概念
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
例如我们要我找在40亿个数据中查找某字符串是否存在,我们也是第一想到的是通过遍历一个一个去比对,但是数据庞大,遍历消耗很多的时间和空间的资源。但是我们可以通过一位图+哈希来解决这个问题。在常数时间内判断该字符串是否存在。位图+哈希,我们称为布隆过滤器。其实这并不能百分百确认该字符串是否存在,只能表示该字符串有可能存在。时间复杂度为O(k),k为哈希函数的个数。下面我们来看看布隆过滤器的原理吧
如果你还不了解位图,可以先看看这一偏博文C++ 位图及位图的实现
原理
将字符串通过n个哈希函数,得出n个数字,再用着n个数字将位图中指定位置置位1

一开始说的为什么不能百分百确认字符串是否存在呢?布隆过滤器是由哈希和位图组成的,而使用哈希难免会造成哈希冲突,此时不同字符串计算出来的哈希位置有可能相同,此时就无法确定是哪个字符串置为1的,所以只能说是该字符串有可能存在,如果该位置为0则表示该字符串肯定不存在
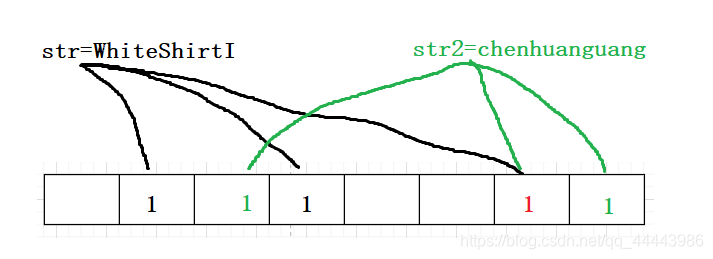
所以一个字符串的哈希函数计算和哈希函数的个数都很重要,这里哈希函数的个数直接用大佬前辈们计算出来的公式:k = m / (n * ln2)(m=位图需要的bit为的大小;n=元素的个数;k=哈希函数的个数)。而哈希函数的计算方式也是通过前辈们总结出来的,都是可以降低哈希冲突的
实现
成员变量和构造函数:成员变量主要是一个位图加一个bit位的个数。其中构造函数要对这两个成员进行初始化,位图所需要的的bit位的大小为m=k * n * ln2。注意,需要取整。
存储数据:存储数据时,我们需要将传进来的字符串通过n哈希函数获得n个下标,但是通过哈希函数计算出来的值有可能会超过我们位图中bit位的个数,此时就需要模上比特位的个数,将其缩小到[0, m)之间。防止越界访问。计算出来的哈希值就带入位图中,将位图中的哈希值的指定位置置为1即可。这里的哈希函数我们直接使用大佬用过的(文末代码有)
查找数据:查找数据也是类似,只要计算出对应的哈希位置,然后查看哈希位置所在的位图是否为1,只要有1个为0则表示不存在,返回false。如果全部存在就返回true
删除数据:布隆过滤器不支持删除的操作,假如某个位图的哈希位置有可能是冲突的,就拿上面的图来解释。如果要想删除字符串str,则就表示要将字符串的哈希位置对应的位图置为0。则此时的字符串str2就不能被查找到,因为字符串str2的第二个哈希位置被置位了0,则表示字符串str2不存在,这是有歧义的,所以就布隆过滤器是并不支持删除操作的
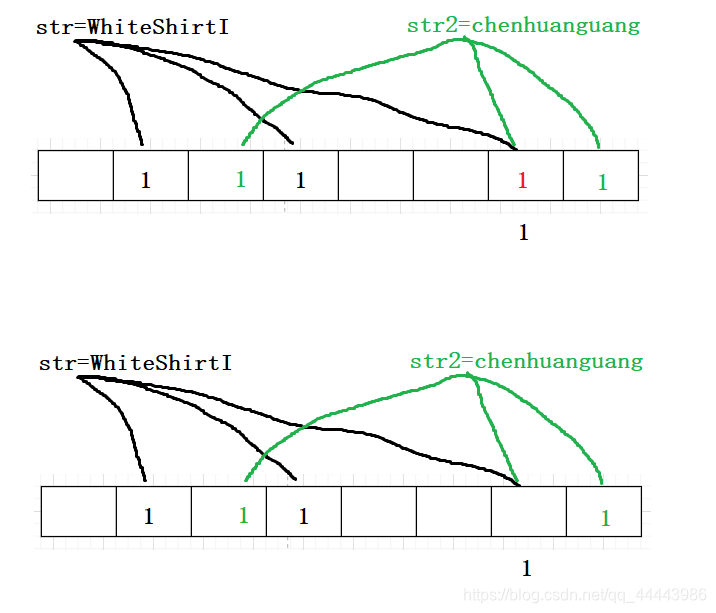
但是如果非要想提供删除的技术,也不是不可以,只是付出的代价比较大。我们可以给每个bit位绑定一个计数器,如果某个bit位存在多个1,则让计数器进行累加,只有该bit位被删除次数等于计数器时,才将bit位置位0。但是这种也并不实用。例如我们可以将1个数所占的bit位增加到2个,非0表示的是计数器的大小,00表示该数据不存在。但是当数据多时,累加最后会溢出。所以最后还是需要更多的bit位。但是这样子又增加了空间的使用,而且布隆过滤器本来就不能百分百确定数据是否存在,所以这付出比收益大,所以一般不提供这样的操作
代码:
struct HashFun1
{
//将字符串的每个字符通过计算得到一个hash值
size_t operator()(const string& str)
{
size_t hash = 0;
for (const auto& ch : str)
{
hash = hash * 131 + ch;
}
return hash;
}
};
struct HashFun2
{
size_t operator()(const string& str)
{
size_t hash = 0;
for (const auto& ch : str)
{
hash = hash * 65599 + ch;
}
return hash;
}
};
struct HashFun3
{
size_t operator()(const string& str)
{
size_t hash = 0;
for (const auto& ch : str)
{
hash = hash * 1313131 + ch;
}
return hash;
}
};
template<class T, class HashFun1, class HashFun2, class HashFun3>
class BloomFilter
{
public:
BloomFilter(const size_t num)
:_bit(5 * num)
, _bitCount(5 * num)
{
}
void set(const T& val)
{
HashFun1 h1;
HashFun2 h2;
HashFun3 h3;
int idx1 = h1(val) % _bitCount;
int idx2 = h2(val) % _bitCount;
int idx3 = h3(val) % _bitCount;
_bit.set(idx1);
_bit.set(idx2);
_bit.set(idx3);
}
bool find(const T& val)
{
HashFun1 h1;
HashFun2 h2;
HashFun3 h3;
int idx1 = h1(val) % _bitCount;
int idx2 = h2(val) % _bitCount;
int idx3 = h3(val) % _bitCount;
if (!_bit.find(idx1))
return false;
if (!_bit.find(idx2))
return false;
if (!_bit.find(idx3))
return false;
return true;//可能存在
}
private:
BitMap _bit;//位图(上一篇博文有实现代码)
size_t _bitCount;
};