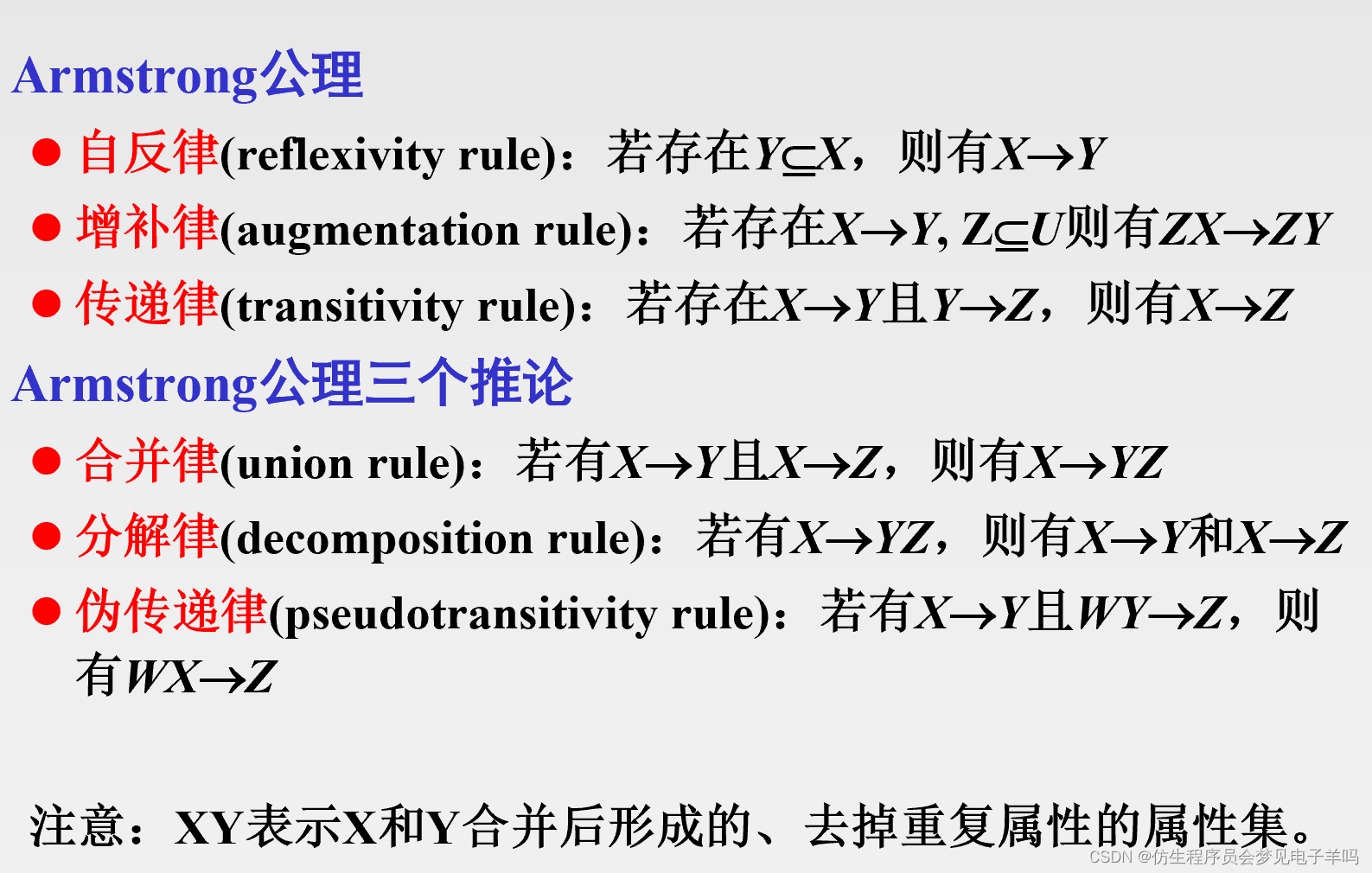
数据依赖的公理系统
A r m s t r o n g Armstrong Armstrong公理系统:设 U U U为属性集总体, F F F是 U U U上的一组函数依赖,于是有关系模式 R < U , F > R<U,F> R<U,F>,对其来说有以下的推理法则:
- A1 自反律
- A2 增广律
- A3 传递律
根据 A 1 , A 2 , A 3 A1,A2,A3 A1,A2,A3这三条推理规则可以得到下面三条有用的推理规则:
- 合并规则
- 伪传递规则
- 分解规则